Python 杂记
dir()、globals()
默认dir()是获取当前作用域的变量列表,而globals()是返回全局作用于的变量字典对象
全局下,dir()就是类似于sorted(list(globals()))的运算结果,而globals()类似于return a。
获得当前Python交互对话的pid
import os
os.getpid()
在使用python或ipython时,进程图标就是python,而IDLE、jupyter QtConsole等,则是pythonw,而且pythonw不止一个,所以这里就要用到这段代码获得python交互对话的pid,届时就可以用HxD读取对的进程,进行一波没有意义的骚操作!
python中的lambda函数与sorted函数
python中的lambda函数与sorted函数
help到文件
import os
import sys
out = sys.stdout
sys.stdout = open("help.txt", "w")
help(sum)
sys.stdout.close()
sys.stdout = out
虽然代码中没有os,但是不导入os,无效
另外.close()在IPython中会报错,并结束进程,而与下面的语句一起执行就不会报错
字符串判断 in or ==[-2:]
当字符很长,有辣么长的时候,用==[-2:]
s=‘n1’*40+‘ns’ 167 ns
s=‘00’*60+‘ns’ 168 ns
如果很短,用in
'ns' in '66.7 ns'
Out[45]: True
'ns'=='66.7 ns'[-2:]
Out[46]: True
%%timeit
'ns' in '66.7 ns'
67.3 ns ± 0.377 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
%%timeit
'ns'=='66.7 ns'[-2:]
150 ns ± 1.03 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
%%timeit
'ns' in '66.7 ns'[-2:]
156 ns ± 0.864 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
%%timeit
'66.7 ns'[-2:]
114 ns ± 1.11 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
s='n1'*1000+'ns'
%%timeit
'ns' in s
2.21 µs ± 12.4 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
%%timeit
'ns' in s[-2:]
190 ns ± 21.5 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
%%timeit
'ns'==s[-2:]
165 ns ± 0.364 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
%%time 无限整数
In [4]: %%time
...: a=2**(2**15*8)
...:
...:
Wall time: 2.98 ms
sys.getsizeof(a)
Out[5]: 34980
In [1]: %%time
...: 161....461
Wall time: 0 ns
Parser : 194 ms
开始的是表达式生成超长整数的情况,生成长度也不算大,但是IPython的耗时有点不对味
后面的是字面量赋值,多出了一个Parser,应该是解析字面量的耗时
%%time
a=2**(2**28*8)
Wall time: 32.7 s
sys.getsizeof(a)
286331180 # 273MB
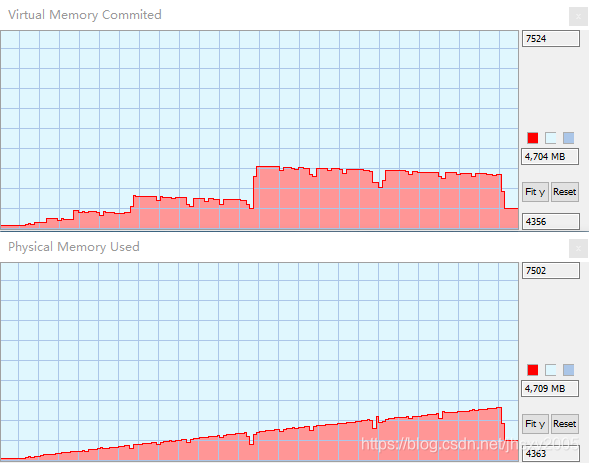
最后的回落:5228-4698=530
最初到最后:4698-4421=277
回落幅度将近数值内存的两倍,但是我挂起了进程查看过程数据:
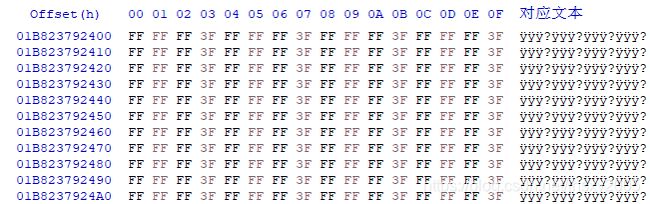
最终结果应该是:45 44 44 04 00 00 00 00 … 00 01 00 00,(1带228*8%30个0,这里是1 0000 0000)
…是71582788个00 00 00 00(2288//30)
如果Python这里使用自然数学的思路,例如decimal的思路去分解表达式,得到结果,不会是这么长的时间。但遗憾这里使用的是基本的编程思路,甚至遵循从左到右以及优先级。如果数玩大了,例如我之前尝试2**(2**308),爆内存都爆不出来数值。
但为什么回落幅度是数值内存的近两倍,就我掌握的手段(不会反编译,不会看源码),无法分析,暂时也不想去想了!
