【C++入门篇】保姆级教程篇【中】
目录
零、面向对象的由来
一、结构体与类
二、类和对象
1)面向过程和面向对象:
2)类的声明与定义
3)类的访问限定符
三、this指针
1)this指针的概念
2)this指针的特性
四、类的默认成员函数
1)构造函数:
2)析构函数:
3)拷贝构造:
前言:
由上一篇的博客我们已经学习到可以写出的基本C++程序了,接下来我们将要进入C++重要的一环——面向对象,在学习面向对象之前,我觉得有必要先了解一下面向对象的由来,那么我们就从语言的发展史开始今天的学习之旅吧!

零、面向对象的由来
在1940年以前,最早的程序设计都是采用机器码,直接使用二进制码来表示机器能够识别和执行的指令和数据,就是直接使用二进制码进行程序的编写(即0和1序列)。
虽然说机器语言由机器直接执行起来很快,但是写起来实在是太慢了,等到发现错误的时候改起来更加费力,这样写起来往往效率低下。由于机器语言实在是太难编写了,于是就发展出了汇编语言,也称为符号语言,用符号代替机器指令的操作码,用地址符号(Symbol)或标号(Label)代替指令或操作数的地址,这样就在在一定程度上简化了编程过程。
虽然说汇编语言简化了编程的过程,但是汇编语言依旧是面向机器的语言,用起来也是很困难,也很容易出错。
面向机器的语言被广泛称之为“低级语言”,是为了解决面向机器的语言存在的问题,巨佬们又创建了面向过程的语言,也被称为“高级语言”,面向过程的语言不在关注机器本身的一些操作,转而关注如何一步步解决具体的问题的过程,这也是面向过程的由来。
与面向机器语言相比,面向过程的语言就是质的飞跃了,减轻了程序员的大量负担,提升程序员的工作效率促进软件行业的快速发展,这阶段发展的语言COBOL、FORTRAN、C语言等语言。
但是随着计算机硬件的快速发展,应用复杂度越来越高,软件规模越来越大,面向过程的语言略显疲态。于是在1960年代爆发了第一次软件危机,典型表现有软件质量低下、项目无法 如期完成、项目严重超支等,因为软件而导致的重大事故时有发生,典型的例子像:1963年美国水手一号火箭发射失败事故,就是因为一行FORTRAN 代码出现了错误所导致的。这个时候面向过程的语言还顶的住。
到了第二次软件危机,根本原因还是软件发展速度跟不上硬件发展,相比第一次的“复杂性”问题,第二次则主要问题是“可拓展性”、“可维护性”,面向过程似乎已经经不起折磨了,在高速变换的业务与需求之下人们迫切需要新的编程模式来对接业务需求,于是面向对象的设计模式以救世主的姿态站了出来,其实面向对象的思想早在1967年就在Simula语言中提出,只是第二次软件危机促进了面向对象的发展,这一思想更加贴合人类的思维,是一次软件设计上的质的飞跃。这阶段发展出来的优秀语言有:C++, java, python, C#等等语言,一直沿用到今天依然没有过时。
这里只是简单叙述了一下从机器语言到面向对象的发展过程,如果想详细了解一下发展史可以看看一位博客园大佬的文章:《面向对象程序设计的由来》。
一、结构体与类
让我们把思绪拉回到曾经学过的数据结构——栈,想一想我们是如何实现一个栈的?
首先,我们需要用到结构体来定义栈这种数据结构,其次在把栈的各个操作以函数的形式一一在全局范围内实现出来,最后再对栈进行各种操作。
//栈的基本操作
typedef int STDataType;
typedef struct Stack
{
STDataType* _a; // 动态栈
int _top; // 栈顶
int _capacity; // 容量
}Stack;
// 初始化栈
Stack* StackInit(STDataType n)
{
//...
}
// 入栈
void StackPush(Stack* ps, STDataType data)
{
//...
}
// 检测栈是否为空,如果为空返回非零结果,如果不为空返回0
bool StackEmpty(Stack* ps)
{
//...
}
// 出栈
void StackPop(Stack* ps)
{
//...
}
// 获取栈顶元素
STDataType StackTop(Stack* ps)
{
//...
}
// 获取栈中有效元素个数
int StackSize(Stack* ps)
{
//...
}
// 销毁栈
void StackDestroy(Stack* ps)
{
//...
