开源语言大模型演进史:早期革新

尽管业内最初强调专有模型,但随着GPT-3等流行语言模型的发布,LLM研究社区开始发布相关开源变体。最早的开源语言模型在性能上落后于最佳的专有模型,不过,它们为提升LLM的研究透明度奠定了基础,并促进了后续LLaMA-2等强大模型的开发。
本系列内容分为三部分,主要探讨开源语言大模型的发展历史。本文是该系列文章的第一篇,本文作者将探讨开源LLM历史的起始阶段,它们对于我们理解开源LLM革命至关重要,后来开源LLM的发展完全建立在这些模型的基础上。在本系列内容的后两部分,作者将进一步介绍最新的开源LLM并探讨如何使用模仿和对齐技术来提升模型性能。
(本文作者为Rebuy公司AI总监、深度学习博士Cameron R. Wolfe。以下内容经授权后由OneFlow编译发布,转载请联系授权。原文:https://cameronrwolfe.substack.com/p/the-history-of-open-source-llms-early)
作者 | Cameron R. Wolfe
OneFlow编译
翻译|杨婷、宛子琳

(引自[12, 20])
语言模型的研究历史可追溯到早期的模型,如GPT、GPT-2以及在Transformer语言模型出现之前就已存在的循环神经网络技术(如ULMFit)。尽管语言模型的发展历程很长,但直到最近才开始真正流行。GPT-3的发布让语言模型首次走进人们视野,通过结合自监督预训练和上下文学习,GPT-3在许多任务上实现了惊人的少样本学习性能,引发了广泛关注和反响。
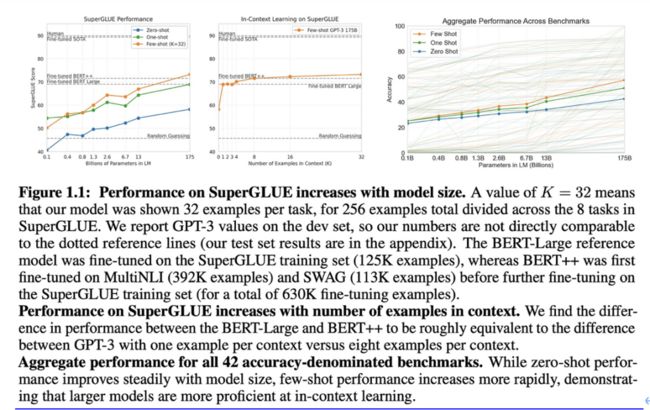
(引自[1])
GPT-3的广泛认可促进了语言大模型(LLM)的提出。不久之后,语言模型的对齐研究催生了更为出色的模型,如InstructGPT和ChatGPT。这些模型的惊人性能引起了人们对语言建模和生成式人工智能的极大兴趣。
尽管这些早期语言大模型非常强大,但其中多数都是闭源的。当语言模型开始广受认可时,许多性能强大的LLM只能通过付费API(如OpenAI API)访问,仅有特定的人或实验室具备研究和开发此类模型的能力。闭源模型的开发模式与常见的人工智能研究实践大相径庭,通常情况下,AI研究鼓励开放和共享以促进进步。
“由于闭源的限制,研究人员很难理解这些语言大模型的工作方式和工作原理,这阻碍了提高模型健壮性以及处理偏见等有害内容。”——引自[4]
1
语言模型的机制
开源LLM研究促进了透明度和共享,创造了一个研究人员可以更快进行合作和创新的环境。简而言之,开源LLM研究的美妙之处在于,它使我们研究这些令人难以置信的模型,让深入了解其中的工作原理成为可能。从此付费API或黑匣子背后就不存在未知的技巧。开源LLM让我们能够查看代码、进行实验,甚至尝试我们自己的想法并进行修改——我们可以完全访问底层模型!
“为进行可重复研究、共同推动AI领域向前发展,社区内更多成员需要访问这些模型的权限。”——引自[4]
但是,要深入理解此类模型,我们首先需要了解它们背后的基本原理。我们将对其进行概述概述,并试图提供对LLM(相对)全面的理解。
语言建模的目标

