【深度强化学习】1. 基础部分
文章目录
- 强化学习纲要-基础部分
-
- 强化学习应用案例
- 强化学习在做什么?
- 基本要素
- 分类
-
- 1. 按照Agent有没有对环境建模来分类
- 2. 按照Agent的决策方式来分类
- 时序决策过程
- 动作空间
- 智能体主要组成部分
-
- 1. Policy
- 2. Value Function
- 3. Model
- Exploration and Exploitation
- 知识点补充
- 致谢
- 参考内容
强化学习纲要-基础部分
【DataWhale打卡】第一天:学习周博磊讲的强化学习结合《深入理解AutoML和AutoDL》这本书中的强化学习的章节总结了基础部分。
参考资料:https://github.com/zhoubolei/introRL
先导课程:线性代数、概率论、机器学习/数据挖掘/深度学习/模式识别
编程基础:Python, PyTorch
强化学习应用案例
- alpha-go、alpha-zero围棋战胜李世石。
- 王者荣耀 绝悟AI 就是强化学习技术应用在MOBA游戏的一个典型例子。
- 可以将股票的买卖看作强化学习问题,如何操作能让收益极大化。
- Atari等电脑游戏。
- 机器人,比如如何让机械臂自己学会给一个杯子中倒水、抓取物体。
- DeepMind让Agent学习走路。
- 训练机械臂通过手指转魔方。
- 训练Agent穿衣服。
强化学习在做什么?
强化学习和监督学习有很大的区别:
-
监督学习需要提供数据和对应的标签,训练数据和测试数据是独立同分布的,从而进行模式和特征的学习。
-
强化学习不同,强化学习没有直接的标签进行指导,并且数据不是独立同分布的,前后数据有比较强的关系。强化学习可以在环境中进行探索和试错,根据实验的结果提取经验,从而学习到最佳策略。
| 监督学习 | 无监督学习 | 强化学习 | |
|---|---|---|---|
| 输出值 | 标签 | 无 | 奖励值 |
| 标签/奖励 | 人类提供标注 | 无标签 | 延迟奖励 |
| 经验 | 无 | 无 | 有 |
| 损失值 | 有 | 无 | 无 |
| 输入 | 独立同分布 | 独立同分布 | 前后依赖 |
强化学习的目标是训练一个agent,能够在不同的情况做出最佳的action,从而让系统给出的reward值最大化。
流程如下:agent会观察环境得到observation,然会采取一个action,环境受到这个action的作用,会反馈给agent一个reward,同时环境给出的observation也发生了改变。循环往复,agent目标是为了从环境中获得最高reward奖励。
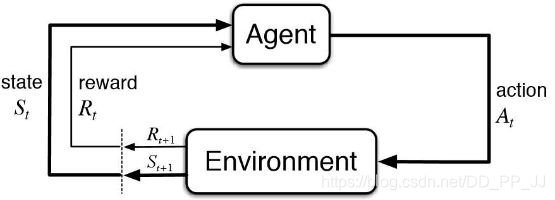
存在两大主体,智能体Agent和环境Environment,整个过程是序列化的:
S t − A t − R t − S t + 1 − A t + 1 − R t + 1 − S t + 2 … S_t-A_t-R_t-S_{t+1}-A_{t+1}-R_{t+1}-S_{t+2}\dots St−At−Rt−St+1−At+1−Rt+1−St+2…
智能体目标就是最大化奖励函数 G t G_t Gt:
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + ⋯ = ∑ k = 0 ∞ γ k R t + k + 1 G_t=R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3}+\dots=\sum_{k=0}^\infin \gamma^k R_{t+k+1} Gt=Rt+1+γRt+2+γ2Rt+3+⋯=k=0∑∞γkRt+k+1
也就是说当前时序为t的时候,最大化奖励函数就是从当前一直到最后一个状态(完成一个episode)所获取的所有Reward。 γ \gamma γ 是一个0-1之间的数,叫做奖励衰减因子。如果等于0,代表这个Agent只考虑当前即时结果,不考虑目标长远。如果等于1,代表这个Agent考虑的是长远利益,放眼整体。
