Unity游戏开发基础之数据结构部分
设计模式
含义:帮助我们降低对象之间的耦合度常用的方法称为设计模式。使用设计模式是为了可重用代码,让代码更容易被其他人所理解,保证代码可靠性,使代码编制真正工程化,这是软件工程的基石。
分类:
创建型模式:工厂方法模式、抽象工厂模式、单例模式、建造者模式、组合模式、原型模式。
结构型模式:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
行为型模式:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
重点:单例模式、工厂方法模式、创造者模式、适配器模式、代理模式、装饰器模式、策略模式、责任链模式、观察者模式、迭代器模式。
超重点:单例模式,有饿汉式,懒汉式、双检锁、静态内部类、线程单例、枚举。
单例模式
含义:一个类只有一个实例,只在内部实例一次,外部无法实例化,全局唯一。一般应用于各种管理器,如角色管理器、声音管理器,场景管理器。
public class MySingleton
{
private static MySingleton __instance;
public static MySingleton instance{
get{
if(__instance == null){
__instance = new MySIngleton();
}
}
}
public MySingleton(){
Debug.Log("执行构造函数");
}
public void Show(){
Debug.Log("show");
}
}
MySingleton.instance.Show();
观察者模式
含义:可称为发布/订阅模式,定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个主题对象(多播委托)。主题对象发生变化时,它们能够自动更新自己,通常用作实现事件处理系统。
Using System;
using UnityEngine;
public class Animal{
protected string Name;
public Animal(string name){
this.Name = name;
}
public virtual void Run(){
}
}
public class Cat:Animal{
public Action actions; //发布者
public Cat(string name):base(name){
}
public void Coming(/*MouseA mouseA,MouseB mouseB,MouseC mouseC*/){
Debug.Log(Name + "猫来了");
//mouseA.Run();
//mouseB.Run();
//mouseC.Run();
this.Run();
if(actions!= null){
actions();
}
}
public override void Run(){
Debug.Log(Name + "追老鼠");
}
}
public class Mouse:Animal{
public Mouse(string name,Cat cat):base(name){
cat.actions += this.Run; //订阅者
}
public override void Run(){
Debug.Log(Name + "老鼠跑");
}
}
public class Visit:monoBehaviour{
void Start(){
Cat cat = New Cat("小野猫");
Mouse mouseA = new Mouse("mouseA",cat);
Mouse mouseB = new Mouse("mouseB",cat);
Mouse mouseC = new Mouse("mouseC",cat);
// 在老鼠数量不确定的情况下,这样的设计是不合理的
//cat.Coming(mouseA,mouseB,mouseC);
// 这样合理
cat.Coming();
}
}
简单工厂/工厂/抽象工厂
简单工厂模式:又叫静态工厂方法模式,由一个工厂对象决定创建出哪一种产品类的实例。只生产一个品类的产品,在工厂中动态创建。
工厂模式:避免简单工厂模式中,新增产品品牌(类型)时,直接修改工厂类。通过多个工厂创建不同的产品。
抽象工厂模式:解决系列产品问题,生产多种产品。
简单工厂模式:
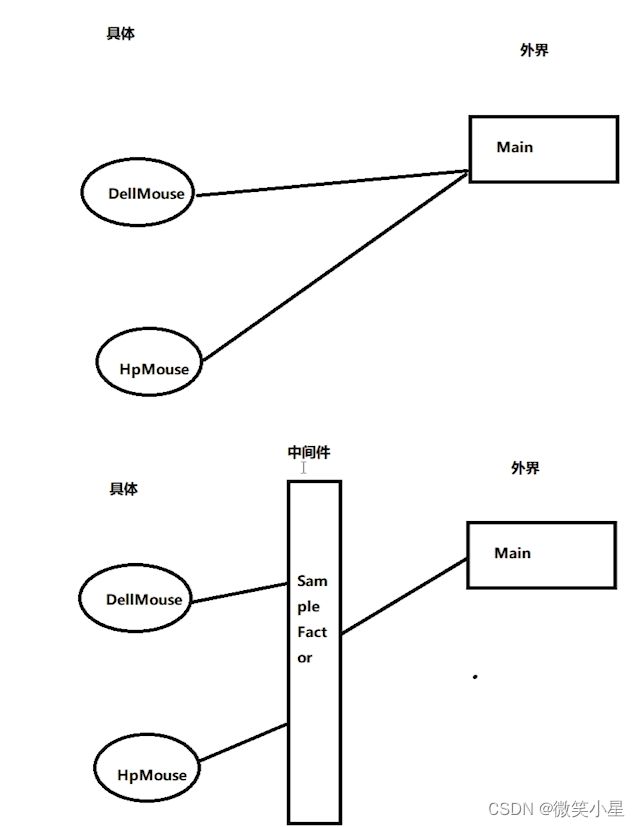
namespace Factor{
public abstract class AbstractMouse{
public abstract void Print();
}
}
using UnityEngine;
namespace Factor{
public class DellMouse: AbstractMouse{
public override void Print(){
Debug.Log("生产了一个Dell鼠标");
}
}
}
using UnityEngine;
namespace Factor{
public class HpMouse: AbstractMouse{
public override void Print(){
Debug.Log("生产了一个Hp鼠标");
}
}
}
namespace Factor{
public class SampleFactor{
public AbstractMouse CreateMouse(MouseType emMouseType){
AbstractMouse mouse = null;
switch(emMouseType){
case MouseType.HpMouse:
mouse = new HpMouse();
break;
case MouseType.DellMouse:
mouse = new DellMouse();
break;
default:
break;
}
return mouse;
}
}
}
using UnityEngine;
using Factor;
public enum MouseType{
None,
DellMouse,
HpMouse,
}
public class FactorMain:MonoBehaviour{
void Start(){
RunNormal();