pip 升级安装模块
pip install spyder -U
今天spyder提示出4.2.2了,我去下载,github电信懂得,然后去清华镜像设置了下,上面有个-U的参数,即下载最新版,卸载旧版,安装最新版
pip install pip -U
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
我设置默认清华镜像后,就随之升级了spyder,秒完成!
chr()
chr可以将int转换为str,无论其是否是可打印的,是否有被定义
素材
哥特字母Iuja U+10336
闭眼睛的笑脸 表情符号 U+1F606
香 中日韩象形文字 U+9999
GB2312:龙
GBK:龍
GB18030:लंबा
UCS-2
通用字符集(英语:Universal Character Set, UCS)是由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的标准字符集。
UTF是"Unicode/UCS Transformation Format"的首字母缩写,即把Unicode字符转换为某种格式之意。UTF-16正式定义于ISO/IEC 10646-1的附录C
UTF-8是UNICODE的一种变长度的编码表达方式《一般UNICODE为双字节(指UCS2)》
wiki:UTF-16
UTF-16可看成是UCS-2的父集。在没有辅助平面字符(surrogate code points)前,UTF-16与UCS-2所指的是同一的意思。但当引入辅助平面字符后,就称为UTF-16了。现在若有软件声称自己支持UCS-2编码,那其实是暗指它不能支持在UTF-16中超过2字节的字集。对于小于0x10000的UCS码,UTF-16编码就等于UCS码。
Microsoft Windows操作系统内核对Unicode的支持
Windows操作系统内核中的字符表示为UTF-16小尾序,可以正确处理、显示以4字节存储的字符。但是Windows API实际上仅能正确处理UCS-2字符,即仅以2字节存储的,码位小于U+FFFF的Unicode字符。其根源是Microsoft C++语言把 wchar_t 数据类型定义为16比特的unsigned short,这就与一个 wchar_t 型变量对应一个宽字符、可以存储一个Unicode字符的规定相矛盾。相反,Linux平台的GCC编译器规定一个 wchar_t 是4字节长度,可以存储一个UTF-32字符,宁可浪费了很大的存储空间。下例运行于Windows平台的C++程序可说明此点:
// 此源文件在Windows平台上必须保存为Unicode格式(即UTF-16小尾) // 因为包含的汉字“”,不能在简体中文版Windows默认的代码页936(即GBK)中表示 // 该汉字在UTF-16小尾序中用4个字节表示 // Windows操作系统能正确显示这样的在UTF-16需用4字节表示的字符 // 但是Windows API不能正确处理这样的在UTF-16需用4字节表示的字符,把它判定为2个UCS-2字符 #includeint main() { const wchar_t lwc[] = L""; MessageBoxW(NULL, lwc, lwc, MB_OK); int i = wcslen(lwc); printf("%d\n", i); int j = lstrlenW(lwc); printf("%d\n", j); return 0; } Windows 9x系统的API仅支持ANSI字符集,只支持部分的UCS-2转换。1996年发布的Windows NT 4.0的API支持UCS-2。Windows 2000开始,Windows系统API开始支持UTF-16,并支持Surrogate Pair;但许多系统控件比如文本框和label等还不支持surrogate pair表示的字符,会显示成两个字符。Windows 7及更新的系统已经良好地支持了UTF-16,包括Surrogate Pair。
