这几天抽空搞了下spring cloud 1.x(2.0目前应该来说还不成熟),因为之前项目中使用dubbo以及自研的rpc框架,所以总体下来还是比较顺利,加上spring boot,不算笔记整理,三天不到一点围绕spring boot reference和spring microservice in action主要章节都看完并完整的搭建了spring cloud环境,同时仔细的思考并解决了一些spring cloud和书籍作者理想化假设的问题,有些在网上和官方文档中没有明确的答案,比如spring cloud sleuth如何使用log4j 2同时保留MDC。本文还会列出spring cloud和dubbo的一些异同和各自优劣势总结,两者应该来说各有优劣势,理想的架构如果各方面条件允许的话,其实可以结合spring cloud+dubbo或者自研的rpc。当然本文不会完完整整的讲解spring cloud整个技术栈的详细细节,但是对于核心要点以及关键的特性/逻辑组件会更多的评述组件的设计是否合理,如何解决,必要的会引述第三方资源,这和其他系列如出一辙。
在开始介绍spring cloud的架构之前,笔者打算先梳理下spring cloud生态的各个组件,因为对于很多新人甚至老鸟来说,初看起来,spring cloud的组件以及版本很乱,查看官方文档https://projects.spring.io/spring-cloud/(http://cloud.spring.io/spring-cloud-static/Edgware.SR3/single/spring-cloud.html,注:spring 5.0出来之后,pdf就没有了:(),我们可以发现如下:
相对于spring framework来说,spring cloud的组织更像是spring template各系列,独立发展,除了核心部分外,几乎各组件没有关联或者关联性很弱,他们只是基于这个框架,除非应用架构需要其特性,否则都不需要关心这些组件。对于微服务架构(假设使用 spring cloud的rpc)来说,只有两个必备:
- spring boot。spring cloud基于spring boot打包方式,所以spring boot是必备的,后面我们会详细讲解spring boot,实际上spring boot中的很多特性跟spring boot毫无关系,纯粹是设计者有意推广而不放在spring context或者spring context support中。
- spring cloud netflix。spring cloud netflix是netflix开源的一套微服务框架,它提供了微服务架构的核心功能,包括服务注册和发现中心Eureka、客户端负载均衡器Ribbon、声明式RPC调用Feign、路由管理Zuul、熔断和降级管理Hystrix。对于大部分的RPC框架来说,基本上都会提供除了熔断和降级管理外的所有特性,比如dubbo(http://dubbo.apache.org/)以及笔者在之前公司自行研发的rpc框架(https://gitee.com/zhjh256/io-spider)。
除了这两个核心组件外,下列组件通常在大型系统中会一起使用(中小型系统可能不会采用):
- spring cloud config。spring cloud config提供了集中式的配置管理中心,其存储支持文件系统和git。
- spring cloud sleuth/zipkin。spring cloud sleuth解决了分布式系统环境中日志的上下文关联和链路追踪问题。
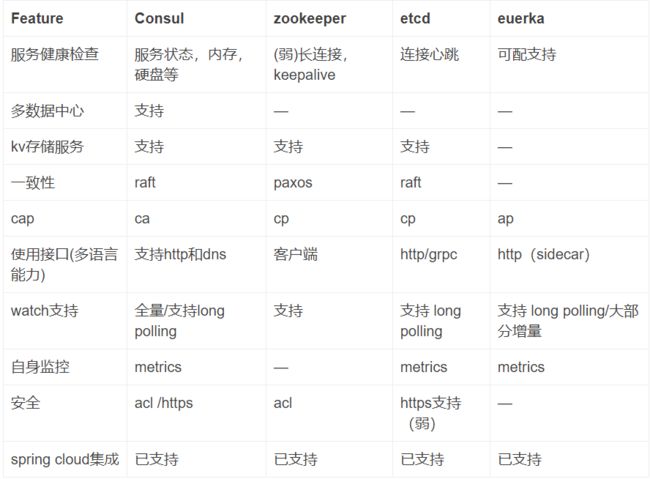
- spring cloud consul。spring cloud consul提供了另一种服务中心、配置中心选择。
在开始正式讲解spring cloud前,还不得不提下spring cloud组件的版本,由于spring cloud组件众多,且由不同的社区主导开发,因此spring cloud的版本命名跟eclipse类似,不是使用数字递增,而是采用城市名命名,每个spring cloud包含一系列的组件,通过查看spring-cloud-dependencies maven构件的定义,我们知道各自的版本。例如Edgware.SR3版本依赖的各组件版本如下:
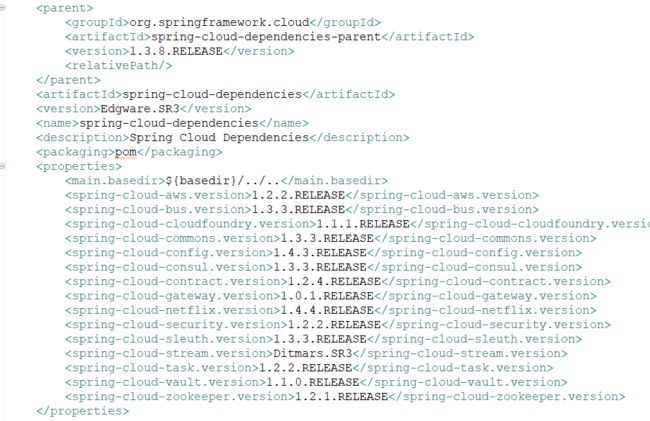
注:spring-cloud-dependencies是个应用一定会引入到dependencyManagement的依赖,它包含了特定版本的spring cloud组件的版本管理,直接引入可以省事很多。