RunSampleFactor();
}
void RunNormal(){
DellMouse dellMouse = new DellMouse();
dellMouse.Print();
HpMouse hpMouse = new HpMouse();
hpMosue.Print();
}
// 外界不需要关注具体的子类对象
void RunSampleFactor(){
SampleFactor factor = new SampleFactor();
AbstactMouse dellMouse = factor.CreateMouse(MouseType.DellMouse);
dellMouse.Print();
AbstactMouse hpMouse = factor.CreateMouse(MouseType.HpMouse);
hpMouse.Print();
}
}
工厂模式:
在这里插入图片描述
namespace Factor{
public abstract class FactorBase{
public abstract AbstractMouse CreateMouse();
}
}
namespace Factor{
public class DellFactor:FactorBase{
public override AbstractMouse CreateMouse(){
return new DellMouse();
}
}
}
namespace Factor{
public class HpMouse:FactorBase{
public override AbstractMouse CreateMouse(){
return new HpMouse();
}
}
}
public class FactorMain:MonoBehaviour{
void Start(){
RunFactor();
}
--snip--
void RunFactor(){
DellFactor dellFactor = new DellFactor();
AbstractMouse dellmouse = dellFactor.CreateMouse();
dellMouse.Print();
HpFactor hpFactor = new HpFactor();
AbstractMouse hpmouse = hpFactor.CreateMouse();
hpmouse.Print();
}
}
工厂模式的好处在于当新增一个类的时候我们不会对原来的代码进行修改,只新增类本身及其工厂。
抽象工厂模式: 可以生产多个类别产品。
在这里插入图片描述
namespace Factor{
public abstract class AbstractKeyBoard{
public abstract void Print();
}
}
namespace Factor{
public class DellKeyBoard:AbstractKeyBoard{
public override void Print(){
Debug.Log("Dell键盘");
}
}
}
namespace Factor{
public class HpMouse:AbstractKeyBoard{
public override void Print(){
Debug.Log("hp键盘");
}
}
}
namespace Factor{
public abstract class FactorBase{
public abstract AbstractMouse CreateMouse();
public abstract AbstractKeyBoard CreateKeyBoard();
}
}
namespace Factor{
public class DellFactor:FactorBase{
public override AbstractMouse CreateMouse(){
return new DellMouse();
}
public override AbstractKeyBoard CreateKeyBoard(){
return new DellKeyBoard();
}
}
}
namespace Factor{
public class HpMouse:FactorBase{
public override AbstractMouse CreateMouse(){
return new HpMouse();
}
public override AbstractKeyBoard CreateKeyBoard(){
return new HpKeyBoard();
}
}
}
--snip--
public class FactorMain:MonoBehaviour{
void Start(){
RunAbstractFactor();
}
--snip--
void RunAbstractFactor(){
DellFactor dellFactor = new DellFactor();
AbstractMouse dellmouse = dellFactor.CreateMouse();
dellMouse.Print();
AbstractKeyboard dellKeyBoard = dellFactor.CreateKeyBoard();
dellKeyBoard.Print();
HpFactor hpFactor = new HpFactor();
AbstractMouse hpmouse = hpFactor.CreateMouse();
hpmouse.Print();
AbstractKeyboard hpKeyBoard = hpFactor.CreateKeyBoard();
hpKeyBoard .Print();
}
}
适配器模式
概念:可以用同一种方式调用不同平台上的同一个功能。

namespace Adaptor{
public class AndroidLine{
public void AndroidCharge(){
Debug.Log("借助Android数据线充电中");
}
}
}
namespace Adaptor{
public class IOSLine{
public void IOSCharge(){
Debug.Log("借助IOS数据线充电中");
}
}
}
namespace Adaptor{
