THE MUTUAL-CHANNEL LOSS (MC-LOSS,附代码分析)
目录
- 简介
- 1 Discriminality组件(dis)
- 2 Diversity组件(div)
- 代码实现
论文地址:The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification.
简介
提出的互信道损失(MC-Loss)功能,有效地导航模型,聚焦于不同的区分区域,而不需要任何细粒度的限定框/部件注释。
在训练步骤中结合提出的MC-Loss的网络如图2所示。

上图所示:使用MC-Loss的典型细粒度分类网络的框架。MC-Loss函数考虑输出特征通道作为输入,并使用超参数支持与交叉熵(CE)损失函数集合在一起。
对于给定的输入图像,首先通过将图像输入基网络提取特征图;例如,VGG16或ResNet18。令所提取的feature map记为 F F F∈ R N × W × H R^{N×W×H} RN×W×H,高度H,宽度W,通道数N。在提出MC-Loss,我们需要设置N的值等于c×ξ,c和ξ分别显示类的数量在一个数据集和特征的数量渠道用来表示每个类。注意,ξ是一个标量hyper-parameter和经验大于2。F的第n个向量特征通道表示为Fn∈RWH, n = 1,2,··,n。请注意,我们对维数F的每个通道矩阵进行了重塑W乘以H变成一个大小为W乘以H的向量,即WH。表示第i类对应的特征信道分组Fi∈Rξ×WH, i = 0, 1,···c−1。在数学上,它可以表示为
![]()
随后F = {F0, F1,··,Fc−1}进入到网络的两个流中,有两个不同的子损耗,针对两个不同的目标。在图2中,交叉熵流将F视为具有传统CE损失 L C E L_{CE} LCE的全连接(FC)层的输入。在此,交叉熵损失鼓励网络提取信息特征,主要集中在全局识别区域。另一方面,MC-Loss流监控网络以突出不同的局部区域。然后在训练步骤中,将MC-Loss加上CE loss,并以支点的权重加入到CE loss中。因此,可以将整个网络的总损耗函数定义为:
![]()
此外,MC-损失是一个判别分量Ldis和另一个多样性分量Ldiv的加权和。我们将MC-损失定义为:
![]()
1 Discriminality组件(dis)
在该框架中,每个类都由一定数量的特征通道分组来表示。鉴别性组件强制特征通道是类对齐的,与特定类对应的每个特征通道应该具有足够的鉴别性。区别性分量Ldis可以表示为:
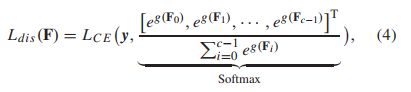
g(·) 表示为:

在这里,CCMP和CWA分别是全球平均池、跨通道最大池和 channel-wise attention的简短表示法。 L C E ( ⋅ , ⋅ ) L_{C E} (·, ·) LCE(⋅,⋅)是ground-truth类标签y与GAP输出之间的交叉熵损失。Mi =diag( M a s k i Mask_i Maski )*, M a s k i Mask_i Maski是一个0-1的随机掩码,图(a)中左边的部分显示了判别组件的流程图。

- CWA:在传统的cnn,训练用传统的CE损失会失去目标,某些特征子集通道包含区别的信息,我们这里提出channel-wise注意操作执行所有ξ的网络同样捕捉歧视信息渠道对应于一个特定的类。与其他channel-wise注意设计,打算将优先分配给有识别力的通道使用soft-attention值,**在每一次迭代分配随机二进制权重(0,1)给通道和随机选择几个特性通道从每个特征组Fi,从而明确鼓励每个特征通道包含足够的区别的信息。**这个过程可以可视化为一个随机的通道丢弃操作。请注意,CWA只在训练期间使用,整个MC-Loss分支在推理时不存在。因此,分类层在训练和推理过程中接收到的输入特征分布是相同的。
- CCMP:利用跨通道最大池化计算对应于特定类的Fi中每个特征通道上每个元素的最大响应,从而得到与特定类一致的一维向量。请注意,跨通道平均池(CCAP)是CCMP的一种替代方法,它仅用平均池代替最大池操作。然而,CCAP倾向于平均每一个元素,这可能会抑制特征通道的峰值,即对局部的关注。相反,CCMP可以保持这些注意,并被发现有利于细粒度分类。
- GAP:使用全局平均池计算每个特征通道的平均响应,得到一个c维向量,其中每个元素对应一个单独的类。
最后,我们使用CE损失函数 L C E L_{C E} LCE来计算地基真值标签与间隙操作后的softmax函数给出的预测概率之间的差异。
2 Diversity组件(div)
多样性(Diversity)分量是一种近似的特征通道距离测量方法,用来计算所有信道的相似度。与其他常用的测量方法,如欧氏距离和具有二次复杂度的Kullback-Leibler散度相比,具有常数复杂度,计算成本更低。多样性分量是一种近似的特征通道距离测量方法,用来计算所有信道的相似度。与其他常用的测量方法,如欧氏距离和具有二次复杂度的Kullback-Leibler散度相比,具有常数复杂度,计算成本更低。图(a)右所示的多样性分量通过训练使一组Fi中的特征通道变得不同。换句话说,一个类别的不同特征通道应该聚焦于图像的不同区域,而不是所有的通道都聚焦于最具区别性的区域。从而使每一组的特征通道多样化,减少了冗余信息,有助于发现图像中针对每一类别的不同区分区域。此操作可解释为跨通道去相关,以便从图像的不同突出区域捕获细节。在softmax之后,我们通过引入CCMP,然后通过空间维度求和来测量交度,从而直接对卷积滤波器施加监督。 L d i v L_{div} Ldiv损失可定义为:

h ( ⋅ ) h(·) h(⋅)表示为:

softmax的功能是空间维度的标准化,而CCMP在这里扮演的角色与它在区别(discriminality)组件中的角色相同。
在ξ极其不同的特征图谱的情况下, L d i v L_{div} Ldiv的上限等于ξ,这意味着他们专注于不同的局部区域,而面临的下界是1面临在Fi中ξ相同特征图谱显然需要优化如下图所示

假设每个特性通道通过softmax是one-hot的规范化,h(·)响应的上限3(ξ= 3)如果每个特性通道在不同的地方,例如,关注不同的地方。反之,如果获得相同的特征通道,h(·)会对下界1做出响应。理想情况下,我们打算最大化 L d i v L_{div} Ldiv项,从而证明公式(3)中的负号是合理的。需要注意的是,多样性分量不能单独用于分类,它是在区分度损失之上的一个正则化器,以隐式地发现图像中不同的区分区域。
代码实现
# 定义CCMP #
import torch
import numpy as np
import random
from torch.autograd import Variable
from torch.nn.modules.module import Module
from torch.nn.modules.utils import _single, _pair, _triple
import torch.nn.functional as F
from torch.nn.parameter import Parameter
class my_MaxPool2d(Module):
def __init__(self, kernel_size, stride=None, padding=0, dilation=1,
return_indices=False, ceil_mode=False):
super(my_MaxPool2d, self).__init__()
self.kernel_size = kernel_size
self.stride = stride or kernel_size
self.padding = padding
self.dilation = dilation
self.return_indices = return_indices
self.ceil_mode = ceil_mode
def forward(self, input):
input = input.transpose(3,1)
input = F.max_pool2d(input, self.kernel_size, self.stride,
self.padding, self.dilation, self.ceil_mode,
self.return_indices)
input = input.transpose(3,1).contiguous()
return input
def __repr__(self):
kh, kw = _pair(self.kernel_size)
dh, dw = _pair(self.stride)
padh, padw = _pair(self.padding)
dilh, dilw = _pair(self.dilation)
padding_str = ', padding=(' + str(padh) + ', ' + str(padw) + ')' \
if padh != 0 or padw != 0 else ''
dilation_str = (', dilation=(' + str(dilh) + ', ' + str(dilw) + ')'
if dilh != 0 and dilw != 0 else '')
ceil_str = ', ceil_mode=' + str(self.ceil_mode)
return self.__class__.__name__ + '(' \
+ 'kernel_size=(' + str(kh) + ', ' + str(kw) + ')' \
+ ', stride=(' + str(dh) + ', ' + str(dw) + ')' \
+ padding_str + dilation_str + ceil_str + ')'
from my_pooling import my_MaxPool2d
criterion = nn.CrossEntropyLoss()
def Mask(self, nb_batch, channels):
# [1,1,0]
foo = [1] * 2 + [0] * 1
bar = []
# bar为foo *200 共600
for i in range(200):
# shuffle()打乱
random.shuffle(foo)
bar += foo
# nb_batch个bar
bar = [bar for i in range(nb_batch)]
# np.array()创建一个数组。
# astype()复制数组,强制转换为指定类型。
bar = np.array(bar).astype("float32")
bar = bar.reshape(nb_batch, 200 * channels, 1, 1)
# 将数组转换为张量
bar = torch.from_numpy(bar)
bar = bar
bar = Variable(bar)
return bar
def supervisor(self, x, targets, height, cnum):
mask = self.Mask(x.size(0), cnum)
# 求 Ldiv:
branch = x
branch = branch.reshape(branch.size(0), branch.size(1), branch.size(2) * branch.size(3))
# Ldiv: softmax
branch = F.softmax(branch, 2)
branch = branch.reshape(branch.size(0), branch.size(1), x.size(2), x.size(2))
# Ldiv: CCMP
branch = my_MaxPool2d(kernel_size=(1, cnum), stride=(1, cnum))(branch)
# Ldiv: GAP
branch = branch.reshape(branch.size(0), branch.size(1), branch.size(2) * branch.size(3))
# # Ldiv: SUM
loss_2 = 1.0 - 1.0 * torch.mean(torch.sum(branch, 2)) / cnum # set margin = 3.0
# 求Ldis:
# Ldis: CWA
branch_1 = x * mask
# Ldis: CCMP
branch_1 = my_MaxPool2d(kernel_size=(1, cnum), stride=(1, cnum))(branch_1)
# Ldis: GAP
branch_1 = nn.AvgPool2d(kernel_size=(height, height))(branch_1)
branch_1 = branch_1.view(branch_1.size(0), -1)
# Ldis: softmax
loss_1 = self.criterion(branch_1, targets)
return [loss_1, loss_2]