Vue的常见性能优化
这里写目录标题
- 编码阶段
-
-
- 不要在模板里面写过多表达式
- 尽量减少 data 中的数据。
- 对象层级不要过深,否则性能就会差
- computed 和 watch 区分使用场景
- SPA 页面采用 keep-alive 缓存组件
- 频繁切换的使用 v-show,不频繁切换的使用 v-if
- v-for 遍历必须加 key,key 最好是 id 值,且避免同时使用 v-if
- 使用路由懒加载、异步组件
- 防抖、节流运用
- 第三方模块按需导入
- 大数据列表和表格性能优化 - 虚拟列表/虚拟表格
-
- 搜索引擎 SEO 优化
-
-
- 预渲染
- 服务端渲染 SSR,nuxt.js
-
- 打包优化
-
-
- 压缩代码
- 使用 CDN 加载第三方模块
- 多线程打包 happypack
- splitChunks 抽离公共文件
-
- 用户体验
-
-
- 骨架屏
-
编码阶段
不要在模板里面写过多表达式
<template>
<div id="app">
<p>{{ flag?'a:'b' }}</p> //少一点
<button @click="exchange">转换</button>
</div>
</template>
尽量减少 data 中的数据。
data 中的数据都会增加getter 和 setter,会收集对应的watcher,值改变时整个应用会重新渲染,可以使用computed (当新的值需要大量计算才能得到,缓存的意义就非常大)
- data后续不使用的数据,使用Object.freeze()。这样可以避免vue初始化时候,做一些无用的操作,从而提高性能
data(){
return{
//直接调用为浅冻结
list:Object.freeze({'我不需要改变'})
}
}
//深冻结
//Object.freeze()原理
//Object.definedProperty()
Object.defineProperty(person, 'name', {
configurable: false,//能否修改属性的特性
enumerable: false,// 是否可以枚举。默认true
writable: false,// 能否修改属性值。默认true
value: 'xm'// 表示属性的值。访问属性时从这里读取,修改属性时,也保存在这里。
})
//Object.seal()
//实现不能删除,不能新增对象属性
function myFreeze(obj) {
if (obj instanceof Object) {
Object.seal(obj);
let p;
for (p in obj) {
if (obj.hasOwnProperty(p)) {
Object.defineProperty(obj, p, {
writable: false
});
myFreeze(obj[p]);
}
}
}
}
对象层级不要过深,否则性能就会差
computed 和 watch 区分使用场景
- v-if 和 v-for 不能连用
当和 v-for 一起使用时,v-for 的优先级比 v-if 更高;
//哪怕我们只渲染一小部分元素,也得在每次重新渲染的时候遍历整个列表。如果 list 的数据有很多,就会造成性能低,页面可能卡顿的现象出现。
<div v-for="item in list"
v-if="item .show"
:key="item.id">
</div>
//每一次都这样运算
this.list.map( item=> {
if (item.active) {
return item.name
}
});
//解决办法
//1.使用空标签 template.
<template v-for="item in list" >
<div v-if="show" :key="item .id">
{{item.name}}
</div >
</template>
//2.使用compted过滤属性
computed:{
items:function(){
return this.list.filter(item=>{
return item.show
})
}
}
SPA 页面采用 keep-alive 缓存组件
- 两个生命周期钩子:activated 与 deactivated
activated在组件第一次渲染时会被调用,之后在每次缓存组件被激活时调用
deactivated:组件被停用(离开路由)时调用
注意:使用了keep-alive就不会调用beforeDestroy(组件销毁前钩子)和destroyed(组件销毁),因为组件没被销毁,被缓存起来了。
//不缓存查询条件和查询结果
mounted: function() {
this.loaddata(1)
},
activated: function () {
this.productclass.name=""//查询条件
this.loaddata(1) //查询结果的方法
}
//使用include或者exclude(优先级更高) 首先匹配name
<!-- 逗号分隔字符串 -->
<keep-alive include="a,b">
<router-view></router-view>
</keep-alive>
<!-- 数组 -->
<keep-alive :include="['a', 'b']">
<router-view></router-view>
</keep-alive>
//使用了LRU算法,简而言之,就是要缓存实例时,会创建一个缓存key,并在缓存中查找是否已有值,如果有,则直接取出用,
//v-if 缓存部分页面或者组件
//第一次打开页面的时候并不缓存,即第一次从列表页跳到详情页,再回来并没有缓存,后面在进入详情页才会被缓存
//并且只会缓存第一次进入的状态,不会重新请求数据,项目只有一种状态需要缓存,可以考虑使用这种方法
//需求:一个List页面,只有从对应的Detial返回(跳转到列表)时,页面被缓存,而当从其余地方跳转到这个List组件时,页面都会被重新加载
// home.vue
<template>
...