public enum AdaptorType{
None,
Android,
IOS,
}
public interface IAdaptor{
void Charge(AdaptorType adaptorType);
}
public class Adaptor:IAdaptor{
AndroidLine androidLine = new AndroidLine();
IOSLine iosLine = new IOSLine();
public void Charge(AdaptorType adaptorType){
if(adaptorType == AdaptorType.Android)
androidLine.AndroidCharge();
else if(adaptorType == AdaptorType.IOS){
iosLine.IOSCharge();
}
}
}
}
namespace Adaptor{
public class AdaptorMain"MonoBehaviour{
void Start(){
// 用的时候统一调用接口即可
IAdaptor adaptor = new Adaptor();
adaptor.Charge(AdaptorType.Android);
adaptor.Charge(AdaptorType.IOS);
}
}
}
注意:考虑到如果还有许多代码的情况下,这里接口用于拓展原始类不足的功能。
IO操作
C#字符串
参考:https://www.runoob.com/csharp/csharp-string.html
举例:
public class StringTest{
void Start(){
Test1();
}
void Test1(){
string str1 = "XIAOXING";
string str2 = "xiaoxing";
Debug.Log(str1.Length); // 长度
Debug.Log(string.Compare(str1,str2));//相等输出整形0,不等输出1
Debug.Log(string.Concat(str1,str2));//拼接
Debug.Log(string.Format("name:{0} age:{1}","张三",14))//格式化输出
Debug.Log(str1.Contains("I"));//判断是否存在目标字符串
Debug.Log(str1.IndexOf("I"));//字符串第一次出现的索引
string [] array = str1.Split(new char[] {'G'});//字符串切割
}
}
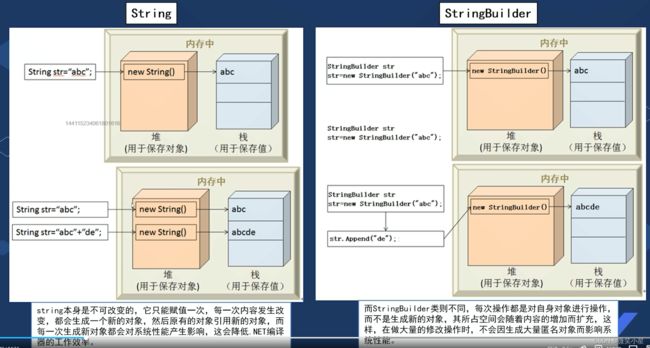
StringBuilder的使用
参考博客:https://blog.csdn.net/sibaison/article/details/72356393
用途:创建新的String的系统开销可能非常安规,如果要修改字符串而不创建新的对象,可以用到这个类。
public class StringBuilderTest{
void Start(){
Test1();
}
void Test1(){
stringBuilder sb = new StringBuilder("Hello World",25);//内容和最大长度
Debug.Log(sb.Length + sb.capacity); //长度+容量
sb = sb.Append("What a beautiful day!"); // 添加内容
Debug.Log(sb.ToString());
}
}
文件读写
参考链接:http://c.biancheng.net/csharp/file-io.html
using UnityEngine;
public class FileStreamTest:MonoBehaviour{
void CreateFile(){
string path = @"E:\WorkSpace\Project\Assets\Resources\student.txt";
FileStream fileStream = new FileStream(path,FileMode.OpenOrCreate,FileAccess.ReadWrite,FileShare.ReadWrite);
string msg = "1710026"
byte[] bytes = Encoding.UTF8.GetBytes(msg);//字符串转换为字节数组
fileStream.Write(bytes,0,bytes.Length);
fileStream.Flush();//刷新缓冲区
fileStream.Close();//关闭流
}
void ReadFile(){
string path = @"E:\WorkSpace\Project\Assets\Resources\student.txt";
if(File.Exists(path)){
FileStream fileStream = new FileStream(path,FileMode.Open,FileAccess.Read);
byte[] bytes = new byte(fileStream.Length);
fileStream.Read(bytes,0,bytes.Length);
string s = Encoding.UTF8.GetString(bytes);
Debug.Log(s)
fileStream.Close();
}
else{
Console.WriteLine("您查看的文件不存在");
}
}
void WriteAndRead{ //另一种方法
// 要写入文件中的数据
string[] str = new string[]{
"C语言中文网",
"http://c.biancheng.net/",
"C# 教程"
};
// 创建 StreamWriter 类的对象
StreamWriter file = new StreamWriter("demo.txt");
// 将数组中的数据写入文件
foreach(string s in str){
file.WriteLine(s);
}
file.Close();
// 读取文件中的内容
string line = "";
StreamReader readfile = new StreamReader("demo.txt");