具有语言建模目标的预训练
语言建模的核心是下一个词元预测(也称为标准语言模型目标),几乎所有语言模型的训练都会用到它。为了使用下一个词元预测来训练语言模型,我们需要一个大规模的原始文本语料库。利用这个语料库,我们通过以下步骤来训练模型:i)从数据集中随机抽取一些文本;ii)训练模型来预测下一个单词。由于可以通过原始文本推导出真实的下一个词元,因此下一个词元预测是一种自监督学习。
什么是词元(token)?下一个词元预测可大致理解为,在给定前置词作为上下文的情况下来预测序列中的下一个单词。不过,词元并不完全等同于单词。当语言模型接收文本作为输入时,原始文本首先会被词元化(即转换为一系列离散的单词或子词)。见下图。

将原始文本转换为一系列词元
与语言模型关联的词元生成器通常具有固定大小的词汇表,或者拥有可从文本序列中创建的可行词元集合。
预测下一个词元。创建一系列词元之后,语言模型具有一个嵌入层,该层存储了词元生成器词汇表中每个词元的独特可学习的向量嵌入。使用这个嵌入层,我们可以将输入序列中的每个词元转换为对应的向量嵌入,形成一个词元向量序列。见下图。
 词元化和嵌入原始文本数据
词元化和嵌入原始文本数据
在为每个词元添加位置嵌入后,我们可以将这个词元向量序列传递给一个仅包含解码器的Transformer(稍后会有更详细的解释)。该模型将转换每个词元向量,并为每个词元生成一个对应的输出向量。值得注意的是,输出向量的数量与输入向量的数量相同。见下图。

使用仅解码器Transformer处理词元
现在,每个词元都有了一个输出表征,可以进行下一个词元预测了。对于序列中的每个词元,我们只需取其输出词元向量,并使用它来预测序列中接下来出现的词元。下面是该过程的示例图。实际上,为提高效率,下一个词元预测的目标是同时计算序列上的所有词元(包括小批次中的所有序列)。

计算下一个词元预测训练目标
由于使用了因果(或掩码)自注意力机制,每个输出词元向量在序列中计算其表征时只考虑了当前和之前的词元。如果我们要使用双向自注意力机制,则每个输出词元向量将通过查看整个词元向量序列来计算,这将使模型能够通过直接复制序列中的下一个词元来解决下一个词元预测任务。因此,为了预测下一个词元,我们需要使用掩码自注意力机制。那么,什么是自注意力机制?什么是Transformer呢?下文将展开深入探讨。
简要说明:“语言模型”这个术语有时可能会被用于指代不仅仅专注于执行下一个词元预测的模型。例如,有人认为 BERT(18)是“语言模型”,但它却是用 Cloze 风格的目标进行训练的,并非是生成模型。因此,专注于下一个词元预测的语言模型通常被称为“因果”语言模型。下文将交替使用这两个术语(生成模型和因果语言模型),用于指代专注于下一个词元预测的模型。
Transformer架构及其变体
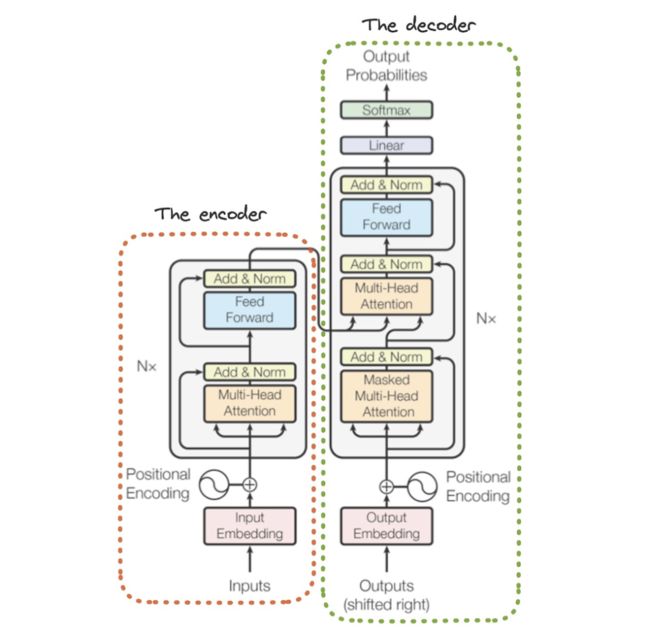
(引自[17])
所有语言模型都使用了Transformer模型的某个变体。这个架构最初由Google研究人员提出,用于解决序列到序列的任务。然而,随后该架构被扩展应用于解决各种不同的问题,从评估文本的语义相似性到图像分类等。Transformer架构的原始形式包含两个组件:
-
编码器(Encoder):每个编码块都执行双向自注意力和一个点对点前馈转换(pointwise feed-forward transformation)。编码块之间通过残差连接和LayerNorm进行分离。
-
解码器(Decoder):每个解码块都执行因果自注意力、交叉注意力(即编码器和解码器词元之间的自注意力)和一个点对点前馈转换。同样地,这些解码块之间也通过残差连接和LayerNorm进行分离。
当架构中的这两个组件同时存在时,编码器处理输入序列并产生一个输出序列。然后,解码器根据编码器的输出序列作为输入以生成自己的输出序列。换句话说,编码器处理整个输入序列,形成一个表征,而解码器在生成输出时使用这个表征作为上下文。总之,Transformer将一个序列作为输入,并产生一个新的序列作为输出。

