论文《Masteing the game of Go without human knowledge》解读
1、整体解读
AlphaGo Zero中使用的是强化学习方法,使用的深度神经网络记为 fθ f θ (其中 θ θ 是网络的参数)。网络的输入是棋盘状态 s s (s s 中表示了当前玩家落子的信息,对手的落子信息,棋盘最后一步落子的信息,当前的棋盘转态谁是先手等信息,即棋盘的历史信息和当前信息)。网络的输出是 (p,v) ( p , v ) ,其中 p p 是当前玩家在局面s s 状态下,即将要选择落子到每一步的概率,所以 p p 是一个向量,假设局面是8*8的五子棋,则p p 是长度为64的向量,而 v v 则是一个标量的评估值,估计当前玩家从状态s s 获胜的概率, v v 的取值范围是v∈[−1,1] v ∈ [ − 1 , 1 ] ,从当前玩家的角度看, v=−1,0,1 v = − 1 , 0 , 1 分别代表当前玩家输了,平局,赢了(为了方便描述,下面的解读都以8*8的五子棋作为说明实例。)值得注意的是,这个网络将策略网络(输出 p p 的部分)和价值网络(输出v v 的部分)结合在一起而形成单一架构。该网络由许多具有批量归一化的卷积层和残余块等组成。

如图.1所示,在每一个 s s 的状态中都首先执行蒙特卡洛(MCTS)搜索得出每次即将要移动的概率π π ( π π 跟前面介绍的 p p 其实意义相同,只不过π π 是MCTS输出的结果,而 p p 是神经网络fθ f θ 输出的结果),这里的MCTS跟纯的MCTS搜索不同,它是在神经网络 fθ f θ 的指导下进行的搜索。(下面部分详细讲解)。
图1.a.Self-Play表示的过程如下:
假设 s1 s 1 是初始棋盘状态,当前玩家是1,玩家1在棋盘状态 s1 s 1 下准备落子,它不知道走哪一步是最佳的落子位置,所以先在 s1 s 1 的棋盘状态下,执行n次MCTS搜索,根据MCTS搜索得出的移动概率 π π 进行落子(这里 π π 的计算:(1)根据n次MCTS模拟对局产生的每个节点的访问次数得出概率向量p1,即访问最多的p1向量对应那个节点的概率就越大,p1中每个节点概率之和为1,(2)然后经过公式1的计算,即将每个节点的访问次数N通过公式(1)的变换在进行计算其概率,那么最终的概率是p2,如果 τ τ 一直取值1,则p2其实就是p1,其中 τ τ 为温度参数,控制探索的程度, τ τ 越大,不同走法间差异变小,探索比例增大,反之,则更多选择当前最优操作(3)将p2的每个节点概率即 pa p a 进行公式(2)变换,其中在论文中 ε=0.25 ε = 0.25 , ηa η a 是dirichlet分布,如公式(3)所示,这样做的目的是在一定程度上有助于覆盖到更多的局面)。当前玩家1在棋盘状态 s1 s 1 经过以上的执行n次MCTS搜索得出 π1 π 1 后,选择落子的方法就是按照概率 π1 π 1 的分布取出下一步移动 a1 a 1 ,然后进入下一个棋盘状态 s2 s 2 ,当前玩家交换为玩家2,不断重复上面步骤直到状态 st s t 分出胜负 z z ,这里z z 只有3种可能,赢,平局,输,分别对应1,0,-1。收集到的数据形式是 (si,πi,z) ( s i , π i , z ) 。
图1.b.Neural Network Training表示的过程如下:
上面收集到的数据 (si,πi,z) ( s i , π i , z ) ,实际上这里可以看出是监督学习的训练了,目标就是让策略网络输出的概率 p p 拟合π π ,价值网络的输出 v v 拟合z z 的过程。因为 π π 是在神经网络的指导下进行的,随着神经网络训练的增加, π π 的结果也越来越可靠,可以认为比 p p 稍微强些。
2、棋盘的表示
以8*8五子棋为例,假设s=4∗8∗8 s = 4 ∗ 8 ∗ 8 的矩阵表示, s[0] s [ 0 ] 用来表示当前玩家走过的位置,从棋盘状态为0到目前状态为止,走过的位置设置1,其他位置为0; s[1] s [ 1 ] 用来表示当前玩家的对手走过的位置,类似 s[0] s [ 0 ] ; s[2] s [ 2 ] 表示lastmove,即上一步落子的位置(上一步落子的一定是当前玩家的对手落子),即只有lastmove设置1,其他位置都是0; s[3] s [ 3 ] 表示当前玩家是否是先手,全部的位置要么设置1,要么设置0.
