open clip论文阅读摘要
看下open clip论文
Learning Transferable Visual Models From Natural Language Supervision
These results suggest that the aggregate supervision accessible to modern pre-training methods within web-scale collections of text surpasses that of high-quality crowd-labeled NLP datasets.
CNNs trained to predict words in image captions learn useful image representations
learn image representations from text
我好奇,在OCR上是怎么测试的?
CLIP训练样本要怎么准备,400 million (image, text) pairs,这个量级的样本集是怎么准备出来的
论文说CLIP这种预训练,zero-shot可以媲美基于监督学习构建的模型,我需要打个问号,在特定领域的业务数据上好像不太够啊?
Learning from natural language has several potential strengths over other training methods. It’s much easier to scale natural language supervision compared to standard crowd-sourced labeling for image classification since it does not require annotations to be in a classic “machine learning compatible format” such as the canonical 1-of-N majority vote “gold label”
MS-COCO and Visual Genome are high quality crowd-labeled datasets, they are small by modern standards with approximately 100,000 training photos each
YFCC100M, at 100 million photos, is a possible alternative, but the metadata for each image is sparse and of varying quality
Many images use automatically generated filenames like 20160716 113957.JPG as “titles” or contain “descriptions” of camera exposure settings. After filtering to keep only images with natural language titles and/or descriptions in English, the dataset shrunk by a factor of 6 to only 15 million photos. This is
approximately the same size as ImageNet
A major motivation for natural language supervision is the large quantities of data of this form available publicly on the internet.
we constructed a new dataset of 400 million (image, text) pairs collected form a variety of publicly available sources on the Internet
We approximately class balance the results by including up to 20,000 (image, text) pairs per query. The resulting dataset has a similar total word count as the WebText dataset used to train GPT-2. We refer to this dataset as WIT for WebImageText
注重样本的类别平衡
we found training efficiency was key to successfully scaling natural language supervision and we selected our final pre-training method based on this metric
是的,在这样规模的数据集上训练,需要的时间是令人畏惧的,所以掌握更快速的训练效率是关键
Recent work in contrastive representation learning for images has found that contrastive objectives can learn better representations than their equivalent
predictive objective
这个发现很有意思,这说明我们可以不需要准确预测每个图片的text caption,这太难了
Other work has found that although generative models of images can learn high quality image representations, they require over an order of magnitude more compute than contrastive models with the same performance
这里又提到了生成模型,在学习表征方面,有监督学习CNN、对比学习CLIP、生成模型Stable Diffusion
We train CLIP from scratch without initializing the image encoder with ImageNet weights or the text encoder with pre-trained weights.
在这么一个大数据集上,甚至比ImageNet还大,加载预训练的ImageNet模型和text encoder模型确实没必要
CLIP is pre-trained to predict if an image and a text snippet are paired together in its dataset. To perform zero-shot classification, we reuse this capability. For each dataset, we use the names of all the classes in the dataset as the set of potential text pairings and predict the most probable (image, text)
pair according to CLIP. In a bit more detail, we first compute the feature embedding of the image and the feature embedding of the set of possible texts by their respective encoders. The cosine similarity of these embeddings is then calculated, scaled by a temperature parameter τ , and normalized into a
probability distribution via a softmax. Note that this prediction layer is a multinomial logistic regression classifier with L2-normalized inputs, L2-normalized weights, no bias, and temperature scaling
Another issue we encountered is that it’s relatively rare in our pre-training dataset for the text paired with the image to be just a single word. Usually the text is a full sentence describing the image in some way. To help bridge this distribution gap, we found that using the prompt template “A photo of a {label}.” to be a good default that helps specify the text is about the content of the image. This often improves performance over the baseline of using only the label text
出现这个问题的原因是模型没能理解语言,不过现在GPT4可以做到了,估计会有点儿突破?
Similar to the “prompt engineering” discussion around GPT3 (Brown et al., 2020; Gao et al., 2020), we have also observed that zero-shot performance can be significantly improved by customizing the prompt text to each task. A few, non exhaustive, examples follow. We found on several fine-grained image classification datasets that it helped to specify the category. For example on Oxford-IIIT Pets, using “A photo of a {label}, a type of pet.” to help provide context worked well. Likewise, on Food101 specifying a type of food and on FGVC Aircraft a type of aircraft helped too. For OCR datasets, we found that putting quotes around the text or number to be recognized improved performance. Finally, we found that on satellite image classification datasets it helped to specify that the images were of this form and we use variants of “a satellite photo of a {label}.”.
