Pytorch(四):神经网络之torch.nn——containers
神经网络(Nueral Networks) 是由对数据进行操作的一些 层(layer) 或 模块(module) 所组成,而PyTorch 中的每个模块都是 nn.Module 的子类,在调用或自定义时均需继承 nn.Module 类。同时 torch.nn 包为我们提供了构建神经网络所需的各种模块,当然一个神经网络本身也是一个由其他 模块/层 组成的模块,这种嵌套结构就允许我们构建更为复杂的网络架构。
在开始搭建神经网络之前先了解下 torch.nn 包,它包含了用于搭建神经网络的所有基础模块,其中有些是经常使用的,如卷积层、池化层、激活函数、损失函数等等,本文会简单记录一下 containers 中常用的类型。

目录
-
- 1. class torch.nn.Module
-
- 1.1 cuda(device=None)
- 1.2 cpu()
- 1.3 eval()
- 1.4 train(mode=True)
- 1.5 load_state_dict(state_dict, strict=True)
- 1.6 to(*args, **kwargs)
- 1.7 zero_grad(set_to_none=False)
- 2. class torch.nn.Sequential()
- 3. class torch.nn.ModuleList(modules=None)
-
- 3.1 append(module)
- 3.2 extend(module)
- 3.3 insert(index, module)
- 4. class torch.nn.ModuleDict(modules=None)
1. class torch.nn.Module
该类是用于所有神经网络模块的 基类,并且所有自定义模型也应继承该类。如上面所说,神经网络本身就是一个模块,即一个模块也可以包含其他的模块,从而构成一个嵌套树状结构。
用于构建网络的子模块可以被分配为常规属性,如下代码使用了两个卷积层,并且以这种方式分配的子模块也会被注册。
例如:
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
model = Model()
print(model)

nn.Module 具有非常多的属性,我只列举其中的几项,需要的话可以去官网查看 torch.nn.Module
1.1 cuda(device=None)
参数:
device:可选参数,类型为整型,若给出该参数,那么模型的参数和buffers 都将移动至该设备上。
能够将所有 模型参数和buffers 复制到 GPU 上运行,这使得关联的参数和buffers 成为不同的对象。
import torch
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 定义GPU
model = Model()
print(next(model.parameters()).device)
model.cuda(device)
print(next(model.parameters()).device)

1.2 cpu()
能够将所有的 模型参数和buffer 移动到CPU上运行。
1.3 eval()
该方法可将模型设置为评估模式。
1.4 train(mode=True)
该方法可将模块设置为训练模式。
参数:
mode:类型为bool,表示是否设置为训练模式True或评估模式False。 默认值为True。
1.5 load_state_dict(state_dict, strict=True)
该方法可将 state_dict 中的参数和缓冲区复制到此模块中。 如果 strict=True ,则 state_dict 的键必须与此模块的 state_dict() 函数返回的键完全匹配。
1.6 to(*args, **kwargs)
- 该方法可以移动或转换模型的参数与 buffers,类似于
torch.Tensor.to(),但只接受浮点型或复数类型。 - 此方法只会将浮点数或复数参数和buffers强制转换为给定的参数
dtype,而积分参数和缓冲区将被移动至给定的参数device但保持 dtypes 不变。 - 当设置
non_blocking时,它会尽可能地尝试相对于主机异步转换/移动,例如,将带有固定内存的 CPU 张量移动到 CUDA 设备。
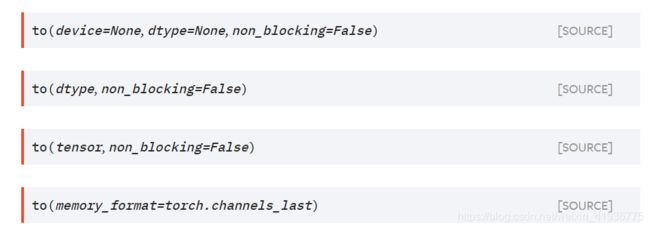
参数: device:类型为torch.device,表示模块中参数和缓冲区的所需设备;dtype:类型为torch.dtype,表示模块中参数所需的浮点数或复数数据类型以及缓冲区;tensor:类型为torch.Tensor,表示dtype和device是此模块中所有参数和缓冲区所需的dtype和device的tensor。memory_format:类型为torch.memory_format,表示此模块中 4D 参数和缓冲区所需的内存格式。
下面的代码展示了将 CPU 上的模型移动到 GPU 上,其他类型可以自己随便写一下代码。
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 定义GPU
model = Model()
print(next(model.parameters()).device)
model.to(device) # 转化为GPU
print(next(model.parameters()).device)