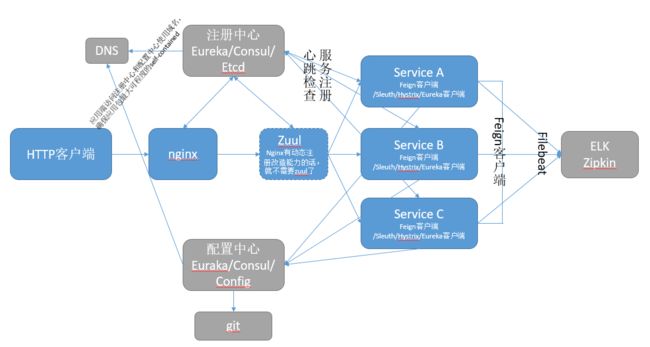
从上述对spring cloud各组件的梳理,我们可以知道完整的spring cloud架构如下:
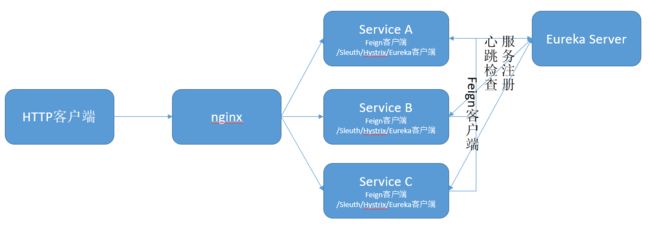
最简的spring cloud架构如下:
现在,我们来看下spring cloud的主要组件的核心功能以及dubbo中对应的特性。
- 在dubbo微服务框架内,ribbon/hystrix集成到了dubbo核心包中,turbine则在dubbo-admin和dubbo-monitor中。
-
zuul proxy就是网关AR(我们原来自研发的spider提供了该特性),这个组件在dubbo中没有对应的实现。
-
spring cloud config是分布式配置中心,dubbo开源版没有提供,阿里内部有个供HSF使用的diamon配置中心。Spring Cloud Config有自带的配置管理库,也可以和开源项目集成,包括:Consul,Eureka,zk(后面我们会看到各配置中心的优劣势)。Spring Cloud Config其实是一个基于spring boot的REST应用,不是一个单独第三方的服务器,可以嵌入在Spring Boot应用中,或者单独启动一个Spring Boot应用,其数据可以存储在文件系统中或者git仓库中。spring cloud配置中心的客户端实现原理比较简单,我们知道在spring框架中,是通过PlaceholderConfigurerSupport实现配置文件加载的,如果不使用spring cloud的配置中心,我们完全可以自己扩展PlaceholderConfigurerSupport,根据启动参数,从远程配置中心进行加载。
-
dubbo使用zk和dubbo-admin作为注册和治理中心,所以spring cloud netflix eureka就相当于zk和dubbo-admin,spring cloud也集成了使用zk作为服务注册和查找中心的组件。
-
在dubbo中,如果需要链路跟踪,我们需要自定义dubbo filter集成zipkin,dubbo自身没有提供这个机制。在spring cloud中,提供了可集成zipkin的Spring Cloud Sleuth,它的其中一个特性是增加跟踪ID到Slf4J MDC,这一点和笔者前面设计的日志框架出入一辙,无法做到跨节点追踪的集中日志平台都是耍流氓。
-
在dubbo中,我们可以通过声明式的@Reference注解来直接调用rpc服务,在spring cloud中,通过Feign,可以实现声明式调用,对于微服务开发来说,提供声明式的服务调用机制对开发效率是很重要的,它可以在编译阶段确保调用方和服务方接口一致。从技术实现来说,现代RESTFUL接口一般签名上出入参都是对象,如果把controller同时当做接口来用的话,实现声明式调用REST微服务也不是很难的事,关键是代码实现上,我们需要在编写controller接口的时候做些调整,跟service一样,实现接口的方式,后面我们会详细讲到。
=====================================
再重复一遍,spring cloud依赖于spring boot,所以不熟悉spring boot的同学,先掌握下spring boot,可参考笔者的写给大忙人spring boot 1.x学习指南。
有些书籍一开始就讲spring cloud config,有些书籍则几乎可以认为把官方文档翻译一遍 ,官方文档很多情况下对某些假设是很理想化的,所以,个人觉得有些时候就该有得放矢,不要追求大而全,很简单的就不要大谈特谈了。
服务注册与发现spring cloud netflix eureka

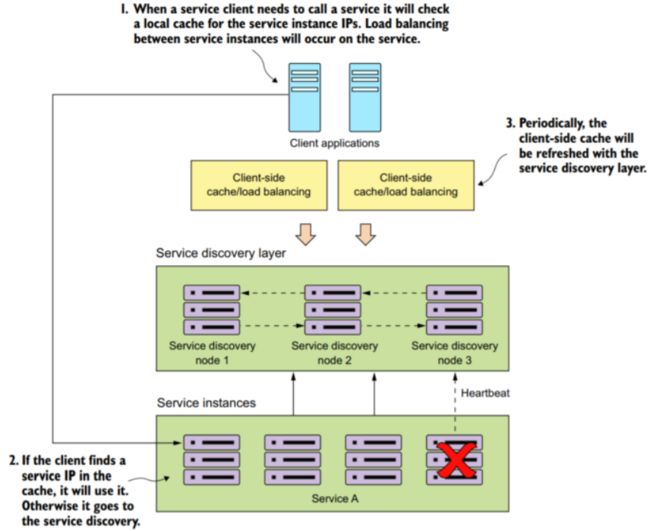
现在来看下服务的注册和调用。
- DiscoveryClient,最底层
- Ribbon-aware Spring RestTemplate,中间层
- Netflix Feign,最抽象,也是最高效的 (注:我们一般自研rpc框架的时候,也是这个思路,不过一般是两层,而不是三层)
由于在实际开发中,我们基本上使用Feign开发,所以,这里我们重点看Feign方式的RPC调用。
