Spring的循环依赖问题
文章目录
- 1.什么是循环依赖
- 2.代码演示
- 3.分析问题
- 4.问题解决
- 5.Spring循环依赖
- 6. 疑问点
-
- 6.1 为什么需要三级缓存
- 6.2 没有三级缓存能解决吗?
- 6.3 三级缓存分别什么作用
1.什么是循环依赖
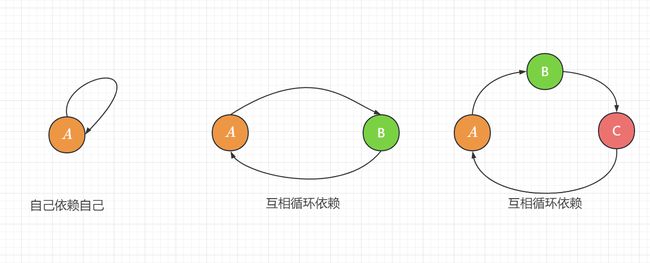
上图是循环依赖的三种情况,虽然方式有点不一样,但是循环依赖的本质是一样的,就你的完整创建要依赖与我,我的完整创建也依赖于你。相互依赖从而没法完整创建造成失败。
2.代码演示
public class CircularTest {
public static void main(String[] args) {
// 出现了循环依赖的情况,死循环-OOM
new CircularServiceA();
}
}
class CircularServiceA {
// A 中依赖了 B
private CircularServiceB circularServiceB = new CircularServiceB();
}
class CircularServiceB {
// B 中依赖了 A
private CircularServiceA circularServiceA = new CircularServiceA();
}
执行后出现了 StackOverflowError 错误:

上面的就是最基本的循环依赖的场景,你需要我,我需要你,然后就报错了。而且上面的这种设计情况我们是没有办法解决的。那么针对这种场景我们应该要怎么设计呢?这个是关键!
3.分析问题
首先我们要明确一点就是如果这个对象 A 还没创建成功,在创建的过程中要依赖另一个对象 B,而另一个对象 B 也是在创建中要依赖对象 A,这种肯定是无解的。
这时我们就要转换思路,我们先把 A 创建出来,但是还没有完成初始化操作,也就是这是一个半成品的对象,然后在赋值的时候先把 A 暴露出来,然后创建B,让 B 创建完成后找到暴露的 A 完成整体的实例化,这时再把 B 交给 A,完成 A 的后续操作,从而揭开了循环依赖的密码。