(引自[17])
仅解码器和仅编码器Transformer。几乎所有因果语言模型都使用了仅解码器 Transformer架构作为其基础架构,这是一个移除了编码器部分的普通Transformer架构(见上图)。此外,每个解码器块中的交叉注意力部分也被移除,原因是没有编码器存在(无法关注不存在的编码器)。或者,我们可以通过仅使用架构的编码器部分,构建一个仅包含编码器的架构。仅编码器的架构(例如BERT [18])在解决各种判别式自然语言任务中表现出色,但不能用于生成文本。
为什么选择解码器?选择使用仅解码器架构(而不是仅编码器或完整的编码器-解码器Transformer)构建语言模型并非是随意的决定。相反,这一选择是受训练语言模型时使用下一个词元预测所驱动。在解码器中使用掩码自注意力机制,可以确保模型在预测下一个词元时无法查看序列中的后续词元。否则,下一个词元预测将毫无意义,因为模型可以直接复制下一个词元。见下图。

将因果自注意力用于预测下一个词元
为预测下一个词元时避免作弊,无论是仅编码器还是编码器-解码器Transformer 模型,都必须避免在输入序列中包含任何真实的下一词元。为做到这一点,我们可以:i)输入一个前缀;ii)预测跟随该前缀的词元。然而,这种方法效率较低,因为我们一次只能预测一个下一词元。相比之下,由于使用了掩码自注意力机制,仅解码器模型可以接收完整的词元序列,并对序列中的每个词元应用语言建模目标。此外,一些研究[12]表明,仅解码器架构在下一个词元预测方面的性能最佳。
如何生成文本?根据上述的仅解码器架构,生成文本遵循简单的自回归过程。我们只需不断预测下一个词元,再将这个词元添加到输入中,然后重复这个过程即可。如下图所示:

用语言模型生成文本
训练和使用语言模型
为了更好地理解语言模型,我们需要快速了解这些模型通常在实践中是如何训练和应用的。虽然这一领域已经展开了大量研究,但大多数语言模型都采用了下图所示提出的几种标准技术。