package com.thoughtmechanix.org.api; import org.springframework.cloud.netflix.feign.FeignClient; import org.springframework.web.bind.annotation.PathVariable; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestMethod; @FeignClient("organizationservice") public interface OrganizationService { @RequestMapping(value="/v1/organizations/{organizationId}",method = RequestMethod.GET) public Organization getOrganization( @PathVariable("organizationId") String organizationId); }
然后OrganizationService就可以被当做正常的spring bean使用了,如下:
package com.thoughtmechanix.licenses.controllers; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.beans.factory.annotation.Value; import org.springframework.web.bind.annotation.PathVariable; import org.springframework.web.bind.annotation.RestController; import com.thoughtmechanix.licenses.model.License; import com.thoughtmechanix.org.api.Organization; import com.thoughtmechanix.org.api.OrganizationService; @RestController public class LicenseServiceController implements LicenseService { private static final Logger logger = LoggerFactory.getLogger(LicenseServiceController.class); @Autowired private OrganizationService organizationService; @Override
@RequestMapping(value = "/v2/organizations/{organizationId}/licenses/{licenseId}", method = RequestMethod.GET) public Organization getLicensesInterface(@PathVariable("organizationId")String organizationId, @PathVariable("licenseId")String licenseId) { logger.info("调用远程Eureka服务!"); return organizationService.getOrganization(organizationId); } }
package com.thoughtmechanix.licenses; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.client.circuitbreaker.EnableCircuitBreaker; import org.springframework.cloud.context.config.annotation.RefreshScope; import org.springframework.cloud.netflix.eureka.EnableEurekaClient; import org.springframework.cloud.netflix.feign.EnableFeignClients; import org.springframework.context.annotation.ComponentScan; @RefreshScope @EnableFeignClients("com.thoughtmechanix.org.api") @EnableEurekaClient @SpringBootApplication @EnableCircuitBreaker @ComponentScan({"com.thoughtmechanix.licenses","com.thoughtmechanix.xyz.api"}) public class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); } }
