IMX6ULL —— 字符编码方式和实现
前言:
使用的开发板为韦东山老师的 IMX6ULL
目录
字符的编码方式
编码与字体
1.ASCII
2.ANSI
3.UNICODE
UNICODE 编码实现
1.使用 3 个字节表示一个 UNICODE
2.UCS-2 Little endian/UTF-16 LE
3.UCS-2 Big endian/UTF-16 BE
4.UTF8
字符的编码方式
编码与字体
在计算机上,我们看到的字符“A”可能长这样:![]()
也可能长这样:![]()
对于同一个 TXT 文件中的内容,你在 Notepad 上选择不同字体时,字符显示的形状不一样。
所以 TXT 文件中保存的是字符的核心:它的编码值。而 Notepad 上显示时, 这些字符对应什么样的形状态,这是由字符文件决定的。编码值,字体是两个不一样的东西,比如 A 的编码值是 0x41,但是在屏幕上显示出来时可以使用不同的形状。
什么叫编码?
就是一个字符用什么数字来表示。在计算机里一切都是用数字 来表示,比如字符 A,用 0x01 还是 0x02 来表示它?我们使用 0x41 来表示它。 当你去打开一个 TXT 文件时,发现里面含有数值 0x41,你就知道了:哦,这里 有一个字符 A。
1.ASCII
是“American Standard Code for Information Interchange”的缩 写,美国信息交换标准代码。
电脑毕竟是西方人发明的,他们常用字母就 26 个,区分大小写、加上标点符号也没超过 127 个,每个字符用一个字节来表示就足够了。一个字节的 7 位就 可以表示 128 个数值,在 ASCII 码中最高位永远是 0。
字符和数值的对应关系百度百科-验证
部分如下:

2.ANSI
使用记事本保存文件时,可以选择“ANSI”编码,却没有“ASCII”,怎么回事?
ASNI 是 ASCII 的扩展,向下包含 ASCII。
对于 ASCII 字符仍以一个字节来表示,对于非 ASCII 字符则使用 2 字节来表示。并没有固定的 ASNI 编码,它跟 “本地化”(locale)密切相关。比如在中国大陆地区,ANSI 的默认编码是 GB2312; 在港澳台地区默认编码是 BIG5。以数值“0xd0d6”为例,对于 GB2312 编码它表示“中”;对于 BIG5 编码它表示“笢”。所以对于 ANSI 编码的 TXT 文件,如果你打开它发现乱码,那么还得再次细分它的具体编码。
比如对于一个 TXT 文件,里面的数值如下: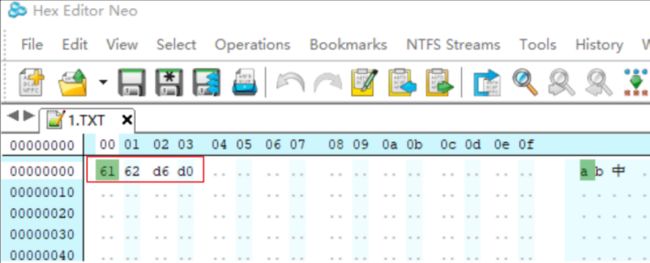
使用 Notepad 打开后,选择不同的编码(或称为字符集),有不一样的显示, 如下:

这仅仅是在中国地区就出现这些不兼容的问题。对于不同国家,它们默认的 ANSI 编码各不相同,所以同一个 TXT 文件在不同国家就很有可能出现乱码。 根本的原理在于没有“统一的编码”,那解决方法自然就是使用“统一的编 码”:UNICODE。
3.UNICODE
在 ANSI 标准中,很多种文字都有自己的编码标准,汉字简体字有 GB2312、 繁体字有 BIG5,这难免同一个数值对应不同字符。比如数值“0xd0d6”,对于 GB2312 编码它表示“中”;对于 BIG5 编码它表示“笢”。这造成了使用 ANSI 编 码保存的文件,不适合跨地区交流。
UNICODE 编码就是解决这类问题:对于地球上任意一个字符,都给它一个唯一的数值。 UNICODE 仍然向下兼容 ASCII,但是对于其他字符会有对应的数值,比如对 于“中”、“笢”,它们的数值分别是:0x4e2d、0x7b22
UNICODE 中的数值范围是 0x0000 至 0x10FFFF,有 1,114,111 即 100 多万个数值,可以表示 100 多万个字符,足够我们使用了。
UNICODE 编码实现
所谓编码实现,就是对于一个数值,怎么表示它。这很奇怪,数值还能怎么表示?