4.问题解决
明白了上面的本质后,我们可以自己来尝试解决下。先来把上面的案例改为 set/get 来依赖关联,然后我们再通过把对象实例化和成员变量赋值拆解开来处理。从而解决循环依赖的问题。
public class CircularTest {
public static void main(String[] args) throws Exception {
// 需要把构造方法和属性赋值作为一个整体,需要提供一个获取实例对象的方法
System.out.println(getBean(CircularServiceA.class).getCircularServiceB()); // com.zhulang.circular.CircularServiceB@74a14482
System.out.println(getBean(CircularServiceB.class)); // com.zhulang.circular.CircularServiceB@74a14482
}
// 存储半成品的容器,解决半成品的关键点
private static final Map<String, Object> singletonObjects = new ConcurrentHashMap<>();
/**
* 根据类型获取对应的实例对象
* 1.完成构造
* 2.完成成员变量的赋值
*
* @param className
* @param
* @return
* @throws Exception
*/
@SuppressWarnings("unchecked")
public static <T> T getBean(Class<T> className) throws Exception {
// 1.获取类对象对应的名称
String beanName = className.getSimpleName().toLowerCase();
// 2.根据名称去 singletonObjects 中查看是否有半成品的对象
if (singletonObjects.containsKey(beanName)) {
return (T) singletonObjects.get(beanName);
}
// 3.singletonObjects 没有半成品的对象,那么就反射实例化对象
T t = className.newInstance();
// 4.把这个半成品对象存储在 singletonObjects 中
singletonObjects.put(beanName, t);
// 5.获取所有的成员变量
Field[] declaredFields = className.getDeclaredFields();
// 6.遍历成员变量,依次赋值
for (Field field : declaredFields) {
// 6.1 进行爆破,针对 private 修饰的对象
field.setAccessible(true);
// 6.2 获取成员变量 对应的类对象
Class<?> fieldType = field.getType();
// 6.3 给成员变量赋值 如果 singletonObjects 中有半成品就获取,否则创建对象
field.set(t, getBean(fieldType));
}
return t;
}
}
class CircularServiceA {
// A 中依赖了 B
private CircularServiceB circularServiceB;
public CircularServiceB getCircularServiceB() {
return circularServiceB;
}
public void setCircularServiceB(CircularServiceB circularServiceB) {
this.circularServiceB = circularServiceB;
}
}
class CircularServiceB {
// B 中依赖了 A
private CircularServiceA circularServiceA;
public CircularServiceA getCircularServiceA() {
return circularServiceA;
}
public void setCircularServiceA(CircularServiceA circularServiceA) {
this.circularServiceA = circularServiceA;
}
}
在上面的方法中的核心是 getBean 方法,A 创建后填充属性时依赖 B,那么就去创建 B,在创建 B 开始填充时发现依赖于 A,但此时 A 这个半成品对象已经存放在缓存到 singletonObjects 中了,所以 B 可以正常创建,在通过递归把 A 也创建完整了。
最后总结下该案例解决的本质:
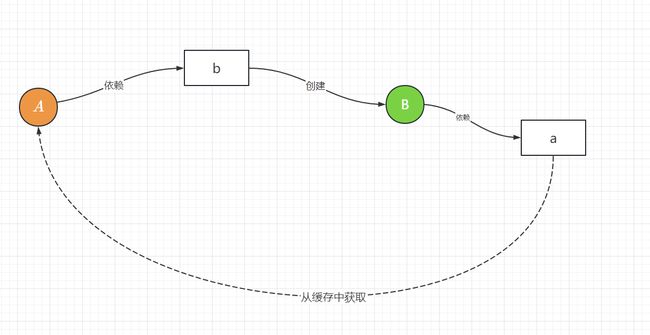
5.Spring循环依赖
刚刚上面的案例中的对象的生命周期的核心就两个:
- 创建对象
- 属性填充
然后我们再来看看 Spring 中是如何解决循环依赖问题的呢?Spring 创建 Bean 的生命周期中涉及到的方法就很多了。下面是简单列举了对应的方法。

基于前面案例的了解,我们知道肯定需要在调用构造方法方法创建完成后再暴露对象,在 Spring 中提供了三级缓存来处理这个事情,对应的处理节点如下图:

-
一级缓存:存储的是 成品Bean 对象 ,存储的所有的单例对象,其实可以说和循环依赖没有关系。
-
二级缓存:存储的是 半成品对象,是解决循环依赖的关键,如果不去考虑 AOP 代理增加的情况,只有二级缓存的情况下也是可以解决循环依赖的,也就是不需要三级缓存。
-
三级缓存:三级缓存存在的意义是解决 AOP 增强对象的原因,存储的是一个 Lambda 表达式(内部类)–> ObjectFactory。
对应到源码中具体处理循环依赖的流程如下:

上面就是在Spring的生命周期方法中和循环依赖出现相关的流程了。那么源码中的具体处理是怎么样的呢?我们继续往下面看。
首先在调用构造方法的后会放入到三级缓存中

下面就是放入三级缓存的逻辑
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
// 使用singletonObjects进行加锁,保证线程安全
synchronized (this.singletonObjects) {
// 如果单例对象的高速缓存【beam名称-bean实例】没有beanName的对象
if (!this.singletonObjects.containsKey(beanName)) {
// 将beanName,singletonFactory放到单例工厂的缓存【bean名称 - ObjectFactory】
this.singletonFactories.put(beanName, singletonFactory);
// 从早期单例对象的高速缓存【bean名称-bean实例】 移除beanName的相关缓存对象
this.earlySingletonObjects.remove(beanName);
// 将beanName添加已注册的单例集中
this.registeredSingletons.add(beanName);
}
}
}
然后在填充属性的时候会存入二级缓存中
earlySingletonObjects.put(beanName,bean);
registeredSingletons.add(beanName);
最后把创建的对象保存在了一级缓存中
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
// 将映射关系添加到单例对象的高速缓存中
this.singletonObjects.put(beanName, singletonObject);
// 移除beanName在单例工厂缓存中的数据
this.singletonFactories.remove(beanName);
// 移除beanName在早期单例对象的高速缓存的数据
this.earlySingletonObjects.remove(beanName);
// 将beanName添加到已注册的单例集中
this.registeredSingletons.add(beanName);
}
}
6. 疑问点
6.1 为什么需要三级缓存
三级缓存主要处理的是 AOP 的代理对象,存储的是一个 ObjectFactory。
三级缓存考虑的是带你对象,而二级缓存考虑的是性能-从三级缓存的工厂里创建出对象,再扔到二级缓存(这样就不用每次都要从工厂里拿)。
6.2 没有三级缓存能解决吗?
没有三级缓存是可以解决循环依赖问题的。
6.3 三级缓存分别什么作用
一级缓存:正式对象
二级缓存:半成品对象
三级缓存:工厂
在 Spring 框架中,singletonObjects、earlySingletonObjects 和 singletonFactories 是三个不同的数据结构,用于管理单例 Bean 的创建和缓存。
-
singletonObjects:该数据结构是一个哈希表,以 Bean 名称为键,存储已经完全初始化的单例 Bean 实例。当我们通过ApplicationContext.getBean() 方法请求获取一个单例 Bean 时,Spring 首先会从 singletonObjects 中查找是否存在该 Bean的实例,如果存在,则直接返回;如果不存在,则创建一个新的实例,并将其添加到 singletonObjects 中。 -
earlySingletonObjects:该数据结构也是一个哈希表,以 Bean 名称为键,存储正在创建过程中但尚未完全初始化的单例 Bean 实例。当 Spring 创建一个单例 Bean 时,它会先将其实例化并放入 earlySingletonObjects 中。在 Bean 的创建过程中,如果其他 Bean 有对该 Bean 的循环引用,就会出现循环依赖的情况,此时 Spring 会从 earlySingletonObjects 中获取到该 Bean 的早期实例,以解决循环依赖的问题。待 Bean 创建完成后,Spring 会将其从 earlySingletonObjects 移除,并放入 singletonObjects 中。 -
singletonFactories:该数据结构是一个哈希表,以 Bean 名称为键,存储用于创建单例 Bean 实例的工厂对象。这是真正打破循环依赖的 Map,缓存的是 ObjectFactory,也就是 Lambda 表达式,在每个 Bean 的生成过程中,经过实例化得到一个原始对象后,都会提前基于原始对象暴露一个 Lambda 表达式,并保存在三级缓存中。这个 Lambda 表达式可能用到,也可能用不到,如果当前 Bean 没有出现循环依赖,那么这个 Lambda 表达式没用,当前 bean 按照自己的生命周期正常执行,执行完后直接把当前 bean 放入 singletonObjects 中。如果当前 bean 在依赖注入时发现出现了循环依赖(当前正在创建的 bean 被其它 bean 依赖了),则从三级缓存中拿到 Lambda 表达式,并执行 Lambda 表达式得到一个对象,把得到的对象放入二级缓存。如果当前 bean 需要 AOP,那么执行 Lambda 表达式得到的是对应的代理对象,如果无需 AOP,则直接得到一个原始对象。
综上所述,singletonObjects 用于缓存已完全初始化的单例 Bean 实例,earlySingletonObjects 用于缓存正在创建中的单例 Bean 实例,singletonFactories 则是用于缓存用于创建单例 Bean 实例的 Factory 对象。这三个数据结构共同协作,确保了单例 Bean 的正确创建和管理。