CNN算法实现图像分类
1、引言
本文涵盖两个主题:
- 了解CNN模型的基本概念;
- 使用Fashion-MNIST数据集实时实现CNN模型;
该数据集包含70,000张28x28像素的灰度图片,共涵盖10个类别的时尚物品,包括衬衫、运动鞋、裤子等,以便更好地理解和掌握卷积神经网络模型的基本原理和实践应用。
本期内容『数据+代码』已上传百度网盘。有需要的朋友可以关注公众号【小Z的科研日常】,后台回复关键词[CNN]获取。
2、CNN模型基本概念
卷积神经网络的三个基本组件:卷积层、池化层、输出层。让我们详细看看它们中的每一个。

2.1 卷积层
在此层中,如果我们有一个大小为 6 x 6 的图像。我们定义了一个权重矩阵,它从图像中提取某些特征。
我们已将权重初始化为 3 x 3 矩阵。现在,该权重应穿过图像,以便至少覆盖一次所有像素,以提供卷积输出。上述值429,是通过将权重矩阵3和输入图像的突出显示3部分的逐元相乘得到的值相加得到的。
6 x 6 图像现在转换为 4 x 4 图像。将权重矩阵想象成画墙的画笔。画笔首先水平绘制墙壁,然后向下并水平绘制下一行。当权重矩阵沿图像移动时,将再次使用像素值。这基本上可以在卷积神经网络中实现参数共享。
让我们看看这在真实图像中的样子。
- 权重矩阵的行为类似于图像中的过滤器,从原始图像矩阵中提取特定信息。
- 粗细组合可能是提取边缘,而另一个可能是特定的颜色,而另一个可能只是模糊不需要的噪音。
- 学习权重,使损失函数最小化并从原始图像中提取特征,这有助于网络进行正确的预测。
- 当我们使用多个卷积层时,初始层提取更多的通用特征,随着网络的深入,特征变得越来越复杂。
在进一步深入之前,让我们在这里了解一些概念:
什么是步幅?
如上所示,我们在整个图像上移动的过滤器或权重矩阵一次移动一个像素。如果这是一个在图像上一次移动 1 个像素的权重矩阵的超参数,则称为 1 的步幅。随着步幅值的增加,图像的大小不断减小。
用零填充输入图像可以为我们解决这个问题。我们还可以在图像周围添加多层零,以防步幅值较高。我们可以看到在用零填充图像后如何保留图像的初始形状。这称为相同的填充,因为输出图像与输入图像具有相同的大小。这被称为相同的填充(这意味着我们只考虑输入图像的有效像素)。中间的 4 x 4 像素将是相同的。在这里,我们保留了来自边框的更多信息,并保留了图像的大小。
CNN具有多个过滤器:
- 权重的深度维度将与输入图像的深度维度相同。
- 权重延伸到输入图像的整个深度。
- 具有单个权重矩阵的卷积将导致具有单个深度维度的卷积输出。在多个过滤器的情况下,所有过滤器都应用了相同的尺寸。
- 每个滤波器的输出堆叠在一起,形成卷积图像的深度维度。
假设我们有一个大小为 32 x 32 x 3 的输入图像。我们应用了 10 个尺寸为 5 x 5 x 3 的过滤器,并带有有效的填充。输出的尺寸为 28 x 28 x 10。
2.2 池化层
如果图像很大,我们需要减少可训练参数的数量。为此,我们需要在卷积层之间使用池化层。池化用于减小图像的空间大小,并在每个深度维度上独立实现,因此图像深度没有变化。在这里,我们将步幅定为 2,而池大小也为 2。最大操作应用于卷积输出的每个深度维度。
2.3 输出层
有时很难理解每个卷积层末尾的输入和输出维度。为此,我们将使用三个超参数来控制输出体积的大小。
- 过滤器数量:输出音量的深度将等于应用的过滤器数量。激活映射的深度将等于过滤器的数量。
- 步幅:当我们有一个步幅时,我们会在单个像素上移动。对于较高的步幅值,我们一次移动大量像素,因此产生的输出体积更小。
- 零填充:这有助于我们保留输入图像的大小。如果添加单个零填充,则单个步幅滤镜移动将保留原始图像的大小。
我们可以应用一个简单的公式来计算输出尺寸。
输出图像的空间大小可以计算为( [W-F+2P]/S)+1。其中,W 是输入卷大小, F是过滤器的大小, P 是应用的填充数 S 是步数。
让我们以大小为 64 x 64 x 3 的输入图像为例,我们应用 10 个大小为 3 x 3 x 3 的过滤器,单步幅且无零填充。
这里 W=64, F=3, P=0 和 S=1。输出深度将等于应用的滤波器数量,即 10。
输出的大小将为 ([64-3+0]/1)+1 = 62。因此,输出将为62 x 62 x 10。
- 由于没有卷积和填充层,我们需要类形式的输出。
- 为了生成最终输出,我们需要应用一个完全连接的层来生成一个等于我们需要的类数的输出。
- 卷积层生成 3D 激活图,而我们只需要输出图像是否属于特定类。
- 输出层具有类似于分类交叉熵的损失函数,用于计算预测中的误差。前向传递完成后,反向传播开始更新权重和偏差,以减少误差和损失。
3、CNN模型实现
数据描述:
- 每张图像高 28 像素,宽 28 像素,总共 784 像素。
- 每个像素都有一个与之关联的像素值,指示该像素的明暗度,数字越大表示越暗。此像素值是介于 0 和 255 之间的整数。
- 训练和测试数据集有 785 列。
- 第一列由类标签组成,表示服装的物品。
- 其余列包含关联图像的像素值。
为了在图像上定位一个像素,假设我们已经将 x 分解为 x = i * 28 + j,其中 i 和 j 是介于 0 和 27 之间的整数。像素位于 28 x 28 矩阵的第 i 行和第 j 列上。例如,pixel31 表示左起第四列和顶部第二行中的像素。
3.1 数据预处理
现在观察到第一列是标签数据,因为它有 10 个类,所以它将有从 0 到 9.其余列是实际的像素数据。在这里,如您所见,大约有 784 列包含像素数据。这里的每一行都是表单像素数据中的不同图像表示。
现在让我们将训练数据拆分为 x 和 y 数组,其中 x 表示图像数据,y 表示标签。