while((line = readfile.ReadLine()) != null){
Console.WriteLine(line);
}
readfile.Close();
Console.ReadKey();
}
}
用Directory和DirectoryInfo操作文件夹
参考链接:http://c.biancheng.net/csharp/directory.html
一个是静态操作,一个是创建对象后操作
string strDir = @"E:\"
Directory.CreateDirectory(strDir);
Directory.Exists(strDir); //判断文件夹是否存在
Directory.Delete(strDir); //删除文件夹,如果有子文件夹需要加参数true
Directory.Move(strDir,@"D:\");//移动文件夹
DirectoryInfo directoryInfo = new DirectoryInfo(strDir);
directoryInfo.Create(); //创建文件夹
directoryInfo.CreateSubdirectory("code-1"); //创建子文件夹
directoryInfo.Delete(); //删除文件夹,如果有子文件夹需要加参数true
directoryInfo.MoveTo("D:\"); // 移动文件夹
数据结构
数组
含义:数组是用来储存数据的集合,元素类型相同,固定长度,顺序集合。
int[] array1 = new int[3];
int[] array2 = new int[3]{1,2,3};
int[] array3 = {1,2,3,4,5};
array1[0] = 5; //赋值
Debug.Log(array1[0]); //读取
foreach(var v in array2){
Debug.Log(v);
}
动态数组
动态数组会自动调整大小,可以在指定位置添加删除项目,允许在列表中动态分配内存。
ArrayList arraylist1 = new ArrayList();
arraylist1.Add(45); //添加一个数据
int[] array3 = {1,2,3,4,5};
arraylist1.AddRange(array3); //添加一组数据
arraylist1.Clear(); //清空
arraylist1.Contains(12); //判断是否包含特定元素
arraylist1.IndexOf(12); //返回第一次出现的元素索引,没有返回-1
arraylist1.Insert(3,66); //索引+插入元素
arraylist1.Remove(12); // 删除第一次出现的元素
arraylist1.Reverse(); //翻转元素
arraylist1.Sort(); //按顺序排列
列表
和泛型结合使用,作用与功能类似arraylist,无需装箱拆箱,类型转换,提前定义元素类型,比较安全,编译时就能检查错误。
List<int> list1 = new List<int>();
list1.Add(1);
// 和arraylist函数类似
哈希表
哈希表代表了键值对集合,使用键访问集合中的元素。用法比较简单。
Hashtable ht1 = new Hshtable();
ht1.Add("1",99);
ht1.Clear();
if(ht1.ContainsKey("1")){
Debug.Log("包含键为“1”的数据");
}
ht1.Remove("1");
Debug.Log(ht1["1"]); //读取
ht1["1"]=99; //修改
ICollection key = ht1.Keys;
foreach(var k in key){ //遍历
Debug.Log(ht1[k]);
}
和字典的不同在于可以存储任何类型的变量,不需要提前定义,但需要拆箱装箱。
哈希表本质上是通过数组储存的,一般把Key输入哈希函数中,计算出哈希值,把用这个哈希值作为数组的索引来读取和修改Value。
如果不同的Key计算出了同一个哈希值,称为发生了哈希冲突(哈希碰撞),因此设计合适的哈希函数很重要(直接定址法,数字分析法,折叠法,随机数法和除留余数法等等)
解决哈希冲突的方法有开放寻址法(一个位置被占了就一直找下一个位置),拉链法:通过在数组的位置上额外存放一个指针指向另外的一个位置(相当于链表),然后去下一个位置看是否有冲突,有冲突就继续走向这个位置指针的下一个位置,以此类推。
当哈希表被占领的位置过多(例如超过70%),就会触发扩容机制,创建一个新的数组,长度为原来的两倍,并且重新利用哈希函数计算位置。
字典
字典也存储键值对,但字典也是和泛型一起用的,提前指导好键值的数据类型。字典是通过哈希表实现的。
Dictionary<string,string> dict1 = new Dictionary<string,string>();
dict.add("1","100");
if(dict1.ContainsKey("1")){
Debug.Log("键存在");
}
dict1["1"] = 100;
foreach(KeyValuePair<string,string> kvp in dict1){
Debug.Log(kvp.Key + " " + kvp.Value);
}
dict1.Remove("2");
dict1.Clear();
哈希集
包含不重复项的无序集合
HashSet<int> hs1 = new HashSet<int>();
HashSet<int> hs2 = new HashSet<int>();
hs1.Add(1);
hs1.Add(2);
hs1.Add(2); //重复无效
Debug.Log(hs1.count); //计算个数
hs2.Add(2);
hs2.Add(3);
hs1.IntersectWith(hs2); //h1取交集
hs1.UnionWith(hs2); // h1取并集
hs1.ExceptWith(hs2); //h1取差集
hs1.SymmetricExceptWith(hs2); //对称差集,即并集中去掉交集的部分
链表
C#中是有前驱和后驱的双向链表。链表在内存中是离散的,不连续。通过两个指针指向上一个存储位置和下一个存储位置。
链表在删除和插入的时候效率比列表和数组快,但查找的时候只能靠遍历,比较慢。
