【MySQL数据库】 六
本文主要介绍了数据库原理中数据库索引和事务相关概念.
一.索引
在查询表的时候,最基本的方式就是遍历表,一条一条筛选 .
因此,就可以给这个表建立索引,来提高查找的速度
比如,按照id建立索引
在数据库上额外搞一个空间维护一些id 相关的信息,
id:1 表的某个位置
id:2 表的某个位置
后续再按照id来查询,就不必直接遍历了,而是从索引中进行查询,根据索引就能够 , 初步判断锁定数据所在位置
索引,是用来提高查询效率的
1.缺陷
1.消耗额外空间
2.有可能拖慢增/删/改的速度
对于新增来说,不光要往表里写数据,同时还要修改索引
删除/修改,如果删除修改的条件,正好是和索引匹配还可以快点;如果涉及到索引列的删除/修改,这个时候也要需要维护索引
(好在大多数的业务场景中,是查询操作为主,增删改少很多,这种情况下,使用索引,就非常合适了 .
2.sql中使用索引
1.查看索引
show index from 表名;
- 对于class表,由于classid是主键,自动生成了一个索引
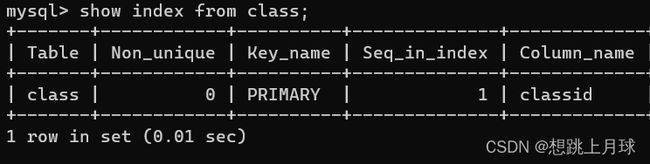
- 对于classes表,由于classid是unique,自动生成了一个索引
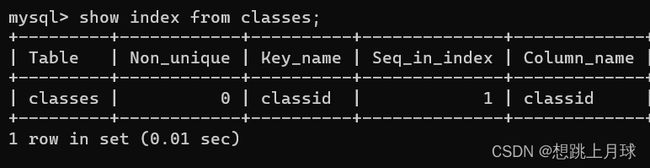
- 对于student表,由于classid是外键,也自动生成了索引
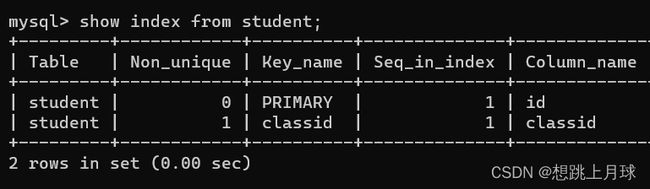
2.创建索引
手动创建索引
create index 索引名 on 表名 (字段名) ;
![]()
查看创建的索引
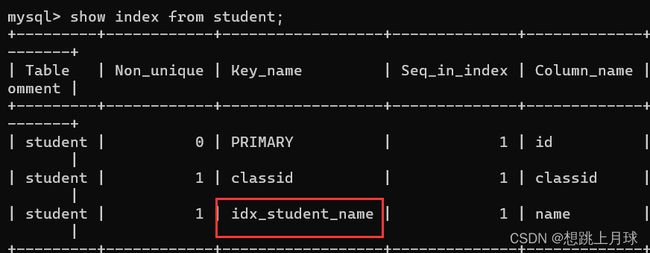
注意:
这个创建索引操作,可能会非常危险 !!
如果表是空的,或者表里的数据本身不多,创建索引,没关系;
如果表非空,并且包含了非常多的数据,创建索引,会引起非常大规模的硬盘IO操作,进一步就会导致数据库被卡死 !
3.删除索引
指定要删除的索引名和表名
drop index 索引名 on 表名;
![]()
删除索引,只能针对手动创建的索引 ; 自动生成的索引,是不能删除的;
如果需要给一个已经有很多数据的表创建/删除索引,并且这个数据库还是生产环境的数据库 ,怎么做 ?
冗余 !
数据库服务器往往不是单台服务器,为了整个系统的可靠性,通常会搞多个mysql服务器节点,这些节点的数据是一样的,能够提供相同的服务
因此可以先准备好一个新的mysql服务器,把表和索引都创建好,然后把数据都导入到新的服务器,再把要替换的mysql服务器关闭,把新的mysql服务器提上就行
其实sql除了增删改查之外,也支持一些其他的语法 (定义变量/条件/循环/函数)
但是并不建议使用复杂的sql
1.语法比较老了
2.不方便调试/优化
3.索引底层的数据结构
非常重要!!!!
mysql的索引的数据结构是什么样的数据结构?
不是一定的,取决于mysql使用哪个存储引擎
存储引擎
mysql里面包含很多模块
负责解析sql的
负责网络通信的
负责存储数据的 -- > 存储引擎 ,本质就是代码中的一个模块(包含了若干个代码文件)
具体如何存储数据,mysql支持多种存储方案
innodb当下最主流的一种方式
数据库组织数据使用的数据结构,是在硬盘上 !
对于内存上的数据结构,对于访问操作来说,是不敏感的;
但是硬盘上的数据结构,对于访问操作来说,比较敏感; 读写一次硬盘,开销远远大于内存
而索引,主要目的是为了进行快速查找 , 因此硬盘的读写对索引来说非常敏感 ! 太多的硬盘读写势必拖慢索引的速度 !