强化学习的特点:
- 输入的数据是序列化、前后有依赖的,并不是独立同分布的。
- 没有监督信息,每一步没有被告诉应该做什么。
- Trial-and-error exploration,exploration和exploitation之间的平衡:
- exploration: 代表探索环境,尝试一些新的行为,这些行为有可能会带来巨大的收益,也可能减少收益。
- exploitation: 就采取当前已知的可以获得最大收益的action。
- Reward Delay效应,当采取一个action以后,并不会立刻得到反馈,需要等待一段时间或者等结束之后才会有反馈。
基本要素
- 环境的状态:用符号S表示, S t S_t St代表t时刻下处于的某一个状态。
- 个体的动作:用符号A表示, A t A_t At代表t时刻个体采取的动作。
- 环境的奖励:用符号R表示, R t + 1 R_{t+1} Rt+1表示t时刻个体在 S t S_t St状态下,采取动作 A t A_t At得到的奖励。
- 智能体agent策略:用符号 π \pi π表示,agent会根据 π \pi π表示的策略来选择动作。
- 价值函数:用符号 V π ( s ) V^{\pi}(s) Vπ(s)表示,agent在面临状态S的情况下,如果采用策略 π \pi π后进行动作的价值,是一个期望函数。 V π ( s ) = E π ( R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . ∣ S t = s ) V^{\pi}(s)=E_{\pi}(R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3}+...|S_t=s) Vπ(s)=Eπ(Rt+1+γRt+2+γ2Rt+3+...∣St=s)
- 奖励衰减因子:用符号 γ \gamma γ来表示,是一个0-1之间的数,用于约束距离时间较远的reward所占的比重。
分类
1. 按照Agent有没有对环境建模来分类
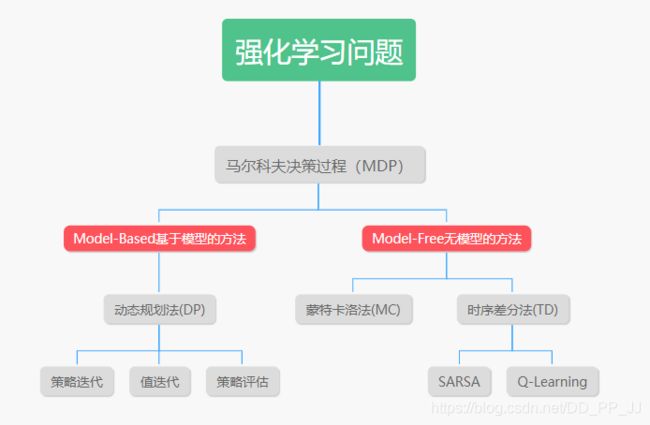
强化学习主要分为动态规划、蒙特卡罗法、时序差分法。强化学习中,从一个状态s转化到另外一个状态s’不仅和当前状态s和动作a有关,还与之前的状态有关。但是考虑这么多状态会导致模型非常复杂,所以引入马尔可夫性来简化问题,也就是一个假设 H H H, 即转化到下一个状态s‘的概率仅仅与当前的状态s有关,而和之前的状态没有关系。
解决马尔科夫决策过程有两个分类,见上图,需要解释的是Model-based方法和Model-Free方法。
Model-based方法代表这个问题中,必须能够获得环境的状态转化方程,需要对环境进行建模,比如在仿真环境中训练机械手臂。agent学习的模型可以提高对状态转移函数和奖励函数的估计的准确性。这样就可以通过动态规划算法求解。
有模型的强化学习方法可以对环境建模,使得该类方法具有独特魅力,即“想象能力”。在免模型学习中,智能体只能一步一步地采取策略,等待真实环境的反馈;而有模型学习可以在虚拟世界中预测出所有将要发生的事,并采取对自己最有利的策略。
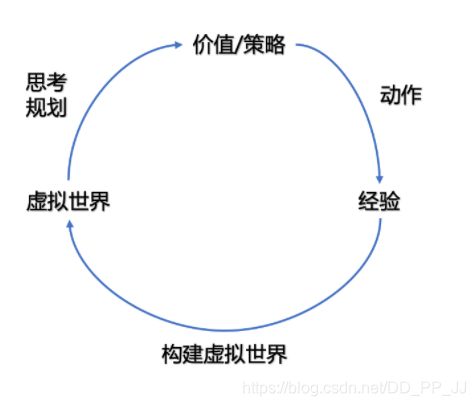
Model-Free方法代表不需要对环境进行建模,只需要经验,也就是实际或者仿真的与环境进行交互的整个样本序列。免模型学习通常属于数据驱动型方法,需要大量的采样来估计状态、动作及奖励函数,从而优化动作策略。免模型学习的泛化性要优于有模型学习,原因是有模型学习算需要对真实环境进行建模,并且虚拟世界与真实环境之间可能还有差异,这限制了有模型学习算法的泛化性。
判断方法:在Agent执行动作前,看其能否对下一步的状态和回报做出预测,如果可以预测那就是model-based方法,如果不能,那就是model-free的方法。
Q: 有模型强化学习和免模型强化学习有什么区别?
