面试官常问:谈谈MySQL 索引,B+树原理,以及建索引的几大原则?
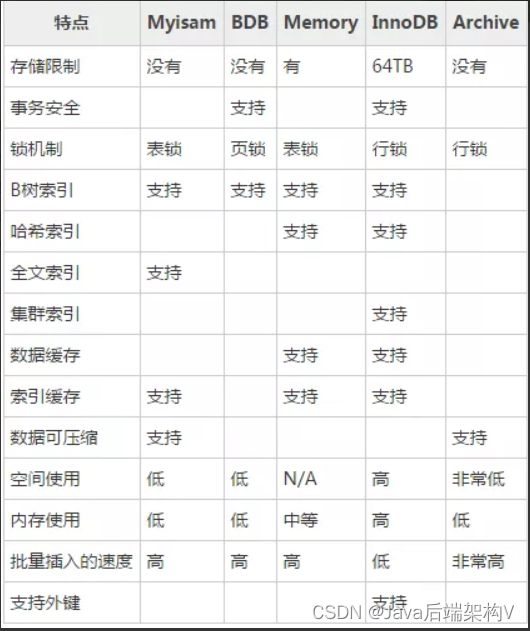
存储引擎的比较
注:上面提到的B树索引并没有指出是B-Tree和B+Tree索引,但是B-树和B+树的定义是有区别的。
在 MySQL 中,主要有四种类型的索引,分别为:B-Tree 索引, Hash 索引, Fulltext 索引和 R-Tree 索引。
B-Tree 索引是 MySQL 数据库中使用最为频繁的索引类型,除了 Archive 存储引擎之外的其他所有的存储引擎都支持 B-Tree 索引。Archive 引擎直到 MySQL 5.1 才支持索引,而且只支持索引单个 AUTO_INCREMENT 列。
不仅仅在 MySQL 中是如此,实际上在其他的很多数据库管理系统中B-Tree 索引也同样是作为最主要的索引类型,这主要是因为 B-Tree 索引的存储结构在数据库的数据检索中有非常优异的表现。
一般来说, MySQL 中的 B-Tree 索引的物理文件大多都是以 Balance Tree 的结构来存储的,也就是所有实际需要的数据都存放于 Tree 的 Leaf Node(叶子节点) ,而且到任何一个 Leaf Node 的最短路径的长度都是完全相同的,所以我们大家都称之为 B-Tree 索引。
当然,可能各种数据库(或 MySQL 的各种存储引擎)在存放自己的 B-Tree 索引的时候会对存储结构稍作改造。如 Innodb 存储引擎的 B-Tree 索引实际使用的存储结构实际上是 B+Tree,也就是在 B-Tree 数据结构的基础上做了很小的改造,在每一个Leaf Node 上面除了存放索引键的相关信息之外,还存储了指向与该 Leaf Node 相邻的后一个 LeafNode 的指针信息(增加了顺序访问指针),这主要是为了加快检索多个相邻 Leaf Node 的效率考虑。
InnoDB是Mysql的默认存储引擎(Mysql5.5.5之前是MyISAM)
B-树、B+树概念
B树
即二叉搜索树:
- 所有非叶子结点至多拥有两个儿子(Left和Right);
- 所有结点存储一个关键字;
- 非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;

B-树
是一种多路搜索树(并不是二叉的):
- 定义任意非叶子结点最多只有M个儿子;且M>2;
- 根结点的儿子数为[2, M];
- 除根结点以外的非叶子结点的儿子数为[M/2, M];
- 每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
- 非叶子结点的关键字个数=指向儿子的指针个数-1;
- 非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
- 非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
- 所有叶子结点位于同一层;
如:(M=3)
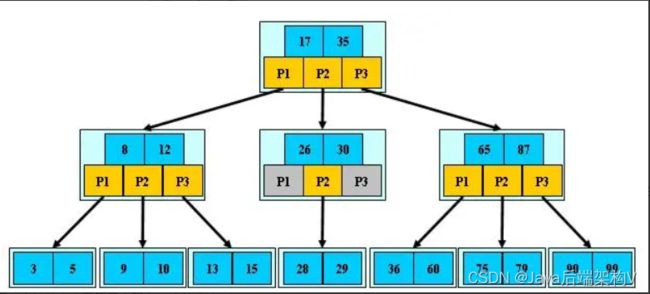
B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点;
B-树的特性:
- 关键字集合分布在整棵树中;
- 任何一个关键字出现且只出现在一个结点中;
- 搜索有可能在非叶子结点结束;
- 其搜索性能等价于在关键字全集内做一次二分查找;
- 自动层次控制;
由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的至少利用率。
所以B-树的性能总是等价于二分查找(与M值无关),也就没有B树平衡的问题;
由于M/2的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占M/2的结点;删除结点时,需将两个不足M/2的兄弟结点合并;
B+树
B+树是B-树的变体,也是一种多路搜索树:
其定义基本与B-树同,除了:
- 非叶子结点的子树指针与关键字个数相同;
- 非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
- 为所有叶子结点增加一个链指针;
- 所有关键字都在叶子结点出现;
如:(M=3)
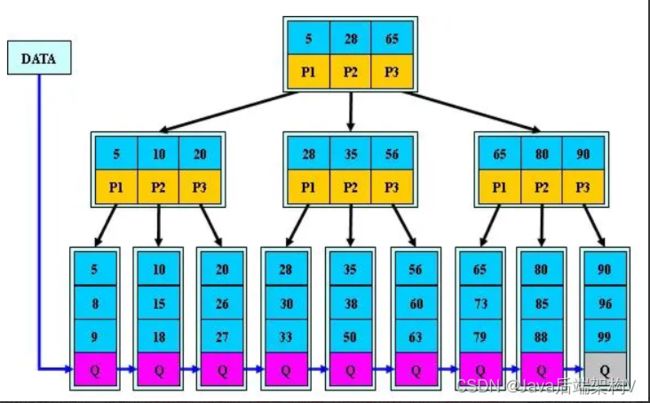