}想必这种数据结构的实现大家也很熟悉,但是我们的祖师爷叒对C语言的这一块不满意了,祖师爷在开发的过程中发现,快速变换的业务与需求对高速发展的硬件已经不匹配了,于是祖师爷在设计C++时也引入了面向对象这一特性。
于是在C++中结构体我们可以这样写:
typedef int STDataType;
struct Stack
{
STDataType* _a; // 动态栈
int _top; // 栈顶
int _capacity; // 容量
// 初始化栈
void Init(STDataType n)
{
//...
}
// 入栈
void Push(STDataType data)
{
//...
}
// 检测栈是否为空,如果为空返回非零结果,如果不为空返回0
bool Empty()
{
//...
}
// 出栈
void Pop()
{
//...
}
// 获取栈顶元素
STDataType Top()
{
//...
}
// 获取栈中有效元素个数
int Size()
{
//...
}
// 销毁栈
void Destroy()
{
//...
}
};我们可以看到在C++中,我们可以将函数放在结构体内,这种写法在C语言中会发生报错,但在C++中是合法的,也就是说在C语言中不能将属性和行为进行分离。
不知道大家有没有注意到,我在用C++写结构体的时候并没有使用typedef,这其实是因为在C++中,只要你定义了结构体,那么就会默认typedef你结构体的名称。
在C++中,结构体也被称为“类”,类就是结构体,结构体内部变量被称为成员变量,内部函数也被称为成员函数,C++这种写法会更加方便,首先 在C语言中不同结构体经常会有重复操作,像最基本的增删查改初始化等,C语言常常是这样的:
StackInit(),QueueInit(),StackPush(),QueuePush(),StackPop(),QueuePop()...
这些操作前面加上结构的名称加以区分,但是像C++中把操作函数放到结构体内部,名字写起来会更加的方便,只用Push,Pop...来表示操作就行,这是因为我们可以直接在类的内部直接调用这个函数,像:
void Test()
{
Stack st;//使用Stack *st, 访问方式就是st -> Push()...这里跟C语言一样
st.Init();
st.Push();
st.Push();
st.Push();
st.Push();
st.Push();
st.Pop();
st.Pop();
//...
return 0;
}直接可以由这个类定义出来的变量来调用类的成员函数,这样也不用担心名字太长记不住的问题,但其实这并不是C++类的标准写法,而且这并不是比较重要的点。
相信你还是有些疑问,毕竟群众的眼睛是雪亮的,在C++里我们把函数放到类的内部的时候,不仅把函数名缩短了,而且还把指针形参全部删除了,你一定很奇怪,但是不要急,让我来一一为你来介绍 什么是类和对象,以及类的标准写法,以及为什么没有传指针。
二、类和对象
1)面向过程和面向对象:
在上面的历史里我们大概也知道了什么是面向过程,什么是面向对象,它们真正的定义是:
面向过程:就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了。
面向对象:是把构成问题事务分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描述某个事物在整个解决问题的步骤中的行为。
或许有些人对面向对象还是不太理解,其实前面用C++的方式写的栈,在Test函数内创建的变量,其实就叫对象。我这里举一个例子:
工人在造房子之前需要建筑图纸,这个图纸可以看做是一个类,图纸的内容就是类的成员变量及成员函数,那么图纸可以住人吗?显然不行,所以类是不存储任何数据的。但是由图纸建造的房子可以住人吗?当然可以,其实这个所谓的房子就是 类的实例化(对象)。

2)类的声明与定义
在前面我也提到了,struct的写法并不是一个标准类的写法,在C++中类的标准写法是需要关键字——class 的,那么该如何定义一个类呢?
