orchestrator数据库高可用组件搭建
一、前言
说一下为什么使用orchestrator作为数据库的高可用组件而不是MHA,因为mha组件存在组件单点问题,而orchestrator组件可以组建集群,不会出现单点问题
二、搭建
搭建mysql gtid主从
参考:mysql主从搭建(gtid)-CSDN博客
上面的主从配置是为了 orchestrator数据库高可用组件的使用,其中有几个配置不能出错
主从配置中的CHANGE MASTER TO MASTER_HOST='rabbitmq02',必须使用主机名,不能使用ip地址,不然在使用orchestrator组件做mysql故障切换时会出问题
还有就是对于主从同步用户的权限配置也是加多了几项,而不是单纯的配置REPLICATION SLAVE权限
搭建orchestrator集群
在github上下载orchestrator的安装包
地址:Releases · openark/orchestrator · GitHub
这里使用三台主机构建orchestrator集群,使用raft协议使用高可用,允许一台主机宕机
| ip | port |
| 10.1.60.118 | 3306、3001 |
| 10.1.60.120 | 3306、3001 |
| 10.1.60.125 | 3306、3001 |
需要先为每台主机安装mysql服务
参考:yum安装mysql 5.7_yum安装mysql5.7_Apex Predator的博客-CSDN博客
创建 orchestrator数据库与用户
mysql -u root -p
create database orchestrator;
create user 'orchestrator'@'%' identified by '11111111';
grant all on orchestrator.* to 'orchestrator'@'%';
flush privileges;
将安装包分别放到三台主机上并解压
mkdir /opt/orchestrator && cd /opt/orchestrator
tar -zxvf orchestrator-3.2.5-linux-amd64.tar.gz && ls

拷贝配置文件(三台主机都需要操作)
cd usr/local/orchestrator/
cp orchestrator-sample.conf.json orchestrator.conf.json
编辑配置文件(三台主机都需要操作)
vi orchestrator.conf.json
{
"Debug": true,
"EnableSyslog": true,
"ListenAddress": ":3001", #默认是使用3000端口,但是我这边有服务被使用了所以改成3001端口
"MySQLTopologyUser": "orchestrator", #配置被监控的主从数据库的用户
"MySQLTopologyPassword": "11111111", #配置被监控的主从数据库的用户密码
"MySQLTopologyCredentialsConfigFile": "",
"MySQLTopologySSLPrivateKeyFile": "",
"MySQLTopologySSLCertFile": "",
"MySQLTopologySSLCAFile": "",
"MySQLTopologySSLSkipVerify": true,
"MySQLTopologyUseMutualTLS": false,
"MySQLOrchestratorHost": "10.1.60.125", #配置orchestrator组件服务本机地址
"MySQLOrchestratorPort": 3306, #配置orchestrator组件服务数据库端口
"MySQLOrchestratorDatabase": "orchestrator", #配置orchestrator组件数据库
"MySQLOrchestratorUser": "orchestrator", #配置orchestrator数据库用户
"MySQLOrchestratorPassword": "11111111", ##配置orchestrator数据库用户密码
"MySQLOrchestratorCredentialsConfigFile": "",
"MySQLOrchestratorSSLPrivateKeyFile": "",
"MySQLOrchestratorSSLCertFile": "",
"MySQLOrchestratorSSLCAFile": "",
"MySQLOrchestratorSSLSkipVerify": true,
"MySQLOrchestratorUseMutualTLS": false,
"MySQLConnectTimeoutSeconds": 1,
"RaftEnabled": true, #启用raft配置,以下配置默认是没有的,需要手动加上
"RaftDataDir": "/opt/orchestrator", #配置orchestrator安装包地址
"RaftBind": "10.1.60.125", #配置orchestrator组件服务本机地址
"DefaultRaftPort": 10008, #配置raft服务端口
"RaftNodes": [ #配置orchestrator组件集群地址