3、MCTS搜索
这里的MCTS搜索相比于纯MCTS搜索,最大的区别是当遇到叶子节点node(在纯MCTS中对应于一个子节点也未访问的节点)时候,(1)这里的MCTS搜索是在深度神经网络 fθ f θ 的指导下进行的,即未访问的节点的子节点的初始化为 fθ(s)=(p,v) f θ ( s ) = ( p , v ) ;此时,叶子节点node被展开,其价值为 v v ,下一步即将要走的概率为p p ,然后叶子节点node用这个 v v 值反向传播去更新从node节点到根节点的一条路径。如果在node节点处,当前局面s s 已经是分出胜负的局面,即node节点还没落子就结束局面,那么赢的一方就是上一个玩家,那么用 v=1 v = 1 值反向传播去更新从node节点到根节点的一条路径,即对于上一个玩家来说,node节点是价值很高的一步落子。由于玩家是交叉进行的,node节点用 v=1 v = 1 更新,那么node的父节点用 v=−1 v = − 1 更新,依次类推。(2)纯MCTS搜索则是在遇到叶子节点node时,判断在node节点下,哪些子节点是可以落子的,选择一个可以落子的子节点进行随机走,直到在node选择的该子节点中分出胜负,然后反向传播去更新从node节点到根节点的一条路径,注意更新的开始是node节点,如果结果是赢,则node节点的 v=1 v = 1 。当下一次模拟在遇到node时候,则还是选择一个node的子节点进行随机走直到分出胜负。纯MCTS搜索相比于借助神经网络的MCTS搜索,其效率比较低,因为一次模拟对局,它只展开node节点的一个子节点,而借助神经网络的MCTS搜索一次可以展开node所有子节点,然后下一次遇到node之后,则可以node是完全展开的节点了,可以继续往下走,走哪一步根据 Q(s,a)+U(s,a) Q ( s , a ) + U ( s , a ) 计算得出,Q,初始值都是0。其中U(s,a)正比于 P(s,a)/(1+N(s,a)) P ( s , a ) / ( 1 + N ( s , a ) ) ,如公式(4),该方法是PUCT算法的变种,这种搜索策略刚开始偏向高先验概率低访问频率的行动,后来逐渐偏好高行动价值的动作。而纯MCTS搜索需要将所有子节点访问后才可以。
总结MCTS搜索:
如图.2所示:
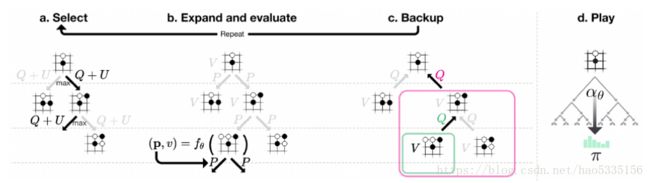
(1)Select选择阶段:
起始于树的根节点,当遇到叶子节点后终止,选择落子的依据是 Q(s,a)+U(s,a) Q ( s , a ) + U ( s , a ) 值最大的节点
(2)Expand and evaluate扩展评估阶段:
遇到叶子节点node,则把当前 s s 输入神经网络得出node节点的(p,v) ( p , v ) 信息,然后反向传播更新
(3)Backup回传阶段:
从叶子结点node开始回传边的统计量,其中搜索树中每一节点s针对合法操作保存以下数据结构 N(s,a),W(s,a),Q(s,a),P(s,a) N ( s , a ) , W ( s , a ) , Q ( s , a ) , P ( s , a ) 。其中 N(s,a) N ( s , a ) 是记录边的访问次数, W(s,a) W ( s , a ) 是合计的行动价值, Q(s,a) Q ( s , a ) 是平均行动价值, P(s,a) P ( s , a ) 是选择该条边的先验概率。
(4)Play落子阶段:
搜索结束后AlphaGo Zero在根节点 s 处选择a操作进行落子,在AlphaGo Zero论文中,每一个self-play对局的前30步,action是根据正比于MCTS根节点处每个分支的访问次数的概率采样得到的,即落子概率与访问次数成幂指数比例 π(a|s)=N(s,a)1/τ/∑bN(s,b)1/τ π ( a | s ) = N ( s , a ) 1 / τ / ∑ b N ( s , b ) 1 / τ 。其中 τ τ 为温度参数,控制探索的程度, τ τ 越大,不同走法间差异变小,探索比例增大,反之,则更多选择当前最优操作。而之后的exploration则是通过直接加上Dirichlet noise的方式实现的,如公式(2)(3),即在温度计算公式后进行公式(2)(3)的变换(在自我对弈收集数据时有这个操作,为了增加数据的多样性,在训练好的网络中不需要这一步)。最终得出 π π ,根据 π π 的概率分布选择落子。即,经过n次MCTS搜索模拟对局后,真正走出的一步落子。
4、优化的目标
loss=(z−v)2−πTlog(p)+c||θ|| l o s s = ( z − v ) 2 − π T l o g ( p ) + c | | θ | |
第一项:通过最小二乘最小化获胜概率误,第二项:通过交叉熵最大化先验走子概率与提升后走子概率一致性;第三项:L2范数权值衰减防止过拟合。
参考
1.AlphaGo Zero论文笔记
2.AlphaZero实战
3.Masteing the game of Go without human knowledge