A: 针对是否需要对真实环境建模,强化学习可以分为有模型学习和免模型学习。
- 有模型学习是指根据环境中的经验,构建一个虚拟世界,同时在真实环境和虚拟世界中学习;
- 免模型学习是指不对环境进行建模,直接与真实环境进行交互来学习到最优策略。
from: https://blog.csdn.net/ppp8300885/article/details/78524235
Q: Q-learning也是对下一步的状态和奖励在做预测吗?
A: 无模型的RL是不会显式对Reward function和transition function进行建模, Q-learning的Q值更新是用的: 当前返回的reward(真实值)+下一步状态Q值(这个是异策略估计的), 这个reward是执行完a动作后的真实值, 并不是自己拟合的reward function给出的. AlphaGo为啥是model-based, 因为他依赖蒙特卡罗树去估计棋局未来的演化(transition function)和赢率(reward function)
2. 按照Agent的决策方式来分类
从Agent的决策方式来看,可以分为三种:
- Value-Based方法中,Agent学习的目标是价值函数,隐式地学习了策略(因为策略是从价值函数中推算出来的),常见的算法有SARSA、Q-Learning
- Policy-Based方法中,Agent学习的目标就是策略,给一个状态s,直接求出输出动作地概率。策略可以分为两类:确定性策略和随即策略。常见算法就是策略梯度蒜贩。
- Actor-Critic方法中,结合了以上两种方法,将策略函数和价值函数都学习了,吸取了两者的优点。
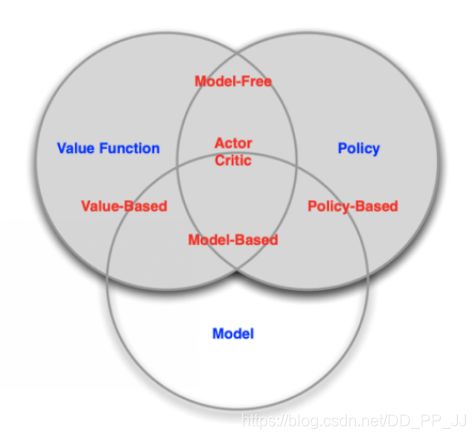
一个常用的强化学习问题解决思路是,先学习环境如何工作,也就是了解环境工作的方式,即学习得到一个模型,然后利用这个模型进行规划。
时序决策过程
State和Observation并不是等价的概念:
引入历史的概念,历史是观测、行为、奖励的序列:
H t = O 1 , R 1 , A 1 , … , A t − 1 , O t , R t H_t = O_1,R_1,A_1,\dots,A_{t-1},O_t,R_t Ht=O1,R1,A1,…,At−1,Ot,Rt
Agent采取的当前动作会依赖之前的历史,所以整个游戏的状态可以看做关于历史的函数:
S t = f ( H t ) S_t=f(H_t) St=f(Ht)
状态(state)s是对环境的整体描述,不会有其他隐藏的信息。观测(observation)o是状态的部分描述,可能会遗漏一些信息。
举个例子:在机器手臂抓杯子的案例中:
观测可以是通过摄像头得到的RGB像素值矩阵,来表示一个视觉的观测。
状态则是机器手臂每个关节的角度和速度的表示。
环境状态和智能体状态:
S t e = f e ( H t ) S t a = f a ( H t ) S_t^e=f^e(H_t) \\ S_t^a=f^a(H_t) Ste=fe(Ht)Sta=fa(Ht)
当满足 O t = S t a = S t e O_t=S_t^a=S_t^e Ot=Sta=Ste的时候,称这种状态为Full Observability,agent可以观测环境的全部状态,也就是马尔可夫决策过程MDP。
同时也有Partial Observation, agent无法观测环境中的全部状态,只能看到部分状态比如说Atari游戏中只能观测到屏幕上的像素,无法获取小球位置(这个状态就不可见)。这种问题是部分可见的马尔可夫决策过程POMDP。
动作空间
不同的环境/游戏可以采取的动作不同。有效动作的集合经常被称为动作空间(action space)。像 Atari 和 Go 这样的环境有离散动作空间(discrete action spaces)
在其他环境,比如在物理世界中控制一个 agent,在这个环境中就有连续动作空间(continuous action spaces) 。
智能体主要组成部分
RL Agent组成部分有policy函数(负责选取下一步动作)、价值函数(对当前状态进行评估,估计以后的收益大概有多少)、模型(表示了Agent对这个环境状态进行了理解)
1. Policy
Policy决定了Agent的行为,根据看到的状态,得到应该采取的行为。主要分为两种:
- 随机性策略:stochastic policy: 也就是说输出的action是一个概率分布,通过对概率分布进行采样,得到真实采取的行为。 π ( a ∣ s ) = P ( A t = a ∣ S t = s ) \pi(a|s)=P(A_t=a|S_t=s) π(a∣s)=P(At=a∣St=s)
- 确定性策略:deterministic policy, 就是说只采取它的极大化,采取最有可能的动作。 a ∗ = a r g m a x a π ( a ∣ s ) a*=argmax_a\pi(a|s) a∗=argmaxaπ(a∣s)
Q: 既然有确定性策略,采取能让奖励极大化的action不就可以了,为什么要加入随机性呢?