为此,我们需要将数据帧转换为 float32 类型的 numpy 数组,这是张量流和 keras 的可接受形式。
train_data = np.array(train_df, dtype = 'float32')现在让我们将训练数组切成 x 和 y 数组,即 x_train,y_train 分别存储所有图像数据和标签数据。即
- x_train包含除标签列和不包括标题信息之外的所有行和所有列。
- y_train包含所有行和第一列,不包括标题信息。
x_train = train_data [:, 1 :] / 255
y_train = train_data [:, 0 ]
x_test = test_data [:, 1 :] / 255
y_test = test_data [:, 0 ] PS:由于 x_train 和 x_test 中的图像数据是从 0 到 255 ,我们需要将其从 0 重新缩放到 1。为此我们需要将x_train和x_test除以 255。重要的是,训练集和测试集必须以相同的方式进行预处理。
现在,将训练数据拆分为验证数据和实际训练数据,用于训练模型并使用验证集对其进行测试。
x_train,x_validate,y_train,y_validate = train_test_split(x_train,y_train,test_size = 0.2,random_state = 12345)可视化调整数据大小后需要准备好训练网络的一些样本。
class_names = ['T_shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
plt.figure(figsize=(10, 10))
for i in range(36):
plt.subplot(6, 6, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(x_train[i].reshape((28,28)))
label_index = int(y_train[i])
plt.title(class_names[label_index])
plt.show()
训练样本如下图:

3.2 建立卷积神经网络(CNN)
首先,让我们在定义模型之前定义图像的形状。
image_rows = 28
image_cols = 28
batch_size = 4096
image_shape = (image_rows,image_cols,1)
现在我们需要对 x_train、x_test 和 x_validate 集进行更多格式化。
x_train = x_train.reshape(x_train.shape[0],*image_shape)
x_test = x_test.reshape(x_test.shape[0],*image_shape)
x_validate = x_validate.reshape(x_validate.shape[0],*image_shape)
模型网络中的第一层 keras.layers.Flatten 将图像的格式从二维数组(28 x 28 像素)转换为一维数组(28 * 28 = 784 像素)。此图层将图像中的像素行解堆叠并将它们对齐,并且没有要学习的参数;它仅重新格式化数据。
像素展平后,网络由两个 keras.layers.Dense 层的序列组成。这些是密集连接或完全连接的神经层。第一个密集层有 32 个节点(或神经元)。第二层(也是最后一层)是一个 10 节点的 softmax 层,它返回一个包含 10 个概率分数的数组,总和为 1。每个节点都包含一个分数,指示当前图像属于 10 个类之一的概率。
cnn_model = Sequential([
Conv2D(filters=32,kernel_size=3,activation='relu',input_shape = image_shape),
MaxPooling2D(pool_size=2) ,
Dropout(0.2),
Flatten(),
Dense(32,activation='relu'),
Dense(10,activation = 'softmax')
])
在模型准备好进行训练之前,还需要进行一些设置。这些是在模型的编译步骤中添加的:
- 损失函数:用于测量模型在训练期间的准确性。您希望最小化此函数以“引导”模型朝着正确的方向发展。在这里我们将使用“sparse_categorical_crossentropy”
- 优化器:这是根据模型看到的数据及其损失函数更新模型的方式。
- 指标:用于监控训练和测试步骤。以下示例使用准确度,即正确分类的图像的比例。
cnn_model.compile(loss ='sparse_categorical_crossentropy', optimizer=Adam(lr=0.001),metrics =['accuracy'])
训练神经网络模型需要执行以下步骤:
- 将训练数据馈送到模型。在此示例中,训练数据位于x_train和y_train数组中。
- 该模型学习关联图像和标签。
- 模型对测试集(在此示例中为 x_test 数组)进行预测。验证预测是否与 y_test 数组中的标签匹配。
history = cnn_model.fit(
x_train,
y_train,
batch_size=4096,
epochs=75,
verbose=1,
validation_data=(x_validate,y_validate),
)绘制训练准确度与损失的关系图,以更好地了解模型训练。
plt.figure(figsize=(10, 10))