注:这里有个特殊点,Feign的接口扫描路径定义在@EnableFeignClients注解的beanPackage属性上,而不是@ComponentScan注解上,否则如果Feign的接口不在主应用类所在的包或者子包下,就在启动时包bean找不到,如下所示:
Description:
Field organizationService in com.thoughtmechanix.licenses.controllers.LicenseServiceController required a bean of type 'com.thoughtmechanix.org.api.OrganizationService' that could not be found.
Action:
Consider defining a bean of type 'com.thoughtmechanix.org.api.OrganizationService' in your configuration.
[WARNING]
java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.springframework.boot.maven.AbstractRunMojo$LaunchRunner.run(AbstractRunMojo.java:527)
at java.lang.Thread.run(Thread.java:745)
Caused by: org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'licenseServiceController': Unsatisfied dependency expressed through field 'organizationService'; nested exception is org.springframework.beans.factory.NoSuchBeanDefinitionException: No qualifying bean of type 'com.thoughtmechanix.org.api.OrganizationService' available: expected at least 1 bean which qualifies as autowire candidate. Dependency annotations: {@org.springframework.beans.factory.annotation.Autowired(required=true)}
at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor$AutowiredFieldElement.inject(AutowiredAnnotationBeanPostProcessor.java:588)
at org.springframework.beans.factory.annotation.InjectionMetadata.inject(InjectionMetadata.java:88)
at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor.postProcessPropertyValues(AutowiredAnnotationBeanPostProcessor.java:366)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.populateBean(AbstractAutowireCapableBeanFactory.java:1264)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:553)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:483)
at org.springframework.beans.factory.support.AbstractBeanFactory$1.getObject(AbstractBeanFactory.java:306)
at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:230)
at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:302)
