图文并茂解读联合索引底层存储结构及索引查找过程
文章目录
- 前言
- 版本
- 数据准备
-
- SQL
- 数据创建结果
- 有无联合索引执行情况
-
- 无联合索引
- 存在联合索引
- 底层存储结构
- 查询过程
-
- 最左匹配原则
- 查询过程解析
- 联合索引优势
-
- 支持复杂查询
- 索引覆盖查询
- 提高排序和分组性能
- 减少索引数量
- 使用建议
-
- 联合索引的列顺序十分重要
- 建议能使用联合索引尽量使用联合索引
- 常见问题分析
-
- 为什么遵循最左匹配原则
- 联合索引中字段范围查询为什么会导致后续联合索引字段可不用
- 个人简介
前言
- 大家好,我是 Lorin ,联合索引(Composite Index)又称复合索引,它包括两个或更多列。与单列索引不同,联合索引可以覆盖多个列,这有助于加速复杂查询和过滤条件的检索。联合索引的列顺序非常重要,因为查询优化器会按照索引列的顺序执行搜索。
- 本文将从联合索引基本概念、底层存储结构、索引查找过程、实践建议几个方面图文并茂进行详细介绍。
版本
SELECT VERSION();
5.7.36-log
数据准备
SQL
// 创建表
CREATE TABLE `test_table_union_index` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`merchant_id` int(20) NOT NULL,
`order_id` int(20) NOT NULL,
PRIMARY KEY (`id`),
KEY `merchant_id_order_id_union_index` (`merchant_id`,`order_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8mb4;
// 插入数据
INSERT INTO `test_table_union_index` (`merchant_id`, `order_id`) VALUES (3, 1);
INSERT INTO `test_table_union_index` (`merchant_id`, `order_id`) VALUES (3, 2);
INSERT INTO `test_table_union_index` (`merchant_id`, `order_id`) VALUES (4, 3);
INSERT INTO `test_table_union_index` (`merchant_id`, `order_id`) VALUES (4, 3);
INSERT INTO `test_table_union_index` (`merchant_id`, `order_id`) VALUES (5, 1);
INSERT INTO `test_table_union_index` (`merchant_id`, `order_id`) VALUES (5, 2);
// 查询 SQL EXPLAIN 分析
EXPLAIN SELECT * FROM test_table_union_index WHERE merchant_id = 3 AND order_id = 2;
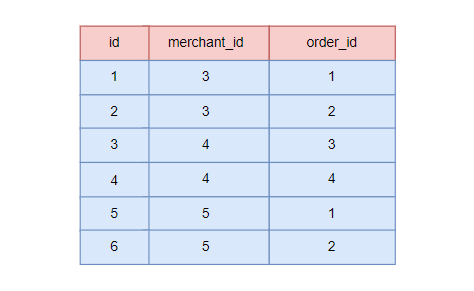
数据创建结果
- SQL 执行完成后,我们可以看到数据库存储了如下数据:
有无联合索引执行情况
// 查询 SQL EXPLAIN 分析
EXPLAIN SELECT * FROM test_table_union_index WHERE merchant_id = 3 AND order_id = 2;
无联合索引

存在联合索引

底层存储结构
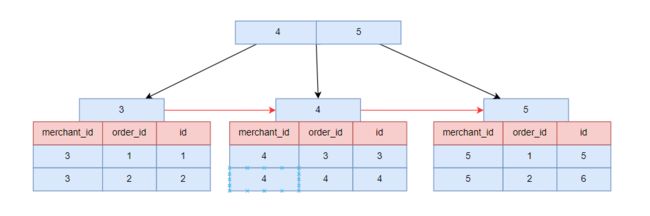
- 上图是联合索引 “merchant_id_order_id_union_index” 的底层存储结构(不一定和 MySQL 数据库底层实现完全一致),我们可以看到除了具有单列索引的特点外,联合索引还具有以下一些特点:
- B+树通过索引首列值构建,如 merchant_id_order_id_union_index 根据 merchant_id 构建。
- 叶子节点拥有联合索引中的所有字段以及主键字段,且叶子节点数据局部有序,如我们有一个三个字段的联合索引(a,b,c):
叶子节点(1):
a,b,c(1,3,3)
a,b,c(1,3,4)
a,b,c(1,4,1)
a,b,c(1,4,2)
叶子节点(2)
a,b,c(2,3,3)
a,b,c(2,3,4)
a,b,c(2,4,1)
a,b,c(2,4,2)
a 列在B+树整体有序,a 列相同的情况下 b 列数据按序排列,但 c列不一定有序。
查询过程
最左匹配原则
- 联合索引遵循最左匹配原则,只能从左往右依次搜索联合索引字段,否则索引字段不生效。
例如索引是 key_index (a,b,c)。 可以支持 a 、a,b 、a,b,c 3种组合进行查找,但不支持 b,c 、c 进行查找。
查询过程解析