class className{
//类体,由成员函数和成员变量组成
};//一定要带分号实际上,class为定义类的关键字,className为类的名字,{}内为类的主体,注意类定义结束时后面分号不能省略。类体中内容称为类的成员,类中的变量称为类的属性 或 成员变量,类中的函数称为成员方法 或 成员函数。
类有两种定义方式:1、声明 和 定义全部放在类体中,要注意的是,成员函数如果在类中定义,编译器可能会将其当成 内联函数 处理。
class Person{
public:
//显示基本信息
void showinfo()
{
cout << "name :" << _name << "sex :" << _sex << "age :" << _age << endl;
}
private:
char* _name;//姓名
char* _sex;//性别
int _age;//年龄
};2、类的 声明 放在.h文件中,成员函数的 定义 放在.cpp文件中,注意:类与namespace一样也是一种 域,所以在.cpp文件中要在成员函数名前要加 类名:: 。
#include"Person.h"
//显示基本信息
void Person::showinfo()
{
cout << "name :" << _name << "sex :" << _sex << "age :" << _age << endl;
}我们前面以工程图为例来解释类和对象,其中,由工程图创建的房子就叫做对象,那么,房子是否可以重复建?肯定是可以的,而且房子之间互不影响,也就是说,一个类可以有多个对象,而且各个对象之间互不影响。
那么我们房间的大小呢?我们在C语言中有个叫做 内存对齐 的东西(如果有些遗忘可以看看我的这篇文章:C语言内存对齐),但是在C语言中我们的struct内部是不存在函数的,所以我们对类进行sizeof会发生什么呢?我们以Date(日期)类为例:
#include
using namespace std;
class Date{//日期类
public:
void Init(int year, int month, int day)//初始化年月日
{
_year = year;
_month = month;
_day = day;
}
void Print()//打印当前年月日
{
cout << _year << "-" << _month << "-" << _day << endl;
}
private://私有成员
int _year;//年
int _month;//月
int _day;//日
};
void Test()
{
Date d;//创建对象
d.Init(2023, 10, 28);//初始化
d.Print();//打印当前年月
cout << sizeof(Date) << endl;//将类的大小打印出来
}
int main()
{
Test();
return 0;
}  如果只看私有成员变量,对C语言来说就是三个整形,那么sizeof后的结果不出意外是12,然而我们发现,我们对这个类的进行sizeof的结果也是12,那是不是就是可以认为函数并不存在类的内部?我们可以设计一个类,把空指针传给对象,再看看这个对象是否能调用类的成员函数:
如果只看私有成员变量,对C语言来说就是三个整形,那么sizeof后的结果不出意外是12,然而我们发现,我们对这个类的进行sizeof的结果也是12,那是不是就是可以认为函数并不存在类的内部?我们可以设计一个类,把空指针传给对象,再看看这个对象是否能调用类的成员函数:
#include
using namespace std;
class byte {
public:
void Print()
{
cout << "嘿嘿,看的到我吗?" << endl;
}
private:
int _a;
};
void Test()
{
byte *s;//创建指针对象
s = nullptr;//将指针置空
s -> Print();//调用类内部函数
}
int main()
{
Test();
return 0;
}  我们发现,虽然我们把对象指针置空了,但是我们依旧可以继续调用类内部函数,这也就说明了类内部函数的空间并不与类在同一片空间。
我们发现,虽然我们把对象指针置空了,但是我们依旧可以继续调用类内部函数,这也就说明了类内部函数的空间并不与类在同一片空间。
那么既然如此,我们专门来打印一下函数与类内部成员的地址来进行比较它们的位置(为了能够访问到类的私有成员变量,这里将私有改为公有):
#include
using namespace std;
class Date{
public:
void Init(int year, int month, int day)
{
_year = year;
_month = month;
_day = day;
}
void Print()
{
cout << _year << "-" << _month << "-" << _day << endl;
}
//private:
int _year;
int _month;
int _day;
};
void Test()
{
Date d;
cout << "year : " << &d._year << endl;
cout << "month : " << &d._month << endl;
cout << "day : " << &d._day << endl;
cout << &d.Init << endl;
cout << &d.Print << endl;
return;
}
int main()
{
Test();
return 0;
} 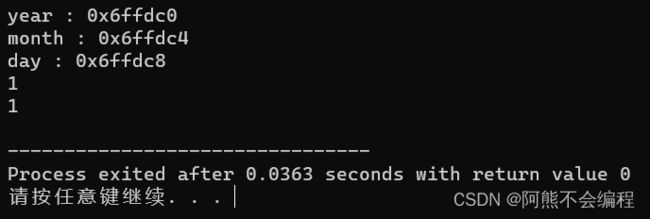 我们发现,打印出来的成员变量的地址值和C语言中的内存对齐没有什么区别。
我们发现,打印出来的成员变量的地址值和C语言中的内存对齐没有什么区别。
那么既然成员函数不在类内部,如果是个空类(只有成员函数,无成员变量)呢?这个时候类的大小是多少呢?