回忆学过的数据结构:
顺序表/链表/栈/队列/堆 都不行
1.哈希表
工作中最常用的数据结构
O(1)复杂度查询/插入/删除/修改数据
但是不适合数据库的查询场景
因为哈希表只能做精确查询,没法做到模糊查询和范围查询
2.红黑树
O(logN) 插入删除/修改/查询
也不适合数据库的查询场景
元素有序,可以处理范围查询
最大的问题,在于红黑树的高度,会在元素个数比较多的时候,变得比较高,因此会引入较多的硬盘IO
索引存储在硬盘上,每次比较都意味着硬盘IO操作
(1次硬盘IO操作相当于1万次内存IO操作)
上述讨论是针对mysql innodb存储引擎来讨论, 对于其他的存储引擎也可能会用到hash作为索引
3.B树
innodb使用的是B+树 , B+树是为了数据库量身定做的数据结构
要了解B+树,需要先了解B/B-树
B树的本质是是要给N叉搜索树
一个节点,可以保存多个key;
N个key可以延伸出N+1个分叉
(N个key可以划分出N+1)个区间
B树查询元素的流程:
拿着要查询的元素从根节点触发,判定要查找的元素是否在根节点上存在,
如果不存在,看这个元素是落在哪个区间里,就沿着这个区间的路线往下一个节点上找,最后找到叶子节点还不存在,就是真的不存在了.
此时每个节点上,都可以保存多个元素, 当总的元素个数固定,相比于二叉搜索树,涉及到的节点的总数就大大降低了,树的高度也大大降低了(B树的高度远远小于二叉搜索树的高度) , 因此进行查询的时候,硬盘IO的次数也随之减少了
注意:
对于数据库来说,每个节点,都需要把数据从硬盘上读出来才能进行比较 ;
但是一个节点有多个key,和一个节点有一个key,硬盘IO的开销是差不多的;
对于B树来说,进行插入和删除元素的时候,就涉及到拆分和合并的操作
一个节点,可以cun多个key,也不能无限的存,当存储的key数量达到一定程度的时候,
就需要把这个节点拆分,把这个节点的一部分key以书的子节点的方式来进行重新组织
拆分
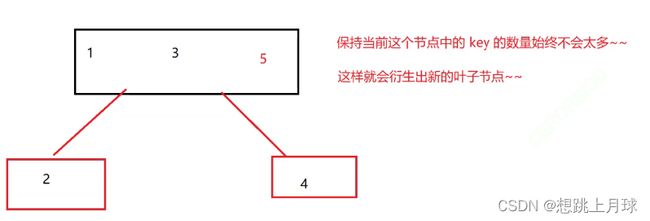
合并
当key变少了就可以合并成一个节点
4.B+树
数据库索引的主角,在B树的基础上,进一步作出了一些改进 (针对数据库查询)
1)B+树也是N叉搜索树
但是N个key分出了N个区间
其中节点上的最后一个key就是最大值了
2)父节点的key会在子节点中重复出现 (而且是以最大值的身份)
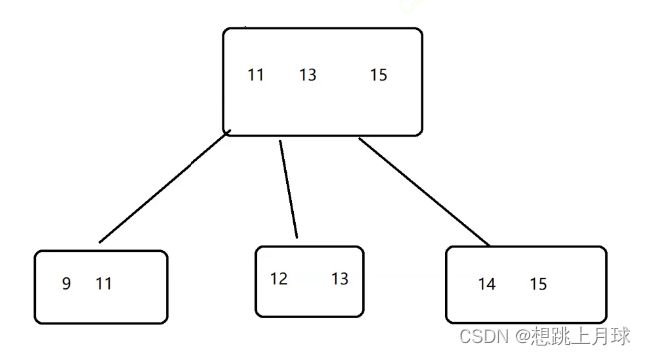
看起来重复了很多元素,浪费了空间
实际上能够达成一个重要的效果:叶子节点这一层,包含了整个数据的全集
3)叶子节点,按照链表的方式,首尾相连
此时就可以通过叶子节点之间的连接,快速找到下一个,上一个元素,进一步也方便进行范围查询
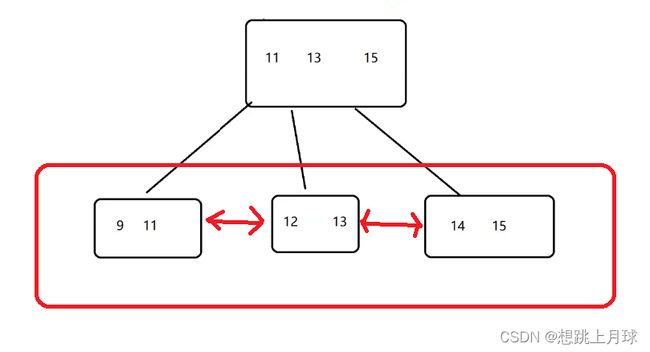
比如查询id>=5 and id<=12
只需要确定开头和结尾 , 把中间的这段子链表拎出来就是范围查询的结果
以上是三个B+树的特点
优势
1.特别擅长范围查询
2.所有的查询都会落在叶子节点上,比较次数是均衡的 , 查询时间是稳定的 !