at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:197)
at org.springframework.beans.factory.support.DefaultListableBeanFactory.preInstantiateSingletons(DefaultListableBeanFactory.java:761)
at org.springframework.context.support.AbstractApplicationContext.finishBeanFactoryInitialization(AbstractApplicationContext.java:867)
at org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.java:543)
at org.springframework.boot.context.embedded.EmbeddedWebApplicationContext.refresh(EmbeddedWebApplicationContext.java:122)
at org.springframework.boot.SpringApplication.refresh(SpringApplication.java:693)
at org.springframework.boot.SpringApplication.refreshContext(SpringApplication.java:360)
at org.springframework.boot.SpringApplication.run(SpringApplication.java:303)
at org.springframework.boot.SpringApplication.run(SpringApplication.java:1118)
at org.springframework.boot.SpringApplication.run(SpringApplication.java:1107)
at com.thoughtmechanix.licenses.Application.main(Application.java:19)
... 6 more
Caused by: org.springframework.beans.factory.NoSuchBeanDefinitionException: No qualifying bean of type 'com.thoughtmechanix.org.api.OrganizationService' available: expected at least 1 bean which qualifies as autowire candidate. Dependency annotations: {@org.springframework.beans.factory.annotation.Autowired(required=true)}
at org.springframework.beans.factory.support.DefaultListableBeanFactory.raiseNoMatchingBeanFound(DefaultListableBeanFactory.java:1493)
at org.springframework.beans.factory.support.DefaultListableBeanFactory.doResolveDependency(DefaultListableBeanFactory.java:1104)
at org.springframework.beans.factory.support.DefaultListableBeanFactory.resolveDependency(DefaultListableBeanFactory.java:1066)
at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor$AutowiredFieldElement.inject(AutowiredAnnotationBeanPostProcessor.java:585)
... 25 more
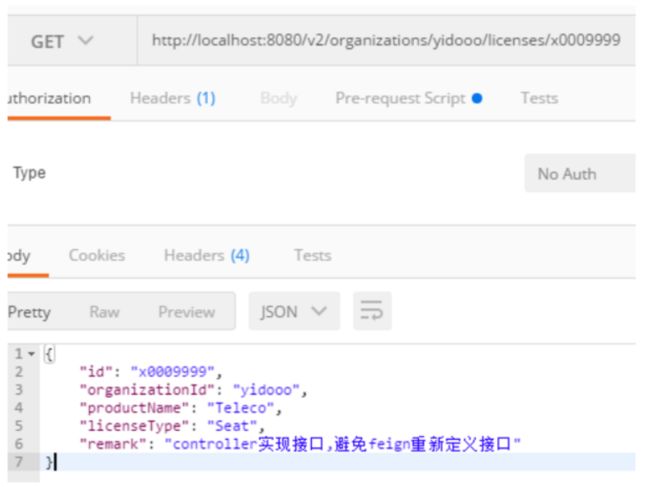
通过为controller定义要实现的接口,就做到了一次定义,多次引用(这和我们使用传统的spring mvc开发不同,建议把RequestMapper定义在接口上)。