#include
using namespace std;
class null{
public:
void Print()
{
cout << "今天天气不错" << endl;
}
};
int main()
{
null p;
cout << sizeof(null) << endl;
return 0;
}  可以看到,类的大小不是0,而是1,为什么是1呢?这是因为无论是不是空类但总要保存这个类的地址,语法上是不占用空间的,但是实际上还是需要一定的空间用来寻址的。
可以看到,类的大小不是0,而是1,为什么是1呢?这是因为无论是不是空类但总要保存这个类的地址,语法上是不占用空间的,但是实际上还是需要一定的空间用来寻址的。
3)类的访问限定符
相信你也注意到了,上面代码中Person类内有private和public,那这些是什么呢?其实,为了更好的去维护代码,于是在类内有着“ 权限 ”存在,叫做 访问限定符,其中访问限定符有三种,就是public(公有),protected(保护),private(私有) 三种访问限定符。
访问限定符说明:
1、 public修饰的成员在类外可以直接被访问。
2、protected 和 private 不可在类外访问(在这里这两个是相同的,在多态继承那里有区别)
3、访问权限作用域从该访问限定符出现的位置开始直到下一个访问限定符出现为止。
4、如果后面没有访问限定符,作用域就到 } 即类结束。
5、class的默认访问权限为private,struct为public(因为struct要兼容C)
注意:访问限定符只在编译时有用,当数据映射到内存后,没有任何访问限定修饰符上的区别。
面试题【问:C++中struct和类有什么区别?】
答:C++兼容C,所以C++中struct可以当成结构体来使用。另外C++中struct还可以用来定义类。和class定义类是一样的,不一样的是struct成员默认访问权限为public,而class成员默认访问权限为private。注:在继承和模版参数列表位置,struct 和 class 也有区别,后面再介绍。
三、this指针
在最开始,我们留下的问题还有一个没有解决,那就是指针问题,为什么把函数放在类内,就不用传指针了呢,这样还能运行吗?
#include
#include
#include
using namespace std;
class Stack {
public:
void Init(int capacity = 3)//这里仅仅实现一个函数
{
_a = (int*)malloc(sizeof(int) * capacity);
if (_a == nullptr)
{
perror("malloc");
exit(-1);
}
_top = -1;
_capacity = capacity;
}
private:
int* _a;
int _top;
int _capacity;
};
int main()
{
Stack st;
st.Init();
return 0;
}  我们从监视里面可以看到,就算没有传指针,类的内部私有成员依旧是被赋了值。那到底为什么不用指针就能访问呢?这就是不得不说一个默认存在类内部的指针——this指针。
我们从监视里面可以看到,就算没有传指针,类的内部私有成员依旧是被赋了值。那到底为什么不用指针就能访问呢?这就是不得不说一个默认存在类内部的指针——this指针。
1)this指针的概念
其实,上回就说了祖师爷早就看指针不爽很久了,每次我要用自定义类型我都需要去取地址,很有可能会忘记取地址造成无法预料的后果,于是祖师爷在C++中引入了this指针。
在类中,C++定义了一个 默认 的参数——this指针,可是我们在前面到现在的代码里都没有this指针啊?说的没错,this指针是看不见的,但是却实际存在,实际上:
在类中,非静态成员函数 的 参数列表中 会 自动生成 this指针,this指针 指向该类创建的对象的内存空间(前面说了,类成员函数不占用类空间),指针的整体形式为:类名 *const this
我们可以看到this指针是默认不能被改变的,那么它既然是个指针,是怎么作用的呢?我们以前面用过的日期类来举例:
class Date{
public:
void Init(int year, int month, int day)
{
this -> _year = year;//this指针就是指向该类对象所生成的空间的地址
this -> _month = month;
this -> _day = month;
}
private:
int _year;
int _month;
