Kafka和RocketMQ区别(架构、存储、高可用)
公司提供两种工具 Kafka和RocketMQ,需要了解原理,业务选型时更好决策。本篇主要讲二者核心区别,然后给出一些业务指导。
一、架构简介
1.1 Kafka
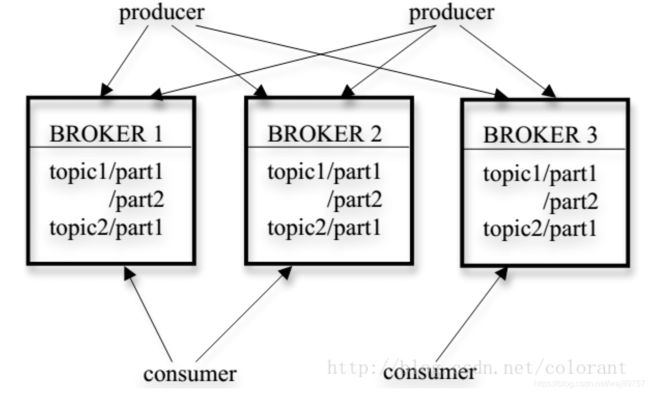
三大组件: producer broker consumer
1.2 RocketMQ
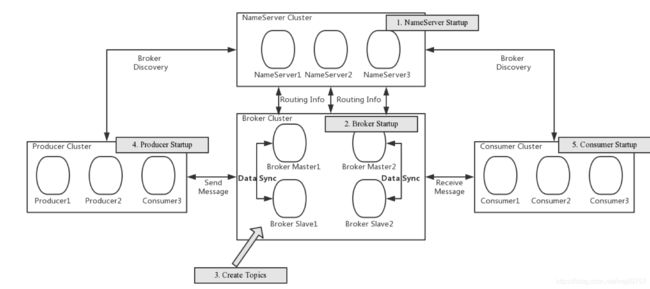
四大组件: producer broker nameSrv consumer
broker是两者最大分歧。
Kafka broker 是一个物理节点;负责读写消息、数据同步;负责多节点间协调(路由规则元数据维护,管理topic、数据迁移、调整分区、集群节点健康管理)
+RM nameSrv 负责多节点协调 (数据和计算节点的分离)
二、多节点协调原理
2.1 KafkaController
Kafka依赖ZooKeeper做元数据管理和服务发现。早期版本所有broker都与zk交互,后期由Kafka Controller(就是一个broker)来统一与zk通信,这样好处是降低对ZK的压力,节点管理自己实现。
数据一致性 依赖ZK的一致性原理
Leader选举 依赖ZK的临时节点

2.2 NameSrv
NameSrv核心指责:
1.维护 broker 注册信息
2.告知client 某个topic的所有broker 以及路由规则
3.告知consumer broker的信息
最终一致性是否合理?
架构: broker和nameSrv在同一个网络,相互之间是长链接通信,保持心跳。nameSrv集群节点间不沟通,互相独立。所以没有分布式协调保证强一致,只有最终一致性。
假设一种场景: broker注册 会轮询nameSrv将信息写入所有节点,如果某个节点多次重试依然没写成功,证明n和b之间出现了问题。这时可能存在n有些节点上线了b信息,有些没有,节点间状态不一致。
如果是n出问题,client和consumer应该也连不到;如果是b出问题 n会摘掉
当client从某个n获取一个已经下线的b,client会尝试连接,连不上会继续轮询下一个n
结论:过程不一致,会损耗一些重连时间,但最终结果不变。
思考——为什么RM只保证最终一致性接受一定重试损失
RM是晚于Kafka诞生的,势必要规避一些问题。
它追求一种简单架构,broker只做存储,不做其他工作。分布式协调会在代码层面和维护层面带来极高的复杂度
RM存储节点数据固定 不会做任何迁移。 Kafka broker有协调属性,节点上下线时会重新计算topic的分区,会涉及数据迁移。
所以相比之下RM broker要更轻量级,职责单一。
三、数据存储原理
二者数据怎么备份、怎么切换?