<keep-alive>
<router-view v-if="$route.meta.keepAlive"></router-view>//被缓存
</keep-alive>
<router-view v-if="!$route.meta.keepAlive"></router-view>//不被缓存
</template>
//router.js
//给vue定义name,首字母需要大写
export default new Router({
routes: [
{
path: '/',
name: 'Aa',
component: a,
meta: {
keepAlive: false // 不需要缓存
}
},
{
path: '/b',
name: 'Bb',
component: b,
meta: {
keepAlive: true // 需要被缓存
}
}
]
})
//在路由守卫钩子中,控制页面是否缓存
//List.vue
export default {
// 从List页面离开时,修改keepAlive值为false,保证进入该页面时页面刷新
beforeRouteLeave(to, from, next) {
from.meta.keepAlive = false
next()
}
}
//Detail.vue
export default {
// 从Detail返回List时,修改List的keepAlive为true, 确保返回List页面时使用缓存不刷新页面
// 因为离开List时,keepAlive被设置为了false;所以这时候不管从哪里进入到List页面,都是没有keep-alive缓存的;而在Detail离开的时候,又将List对应的keepAlive设置为了true,所以从Detail进入到List 就实现了页面缓存
beforeRouteLeave(to, from, next){
if(to.name === 'List') {
to.meta.keepAlive = true
}
next()
}
}
小提示:
有缓存页面生命周期:
如果是第一次进入:created->mounted->activated
不是第一次进入:activated
如果既想实现页面状态的保存,还想实现返回页面后重新请求接口数据实现页面数据的刷新,
可以将请求数据的方法放入到activated生命周期中进行请求,页面重新进入后执行activated,可以实现页面数据的刷新去掉缓存
频繁切换的使用 v-show,不频繁切换的使用 v-if
v-for 遍历必须加 key,key 最好是 id 值,且避免同时使用 v-if
key存在意义:为了跟踪每个节点的特征,使其具有唯一性,高效更新虚拟dom
vue在更新已经渲染的元素序列时,会采用就地复用策略,都会在对顺序进行破坏时,不仅会产生真实dom更新,浪费资源,耿永导致产生错误更新。
比如两个inputAB输入值,在头部添加一个InputC,结果按顺序,CA有值,B无值。
使用路由懒加载、异步组件
- 路由懒加载
{
path:'./about',
name:'About',
component:() => import('../views/Aboout.vue')//在此处引入为懒加载
}
只有在使用该路由时才加载路由。可缩减首屏加载时间。
防抖、节流运用
| 类型 | 场景 |
|---|---|
| 函数防抖 | 搜索框输入(只需要最后一次输入完成后再放松Ajax请求) |
| - | 滚动事件scroll(只需要执行触发后的最后一次滚动事件的处理程序) |
| - | 连续点击按钮事件 |
| - | 窗口resiz改变事件 |
| - | 文本输入的验证(连续输入文字后发送Ajax请求进行验证,停止输入后验证一次) |
| 函数节流 | DOM元素的拖拽功能实现(mousemove) |
| - | 游戏中的刷新率,比如射击游戏,就算一直按着鼠标射击,也只会在规定射速内射出子弹 |
| - | Canvas画笔功能 |
| - | 鼠标不断触发某事件时,如点击,只在单位事件内触发一次. |
- 防抖
在事件被触发n秒后再执行回调,如果在这n秒内又被触发,则重新计时
防抖类似于王者英雄回城6秒,如果回城被打断,再次回城需要再等6秒
应用场景
//定义方法要做的事情
function fun(){
console.log('我改变啦')
}
//定义事件触发要执行的方法,两个参数分别是传入的要做的事情和定时器的毫秒数
function debounce(fn,delay){
//定义一个变量作为等会清除对象
var flay=null;
//使用闭包防止每次调用时将flay初始化为null;
return function(){
//在这里一定要清除前面的定时器,然后创建一个新的定时器