int _day;
};我们可以看到this指针是默认指向类对象的成员变量的,既然this指针可以显示地写出来,那么是否也可以把this指针显示地放进形参里?我们可以尝试一下:
class Date{
public:
void Init(Date *const this, int year, int month, int day)
{
this -> _year = year;//this指针就是指向该类对象所生成的空间的地址
this -> _month = month;
this -> _day = month;
}
private:
int _year;
int _month;
int _day;
};![]()
我们可以看到其实是会报错的, 其实C++里规定了this指针可以在 类的非静态成员函数 里显示地写出来,但是不能再此函数的 参数列表中出现 ,这是编译器的工作。
2)this指针的特性
通过前面的例子我们可以总结出this指针的一些特性:
1、this指针只能在 类内 的 非静态函数 中存在与使用。
2、this指针前面有const,所以this指针是 不可 以被改变的。
3、this指针是 不存在类内 的,只是通过形参进行传递。
4、this指针不能显示的传。
上面的第三点其实很重要,this指针是不存在类的内部的,this指针的空间实际上是在寄存器上的。有些面试题也会考,如下:
【面试题1】【this指针存在哪里?】
答:编译器在生成程序时加入了获取对象首地址的相关代码。编译器有并把获取的首地址存放在了 寄存器 中。成员函数的其它参数都是存放在栈中。而this指针参数则是存放在寄存器中。类的静态成员函数没有this指针,所以不能调用类的内部成员变量。
【面试题2】【this指针能传空指针吗?】
答:如果只调用 类的静态成员函数 那就不会有任何影响,因为静态成员函数也不需要类内部成员变量,但是如果调用 非静态成员函数 的话就一定会发生 空指针引 用的报错,这点和C一样。
四、类的默认成员函数
我们在写任何类的时候,编译器都会默认生成六个默认的成员函数,每个成员函数在类里面都有着不同的作用,他们依次是:

六个函数在类里面都担当着相当重要的作用,那么他们具体的作用是什么?我们一个一个分析。
1)构造函数:
我们在写数据结构的时候,尤其像栈这种数据结构,这种我们需要再堆上开辟空间的数据结构,每次使用时必须要初始化,有时候可能会忘记调用初始化函数,虽然说这个错误很明显,但是越是小错误就越不容易被关注,然而我们的祖师爷关注到了(可能他有时候也会犯这种错误),每次创建对象后还要专门初始化一下,那为什么不在类内直接初始化呢?于是祖师爷就在C++中引入了构造函数。
那构造函数是什么呢?定义又是什么呢?我们来看一下前面的日期类:
#include
using namespace std;
class Date{
public:
/*void Init(int year, int month, int day)
{
_year = year;
_month = month;
_day = day;
}*/
Date(int year, int month, int day)
{
_year = year;
_month = month;
_day = day;
}
void Print()
{
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
int _year;
int _month;
int _day;
};
void Test()
{
Date d(2023, 10, 1);
d.Print();
return;
}
int main()
{
Test();
return 0;
} 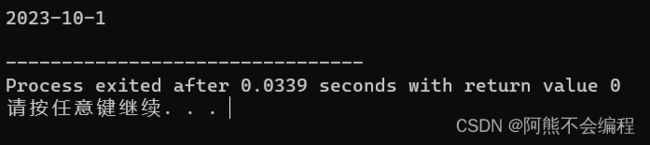
可以看到,我用一种与类名相同的函数代替了Init函数,我们可以发现这样也是可以通过编译的,也不需要自己手动调用就可完成初始化。这个函数其实就是所谓的构造函数。
那么构造函数的定义到底是什么呢?
·实际上,构造函数是特殊的成员函数,需要注意的是,虽然构造函数名字带有构造,但是构造函数的主要任务并不是开空间创造对象,而是初始化对象。
由上面的例子我们可以看得出构造函数的一些特征:
1、函数名与类名相同。
2、对象实例化时编译器自动调用对应的构造函数。
3、构造函数没有返回值。
4、构造函数可以重载。
相信你也看到了,我们在日期类进行类的实例化的时候其实是带括号的,而且通过参数可以传到构造函数的各个形参,我们之前在创建对象的时候没有带括号,那么这里是不是也可以不带?