SELECT * FROM test_table_union_index WHERE merchant_id = 3 AND order_id = 2;
- 联合索引遵循最左匹配原则,以上述查询 SQL 为例,联合索引先根据 merchant_id = 3 在构建的B+树索引上进行查询数据,找到叶子节点:

- 然后根据 order_id = 2 查询定位数据,查询到数据对应的主键 ID = 2,最后进行回表查询。
联合索引优势
支持复杂查询
- 联合索引能够加速包含多个条件和多个列的查询。这对于联接多个表或需要在多列上进行过滤的查询非常有用。
索引覆盖查询
- 联合索引可以覆盖多个查询中的列,从而减少了数据库的I/O负载。这意味着数据库不必访问数据行,而可以直接使用索引来满足查询条件。
提高排序和分组性能
- 如果你的查询需要排序或分组结果,联合索引可以在这方面提供显著的性能改进,特别是当排序或分组涉及索引中的列时。
减少索引数量
- 使用联合索引可以减少索引的数量,这对于大型数据库来说是一个重要考虑因素,因为每个额外的索引都会增加数据库维护的开销。
使用建议
联合索引的列顺序十分重要
- 确定哪些列应包括在联合索引中,以及它们的顺序非常重要。通常将最频繁用于过滤条件的列放在索引前面。
建议能使用联合索引尽量使用联合索引
- 应该尽可能使用联合索引,但联合索引无法满足需求时可以结合单列索引使用。
常见问题分析
为什么遵循最左匹配原则
- 从联合索引的底层存储结构我们可以知道,联合索引是根据字段从左往右组织的,不从左边的字段开始查询无法使用索引。
联合索引中字段范围查询为什么会导致后续联合索引字段可不用
- 从联合索引的底层存储结构我们可以知道,叶子节点数据局部有序,下面的案例可以清楚饿展示这个问题:
假设存在如下数据:
1(b=1,c=4,d = 10)
2(b=2,c=5,d = 6)
3(b=2,c=5,d = 7)
4(b=3,c=1,d = 2)
5(b=3,c=5,d = 1)
查询条件: b > 1 且 c = 5 , d = 6
先查找 b > 1 :
2(b=2,c=5,d = 6)
3(b=2,c=5,d = 7)
4(b=3,c=1,d = 2)
5(b=3,c=5,d = 1)
再查找 c = 5 , 此时 c 并不是有序的,因此无法使用联合索引字段 c:
2(b=2,c=5,d = 6)
3(b=2,c=5,d = 7)
5(b=3,c=5,d = 1)
综上所述:联合查询中范围查询会导致后续字段数据无序,导致联合索引中后续索引字段失效。
个人简介
你好,我是 Lorin 洛林,一位 Java 后端技术开发者!座右铭:Technology has the power to make the world a better place.
我对技术的热情是我不断学习和分享的动力。我的博客是一个关于Java生态系统、后端开发和最新技术趋势的地方。
作为一个 Java 后端技术爱好者,我不仅热衷于探索语言的新特性和技术的深度,还热衷于分享我的见解和最佳实践。我相信知识的分享和社区合作可以帮助我们共同成长。
在我的博客上,你将找到关于Java核心概念、JVM 底层技术、常用框架如Spring和Mybatis 、MySQL等数据库管理、RabbitMQ、Rocketmq等消息中间件、性能优化等内容的深入文章。我也将分享一些编程技巧和解决问题的方法,以帮助你更好地掌握Java编程。
我鼓励互动和建立社区,因此请留下你的问题、建议或主题请求,让我知道你感兴趣的内容。此外,我将分享最新的互联网和技术资讯,以确保你与技术世界的最新发展保持联系。我期待与你一起在技术之路上前进,一起探讨技术世界的无限可能性。
保持关注我的博客,让我们共同追求技术卓越。