clearTimeout(flay)
//最后这个定时器只会执行一次
//事件触发完成之后延迟500毫秒再触发
//(这里的变量赋值是跟定时器建立连接,进行地址赋值,要重新赋值给flay
//重新设置新的延时器
flay=setTimeout(function(){
fn.apply(this); //修正fn函数的this指向
},delay)
}
}
//给浏览器添加监听事件resize
window.addEventListener('resize', debounce(fun, 500));
- 节流
节流 规定在给定时间内,只能触发一次函数。如果在给定时间内触发多次函数,只有一次生效
节流类似于王者技能,放完一个英雄技能后,要6秒才能再次释放
//时间戳
//fn为需要执行的函数,wait为需要延迟的时间
function throttle(fn,wait){
//记录上一次函数触发的时间
var pre = Date.now();
//使用闭包能防止让pre 的值在每次调用时都初始化
return function(){
var context = this;
var args = arguments;
//arguments 对象包含了传给函数的所有实参
//arguments 是函数调用时传入的参数组成的类数组对象
//func(1, 2),arguments 就约等于 [1, 2]
var now = Date.now();
if( now - pre >= wait){
//修正this的指向问题
fn.apply(context,args);
//将时间同步
pre = Date.now();
}
}
}
//定义要做的事情
function handle(){
console.log(Math.random());
}
//触发函数
window.addEventListener("mousemove",throttle(handle,1000));
//定时器
function throttle(fn,wait){
var timer = null;
return function(){
var context = this;
var args = arguments;
if(!timer){
timer = setTimeout(function(){
fn.apply(context,args);
timer = null;
},wait)
}
}
}
function handle(){
console.log(Math.random());
}
window.addEventListener(“mousemove”,throttle(handle,1000));
第三方模块按需导入
大数据列表和表格性能优化 - 虚拟列表/虚拟表格
//虚拟列表
//html
<div ref="Wrap" @scroll="scrollListener">
<div ref="Bar"></div>
<ul ref="list">
<li v-for="(val,index) in showList" :key="index">{{val}}</li>
</ul>
</div>
//js
//构造一个超长列表
// data
list: [],//超长的显示数据
itemH: 30,//每一列的高度
showNum: 10,//显示几条数据
start: 0,//滚动过程显示的开始索引
end: 10,//滚动过程显示的结束索引
// computed
//显示的数组,用计算属性计算
showList(){
return this.list.slice(this.start, this.end);
},
//mounted
for (let i = 0; i < 1000000; i++) {
this.list.push('列表' + i)
}
//计算滚动容器高度
this.$refs.Wrap.style.height = this.itemH * this.showNum + 'px';
//计算总的数据需要的高度,构造滚动条高度
this.$refs.Bar.style.height = this.itemH * this.list.length + 'px';
//methods
scrollListener(){
//获取滚动高度
let scrollTop = this.$refs.Wrap.scrollTop;
//开始的数组索引
this.start = Math.floor(scrollTop / this.itemH);
//结束索引
this.end = this.start + this.showNum;
//绝对定位对相对定位的偏移量
this.$refs.list.style.top = this.start * this.itemH + 'px';