有的时候,稳定比快更重要 .
3.由于叶子节点上的完整的数据全集 .
因此表的每一行数据的其他列,都可以保存在叶子节点上,而非叶子节点,只存储索引的key即可 (只保存id)
其实在物理层面上,不需要表格这样的数据结构,直接使用B+树来存储这个表的数据,只是用户看起来像表格而已
此时,非叶子节点的存储空间,消耗是非常小的 ,可以在内存中缓存一份 ;
因此进行数据查询的时候,就可以通过内存来直接进行比较, 从而更快速的找到叶子节点的记录,又进一步地减少了硬盘IO的次数 .
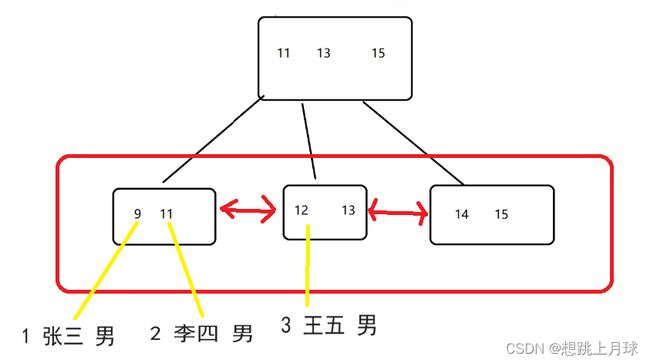
,
这里的面试题:
介绍一下对数据库索引的认识
这里的回答包含前面索引的这个章节的所有内容
二.事务
事务的本质就是为了把多个操作,打包成一个操作来完成 (让这多个操作,要么全都执行成功 , 要么就一个都不执行 --->原子性 )
注意:
"一个都不执行" 不是真的不执行
执行成不成功,得执行了才知道
假设事务中有三个操作
先执行1 ,再执行2 , 最后执行3
真正执行之前,是不知道123哪一步会失败
如果中间执行到中间出错了 , 就需要自动把之前前面已经成功执行的操作,进行还原,还原会最初没有执行的模样, 本质上,这里的"一个都不执行",指的是 看起来和 没执行一样
还原的这个过程,把它称作回滚 .
实现过程:
把事务中的执行的每个操作都记录下来,如果需要回滚,就直接按照操作的逆操作来执行就可以
事务 -> 原子性 -> 回滚 ->特定的日志
1.使用
1.开启事务
start transaction
输入多个sql语句
2.提交事务
commit
把这些sql按照原子的方式进行执行(带回滚机制)
3.rollback回滚
手动触发回滚
一个事务必须以这两个操作结尾 , 接下来的各种sql操作都会被认为是事务的一部分 .
上述操作,在开发中往往是通过程序代码的方式来操作事务 , 不会用命令来操作事务 , 并且差异很大
2.事务的基本特性
1.原子性
保证多个操作被打包成一个整体 , 要么全部正确执行 ,要不一个都不执行
2.一致性
事务执行之前和事务执行之后,数据都能对上 (约束/回滚机制)
3.持久性
执行的各种操作都是持久生效的(最终写入到磁盘中的)
一旦事务执行成功了,这里的所有操作产生的修改,都会写到硬盘里的
4.隔离性
并发执行事务的时候,隔离性会在执行效率和数据可靠之间做出权衡,
隔离 描述的是同时执行的事务之间相互的影响;
隔离性越高,并发性越低 ; 数据越可靠, 性能就越低 ;
3.并发
简称理解成同时执行 .
在并发执行事务的过程中,可能产生以下问题:
1.脏读
读到了事务提交之前的中间数(脏数据)
解决方法: 引入写加锁 . 提交之前,不能读
2.不可重复读
一个事务之内,多次读取同一个数据,发现数据不一样(读的过程中,另一个事务修改
了数据)
解决方法:引入读加锁. 读的时候,不能修改了
3.幻读
一个事务之内,多次读到的数据,值相同,但是结果集不同
解决方法: 彻底串行化,完全放弃并发执行
逐渐往下,隔离性越高,数据越可靠,并发程度越低,
咱们可以根据实际的需求场景,来决定使用哪个隔离级别,找到一个效率和可靠性都能接受的情况
4.事务的隔离级别
mysql提供了四种事务的隔离级别
1.read uncommitted (RU)
允许读未提交的数据 (存在脏读/不可重复读/幻读问题)
2.read committed (RC)
允许提交已经提交的数据(给写加锁了,解决了脏读,存在不可重复读/幻读 )
3.repeatable read(RR)
可以重复读取数据(写写操作和读操作都加锁,解决了不可重复读的问题,存在幻读问题)
4.serializable
事务彻底串行执行 (解决了脏读/不可重读读/幻读)
默认的事务级别是RR