我们发现必须要带参数才能传参,这样很不舒服,但是我们看一下特性的第四点,构造可以进行重载,那么我们就可以设置一个不带参数的构造来初始化。
#include
using namespace std;
class Date{
public:
Date()
{
_year = 1;
_month = 1;
_day = 1;
}
Date(int year, int month, int day)
{
_year = year;
_month = month;
_day = day;
}
void Print()
{
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
int _year;
int _month;
int _day;
};
void Test()
{
//Date d();
Date d;
d.Print();
return;
}
int main()
{
Test();
return 0;
} 在这里创建对象的时候就可以不带参数创建了,实际上,不带参编译器会默认调用传空参构造,这样也可以完成初始化任务。
每当这个时候,总会有人在创建对象的时候写成Test函数里注释的那部分,我们不妨放开注释跑一下代码:
我们会发现这样的写法编译器是会报错的,其实这是因为这样的创建方式和函数的声明发生冲突,编译器默认你调用带参构造,所以就会报错。
有时候或许你会觉得写两个构造函数看着很不舒服,能不能只写一个?答案是可以的,我们可以用前面学的 缺省值 来应用:
class Date{
public:
Date(int year = 1, int month = 1, int day = 1)
{
_year = year;
_month = month;
_day = day;
}
void Print()
{
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
int _year;
int _month;
int _day;
}; 如果有一天在写日期类的时候,你不小心忘记写构造函数了,这时候你在调用Print函数会发现: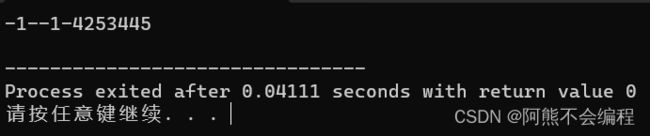
似乎出来的是随机值,其实我们没写构造函数的时候编译器是会默认生成构造函数的,只不过生成的默认构造赋给成员变量时是随机值。
但是你仔细想想,似乎又不对味了,既然编译器给你默认生成构造,还给的是随机值,那么这跟没用有什么区别,如写。实际上:
在C++中,类型被分为了 内置类型 和 自定义类型 ,其中内置类型为编译器给你的类型(由,int, char, double 以及任何指针 都属于内置类型),自定义类型是自己定义的类型(用struct,class,union等类型就叫自定义类型)。而编译器生成默认的构造函数是会对自定类型成员调用的它的默认构造函数,而内置类型不做处理。
2)析构函数:
既然编译器都帮助我们把构造函数写了,那么会不会有销毁的函数呢?毕竟 帮人帮到底,送佛送到西 嘛。别说,还真存在这样的函数————析构函数。
实际上,与构造函数功能相反,析构函数不是完成对象本身的销毁,局部对象销毁工作是由 编译器完成的。而对象在销毁时会 自动调用 析构函数,完成对象中的开辟的内存销毁工作。
析构函数的特点:
1、函数名与类名相同,并且需要再函数名前加上‘~’符号表示析构。
2、没参数没返回值。
3、没有重载。
4、只有用该类创建的对象 生命周期结束后,编译器才会自动调用析构函数。
虽然编译器会给我们默认生成析构函数,但是对于类成员有空间分配的情况是需要手写一个析构函数的,编译器不会帮你销毁你所开的空间,例如栈的数据结构要这样写:
typedef int DataType;
class Stack
{
public:
Stack(int capacity = 3)
{
_a = (DataType*)malloc(sizeof(DataType)* capacity);
if (NULL == _a)
{
perror("malloc");
exit(-1);
}
_capacity = capacity;
_top = -1
}
~Stack()
{
if (_a)
{
free(_a);
_a = nullptr;
_capacity = 0;
_top = -1;
}
}
private:
DataType* _a;
int _capacity;
int _top;
};我们如何来直观地感受到析构函数的调用呢?我们来看下面的代码:
#include
using namespace std;
class A{
public:
~A()
{
cout << "A" << endl;
}
};
class B{
public:
~B()
{
cout << "B" << endl;
}
};
class C{
public:
~C()
{
cout << "C" << endl;
}
};
class D{
public:
~D()
{
cout << "D" << endl;
}
};
C c;
int main()
{
A a;
B b;
static D d;
return 0;
} 我们设置4个空类,每个类里的析构都打印自己类的名字,我们可以想一想最后打印的顺序,这也能说明类的调用顺序。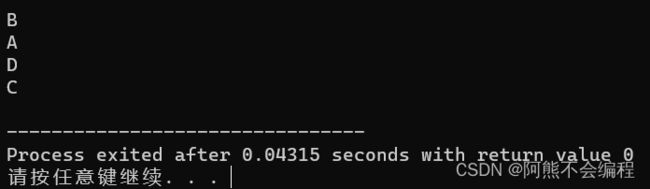