}
//虚拟表格
//当存在不需要分页,并且数据量较多的表格场景时,因渲染大量数据、页面结构造成页面渲染过慢,出现卡顿。就产生了虚拟表格
- 图片懒加载
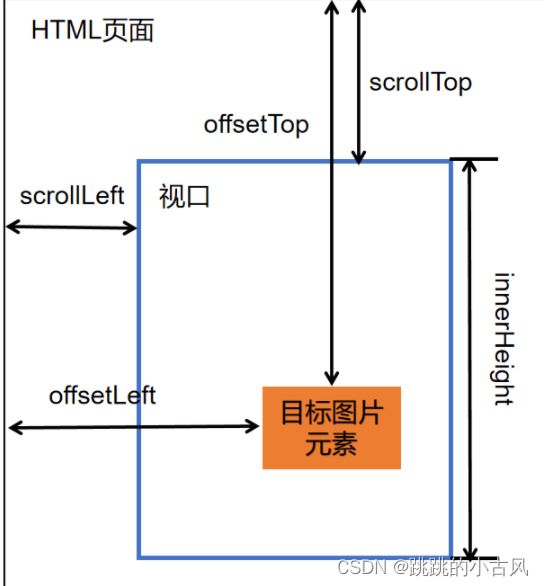
- 1.监听scroll+scrollTop+offsetTop+innerHeight
监听scroll事件,当图片出现在可视区时,将data-src值赋值给src,加载图片,在图片未加载时,用alt 属性,在图像无法显示时的替代文本
scrollTop(网页元素被滚动条卷去的部分)
offsetTop(元素相对父元素的位置)
innerHeight(当前浏览器窗口的大小)
//HTML
<div>
<img class="lazy-load" data-src="```" alt="">
<img class="lazy-load" data-src="`" alt="">
<img class="lazy-load" data-src="```" alt``="">
<img class="lazy-load" data-src="```" alt="">
</div>
// 引入 lodash 库
<script src="https://cdn.bootcss.com/lodash.js/4.17.12-pre/lodash.core.min.js"></script>
//js
let lazyImages = [...document.querySelectorAll('.lazy-load')]
let inAdvance = 300
function lazyLoad() {
lazyImages.forEach(image => {
var clietH = window.innerHeight || document.documentElement.clientHeight || document.body.clientHeight;
var scrollTop = document.documentElement.scrollTop || window.pageYOffset || document.body.scrollTop;
let eleTop = item.offsetTop
let count = scrollTop + clietH - eleTop
if (count > 0) {
image.src = image.dataset.src; // //从data-url中取出真实的图片地址赋值给scr
}
})
}
lazyLoad();
window.addEventListener('scroll', _.throttle(lazyLoad, 50))
window.addEventListener('resize', _.throttle(lazyLoad, 50))
//data-src,它是自定义属性,可以在 js 里通过 dataset 获得它的属性值;
// _.throttle 函数,它是一个节流函数,引用自 lodash 库,因为监听 scroll 滚动以及 resize 窗口改变事件会不断地触发,过于频繁,所以使用节流函数让其每隔一段时间执行,节省开销。
- 2 .监听scroll getBoundingClientRect()
Element.getBoundingClientRect() 方法返回元素的大小及其相对于视口的位置。
返回对象(width,height,top,left,right,bottom)
function lazyLoad() {
lazyImages.forEach(image => {
var clietH = window.innerHeight || document.documentElement.clientHeight || document.body.clientHeight;
Array.from(imgs).forEach((item) =>{
let ele = item.getBoundingClientRect()
if (ele.top > 0 && ele.top < clietH) {
item.setAttribute('src',item.getAttribute('data-url'))
}
})
})
}
- 3 .Intersection Observer API
针对元素的可见时间进行监听
var io = new IntersectionObserver(callback, option);
// 开始观察
io.observe(document.getElementById('example'));
// 停止观察
io.unobserve(element);
// 关闭观察器