比如“中”的 UNICODE 值是 0x4e2d,在 TXT 文件中怎么表示 0x4e2d? 直接写入 0x4e2d?不行!
比如在 TXT 文件中写入 2 字节数据“0x2d 0x4e”,它可以用来表示“中” 字吗?不能!它们对应 ASCII 字符“-N”。
问题的关键在于:怎么断字。在 TXT 文件中,2 字节数据“0x2d 0x4e”是作为一个整体看待,还是拆成 2 部分看待?
所以,需要用一定的技巧来表示数值,这就对应不同的编码实现。
现在我们知道:
- ASCII 编码中使用一个字节来表示一个字符,只用到其中的 7 位,最高位恒为 0;
- ANSI 编码中,对于 ASCII 字符仍使用一个字节来表示(BIT7 是 0),对于非 ASCII 字符一般使用 2 个字节来表示,非 ASCII 字符的数值 BIT7 都是 1。
UNICODE:比较复杂
先用记事本新建 3 个文件:utf-16_le.txt、utf-16_be.txt、utf-8.txt、 bom_utf-8.txt,里面的内容都是“ab 中”,保存时编码分别选择“UTF-16 LE”、 “UTF-16 BE”、“UTF-8”、“带有 BOM 的 UTF-8”
怎么表示一个 UNICODE 数值?
1.使用 3 个字节表示一个 UNICODE
不,太浪费。
UNICODE 的最大值是 0x10FFFF,那使用 3 个字节来表示一个 UNICODE 数 值?这当然是很省事的方法,但是会造成浪费,比如字符 A 的 UNICOCDE 值是 0x41,难道也用“0x41 0x00 0x00”这 3 个字节来表示?
2.UCS-2 Little endian/UTF-16 LE
每个 UNICODE 值用 3 字节来表示有点浪费,那只用 2 字节呢?它可以表示 2^16=65536 个字符,全世界常用的字符都可以表示了。
Little endian 表示小字节序,数值中权重低的字节放在前面,比如字符 “A 中”在 TXT 文件中的数值如下,其中的“A”使用“0x41 0x00”两字节表 示;“中”使用“0x2d 0x4e”两字节表示。文件开头的“0xff 0xfe”表示“UTF-16 LE
3.UCS-2 Big endian/UTF-16 BE
Big endian 表示大字节序,数值中权重低的字节放在后面,比如字符“ab 中”在 TXT 文件中的数值如下,其中的“A”使用“0x00 0x41”两字节表示; “中”使用“0x4e 0x2d”两字节表示。文件开头的“0xfe 0xff”表示“UTF-16 BE
4.UTF8
在上面 2 种方法中,每一个 UNICODE 使用 2 字节来表示,这有 3 个缺点: 表示的字符数量有限、对于 ASCII 字符有空间浪费、如果文件中有某个字节丢 失,这会使得后面所有字符都因为错位而无法显示。 使用 UTF8 可以解决上述所有问题。UTF8 是变长的编码方法,有 2 种 UTF8 格式的文件:带有头部、不带头部。先举例,看图 对于其中的 ASCII 字符,在 UTF8 文件中直接用其 ASCII 码来表示,比如上图中的 0x61 表示字符 a、0x62 表示字符 b。上图中的 3 个字节“0xe4 0xb8 0xad”表示的数值是 0x4e2d,对应“中”的 UNICODE 码。
对于其中的 ASCII 字符,在 UTF8 文件中直接用其 ASCII 码来表示,比如上图中的 0x61 表示字符 a、0x62 表示字符 b。上图中的 3 个字节“0xe4 0xb8 0xad”表示的数值是 0x4e2d,对应“中”的 UNICODE 码。
对于非 ASCII 字符,使用变长的编码:每一个字节的高位都自带长度信息。 上图中,0xe4 的二进制是“11100100”,高位有 3 个 1,表示从当前字节起 有 3 字节参与表示 UNICODE;
上图中,0xe4 的二进制是“11100100”,高位有 3 个 1,表示从当前字节起 有 3 字节参与表示 UNICODE;
0xb8 的二进制是“10111000”,高位有 1 个 1,表示从当前字节起有 1 字节 参与表示 UNICODE;
0xad 的二进制是“10101101”,高位有 1 个 1,表示从当前字节起有 1 字节 参与表示 UNICODE;
除去高位的“1110”、“10”、“10”后,剩下的二进制数组合起来得到 “01001110001101”,它就是 0x4e2d,即“中”的 UNICODE 值。
使用 UTF8 编码时,即使 TXT 文件中丢失了某些数据,也只会影响到当前字符的显示,后面的字符不受影响。