怎么样?你想对了吗?我们来具体逐步分析一下:
1、类的析构函数调用一般按照构造函数调用的相反顺序进行调用,但是要注意static对象的存在, 因为static改变了对象的生存作用域,需要等待程序结束时才会析构释放对象。
2、全局对象先于局部对象进行构造,局部对象按照出现的顺序进行构造,无论是否为static,所以构造的顺序为 c a b d。
3、析构的顺序按照构造的相反顺序析构,只需注意static改变对象的生存作用域之后,会放在局部 对象之后进行析构。
因此析构顺序为B A D C。
3)拷贝构造:
我们经常使用C语言来写函数,可是大家有没有想过,函数调用完之后就会销毁,那么我们是怎么得到函数的返回值的呢?例如:
#include
int Add(int x, int y)
{
return x + y;
}
int main()
{
int ret = Add(3, 4);
printf("%d\n", ret);
return 0;
} 难道你没有疑问吗,在函数销毁的时候为什么还能将值给正确返回出来?实际上函数在返回的时候出了作用域确实是会销毁的,但是编译器是会给函数 返回值 创建一个 临时变量 来保存函数的返回值,临时变量在赋值给ret。
其实不仅是函数如此,我们在C语言中常用的const,也是这个效果,例如:
#include
int main()
{
int ret = 0;
const char a = 3;
ret = a;
printf("%d\n",ret);
return 0;
} 
我们对const的变量进行强制类型转换实际上是不会改变const所引用变量的类型,实际上也和有返回值的函数一样,在这里会生成临时变量,临时变量记录const int a的类型转换之后的值,在由临时变量向要赋值的变量进行赋值。
我们在C++中对对象进行值传递,编辑器会给这个对象对应的类生成一个拷贝构造函数,将内容拷贝一份传给形参,默认的拷贝构造函数对象按 内存存储按 字节序完成拷贝,属于值传递,叫做浅拷贝(与之对应的是深拷贝,后面会提到)。
那么到底什么是拷贝构造呢?其实:
拷贝构造函数:函数名与类名相同,不需要返回值,只有 单个形参,该形参是对本类类型 对象的引用(有const修饰),在用 已存在 的类类型对象 创建新对象时由编译器自动调用。
既然拷贝构造编译器会帮你写出来,也就是说它也能和构造和析构一样能够被显示的写出来,在构造函数的定义里面我们可以看到 一个拷贝构造形参是本类的引用:
class Date{
public:
Date(int year = 1, int month = 1, int day = 1)
{
_year = year;
_month = month;
_day = day;
}
Date(const Date &d)//拷贝构造
{
_year = d._year;
_month = d._month;
_day = d._day;
}
void Print()
{
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
int _year;
int _month;
int _day;
};上面就是拷贝构造的完整写法,首先我们从内容来分析,将本类的成员变量拷贝一份给新的类,没什么问题(注意这里都是同一个类,不同的对象,只要在类内就能访问私有成员)。
那上面的形参为什么一定要是引用呢?而且还要加上const,我们不妨做个实验:
#include
using namespace std;
class Date{
public:
Date(int year = 1, int month = 1, int day = 1)
{
_year = year;
_month = month;
_day = day;
}
Date(Date d)
{
_year = this._year;
_month = this._month;
_day = this._day;
}
void Print()
{
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
int _year;
int _month;
int _day;
};
void GetDate(Date d)
{
d.Print();
}
void Test()
{
Date d;
GetDate(d);
}
int main()
{
Test();
return 0;
} 我们将拷贝构造改成传值传递,这样运行起来会发生什么呢?![]()
可以看到,这里编译器直接指定了你拷贝构造形参写错了,这是为什么?其实这样是会发生无穷递归的,我们知道类的对象在进行传值传递时会自动调用拷贝构造,但是如果拷贝构造也是形参,那么传值传递就会引发对象的拷贝,一直循环发生无穷递归。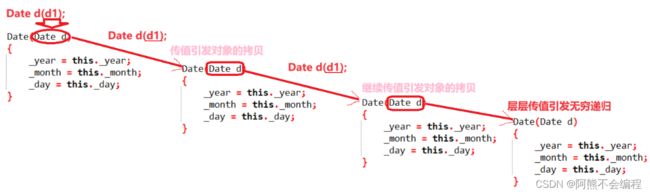
所以为了避免这种无穷递归的情况,拷贝构造的传值就为引用传值(注意:这里传指针虽然也可以,但是编译器是不会认为你为拷贝构造的)而且防止你赋值搞反了,一定要在引用前加上const这样保证不会改变原本对象。
同样的方式,对于栈这种数据结构, 编译器默认生成的构造会在调用时发生什么?