A: 引入随机性是为了更好的探索环境,随机性可能会带来负面收益,但是也可能会带来巨大的正面收益,为了探索这种可能性,所以随机性策略更好。
2. Value Function
价值函数是期望,在看到当前状态s的时候,直到游戏结束期望获得的reward值就是价值函数 V π ( s ) V^\pi(s) Vπ(s)。
V π ( s ) = E π [ G t ∣ S t = s ] = E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ S t = s ] V_\pi(s)=E_\pi[G_t|S_t=s]=E_\pi[\sum_{k=0}^{\infin}\gamma^kR_{t+k+1}|S_t=s] Vπ(s)=Eπ[Gt∣St=s]=Eπ[k=0∑∞γkRt+k+1∣St=s]
以上公式中的 γ \gamma γ上文已经讲过了,是奖励衰减因子。因为希望能够在尽可能短的时间内,得到更多的奖励。
当然价值函数只考虑s也是不足的,Q函数综合考虑了状态和动作的影响,代表在当前状态s下,采取动作a以后的期望得到的奖励值。
Q π ( s , a ) = E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ S t = s , A t = a ] Q_\pi(s,a)=E_\pi[\sum_{k=0}^{\infin}\gamma^k R_{t+k+1}|S_t=s,A_t=a] Qπ(s,a)=Eπ[k=0∑∞γkRt+k+1∣St=s,At=a]
3. Model
模型决定了下一个状态是什么,下一步的状态取决于当前的状态和当前采取的行动。主要由两部分组成:
- 概率函数 P s s ′ a = P [ S t + 1 = s ′ ∣ S t = s , A t = a ] P_{ss'}^a=P[S_{t+1}=s'|S_t=s,A_t=a] Pss′a=P[St+1=s′∣St=s,At=a],表示从s状态采取动作a以后会转移s‘状态上。
- 奖励函数 R s a = E [ R t + 1 ∣ S t = s , A t = a ] R_s^a=E[R_{t+1}|S_t=s,A_t=a] Rsa=E[Rt+1∣St=s,At=a], 表示当前状态采取某个行为以后的奖励的期望值。
有了Model也就代表可以用Model-based方法进行求解,可以使用动态规划的方法求解问题。
Exploration and Exploitation
在强化学习里面,Exploration 和Exploitation 是两个很核心的问题。
- Exploration 是说我们怎么去探索这个环境,通过尝试不同的行为来得到一个最佳的策略,得到最大奖励的策略。
- Exploitation 是说我们不去尝试新的东西,就采取已知的可以得到很大奖励的行为。
因为在刚开始的时候强化学习 agent 不知道它采取了某个行为会发生什么,所以它只能通过试错去探索。所以 Exploration 就是在试错来理解采取的这个行为到底可不可以得到好的奖励。Exploitation 是说我们直接采取已知的可以得到很好奖励的行为。所以这里就面临一个 trade-off,怎么通过牺牲一些短期的 reward 来获得行为的理解。
知识点补充
Rollout:从游戏当前帧,生成很多局游戏,让当前的Model和环境交互,得到很多的观测(轨迹),得到最终的最终reward,从而可以训练agent。
致谢
感谢DataWhale的工作人员的组织,以及群友的耐心解答,感谢!(鞠躬)
https://github.com/cuhkrlcourse/RLexample
https://github.com/datawhalechina/leedeeprl-notes
参考内容
https://blog.csdn.net/ppp8300885/article/details/78524235
https://datawhalechina.github.io/leedeeprl-notes/#/chapter1/chapter1