1.7 zero_grad(set_to_none=False)
该方法可将所有模型参数的梯度设置为零。
参数:
set_to_none:类型为bool,作用是将grads设置为None而不是零,默认是False。
2. class torch.nn.Sequential()
该类表示一个 序列容器,模块或层将按照它们在构造函数中传递的顺序添加到该容器中,含有模块或层的有序字典也可以使用该容器。
例如:
import torch.nn as nn
# Example of using Sequential
model = nn.Sequential(
nn.Conv2d(1, 20, 5),
nn.ReLU(),
nn.Conv2d(20, 64, 5),
nn.ReLU()
)
print(model)

import torch.nn as nn
from collections import OrderedDict
# Example of using Sequential with OrderedDict
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1, 20, 5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20, 64, 5)),
('relu2', nn.ReLU())
]))
print(model)

3. class torch.nn.ModuleList(modules=None)
参数:
modules:可选参数,表示一组要添加的可迭代模块对象。
该类可将一系列子模块保存至列表 ModuleList 中,并且 ModuleList 可以像常规的 Python 列表一样索引。
例如:
import torch
import torch.nn as nn
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.linears = nn.ModuleList([nn.Linear(5, 5) for i in range(5)])
def forward(self, x):
# ModuleList can act as an iterable, or be indexed using ints
for i, layer in enumerate(self.linears):
x = self.linears[i // 2](x) + layer(x)
return x
model = MyModule()
print(model)
input_data = torch.randn(5, 5)
output_data = model(input_data)
print(output_data)
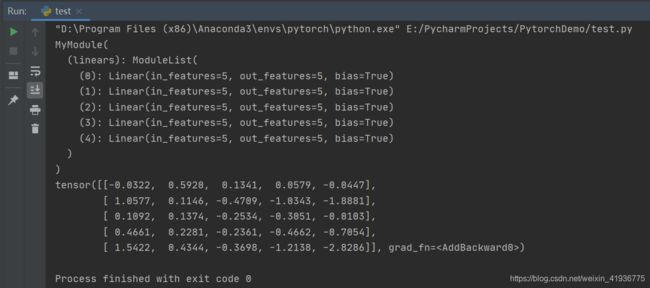
nn.ModuleList 还具有以下三种属性:
3.1 append(module)
module:类型是nn.module,表示用于扩充的模块。
表示将一个给定的模块或层添加至 ModuleList 的末尾。
import torch
import torch.nn as nn
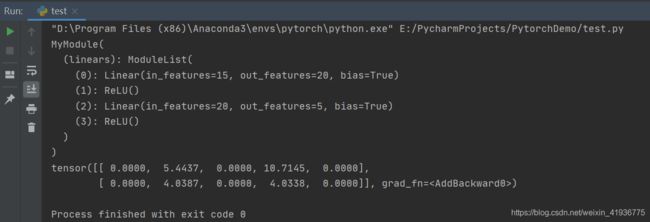
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.linears = nn.ModuleList([nn.Linear(15, 20), nn.ReLU(), nn.Linear(20, 5)])
self.linears.append(nn.ReLU())
def forward(self, x):
# ModuleList can act as an iterable, or be indexed using ints
for i, layer in enumerate(self.linears):
x = self.linears[i](x) + layer(x)
return x
model = MyModule()
print(model)
input_data = torch.randn(2, 15)
output_data = model(input_data)
print(output_data)
3.2 extend(module)
module:类型是可迭代的模块对象,表示用于添加的模块。
表示将 Python 可迭代模块中的模块附加到 ModuleList 的末尾。
import torch
import torch.nn as nn
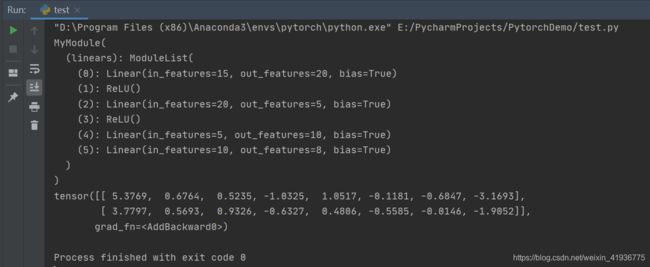
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.linears = nn.ModuleList([nn.Linear(15, 20), nn.ReLU(), nn.Linear(20, 5)])
self.linears.extend([nn.ReLU(), nn.Linear(5, 10), nn.Linear(10, 8)])
def forward(self, x):
# ModuleList can act as an iterable, or be indexed using ints
for i, layer in enumerate(self.linears):