链表可以分为单向和双向。
LinkedList<int> linList = new LinkedList<int>();
LinkedListNode<int> node;
node = linList.AddFirst(1); //第一个节点
linlist.AddAfter(node,2); //添加在某节点后面+具体值
linlist.AddBefore(node,0); //添加在某节点前面+具体值
Debug.Log(linList.Count);
Debug.Log(linList.First.Value); //第一个值
Debug.Log(linList.Last.Value); //最后一个值
Debug.Log(node.Previous.Value); //节点前一个值
Debug.Log(node.Next.Value); //节点后一个值
链表逆序(反转链表)的方法:
方法一:就地逆序
方法二:递归法
方法三:插入法
就地逆序:
def reverseList(self,head: Optional[ListNode]) -> Optional[ListNode]:
pre = None
cur = head
while cur:
nxt = cur.next
cur.next = pre
pre = cur
cur = nxt
return pre
插入法:
从链表的第二个结点开始,把遍历到的结点插入到头结点的后面,直到遍历结束。假如原链表为head->1->2->3->4->5->6->7,在遍历到2的时候,将2插入到头结点的后面,链表变为head->2->1->3->4->5->6->7,同理head->3->2->1->4->5->6->7等等。
def insertReverse(head):
# 特殊情况:头节点为空,或者只有单个节点
if head is None or head.next is None:
return
# 操作头节点, 2次指针操作,头节点head.next赋值给cur, 由于头节点最终要成为尾结点,其指向为空
cur = head.next
head.next = None
# 操作第二个及之后的节点,每次遍历到的节点都放到头节点处
while cur:
nex = cur.next
cur.next = head
head = cur
cur = nex
return head
堆栈
先进后出的对象集合
Stack st1 = new Stack();
st1.Push("a");
st1.Push("b");
st1.Push("c");
Debug.Log(st1.Count);
string v = (string)st1.Pop();
v = st1.Peek(); //拿到栈顶的值,不出栈
foreach(var v in st1){
Debug.Log(v1);
}
// 自己实现,使用链表的形式
class MyStack{
class StackData{
public StackData nextItem;
public object topData;
public StackData(StackData next,object data){
this.nextItem = next;
this.topData = data;
}
StackData top;
public void Push(object data){
top = new StackData(top,data);
}
public object Pop(){
object rs1 = top.topData;
top = top.nextItem;
return rs1;
}
}
}
MyStack ms = new MyStack();
ms.Push("a");
ms.Push("b");
ms.Push("c");
string v = ms.Pop();
队列
先进先出的队列集合
Queue queue1 = new Queue();
Queue<int> queue2 = new Queue<int>(); // 更多使用这种,效率高,不用装箱拆箱
queue2.Enqueue(1); //入队
queue2.Enqueue(2);
int v = queue2.Dequeue();
// 自己实现
class MyQueue{
class QueueData{
public QueueData nextItem;
public object topData;
public QueueData(QueueData last,object data){
last.nextItem = this;
this.topData = data;
}
QueueData top;
QueueData lastData;
public void Enqueue(object data){
if(top == null){
top = new QueneData(data);
}
else{
lastData = new QueueData(lastData,data);
}
}
public object Dequeue(){
object rs1 = top.topData;
top = top.nextItem;
return rs1;
}
}
}
Queue mq1 = new MyQueue();
mq1.Enqueue(1); //入队
mq1.Enqueue(2);
int v = mq1.Dequeue();
int v = mq1.Dequeue();
二叉树
一棵二叉树是结点的一个有限集合,该集合或者为空,或者是由一个根节点加上两棵别称为左子树和右子树的二叉树组成。
二叉树的特点:
- 每个结点最多有两棵子树,即二叉树不存在度大于2的结点。
- 二叉树的子树有左右之分,其子树的次序不能颠倒。
- 满二叉树:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果一个二叉树的层数为K,且结点总数是(2^k) -1 ,则它就是满二叉树。
- 完全二叉树:完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对应时称之为完全二叉树。 要注意的是满二叉树是一种特殊的完全二叉树。
- 二叉树的顺序存储在物理上是一个数组,在逻辑上是一颗二叉树。
性质
-
若规定根节点的层数为1,则一棵非空二叉树的第i层上最多有2^(i-1) 个结点.