plt.subplot(2, 2, 1)
plt.plot(history.history['loss'], label='Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.legend()
plt.title('Training - Loss Function')
plt.subplot(2, 2, 2)
plt.plot(history.history['accuracy'], label='Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.legend()
plt.title('Train - Accuracy')
绘制训练和验证准确性以及损失。
accuracy = history.history['accuracy']
val_accuracy = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
# create a figure with two subplots
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
# plot training and validation accuracy
ax1.plot(epochs, accuracy, '.', color='green', label='Training Accuracy')
ax1.plot(epochs, val_accuracy, '-', color='orange', label='Validation Accuracy')
ax1.set_title('Training and Validation Accuracy', fontsize=16)
ax1.set_xlabel('Epoch', fontsize=14)
ax1.set_ylabel('Accuracy', fontsize=14)
ax1.tick_params(axis='both', which='major', labelsize=12)
ax1.legend()
# plot training and validation loss
ax2.plot(epochs, loss, '.', color='green', label='Training Loss')
ax2.plot(epochs, val_loss, '-', color='orange', label='Validation Loss')
ax2.set_title('Training and Validation Loss', fontsize=16)
ax2.set_xlabel('Epoch', fontsize=14)
ax2.set_ylabel('Loss', fontsize=14)
ax2.tick_params(axis='both', which='major', labelsize=12)
ax2.legend()
# adjust subplots and save the figure
plt.tight_layout()
plt.savefig('training_metrics.png')
plt.show()
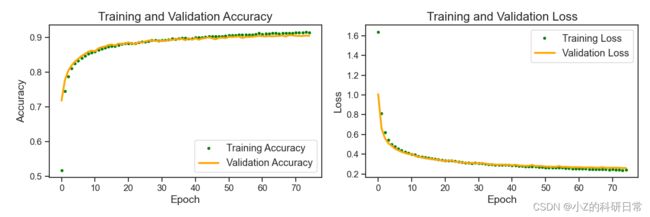
将分类器的性能总结如下:
#Get测试数据的预测
predicted_classes = cnn_model . predict_classespredict_classes( x_test )
#Get要绘制的指数
y_true = test_df 。ILOC [:, 0 ]
correct = NP . nonzero ( predicted_classespredicted_classes== y_true )[ 0 ]
incorrect = np . nonzero ( predicted_classes != y_true )[ 0 ]
from sklearn.metrics import classification_report
target_names = [ “Class {} ” . format ( i ) for i in range ( (num_classes )]
print ((classification_report (y_true , predicted_classes , target_namestarget_names= target_names )) 我们的分类器在精度和召回率方面对于类别2,分类器略微缺乏精度,而类别 4 的分类器略微缺乏召回率(即遗漏)。
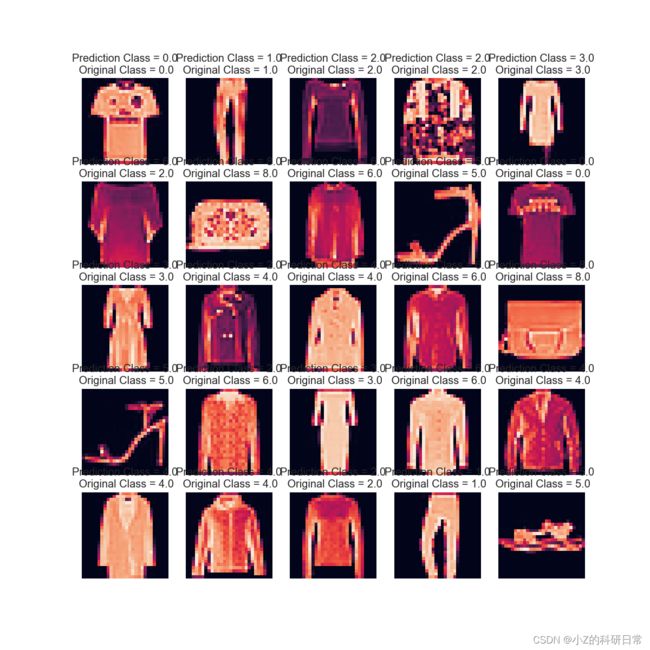
检查测试标签并检查它是否正确分类。
L = 5
W = 5
fig, axes = plt.subplots(L, W, figsize = (12,12))
axes = axes.ravel()
for i in np.arange(0, L * W):
axes[i].imshow(x_test[i].reshape(28,28))
axes[i].set_title(f"Prediction Class = {predicted_classes[i]:0.1f}\n Original Class = {y_test[i]:0.1f}")
axes[i].axis('off')
plt.subplots_adjust(wspace=0.5)
感谢您阅读本篇文章!如果您对神经网络与深度学习等方面感兴趣,欢迎关注我们的微信公众号(小Z的科研日常)。