io.disconnect();
//intersectionRatio:目标元素的可见比例,即intersectionRect占 boundingClientRect的比例,完全可见时为1,完全不可见时小于等于0
//target:被观察的目标元素,是一个 DOM 节点对象
// 观察器实例
let io = new IntersectionObserver((entires) =>{
entires.forEach(item => {
// 原图片元素
let oImg = item.target
if (item.intersectionRatio > 0 && item.intersectionRatio <= 1) {
oImg.setAttribute('src', oImg.getAttribute('data-url'))
}
})
})
// 给每一个图片设置观察器
Array.from(lazyImages).forEach(element => {
io.observe(element)
});
搜索引擎 SEO 优化
预渲染
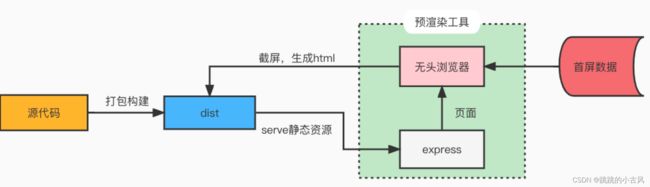
vue是一个单页面应用(spa),只有一个 html 文件(内容只有一个#app根节点),通过加载js脚本来填充页面要渲染的内容,然而这种方式无法被爬虫和百度搜索到。
构建阶段生成匹配预渲染路径的 html 文件(注意:每个需要预渲染的路由都有一个对应的 html)。构建出来的 html
文件已经有静态数据,需要ajax数据的部分未构建
解决问题
- SEO:单页应用的网站内容是根据当前路径动态渲染的,html 文件中往往没有内容,网络爬虫不会等到页面脚本执行完再抓取;
- 弱网环境:当用户在一个弱环境中访问你的站点时,你会想要尽可能快的将内容呈现给他们。甚至是在 js 脚本被加载和解析前;
- 低版本浏览器:用户的浏览器可能不支持你使用的 js 特性,预渲染或服务端渲染能够让用户至少能够看到首屏的内容,而不是一个空白的网页。
//1.安装预渲染插件
npm install prerender-spa-plugin -D #安装或者编译出错,npm换成cnpm
//一个 webpack 插件用于在单页应用中预渲染静态 html 内容。因此,该插件限定了你的单页应用必须使用 webpack 构建,且它是框架无关的,无论你是使用 React 或 Vue 甚至不使用框架,都能用来进行预渲染。
//原理:在 webpack 构建阶段的最后,在本地启动一个 phantomjs,访问配置了预渲染的路由,再将 phantomjs 中渲染的页面输出到 html 文件中,并建立路由对应的目录。
//2.配置vue.config.js
const path = require('path')
const PrerenderSPAPlugin = require('prerender-spa-plugin')
const Renderer = PrerenderSPAPlugin.PuppeteerRenderer
module.exports = {
configureWebpack: {
plugins: [
new PrerenderSPAPlugin({
// 生成文件的路径,与webpack打包一致即可
// 这个目录只能有一级,如果目录层次大于一级,在生成的时候不会有任何错误提示,在预渲染的时候只会卡着不动。
staticDir: path.join(__dirname, 'dist'),
// 需要预渲染的路由
// 对应自己的路由文件
routes: ['/', '/about'],
// 这个很重要,如果没有配置这段,也不会进行预编译
renderer: new Renderer({
inject: {
foo: 'bar'
},
//renderer.headless为表示是否以无头模式运行,无头即不展示界面,如果设置为false,则会在浏览器加载页面时候展示出来,一般用于调试
headless: false,
//renderer.renderAfterTime可以让控制页面加载好后等一段时间再截图,保证数据已经都拿到,页面渲染完毕
renderAfterTime: 5000,
// 在 main.js 中 document.dispatchEvent(new Event('render-event')),
//两者的事件名称要对应上。在程序入口执行
renderAfterDocumentEvent: 'render-event',
})
})
]
}
}
//4.修改main.js
new Vue({
el: '#app',
router,
components: { App },
template: '小知识:seo为啥对vue单页面不友好?