所以,从使用上来说,Feign很简单,对于有过其他RPC开发经验的同学来说,就是换个注解而已。
熔断、降级和服务隔离Netflix Hystrix
我记得dubbo和其他rpc在这一块做的不是特别好,虽然spring cloud提供了该特性、而且很灵活,但是它有个关键设计很鸡肋,后面会讲到。
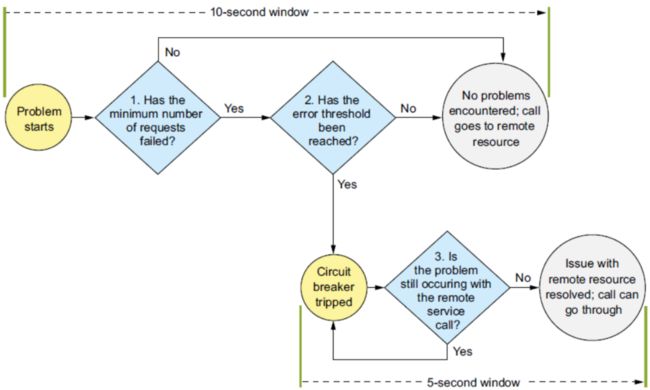
在spring cloud的微服务架构中,一个请求调用经过的节点内关键步骤如下:
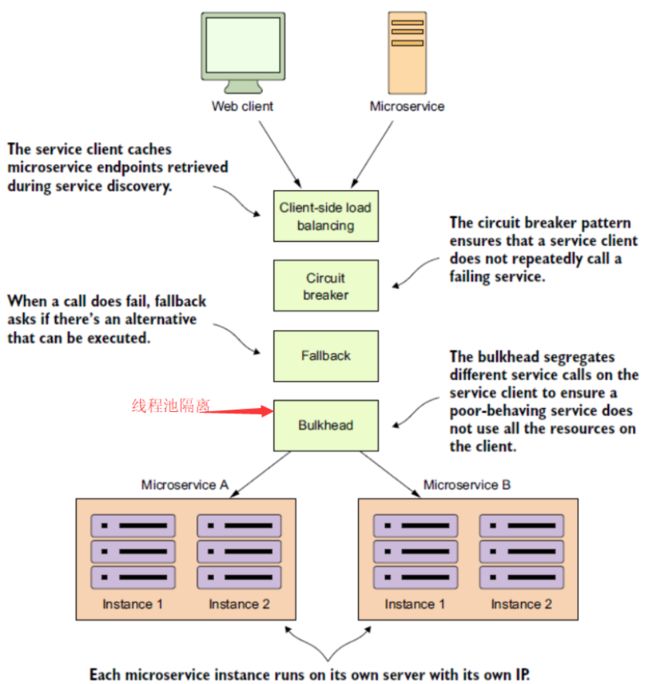

合理的隔离机制应该是可以自定义线程池数量,以及哪些服务放在哪个线程池。如下:
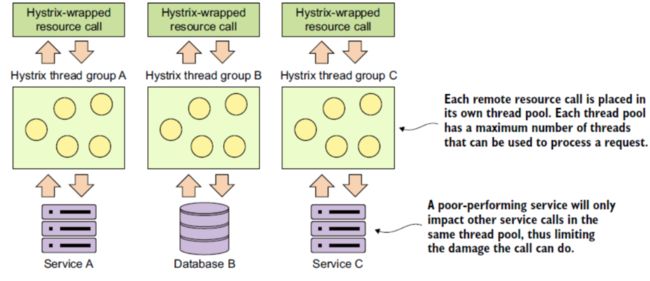
自然,Hystrix提供了按需配置线程池的接口。@HystrixCommand注解的threadPoolKey和threadPoolProperties属性就是用来指定线程池的,包括线程池名称、大小、队列长度(就线程池而言,最重要的就是名称,核心大小,最大大小,队列长度)。如下:
@HystrixCommand(fallbackMethod = "buildFallbackLicenseList",
threadPoolKey = "licenseByOrgThreadPool",
threadPoolProperties = {
@HystrixProperty(name = "coreSize",value="30"),
@HystrixProperty(name="maxQueueSize", value="10")
}) public ListgetLicensesByOrg(String organizationId){ return licenseRepository.findByOrganizationId(organizationId);
)
- 自定义Hystrix Concurrency Strategy类
- 定义一个Callable类,将UserContext注入Hystrix Command
- 配置Spring Cloud使用自定义的Hystrix Concurrency Strategy类
线路熔断
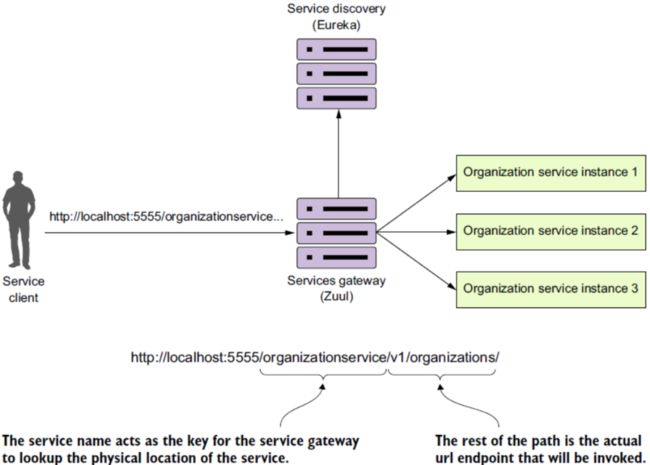
服务路由zuul
<dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-starter-zuulartifactId> dependency>
@SpringBootApplication @EnableZuulProxy public class ZuulServerApplication { public static void main(String[] args) { SpringApplication.run(ZuulServerApplication.class,args); } }
eureka:
instance:
preferIpAddress: true
client:
registerWithEureka: true
fetchRegistry: true
serviceUrl:
defaultZone: http://localhost:8761/eureka/
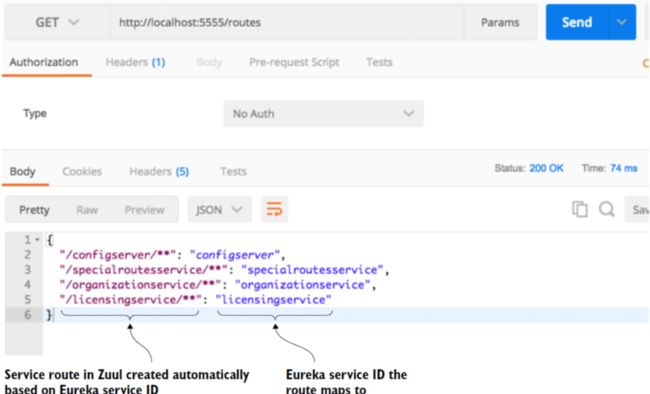
Zuul路由配置
- 基于服务中心自动路由(大规模使用)
- 使用服务中心手工路由(A/B测试使用)
- 根据静态url路由(历史兼容使用)
分布式日志聚合Spring Cloud Sleuth
- 透明在服务调用上创建和注入相关ID(dubbo没有提供现成的功能,需要自行基于dubbo filter实现)
- 在服务调用之间透传相关ID
- 增加相关ID到Spring’s MDC,Spring Boots的默认SL4J和Logback会自动包含相关ID,log4j则不会自动包含(参考本博客spring boot系列的日志部分)。
- 可选的,发布跟踪信息到Zipkin
要启用Spring Cloud sleuth,只要在pom文件中包含下列依赖即可:
<dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-starter-sleuthartifactId> dependency>
- 服务的应用名
- 全局跟踪ID
- 当前请求段ID
- 是否发送到zipkin的标记

![]()
分布式配置中心spring cloud config
<dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-starter-configartifactId> dependency> <dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-config-serverartifactId> dependency>
package com.thoughtmechanix.confsvr; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.config.server.EnableConfigServer; @SpringBootApplication @EnableConfigServer public class ConfigServerApplication { public static void main(String[] args) { SpringApplication.run(ConfigServerApplication.class, args); } }
然后在application.yml中设置存储信息,如下:
server:
port: 8888
spring:
profiles:
active: native
cloud:
config:
server:
native:
searchLocations: file:///D:/spring-cloud-example/config/
这样运行spring-boot:run就可以启动配置中心服务了。
注意,这里需要注意点的是,路径大小写敏感,否则可能出现一直访问不到配置文件,但是没有报错信息。
D:/spring-cloud-example/config/下包含如下配置文件:
tracer.property: "I AM THE DEFAULT FROM CONFIG CENTER" spring.jpa.database: "POSTGRESQL" spring.datasource.platform: "postgres" spring.jpa.show-sql: "true" spring.database.driverClassName: "org.postgresql.Driver" spring.datasource.url: "jdbc:postgresql://database:5432/eagle_eye_local" spring.datasource.username: "postgres"
我们可以使用postman访问如下:
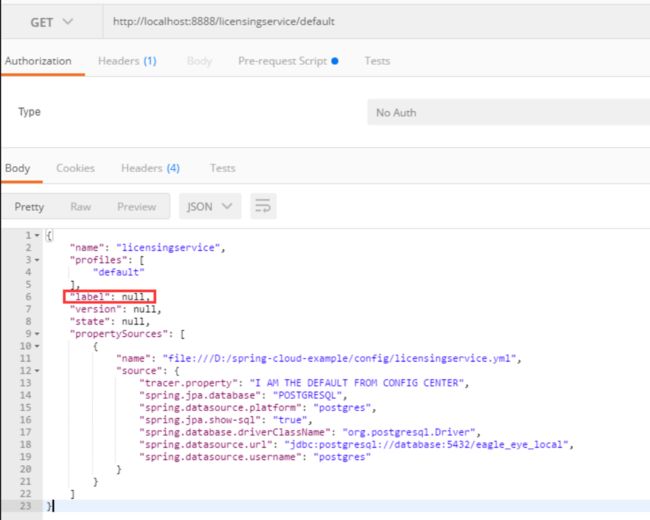
这样,基于文件存储的配置中心就搭建好了。
目前,spring cloud config支持使用文件系统和git作为存储,git的配置可以参考官方文档。
- /{application}/{profile}[/{label}]
- /{application}-{profile}.yml
- /{label}/{application}-{profile}.yml
- /{application}-{profile}.properties
- /{label}/{application}-{profile}.properties
<dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-starter-configartifactId> dependency>
因为所有的配置信息都不在本地,所以我们需要一种机制告诉spring boot去哪里找配置中心,因此spring boot提供了一个bootstrap.yml配置文件,其中定义了使用哪个应用、哪个profile的配置,以及服务器地址。如下所示:
spring:
application:
name: licensingservice
profiles:
active: default
cloud:
config:
uri: http://localhost:8888
在spring boot应用启动的时候,在执行任何bean的初始化前,会先加载bootstrap.yml文件,读取配置,然后再进行其他初始化和加载工作。
这样配置中心的配置就和原来properties中一样,被加载到Environment中了,@Value就可以正常注入了。
@SpringBootApplication @RefreshScope public class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); } }
management: security: enabled: false