Kafka是Leader Follow模式,一个broker是Leader负责读写,其余follow负责备份。
多种一致性方式
1.强一致性 所有节点写入成功 返回ACK
2.一般一致性 某个follow写入成功 返回ACK
3.弱一致性 主节点写成功 返回ACK
新节点加入KafkaController要重新进行分区计算,然后指定某些broker的某些分区数据做迁移。
RM是主从模式,类似MySQL
MASTER/SLAVE在启动时手工指定,新加入的节点要人工介入,指定新的ConsumeQueue,加入集群 参与消息路由。
四、log和commitlog的设计原理
两者的文件存储和读写原理区别?
4.1 Kafka的Log日志形态
基本思想是保证顺序写, log文件存储消息,index文件存储具备索引(offset :position 文件的绝对地址)
LogSegment log文件会按照量级分段 存多个文件,目的是方便查找。
查找流程: 一个offset 根据topic和partition先二分查找到最近的index文件; 在index里二分查找到相近的offset;再到LogSegment里二分找到最终的postition
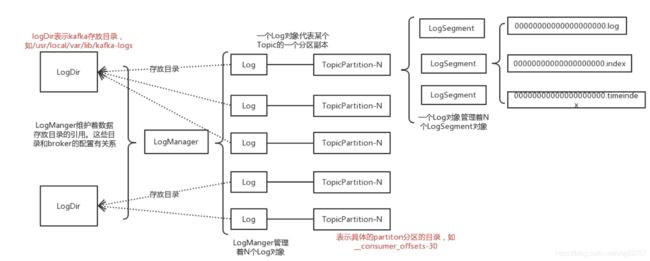
4.2 RocketMQ的commitlog形态
类似MySQL B-Tree存储形态, 数据顺序写入日志同时构建索引树
commitlog consumerqueue index file
1.commitlog 所有消息顺序写入
2.异步写到queue 也是一个文件,数据结构是一个链表,存储key和commitlog的offset ,用于consumer顺序消费
3.同时异步构建索引 写入Index File hashmap结构 用于随机查找key
文件结构的区别?
Kafka
顺序IO,写入非常快。
每个topic会产生多个文件,当topic膨胀后,会存在大量文件,文件IO、内存碎片问题会严重
RM
写入是顺序+随机,相比Kafka要差一些。(但是配合SSD设备以及合理的IO调度算法,差距不是很明显)
更像一个MySQL ibdata文件,所有topic数据都在一个文件里,好管理。
查找更加友好,提供顺序和随机查找,可以实现一些功能(延迟队列,指定索引查找等)对业务更友好。
五、高可用原理和区别
Kafka
Broker三个角色
Leader 负责写 Follower 负责读 KafkaController 负责分布式调度,元数据维护,节点的failover;
一旦节点故障controller会介入选择其他leader或者下线follower
强顺序性消费不支持。
扩容缩容:
任何新加入的broker节点,可能都涉及从其他节点迁移数据;一般会先做针对某个broker分区做一个follower同步数据,(全量数据不太需要,实时消费),然后切consumer,再切prodcer
RocketMQ
Master挂掉如何高可用?
集群内多组M/S保障高可用,一个M挂掉,切换到其他组。
强顺序性消息不支持(实际业务场景很少);延迟消息、事务型消息会丢失
扩容缩容:
新建一组M/S producer重新计算路由 直接写入流量,consumer也加入消费,完事!
六、各有千秋
Kafka
优点:吞吐大,适合大数据实时计算
缺点:broker存在很多文件,IO大;扩缩容涉及到分区数据迁移,运维层面成本高
RocketMQ
优点:
集群部署简单,依靠初始化配置来指定主从、nameSrv、broker地址;没有复杂的分布式协调,不依赖外部组件,自己出问题概率低; 运维更友好
API接口更丰富,适合在线业务
缺点:
吞吐量不如Kafka,在一个数量级但是会差一些,特别在大数据IO场景,业界一般都用Kafka完成