- 爬虫在爬取的过程中,不会去执行js,所以隐藏在js中的跳转也不会获取到。
- vue通过js控制路由然后渲染出对应的页面,而搜索引擎蜘蛛是不会去执行页面的js的,导致搜索引擎蜘蛛只能收录index.html一个页面,在百度中就搜索不到相关的子页面的内容。
- 我们加载页面的时候,浏览器的渲染包含:html的解析、dom树的构建、cssom构建、javascript解析、布局、绘制,当解析到javascript的时候才回去触发vue的渲染,然后元素挂载到id为app的div上,这个时候我们才能看到我们页面的内容,所以即使vue渲染机制很快我们仍然能够看到一段时间的白屏情况,用户体验不好。
服务端渲染 SSR,nuxt.js
服务端渲染:网页上面呈现的内容在服务器端就已经生成好了,当用户浏览网页时,服务器把这个在服务端生成好的完整的html结构内容响应给浏览器,而浏览器拿到这个完整的html结构内容后直接显示(渲染)在页面上的过程
SSR=> 后端把.vue文件编译成.html文件返回给前端渲染,它的好处就是有利于SEO
打包优化
压缩代码
- 代码压缩
//安装uglifyjs-webpack-plugin插件,
//可以去除项目中console.log和debugger
npm install uglifyjs-webpack-plugin --save
//vue.config.js
const UglifyJsPlugin = require('uglifyjs-webpack-plugin')
// 生产环境相关配置
if (isProduction) {
// 代码压缩
config.plugins.push(
new UglifyJsPlugin({
uglifyOptions: {
//生产环境去除console等信息
compress: {
warnings: false, // 若打包错误,则注释这行
drop_debugger: true,//是否移除debugger
pure_funcs: ['console.log']//移除console
}
},
sourceMap: false,
parallel: true
})
)
}
- gzip压缩
可以优化http请求,提高加载速度,gzip 可以压缩所有的文件
npm install compression-webpack-plugin --save-dev
//vue.config.js
const CompressionPlugin = require("compression-webpack-plugin");
// 开启gzip压缩 在webpack的plugins里配置
config.plugins.push(
new CompressionPlugin({
filename: '[path].gz[query]', // 使得多个.gz文件合并成一个文件,这种方式压缩后的文件少
algorithm: 'gzip', // 使用gzip压缩
test: /\.js$|\.html$|\.css$/, // 匹配文件名 这里对js、html、css文件进行了压缩处理
// threshold: 10240, // 对超过10k的数据进行压缩
threshold: 5120, // 对超过5k的数据进行压缩
minRatio: 0.8, 压缩率小于1才会压缩
cache: true, // 是否需要缓存
deleteOriginalAssets:false // true删除源文件(不建议);false不删除源文件
}
))
//运行打包命令 npm run build
文件加内出现.gz文件就代表打包成功
小知识,后台也要配置哦
在服务器我们也要做相应的配置 如果发送请求的浏览器支持gzip,就发送给它gzip格式的文件
//后端通过nginx开启gzip压缩
gzip on;
gzip_min_length 80k;
gzip_buffers 4 16k;
gzip_comp_level 5;
gzip_types text/plain application/javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png;
//后端通过express开启gzip压缩
const compression = require('compression')
app.use(compression()) // 在其他中间件使用之前调用
使用 CDN 加载第三方模块
让信息更快地达到目标用户的分发技术和缓存设备
比如淘宝就是普通服务器,地址在哪,发货地就在哪,服务器部署在哪里,就从哪里提供服务,而cdn就是京东,在各地有仓库,根据买家地址调配最近仓库配送。
多线程打包 happypack
在使用 Webpack 对项目进行构建时,会对大量文件进行解析和处理。当文件数量变多之后,Webpack 构件速度就会变慢。由于运行在 Node.js 之上的 Webpack 是单线程模型的,所以 Webpack 需要处理的任务要一个一个进行操作。
而 Happypack 的作用就是将文件解析任务分解成多个子进程并发执行。子进程处理完任务后再将结果发送给主进程。所以可以大大提升 Webpack 的项目构件速度
由于 JavaScript 是单线程模型,要想发挥多核 CPU 的能力,只能通过多进程去实现,而无法通过多线程实现。
npm install happypack --save-dev
//webpack.config.js
//将常用的 loader 替换为 happypack/loader,并创建 HappyPack 插件
const HappyPack = require('happypack');
module.exports = {
...