B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的特性:
- 所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
- 不可能在非叶子结点命中;
- 非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
- 更适合文件索引系统;
建索引的几大原则
1、最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2、=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式。
3、尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录。
4、索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = '2014-05-29'就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp('2014-05-29');
5、尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
面试需要掌握那些技能?
1. Java基础知识:包括面向对象编程、集合框架、多线程编程、JVM、测试和调试技术等。
2. 熟悉Spring框架:包括Spring MVC、Spring Boot、Spring Cloud等。
3. 掌握常见的数据库操作技术:如SQL语句、关系型数据库和非关系型数据库等。
4. 熟练使用版本控制工具:如Git等。
5. 对Web开发有一定的了解,熟悉前端相关技术:如HTML、CSS、JavaScript等。
6. 能够写高效的算法,并对数据结构有一定的了解。
7. 有良好的代码习惯,能够编写易于维护和扩展的代码,并理解单元测试和集成测试等概念。
8. 在面试过程中,还需要表达清晰、思路清晰明了、能够准确地回答面试官提出的问题,此外,自信、积极和礼貌也是很重要的。
大厂面试官常问的技术核心知识点
1. Java基础知识:Java语言的基本知识,包括数据类型、继承、多态、接口等。
2. 面向对象编程:对面向对象编程原则和设计模式的理解,如单例、工厂、观察者、策略等。
3. 数据库知识:对关系型数据库和非关系型数据库操作的熟悉程度,掌握SQL语言,了解事务管理机制,并清楚地描述ORM框架的使用场景及实际操作。
4. Web开发:Web开发相关技术,例如Servlet、JSP、Spring MVC、JSON、RESTful API等。熟悉HTTP/HTTPS协议以及网络通信机制。
5. 常用框架:Spring、Hibernate、MyBatis等框架,尤其是Spring框架,深入理解Spring IOC,AOP等核心原理,知道如何配置基础设施组件,如事务管理、缓存等基础组件。
6. 分布式系统架构:分布式系统相关技术,如Dubbo、Zookeeper等,对微服务架构模式有一定的了解,熟悉分布式锁、分布式缓存、分布式数据存储等高可用性方案。
7. 性能排查:了解性能优化的方法,包括代码和SQL调优等,并且熟悉性能监测和分析工具,例如掌握JVM内存结构及堆栈排查技术。
8. 算法和数据结构:有基本的算法和数据结构知识,例如排序、查找、哈希表等。
我最近整理了一些小伙伴们发给我的面试题以及我的一些最新的面试等学习资料,有需要的小伙伴可以找我领取下。或者点击 → 《最新Java后端全套VIP面试学习资源》直接获取以下Java后端架构VIP进阶学习面试资料。
资料里面包含了:Java基础、MySQL、jvm、分布式、性能优化、spring 、spring boot、spring cloud、 MyBatis、Netty源码分析、算法、乙级高并发、Redis、dubbo、Tomcat、集合框架、锁、MQ、百万简历模板等等学习视频资料。
资料如图展示:(知识其中一部分)
同时也欢迎大家关注公众号【Java烂猪皮】,回复【666】,获取最新Java后端架构VIP学习资料以及视频学习教程,然后一起学习,一文在手,面试我有。
看完三件事❤️
- 如果你觉得这篇内容对你还蛮有帮助,我想邀请你帮我三个小忙:
- 点赞,转发,有你们的 『点赞和评论』,才是我创造的动力。
- 关注作者公众号 『 java烂猪皮 』,不定期分享原创知识。
- 关注后回复【666】扫码即可获取学习资料包。
- 同时可以期待后续文章ing。