Windows API支持在UTF-16LE(wchar_t类型)与UTF-8(代码页CP_UTF8)之间的转码。例如:
#includeint main() { char a1[128], a2[128] = { "Hello" }; wchar_t w = L'页'; int n1, n2= 5; wchar_t w1[128]; int m1 = 0; n1 = WideCharToMultiByte(CP_UTF8, 0, &w, 1, a1, 128, NULL, NULL); m1 = MultiByteToWideChar(CP_UTF8, 0, a2, n2, w1, 128); }
UTF-32是32位Unicode转换格式(Unicode Transformation Formats, 或UTF)的缩写。UTF-32是一种用于编码Unicode的协定,该协定使用32位比特对每个Unicode码位进行编码(但前导比特数必须为零,故仅能表示221个Unicode码位)。与其他可变长度的Unicode转换格式(UTF)相比,UTF-32编码长度是固定的,UTF-32中的每个32位值代表一个Unicode码位,并且与该码位的数值完全一致。
UTF-32的主要优点是可以直接由Unicode码位来索引。在编码序列中查找第N个编码是一个常数时间操作。相比之下,其他可变长度编码需要进行循序访问操作才能在编码序列中找到第N个编码。这使得在计算机程序设计中,编码序列中的字符位置可以用一个整数来表示,整数加一即可得到下一个字符的位置,就和ASCII字符串一样简单。
UTF-32的主要缺点是每个码位使用四个字节,空间浪费较多。在大多数文本中,非基本多文种平面的字符非常罕见,这使得UTF-32所需空间接近UTF-16的两倍和UTF-8的四倍(具体取决于文本中ASCII字符的比例)。
尽管每一个码位使用固定长度的字节看似方便,但UTF-32并不如其它Unicode编码使用广泛。与UTF-8及UTF-16相比,UTF-32更容易遭到截断。即使使用了"定宽"字体,在大多数情况下用UTF-32计算显示字符串的宽度也并不比其他编码更加容易。主要原因是,存在着一个字符位置会有多于一种可能的码点(结合字符)或一个码点用多于一个字符位置(如CJK表意字符)。结合符号也意味着,文书编辑者不能将一个码位视同一个编辑上的单位。
历史
原本ISO 10646标准定义了一个32位的编码形式,称作UCS-4,通用字符集(UCS)的每一个字符由0到十六进制的7FFFFFFF的31位数值表示(符号位未使用且零)。UCS-4足以用来表示所有的Unicode的字码空间,其最大的码位为十六进制的7FFFFFFF,所以其空间约20亿个码位。2003年11月,由于UTF-16编码形式的限制,RFC 3629标准将Unicode限制为仅支持U+10FFFF以内的码位(另外U+D800到U+DFFF范围内也被保留使用)[1][2]。虽然在之前的ISO标准(1998年的Unicode 2.1)中0xE00000到0xFFFFFF和0x60000000到0x7FFFFFFF这些区域被分配给“保留私人使用”,但这些区域也在后续版本中被删除。在 ISO/IEC JTC 1/SC 2 WG2申明中规定UCS-4将来所有的字符分配将被限制在Unicode范围内,所以UTF-32和UCS4能表示的字符是相同的。
文件读写,一行搞定
open('file','w').write('are you ok?')