这种prompt对于性能的提升是肯定的
We also experimented with ensembling over multiple zeroshot classifiers as another way of improving performance. These classifiers are computed by using different context prompts such as ‘A photo of a big {label}” and “A photo of a small {label}”. We construct the ensemble over the embedding space instead of probability space. This allows us to cache a single set of averaged text embeddings so that the compute cost of the ensemble is the same as using a single classifier when amortized over many predictions
这里使用emsemble的方法提升性能
说白了,比监督学习强在:
1、数据量更多
2、任务种类更多
3、加上文本学习语义信息,不单单是空间信息
we see that zero-shot CLIP is quite weak on several specialized, complex, or abstract tasks such as satellite image classification (EuroSAT and RESISC45), lymph node tumor detection (PatchCamelyon), counting objects in synthetic scenes (CLEVRCounts), self-driving related tasks such as
German traffic sign recognition (GTSRB), recognizing distance to the nearest car (KITTI Distance). These results highlight the poor capability of zero-shot CLIP on more complex tasks.
貌似跟GPT4也有点像?虽然通用性很不错,但是没办法做到全能,特别是复杂任务上,我感觉还是数据的问题吧,当然也有可能是现在的模型架构没办法应对复杂任务,所以需要拆解成更简单的子任务。不可否认的是在业务数据标注上存在加速作用
First, CLIP’s zero-shot classifier is generated via natural language which allows for visual concepts to be directly specified (“communicated”). By contrast,
“normal” supervised learning must infer concepts indirectly from training examples. Context-less example-based learning has the drawback that many different hypotheses can be consistent with the data, especially in the one-shot case. A single image often contains many different visual concepts. Although a capable learner is able to exploit visual cues and heuristics, such as assuming that the concept being demonstrated is the primary object in an image, there is no guarantee
是的,few-shot的难点主要在于,你不知道模型把什么特征跟最终的标签做了关联,所以需要加大样本数据量,才能使模型正确找到这个路径
zero-shot主要是在大数据量上预训练了,所以跟few-shot还是有区别的
我比较看好在大数据上预训练过的大模型
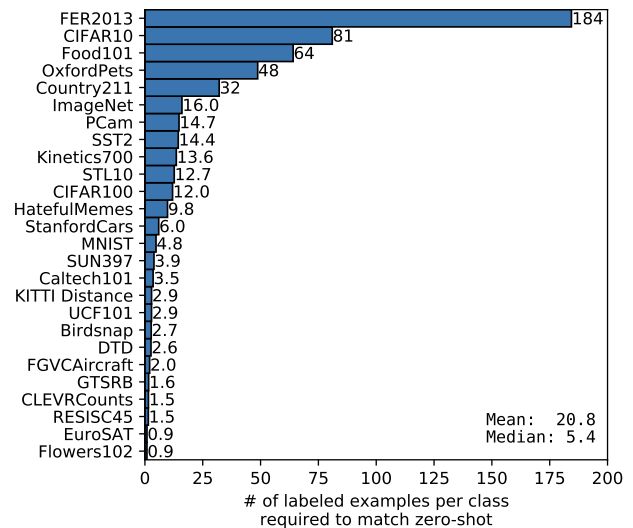
其实这个评估有点儿问题?如何评判稳定性?你这个只是在建立的测试样本集上的结果而已,并不是大量的数据评估结果,特别是放到真实业务场景下的分析结果,我觉得每个类别多点儿数据不是坏事,可以加强特征到标签的连接,特别是捕获正确的特征
If we assume that evaluation datasets are large enough that the parameters of linear classifiers trained on them are well estimated, then, because CLIP’s zero-shot classifier is also a linear classifier, the performance of the fully supervised classifiers roughly sets an upper bound for what zero-shot transfer can achieve
从拟合能力上来看,监督学习可以拟合的性能上限,也是zero-shot可以达到的上限
在大数据上学习到通用表征能力,跟在特定数据集上做监督训练,并不是冲突的
Over the past few years, empirical studies of deep learning
systems have documented that performance is predictable as
a function of important quantities such as training compute
and dataset size
这里提到,近年来的深度学习预测能力,是可以评估的,这个确实有点儿意思哈