-
若规定根节点的层数为1,则深度为h的二叉树的最大结点数是2^h- 1.
-
对任何一棵二叉树, 如果度为0其叶结点个数为 n0, 度为2的分支结点个数为 n2,则有n0=n2+1
-
若规定根节点的层数为1,具有n个结点的满二叉树的深度,h=Log2(n+1). (ps:Log2(n+1)是log以2为
底,n+1为对数) -
对于具有n个结点的完全二叉树,如果按照从上至下从左至右的数组顺序对所有节点从0开始编号,则对于序号为i的结点有:
- 若i>0,i位置节点的双亲序号:(i-1)/2;i=0,i为根节点编号,无双亲节点
- 若2i+1
- 若2i+2
链式存储
二叉树的链式存储结构是指,用链表来表示一棵二叉树,即用链来指示元素的逻辑关系。 通常的方法是链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别用来给出该结点左孩子和右孩子所在的链结点的存储地址 。链式结构又分为二叉链和三叉链,当前我们学习中一般都是二叉链,后面课程学到高阶数据结构如红黑树等会用到三叉链。
// 二叉链
struct BinaryTreeNode
{
struct BinTreeNode* _pLeft; // 指向当前节点左孩子
struct BinTreeNode* _pRight; // 指向当前节点右孩子
BTDataType _data; // 当前节点值域
}
// 三叉链
struct BinaryTreeNode
{
struct BinTreeNode* _pParent; // 指向当前节点的双亲
struct BinTreeNode* _pLeft; // 指向当前节点左孩子
struct BinTreeNode* _pRight; // 指向当前节点右孩子
BTDataType _data; // 当前节点值域
};
遍历
参考:https://blog.csdn.net/chinesekobe/article/details/110874773
所谓遍历(Traversal)是指沿着某条搜索路线,依次对树中每个结点均做一次且仅做一次访问。访问结点所做的操作依赖于具体的应用问 题。 遍历是二叉树上最重要的运算之一,是二叉树上进行其它运算之基础。
NLR:前序遍历(Preorder Traversal 亦称先序遍历)——访问根结点的操作发生在遍历其左右子树之前。相当于从顶部开始,逆时针绕圈。
LNR:中序遍历(Inorder Traversal)——访问根结点的操作发生在遍历其左右子树之中(间)。相当于从左往右排序,每个父节点都在其左右子节点的中间。
LRN:后序遍历(Postorder Traversal)——访问根结点的操作发生在遍历其左右子树之后。相当于从左往右,一次从叶子节点取一个元素下来,依次取到顶部。
深度优先遍历:似于先序遍历。
广度优先遍历:按每一层从上到下,从左到右进行遍历。
// 先序遍历
void ShowXianXu(BitTree T) // 先序遍历二叉树
{
if(T==NULL) // 递归中遇到NULL,返回上一层节点
{
return;
}
printf("%d ",T->data);
ShowXianXu(T->lchild); // 递归遍历左子树
ShowXianXu(T->rchild); // 递归遍历右子树
}
// 中序遍历
void ShowZhongXu(BitTree T) // 先序遍历二叉树
{
if(T==NULL) // 递归中遇到NULL,返回上一层节点
{
return;
}
ShowZhongXu(T->lchild); // 递归遍历左子树
printf("%d ",T->data);
ShowZhongXu(T->rchild); // 递归遍历右子树
}
// 后序遍历
void ShowHouXu(BitTree T) // 后序遍历二叉树
{
if(T==NULL) // 递归中遇到NULL,返回上一层节点
{
return;
}
ShowHouXu(T->lchild); // 递归遍历左子树
ShowHouXu(T->rchild); // 递归遍历右子树
printf("%d ",T->data);
}
前序非递归遍历:
这里使用栈来实现,首先将根放进栈中然后定义一个循环,循环条件是栈不为空,首先将栈顶元素弹出,并用一个结点保存,如果栈顶的元素不是空,就输出栈顶元素的数据,然后看它的左右子树,先把右子树压入栈中,再压左子树,(因为栈后进先出,先要访问左子树,所以左子树后进入),每次进入循环如果栈顶为空的化就不进行操作,直接进行操作,如果栈顶不为空的话再进行下面操作。直到所有结点都被遍历。
中序非递归遍历:
还是利用栈,因为先访问最左边的结点,所有我们先定义一个循环一直向左走把左边的所有结点压入栈中,这时候栈顶就是最左侧得结点,我们要将这个接单弹出,然后输出它的值,下来输出的是它的根结点,所以先要把它的右子树都压入栈中,最后再保存根结点就能保证先输出根结点再输出它右侧元素了。