"10.1.60.118",
"10.1.60.120",
"10.1.60.125"
],
"DefaultInstancePort": 3306,
"DiscoverByShowSlaveHosts": true,
"InstancePollSeconds": 5,
"DiscoveryIgnoreReplicaHostnameFilters": [
"a_host_i_want_to_ignore[.]example[.]com",
".*[.]ignore_all_hosts_from_this_domain[.]example[.]com",
"a_host_with_extra_port_i_want_to_ignore[.]example[.]com:3307"
],
"UnseenInstanceForgetHours": 240,
"SnapshotTopologiesIntervalHours": 0,
"InstanceBulkOperationsWaitTimeoutSeconds": 10,
"HostnameResolveMethod": "None", #此处需要更改为None,默认是default,使用默认的后面通过主机名添加mysql主从的时候会查找不到
"MySQLHostnameResolveMethod": "SELECT concat(@@report_host,':',@@port)", #此处也需要更改为report_host模式
"SkipBinlogServerUnresolveCheck": true,
"ExpiryHostnameResolvesMinutes": 60,
"RejectHostnameResolvePattern": "",
"ReasonableReplicationLagSeconds": 10,
"ProblemIgnoreHostnameFilters": [],
"VerifyReplicationFilters": false,
"ReasonableMaintenanceReplicationLagSeconds": 20,
"CandidateInstanceExpireMinutes": 60,
"AuditLogFile": "",
"AuditToSyslog": false,
"RemoveTextFromHostnameDisplay": ":3306",
"ReadOnly": false,
"AuthenticationMethod": "",
"HTTPAuthUser": "",
"HTTPAuthPassword": "",
"AuthUserHeader": "",
"PowerAuthUsers": [
"*"
],
"ClusterNameToAlias": {
"127.0.0.1": "test suite"
},
"ReplicationLagQuery": "",
"DetectClusterAliasQuery": "SELECT SUBSTRING_INDEX(@@hostname, '.', 1)",
"DetectClusterDomainQuery": "",
"DetectInstanceAliasQuery": "",
"DetectPromotionRuleQuery": "",
"DataCenterPattern": "[.]([^.]+)[.][^.]+[.]mydomain[.]com",
"PhysicalEnvironmentPattern": "[.]([^.]+[.][^.]+)[.]mydomain[.]com",
"PromotionIgnoreHostnameFilters": [],
"DetectSemiSyncEnforcedQuery": "",
"ServeAgentsHttp": false,
"AgentsServerPort": ":3001", #此处也需要更改orchestrator组件默认的端口号
"AgentsUseSSL": false,
"AgentsUseMutualTLS": false,
"AgentSSLSkipVerify": false,
"AgentSSLPrivateKeyFile": "",
"AgentSSLCertFile": "",
"AgentSSLCAFile": "",
"AgentSSLValidOUs": [],
"UseSSL": false,
"UseMutualTLS": false,
"SSLSkipVerify": false,
"SSLPrivateKeyFile": "",
"SSLCertFile": "",
"SSLCAFile": "",
"SSLValidOUs": [],
"URLPrefix": "",
"StatusEndpoint": "/api/status",
"StatusSimpleHealth": true,
"StatusOUVerify": false,
"AgentPollMinutes": 60,
"UnseenAgentForgetHours": 6,
"StaleSeedFailMinutes": 60,
"SeedAcceptableBytesDiff": 8192,
"PseudoGTIDPattern": "",
"PseudoGTIDPatternIsFixedSubstring": false,
"PseudoGTIDMonotonicHint": "asc:",