module: {
rules: [
test: /\.js$/,
// use: ['babel-loader?cacheDirectory'] 之前直接使用 loader
// 现在替换成 happypack/loader,并使用 id 指定创建的 HappyPack 插件
use: ['happypack/loader?id=babel'],
// 排除 node_modules 目录下的文件
exclude: /node_modules/
]
},
plugins: [
...,
new HappyPack({
/*
* 必须配置
*/
// id 标识符,要和 rules 中指定的 id 对应起来
id: 'babel',
// 需要使用的 loader,用法和 rules 中 Loader 配置一样
// 可以直接是字符串,也可以是对象形式
//loaders: ['babel-loader?cacheDirectory'],
//单loader 指定的目录将用来缓存 loader 的执行结果。之后的 webpack 构建,将会尝试读取缓存,来避免在每次执行时,可能产生的、高性能消耗的 Babel 重新编译过程(recompilation process)
loaders: [ 'style-loader', 'css-loader', 'less-loader' ]
//多个 loader
})
]
}
splitChunks 抽离公共文件
在没配置任何东西的情况下,webpack 4 就智能的帮你做了代码分包。入口文件依赖的文件都被打包进了main.js,那些大于 30kb
的第三方包,如:echarts、xlsx、dropzone等都被单独打包成了一个个独立 bundle。
其它被我们设置了异步加载的页面或者组件变成了一个个chunk,也就是被打包成独立的bundle,比如我们的workbook页面,是以运用了懒加载路优酷加载的。
内置的代码分割策略是这样的:
- 新的 chunk 是否被共享或者是来自 node_modules 的模块
- 新的 chunk 体积在压缩之前是否大于 30kb
- 按需加载 chunk 的并发请求数量小于等于 5 个
- 页面初始加载时的并发请求数量小于等于 3 个
缺点 - main.js里面既有node_modules的包,还有src下的业务代码,并且除了main,几乎每个bundle都是这样包含node_modules和src下的代码
- 每次业务代码的变动会导致bundle的hash变化,JS文件缓存失效,要重新下载,但是node_modules下的文件根本没有变动,也会一起重新打包。
SplitChunks是Webpack中一个提取或分离代码的插件,主要作用是提取公共代码,防止代码被重复打包,拆分过大的js文件,合并零散的js文件。
默认规则
- 新代码块可以被共享引用,或这些模块都是来自node_modules
- 新产出的vendor-chunk的大小得大于30kb
- 按需加载的代码块(vendor-chunk)并行请求的数量小于或等于5个
- 初始加载的代码块,并行请求的数量小于或者等于3个
npm install webpack-bundle-analyzer --save-dev
//SplitChunks 插件会提取模块并打包生成js文件 所以先给打包生成的js文件命名
//vue.config.js
module.exports = {
configureWebpack:{
//单入口的 Vue项目中
entry:'./src/main.js',//打包前
output:{ //打包后
filename: 'js/appCS.js',
// chunkFilename: 'CS.[name].js'//非入口文件
},
//多入口的 Vue项目中
entry: { appCS: './src/main.js' },
output:{ filename: 'js/[name].js' },
//[name] 是入口文件模块名称 此方法会多个app.js
},
// 去掉 app.js 要用 chainWebpack 来配置:
chainWebpack: config =>{
config.entryPoints.delete('app').end().entry('appCS').add('./src/main.js')
}
optimization: {
splitChunks: {
chunks: 'async', // 仅提取按需载入的module
//all: 统一将文件分离。当页面首次载入会引入所有的包
//async:将异步加载的文件分离,首次一般不引入,到需要异步引入的组件才会引入。
//initial:将异步和非异步的文件分离,如果一个文件被异步引入也被非异步引入,那它会被打包两次(注意和all区别),用于分离页面首次需要加载的包。
// chunks (chunk) {
//return chunk.name !== 'test' && chunk.name !== 'math'
// } 当splitChunks.chunk为一个函数时,可以自行选择哪些chunk需要被分离
minSize: 30000, // 文件最小打包体积,提取出的新chunk在两次压缩(打包压缩和服务器压缩)之前要大于30kb