后序非递归遍历:
还是利用栈,和中序非递归类似,先找到最左边的结点,并把这条路径上所有的结点按照找的顺序压入栈中,然后将最左侧结点的数据打印出来,然后判断当前节点是不是栈顶结点的左子树,如果是要先访问右结点才能访问根结点,否则将当前结点置成空,下一次就会输出当前结点的根结点,然后重复上述操作。
void PreOrder(BiNode *bt) { //树的前序遍历
SqStack s;
s = InitStack();
BiNode *p = bt;
while (p != NULL || StackEmpty(&s) != 1) { //当p为空,栈也为空时退出循环
while (p != NULL) {
visit(p->data);//访问根结点
Push(&s, p); //将指针p的节点压入栈中
p = p->Lchild; //遍历左子树
}
if (StackEmpty(&s) != 1) { //栈不为空
p = Pop(&s); //根结点出栈,相当于回退
p = p->rchild; //遍历右子树
}
}
DestroyStack(&s);
}
void MidOrder(BiNode *bt) { //树的中序遍历
SqStack s;
s = InitStack();
BiNode *p = bt;
while (p != NULL || StackEmpty(&s) != 1) { //当p为空,栈也为空时退出循环
while (p != NULL) {
Push(&s, p); //将指针p的节点压入栈中
p = p->Lchild; //遍历左子树
}
if (StackEmpty(&s) != 1) { //栈不为空
p = Pop(&s); //根结点出栈,相当于回退
visit(p->data);//访问根结点
p = p->rchild; //遍历右子树
}
}
DestroyStack(&s);
}
void PostOrder(BiNode *bt) { //树的后序遍历
SqStack s;
s = InitStack_1();
BiNode *p = bt;
element elem;
while (p != NULL || StackEmpty_1(&s) != 1) { //当p为空,栈也为空时退出循环
if (p != NULL) {//第一次入栈,访问左子树
elem.ptr = p;
elem.flag = 1; //标记flag为1,表示即将第一次入栈
Push_1(&s, elem); //将指针p的结点第一次压入栈中
p = p->Lchild;
} else {
elem = Pop_1(&s); //出栈
p = elem.ptr; //p指向当前要处理的结点
if (elem.flag == 1) {
//flag==1时,说明只访问过左子树,还要访问右子树
elem.flag = 2;
Push_1(&s, elem); //结点第二次压入栈中
p = p->rchild;
} else {
//flag==2时,左右子树都已经访问过了
visit(p->data);
p = NULL; //访问后,p赋为空,确保下次循环时继续出栈(相当于回退)
}
}
}
DestroyStack_1(&s);
}
反转二叉树
将每个节点的左右节点互换,也就是遍历每一个节点然后交换它们的左右节点,这里就可用到二叉树的各种遍历方法,只是将保存节点值的过程转换为交换左右节点。(中序遍历不能使用,会将某些节点反转两次)
//前序遍历解决问题
public TreeNode invertTree(TreeNode root) {
if(root==null) return null;
//反转左右孩子
TreeNode temp=root.left;
root.left=root.right;
root.right=temp;
invertTree(root.left); //左
invertTree(root.right); //右
return root;
}
排序二叉树找第k大节点
题目:
输入: root = [3,1,4,null,2], k = 1
3
/ \
1 4
\
2
输出: 4
示例 2:
输入: root = [5,3,6,2,4,null,null,1], k = 3
5
/ \
3 6
/ \
2 4
/
1
输出: 4
限制:
1 ≤ k ≤ 二叉搜索树元素个数
答案:
class Solution {
public:
int kthLargest(TreeNode* root, int k) {
//右根左降序遍历
stack s;
while(root || !s.empty())
{