对比with和close,这个不要太简单,当然也仅仅是一条操作,如果操作多了,还是推荐with
查看文件对象的帮助
with open('a:\\t.txt') as ff:
print(ff)
<_io.TextIOWrapper name='a:\\t.txt' mode='r' encoding='cp936'>
ff
Out[16]: <_io.TextIOWrapper name='a:\\t.txt' mode='r' encoding='cp936'>
f=open('a:/t.txt')
f
Out[18]: <_io.TextIOWrapper name='a:/t.txt' mode='r' encoding='cp936'>
在以上两种语法中,with也是生成了文件对象并命名为ff,也就是说ff是一个变量。
查看一个类/方法的help需要得知这个类/方法的名称,但是help也可以跟变量,所以可以使用dir以及help,跟f以查看文件对象的方法等
字典的迭代
for i in d:'' # 312 ns
for i in d.keys():'' # 384 ns
for i in d.values():'' # 390 ns
for i,j in d.items():'' # 621 ns
for i in d:d[i] # 865 ns
如果同时要用key和value,用items要比d[i]快那么一点点。
枚举enumerate
接上,用于列表,类似于字典的items
for i,j in enumerate(l):'' # 675 ns
for i in range(len(l)):l[i] # 942 ns
字典妙用,调用集合、函数等
字典调用函数,省去一串if elif else
也能包含集合
最大的优点就是可以把字符串变成变量名、变成函数调用
l=['isalnum','isalpha','isascii','isdecimal','isdigit','islower','isnumeric','isprintable','isspace','isupper']
f={}
for i in l:
f[i]=eval('str.%s'%i)
if 'isupper' in f:f['isupper'](' ')
d={}
for i in l:
s=set()
f=eval('str.%s'%i)
for j in range(0x110000):
if f(chr(j)):s.add(j)
d[i]=s
for i,j in d.items():
print('%s:%s'%(i,len(j)))
另,字典还有个.get方法,dict.get(key),不存在,返回空
字典 get 好用的获取以及判断
6666 in d # 90.1 ns
d.get(6666) # 113 ns
d.__contains__(6666) # 125 ns
if v:=d.get(6666):v # 140 ns
if 6666 in d:d[6666] # 161 ns
if d.get(6666):d.get(6666) # 237 ns
在海象运算符的助力下,get超过了in
其他
ctypes.string_at(id(data),getsizeof(data)),读取内存指定地址和长度的字节内容
_ctypes.PyObj_FromPtr(id(data)),读取指定位置为头部的变量内容
bytes.hex([’ '[,-5]]),字节转换成以十六进制表示的字符串,插入字符,默认隔两个,可以设置隔开数量以及从左还是右开始算隔开数量
for i in range(0,100,5)[i:i+5],每隔5个一输出,本来是为了上面的功能,既然有现成的,就用上面的
重新载入模块,重载,reload
from imp import reload
reload(fac)
进程占用内存大小
import os,psutil
def mem():
print('内存占用:%.2f MB'%(psutil.Process(os.getpid()).memory_info().rss/1024/1024))
有的时候分析变量占用等情况,需要看到更加实时准确的情况,用得到,保存成.py甚至编译成.pyc,需要的时候导入即可
.pyc 编译字节码
python -m py_compile file.py
或者
import py_compile
py_compile.compile('c:\code\mem.pyc')
imp.reload(mem)
Out[19]: <module 'mem' from 'C:\\code\\mem.pyc'>
%%timeit
mem.mem()
51.9 µs ± 192 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
os.rename('c:/code/mem1.py','c:/code/mem.py')
import imp
%%timeit
mem.mem()
51.5 µs ± 576 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
至少这个只有一句的语句,差不多的运行耗时
exec eval
import decimal
data=eval('decimal.Decimal(1.1)')
# 28.9 µs
exec('data=%s'%'decimal.Decimal(1.1)')
# 39.4 µs
exec是将字符串以Python语句的形式执行,里面可以是任何合法语句,也能按照规则生成大量变量,exec本身不会返回结果
eval只能执行表达式,并返回运算结果。
上述代码,eval的耗时更少,但是只能接受表达式,如下需求
请输入一个赋值表达式,例如:123,‘123’,1.1,range(10)等
支持import,使用;隔开导入和表达式,例如:import fractions;fractions.Fraction(1,2)
如果这里没有import,只有表达式,eval是最直接的选择
有了import的话,就需要进行处理:
exec(s[:(f:=s.find(';'))]+';data='+s[f+1:])