x = self.linears[i](x) + layer(x)
return x
model = MyModule()
print(model)
input_data = torch.randn(2, 15)
output_data = model(input_data)
print(output_data)
3.3 insert(index, module)
index:类型是整型,表示插入模块的索引位置;module:类型是nn.module,表示插入的模块。
表示在 ModuleList 中的给定索引之前插入给定模块。
import torch
import torch.nn as nn
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.linears = nn.ModuleList([nn.Linear(15, 20), nn.ReLU(), nn.Linear(20, 5)])
self.linears.insert(1, nn.Linear(20, 20))
def forward(self, x):
# ModuleList can act as an iterable, or be indexed using ints
for i, layer in enumerate(self.linears):
x = self.linears[i](x) + layer(x)
return x
model = MyModule()
print(model)
input_data = torch.randn(2, 15)
output_data = model(input_data)
print(output_data)
4. class torch.nn.ModuleDict(modules=None)
该类可将子模块保存在一个字典中,ModuleDict 可以像常规 Python 字典一样被索引,同时 ModuleDict 是一个有序的字典:
- 遵循插入顺序;
- 遵循在
update()方法中,合并的OrderedDict、dict、ModuleDict的顺序。
参数:
modules:可选参数,类型为可迭代模块对象,表示一组string: module的映射/字典,或类型为string: module的键值对的可迭代对象。
例如:
import torch
import torch.nn as nn
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.choices = nn.ModuleDict({
'conv': nn.Conv2d(10, 10, 3),
'pool': nn.MaxPool2d(3)
})
self.activations = nn.ModuleDict([
['lrelu', nn.LeakyReLU()],
['prelu', nn.PReLU()]
])
def forward(self, x, choice, act):
x = self.choices[choice](x)
x = self.activations[act](x)
return x
# device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 定义GPU
model = MyModule()
print(model)
#
# model.cuda(device)
input_data = torch.randn(1, 10, 12, 12)
output_data = model(input_data, 'conv', 'prelu')
print(output_data)
该类有几下几种方法:
| 方法 | 作用 |
|---|---|
| clear() | 从 ModuleDict 中删除所有子模块 |
| items() | 返回 ModuleDict 键/值对形式的可迭代对象 |
| keys() | 将 ModuleDict 中的键以一个可迭代对象返回 |
| values() | 将 ModuleDict 中的值以一个可迭代对象返回 |
| pop(key) | 将 ModuleDict 中的键 key 删除并返回模块名称,key 类型为字符串,表示从 ModuleDict 中删除的键 |
| update(modules) | 使用来自映射或可迭代的键值对覆盖现有键,从而更新 ModuleDict。 modules 表示一个从字符串到模块的映射/字典,或类型为 (string, module) 的键值对的可迭代对象。如果 modules 是 OrderedDict、ModuleDict 或键值对的可迭代对象,则保留其中新元素的顺序。 |
除上述提到的几种容器类型,containers 中还包含:
ParameterLisrt;ParameterDict;
以及三种 Global Hooks For Module :
register_module_forward_pre_hook;register_module_forward_hook;register_module_backward_hook。
剩下的这几种目前还没有用到,所以就先不记录了。仅仅看一遍这些定义并不能掌握方法的使用,需要结合实例学习不同的应用方式,fighting~