while(root)
{
s.push(root);
root = root->right;
}
root = s.top();
s.pop();
k--;
if(k==0)
return root->val;
root = root->left;
}
return -1;
}
};
在这段代码中,使用右根左的遍历顺序是为了实现降序遍历二叉搜索树(Binary Search Tree)。降序遍历意味着按照节点值的降序来访问节点。
对于二叉搜索树而言,中序遍历可以实现升序遍历,即从小到大访问节点。而右根左的遍历顺序是中序遍历的逆序,所以可以实现从大到小访问节点,即降序遍历。
在这个特定的问题中,要找到二叉搜索树中第 k 大的元素。通过降序遍历,我们可以依次访问每个节点的值,并在第 k 个节点时返回对应的值,即为第 k 大的元素。
使用栈来辅助遍历的过程,可以实现迭代方式的降序遍历。从根节点开始,先将右子树的节点依次入栈,然后弹出栈顶元素,进行相应的处理(比如减小 k 的值,判断是否为第 k 大的元素),然后将左子节点作为下一个要处理的节点。
因此,使用右根左的遍历顺序是为了满足降序遍历的需求,并能够有效地找到第 k 大的元素。
平衡二叉树
二叉树能提高查询的效率 O(logn),但是当你插入{1,2,3,4,5,6} 这种数据的时候,你的二叉树就像一个链表一样,搜索效率变为 O(n)
所以一般的二叉搜索树在进行数据的存储时可能会使工作的时间复杂度并未降低太多,这时便需要我们将二叉树的高度尽可能的降低,使二叉树的高度降低为log(n),这样我们就得到了一个高度平衡的二叉搜索树,使对于数据的一系列操作的时间复杂度稳定在 O(logn)。
红黑树就是一颗自平衡的二叉树。
跳表
跳表(Skip List)是一种用于实现有序集合的数据结构,它通过在一个有序链表的基础上添加多层索引来提高数据的查找效率。跳表允许快速地按照元素的键值进行查找、插入和删除操作。
跳表的核心思想是通过建立多级索引层次,使得较大范围的元素可以通过跳过一些节点来进行快速搜索。每一级索引都是原始链表的一个子集,且比前一级索引稀疏,即包含更少的节点。最底层的索引就是原始的有序链表。
在跳表中,每个节点包含一个键值对,键用于按照有序方式进行排序,值则是具体存储的数据。每个节点还包含指向下一级索引节点的指针,使得可以在不同层次的索引之间进行快速的跳跃。
查找:从顶层往下,如果下一个指向的节点索引大于我们需要查找的索引,那么就跳到下一层。
插入:当我们在跳表中插入数据的时候,我们通过选择同时将这个数据插入到部分索引层中,如何选择索引层,可以通过一个随机函数来决定这个节点插入到哪几级索引中,比如随机生成了k,那么就将这个索引加入到,第一级到第k级索引中。
删除:和链表插入删除一致,不过是多了几层
public Node find(E e) {
if (empty()) {
return null;
}
return find(e, head, curLevel);
}
private Node find(E e, Node current, int level) {
while (level >= 0) {
current = findNext(e, current, level);
level--;
}
return current;
}
//返回给定层数中小于e的最大者
private Node findNext(E e, Node current, int level) {
Node next = current.next(level);
while (next != null) {
if (e.compareTo(next.data) < 0) {
break;
}
//到这说明e >= next.data
current = next;
next = current.next(level);
}
return current;
}
跳表的查询效率是时间复杂度是 nlogn
红黑树
参考:https://blog.csdn.net/xiaofeng10330111/article/details/106080394
红黑树(Red-Black Tree)是一种自平衡的二叉搜索树,它在插入和删除操作后能够自动调整树的结构,保持树的平衡性。红黑树是在普通二叉搜索树的基础上增加了一些附加的规则和性质来确保平衡。
红黑树的特点包括:
- 根节点是黑色的。
- 每个叶子节点(NIL 节点,空节点)是黑色的。
- 如果一个节点是红色的,那么它的两个子节点都是黑色的。
- 对于每个节点,从该节点到其所有后代叶子节点的简单路径上,均包含相同数量的黑色节点。
这些特性保证了红黑树的关键性质,包括:
任意节点到其每个叶子节点的路径长度相等或差至多为1,因此树的高度是对数级别的,保持了较好的平衡性。
查找、插入和删除操作的时间复杂度为 O(log n),保持了较高的操作效率。