# 46.8 µs
exec(s[:(f:=s.find(';'))]);data=eval(s[f+1:])
# 55.9 µs
虽然eval的效率高些,但是第一行执行一次exec,第二行执行一次exec,一次eval,而字符串处理其实很快捷,第二行的eval就显得多余了。
最终代码片段是:
try:
if 'import' in s:exec(s[:(f:=s.find(';'))]+';data='+s[f+1:])
else:data=eval(s)
except Exception as e:
print('\n输入格式错误:%s'%e)
exit()
str、repr、input
接上述
输入:import fractions\nfractions.Fraction(1,2)
s
Out[22]: 'import franctions\\nfractions.Fraction(1,2)'
repr(s)
Out[24]: "'import franctions\\\\nfractions.Fraction(1,2)'"
'\n' in s
Out[27]: False
'\\n' in s
Out[28]: True
这里的变化在于,输入时,将\n当作字符\和字符n输入,于是转换结果就是\\n,而下面的两个in判断,\n是被当作回车键处理的一个字符,而\\n是被字符\和字符n这两个字符组成的字符串处理的。
find、index、in、starswith、endswith 判断包含
接上
s
Out[60]: 'import fractions\\nfractions.Fraction(1,2)'
ss=s+' '*1000
'\\nfraction' in s
Out[61]: True
# 118 ns
'\\nfractionz' in s
Out[62]: False
# 121 ns in ss 315 ns
s.find('\\nfraction')
Out[63]: 16
# 258 ns
s.index('\\nfraction')
Out[64]: 16
# 276 ns
s.find('\\nfractionz')
Out[65]: -1
# 263 ns
str.find(s,'\\nfraction')
# 318 ns
s.index('\\nfractionz')
Traceback (most recent call last):
File "" , line 1, in <module>
s.index('\\nfractionz')
ValueError: substring not found
s='\\f'
'\\' in s
61.9 ns
s.startswith('\\')
194 ns
s.find('\\')
203 ns
s.endswith('f')
207 ns
效率:in >>>startswith > endswith > find > index
所以只判断是否存在的话,用in
同时判断第一次匹配字符串的索引位置的话,用find
同时不存在需要异常处理的话用index
str.index是绕弯调用函数
in就是contains
| __contains__(self, key, /)
| Return key in self.
切片 逆序
s='0123456789'
s[:2] # 132 ns
s[0:2] # 139 ns
s[2:0:-1] # 164 ns '21'
s[1::-1] # '10'
s[1::-1] # ''
s[-9:-11:-1] # '10' 166 ns
s[1:-11:-1] # 165 ns
s[:2][::-1] # 249 ns 先切片在逆序,耗时近2倍
一般进行批量处理时,需要起始点,但之前很少批量处理,所以逆序的终点需要s[0]的话,写不出,但也没深究过,现在int值的数值块属于4B一组,需要大小端转换,而30位一进的下一组也是小端的,新的大的一组在旧的小的一组后面,类似字节的小端,据说还有半字节的小端甚至比特的小端来着,总之这次写出来了,将0写成-的超限即可-(len+1),追加处理也就要变一下模式了。
但是又发生了一件事情,如果全部使用负数的话,12个长度的串,分为一节4个长度同时逆转两端,那么依次是:
l=list(range(-12,0))
[-12, -11, -10, -9, -8, -7, -6, -5, -4, -3, -2, -1]
l[-9:-13:-1]
[-9, -10, -11, -12]
接下来-5:-9:-1 -1:-5:-1 这是理想状态,但是如果超限了呢?正如索引0想超限,只能使用负号,但是这里都用符号了,索引11想超限,就不能用符号了,只能又用到正好表示,例如:
l[13:-3:-1]
Out[95]: [-1, -2]
这是继续向右移动,只能又用整数表示右侧超限,于是结论就是:
在批处理中,若想不判断边界,那么右侧超限用正数,左侧超限用负数表示。
空字典的生成
d={}
45.8 ns
d=dict()
156 ns
字典的遍历
Python Unicode str.is整理
for i in d:
len(d[i])
1.63 µs
for i,j in d.items():
len(j)
1.48 µs
for i in d.values():
len(i)
1.23 µs
以上方法的运行过程中,占用的内存一样,即j获取的只是d的元素中,item的指针,并未生成新的变量,这让我安心,以前我以为都是生成了新的变量来着,并不是,完全是开放了内部变量的感觉。
for i in d:
pass
304 ns
for i in d.values():
376 ns
for i in d.keys():
374 ns
for i,j in d.items():
592 ns
核心运行,大致如此,中间两个差不多。默认的虽然和.keys结果一样,但是效率高,类似s.is,属于核心方法,而.keys则需要把外部数据再加载。虽然核心方法可能就是他的副本,但是这一出一进就增加了耗时!
但虽然默认方法效率高,但是如果内部需要调用d[i],效率则降低了,所以如果要同时使用两个数据的话,则使用.items