"DetectPseudoGTIDQuery": "",
"BinlogEventsChunkSize": 10000,
"SkipBinlogEventsContaining": [],
"ReduceReplicationAnalysisCount": true,
"FailureDetectionPeriodBlockMinutes": 60,
"FailMasterPromotionOnLagMinutes": 0,
"RecoveryPeriodBlockSeconds": 3600,
"RecoveryIgnoreHostnameFilters": [],
"RecoverMasterClusterFilters": ["*"], #需要更改默认配置,改为*,不然主从故障自动切换不会生效
"RecoverIntermediateMasterClusterFilters": ["*"], #需要更改默认配置,改为*,不然主从故障自动切换不会生效
"OnFailureDetectionProcesses": [
"echo 'Detected {failureType} on {failureCluster}. Affected replicas: {countSlaves}' >> /tmp/recovery.log"
],
"PreGracefulTakeoverProcesses": [
"echo 'Planned takeover about to take place on {failureCluster}. Master will switch to read_only' >> /tmp/recovery.log"
],
"PreFailoverProcesses": [
"echo 'Will recover from {failureType} on {failureCluster}' >> /tmp/recovery.log"
],
"PostFailoverProcesses": [
"echo '(for all types) Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Successor: {successorHost}:{successorPort}' >> /tmp/recovery.log"
],
"PostUnsuccessfulFailoverProcesses": [],
"PostMasterFailoverProcesses": [
"echo 'Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Promoted: {successorHost}:{successorPort}' >> /tmp/recovery.log"
],
"PostIntermediateMasterFailoverProcesses": [
"echo 'Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Successor: {successorHost}:{successorPort}' >> /tmp/recovery.log"
],
"PostGracefulTakeoverProcesses": [
"echo 'Planned takeover complete' >> /tmp/recovery.log"
],
"CoMasterRecoveryMustPromoteOtherCoMaster": true,
"DetachLostSlavesAfterMasterFailover": true,
"ApplyMySQLPromotionAfterMasterFailover": true,
"PreventCrossDataCenterMasterFailover": false,
"PreventCrossRegionMasterFailover": false,
"MasterFailoverDetachReplicaMasterHost": false,
"MasterFailoverLostInstancesDowntimeMinutes": 0,
"PostponeReplicaRecoveryOnLagMinutes": 0,
"OSCIgnoreHostnameFilters": [],
"GraphiteAddr": "",
"GraphitePath": "",
"GraphiteConvertHostnameDotsToUnderscores": true,
"ConsulAddress": "",
"ConsulAclToken": "",
"ConsulKVStoreProvider": "consul"
}启动orchestrator组件服务
nohup ./orchestrator http &>./orchestrator.log&
查看orchestrator组件服务是否正常
netstat -tlpn |grep 3001

访问 orchestrator组件web
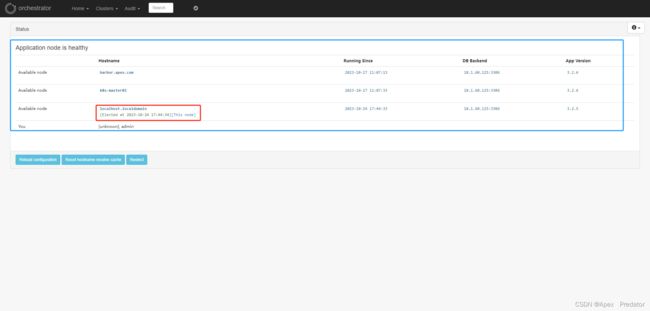
接下来添加mysql主从,只需添加主从中的任意一台就会自动识别整个主从架构
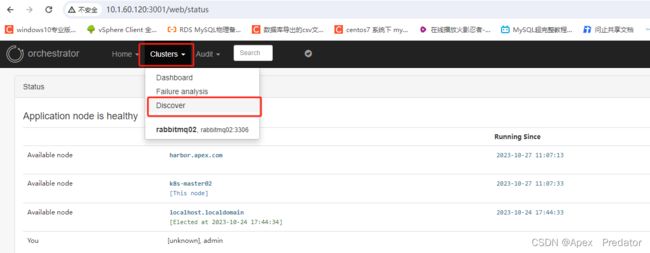


关于主从故障的测试就不再演示了,可以自行操作,但是原来挂掉的主数据库重新启动后需要手动配置slave服务才能重新在加入主从架构中