//比如说某个项目下有三个入口文件,a.js和b.js和c.js都是100byte,当我们将minSize设置为301,那么webpack就会将他们打包成一个包,不会将他们拆分成为多个包
maxSize: 0, // 提取出的新chunk在两次压缩之前要小于多少kb,默认为0,即不做限制
minChunks: 1, // 被提取的chunk最少需要被多少chunks共同引入
maxAsyncRequests: 5, // 最大按需载入chunks提取数
maxInitialRequests: 3, // 最大初始同步chunks提取数
automaticNameDelimiter: '~', // 默认的命名规则(使用~进行连接)
//假设我们生成了一个公用文件名字叫vendor,a.js,和b.js都依赖他,并且我们设置的连接符是"~"那么,最终生成的就是 vendor~a~b.js
name: true,
cacheGroups: { // 缓存组配置,默认有vendors和default
vendors: {
test: /[\\/]node_modules[\\/]/,
priority: -10
},
default: {
minChunks: 2,
priority: -20,
reuseExistingChunk: true
}
}
},
//配置 runtimeChunk 会给每个入口添加一个只包含runtime的额外的代码块,name 的值也可以是字符串,不过这样就会给每个入口添加相同的 runtime,配置为函数时,返回当前的entry对象,即可分入口设置不同的runtime。
runtimeChunk: {
name: entrypoint => `manifest.${entrypoint.name}`
}
}
};
小知识:打包详细分布查看
npm install --save-dev webpack-bundle-analyzer
将打包后的内容用canvas以图形的方式展示出来,借助这个工具,我们可以知道每个chunk由哪些模块组成,非常方便好用
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
module.exports = {
...
plugins: [
...
new BundleAnalyzerPlugin()
]
}

小知识:webpack三大个概念,module、chunk和bundle?
- module:每个import引入的文件就是一个模块(也就是直接手写的代码)
- chunk:当module源文件传到webpack进行打包时,webpack会根据文件引用关系生成chunk(也就是module在webpack处理时是chunk)
- bundle:是对chunk进行压缩等处理后的产出(也就是打包后可以直接运行的文件
webapck拆分出的chunk有四种:
- 根据入口文件拆分
- 根据异步文件拆分(import(‘…’))
- 根据spliteChunk拆分
- 还有一些运行时runtimeChunk,负责
形如 import(‘abc’).then(res=>{}) 这种异步加载的代码,在webpack中即为运行时代码
每次更改所谓的运行时代码文件时,打包构建时app.js的hash值是不会改变的。如果每次项目更新都会更改app.js的hash值,那么用户端浏览器每次都需要重新加载变化的app.js,如果项目大切优化分包没做好的话会导致第一次加载很耗时,导致用户体验变差。现在设置了runtimeChunk,就解决了这样的问题。所以 这样做的目的是避免文件的频繁变更导致浏览器缓存失效,所以其是更好的利用缓存。提升用户体验。
具体描述可参考下面这个博主的,很详细!https://blog.csdn.net/napoleonxxx/article/details/81975186
用户体验
骨架屏
在页面内容未加载完成的时候,先使用一些图形进行占位,待内容加载完成之后再把它替换掉。在这个过程中用户会感知到内容正在逐渐加载并即将呈现,降低了“白屏”的不良体验。
npm install vue-skeleton-webpack-plugin --save
//由于骨架屏插件依赖服务端渲染,再安装vue-server-renderer
npm install vue-server-renderer
//src目录下创建 skeleton.vue 要显示的页面
<template>
<div class="skeleton-wrapper">
<section class="skeleton-block">
<img src="">
<img src="">
</section>
</div>
</template>
<script>
export default {
name: 'skeleton'
};
</script>
<style scoped>
</style>
//src目录下创建entry-skeleton.js文件
import Vue from 'vue'
// 创建的骨架屏 Vue 实例
import skeleton from './skeleton';
export default new Vue({
components: {
skeleton
},
template: '