typedef int DataType;
class Stack
{
public:
Stack(int capacity = 10)
{
_a = (DataType*)malloc(capacity * sizeof(DataType));
if (nullptr == _array)
{
perror("malloc申请空间失败");
return;
}
_top = 0;
_capacity = capacity;
}
void Push(const DataType& data)
{
// CheckCapacity();
_a[_top] = data;
_top++;
}
~Stack()
{
if (_a)
{
free(_a);
_a = nullptr;
_capacity = 0;
_top = 0;
}
}
private:
DataType *_a;
int _top;
int _capacity;
};
int main()
{
Stack s1;
s1.Push(1);
s1.Push(2);
s1.Push(3);
s1.Push(4);
Stack s2(s1);
return 0;
} 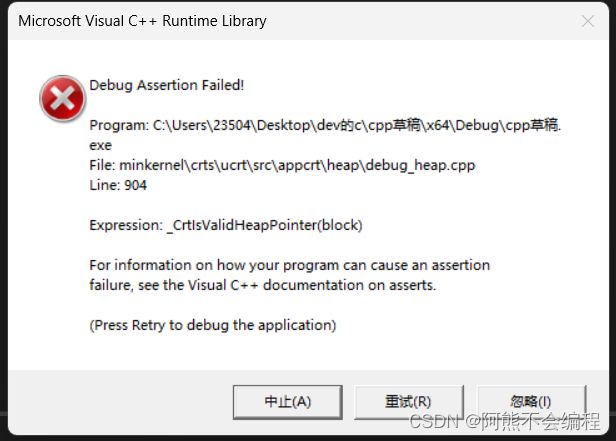
我们发现这个时候编译器默认的拷贝构造不仅不可以用了,甚至还发生了崩溃?!这是为什么呢?
其实,我们前面也说了,编译默认的拷贝构造是只会进行值传递方式拷贝,然而值传递对于像栈这种数据结构来说,指针_a也是值传递,也就是同一份地址的拷贝,而我们知道,在对象声明周期结束时会自动调用该类的析构函数,在首次函数传参的时候,函数结束时会调用一次析构函数,但是问题是这里拷贝的指针和原类的成员指针指向的是同一片空间,所以函数结束时调用析构会销毁这片空间,在原对象生命周期结束时又会调用一次析构函数,但是原来已经给指针是放过一次了,这里又再次对指针释放就造成一个空间多次释放的错误了。
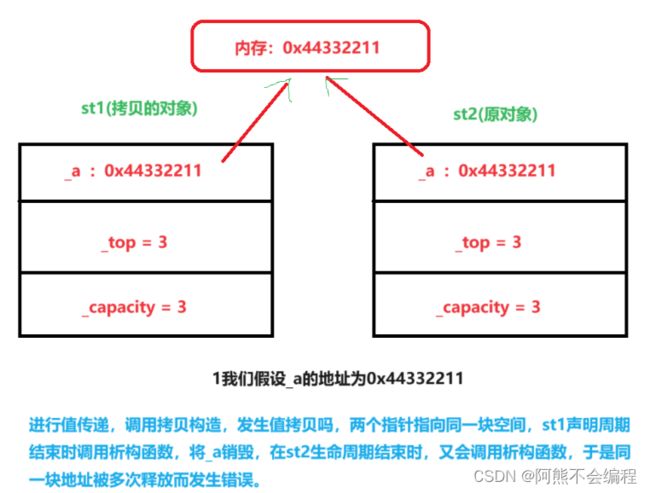
实际上,我们在对需要额外开空间的类通常都是自己写拷贝构造,而且对于要额外空间的成员变量重新开辟新的空间进行拷贝(也叫深拷贝),栈的拷贝构造正确写法如下:
Stack(const Stack &st)
{
_a = (int *)malloc(sizeof(int) * st._capacity);//新开辟一个空间这样就不会发生上面的错误
if(_a == NULL)
{
perror("malloc");
exit(-1);
}
_top = st._top;
_capacity = st._capacity;
}文章篇幅有点太长了,所以我决定剩下的内容放在【下】里面。

如果这篇文章对你有帮助的话,还望三连支持一下博主~~