LLM 训练组件(引自[19])
语言模型可以通过多种不同方式进行学习。本文将重点关注预训练、对齐和上下文学习,这三个方面基本涵盖了语言模型训练和实际应用所需的大部分内容。
预训练是创建LLM的初始步骤,也是所需计算量最大的一步。首先,从一个随机初始化的LLM开始,我们需要使用语言建模目标,在大规模的原始文本语料库上对模型进行训练,这些语料库通过多个不同的来源精心策划而成。之前的研究[1]表明,通过在大规模数据集上预训练庞大的模型(很多参数),可以得到一个基础模型,通过执行下一个词元预测,这个模型可以准确完成各种不同的任务。为获得最佳结果,我们需要在数据和模型规模方面进行扩展。
我们还需要什么?从 GPT-3 [1] 和 Chinchilla [15] 可以看出,语言模型仅通过预训练,就能获得强大性能。然而,在ChatGPT等模型推出之前,LLM 并没有广泛流行,这是因为仅预测下一个词元并没有太大的吸引力。尽管正确的预测可以生成合理的文本,但通常模型会产生重复、简单且不太有价值的输出。我们需要一些方法使 LLM 产生对人类更有价值、更有趣的输出。

图4:API分布的元数据结果。需要注意的是,由于数据集的规模限制,这些结果是在不同的模型大小上进行合并的。请参考附录E.2以获得包括模型大小在内的分析结果。与 GPT-3 相比,PPO 模型更适合用作客户助手,更擅长遵循明确的约束条件和正确的指示,所产生的“幻觉"(在摘要等任务中编造信息)也更少。(引自[19])
对齐(alignment)是指对语言模型进行微调,使其更符合人类用户的期望。这一过程主要通过两种技术实现:监督微调(SFT)或从人类反馈中进行强化学习(RLHF)。语言模型的期望行为在很大程度上取决于其所部署的上下文或应用。而对齐是一种通用工具,可用于任意语言模型的微调,以使其按照特定方式运行。最新的研究表明,在对齐过程中,模型并不会学习新知识;相反,对齐过程只是教会模型如何更好地格式化和呈现它们从预训练中获得的知识。
应用语言大模型(LLM)。完成预训练和微调(或对齐)之后,最后一步是将模型专门针对我们所期望的应用进行专用化(specialize)。这一过程可能需要在特定领域的数据上进行额外的微调,但并不总是需要进行更多的训练。实际上,我们仅通过上下文中的学习就能取得显著成果,具体可参考下图。

(引自[1])
简单来说,上下文学习是指利用通用的基础模型(如预训练的LLM)来解决各种不同问题。由于语言模型具有通用的文本到文本结构,这一过程实际上很容易实现。我们只需构建一个文本问题解决提示,并将其作为输入提供给LLM即可。参见下图。

解决算数问题的不同提示变体
接下来,语言模型就会将问题的答案生成为输出。因此,我们可以通过修改输入提示解决不同问题。为解决问题构建的良好提示的过程被称为提示工程,这又可以分为以下两部分:
-
实用提示工程
-
高级提示工程
2
开源LLM的最初尝试
考虑到预训练的高昂成本,研究界花费了一些时间来推动开源LLM的创建,这让GPT-3等专有模型成为标准。然而,最初的几个模型一经提出,开源LLM的研究进展便如同打开了闸门,势不可挡(甚至是过于迅速)。接下来,我们将了解一些早期模型,更新发布的开源LLM将在本系列的后续部分进行介绍。
GPT-NeoX-20B
GPT-NeoX-20B[6]是最早的开源LLM之一,由EleutherAI团队开发,拥有200亿个参数。GPT-NeoX-20B是在最初的GPT-Neo模型(27亿个参数)[22]的基础上创建的,经过Pile数据集的预训练,在各个自然语言基准测试中展现出令人印象深刻的少样本学习性能(可媲美GPT-3)。尽管与GPT-3相比,这个模型规模较小(200亿参数 vs 1750亿参数),但它是当时发布的最大开源语言模型。此外,用于训练和评估模型的所有代码以及权重都基于Apache 2.0发布,允许商用。

(引自[8])
模型架构。GPT-NeoX-20B采用了标准的仅解码器Transformer架构,但在以下两个方面进行了改进:
-
RoPE嵌入
-
并行注意力和前馈层
在改进标准位置嵌入的基础上,RoPE 嵌入(如上图所示)提供了一种将位置信息注入自注意操作的新方法。这种方法在绝对位置信息和相对位置信息之间取得了更好的平衡,并在许多其他模型中使用(例如,PaLM [9] 和 Falcon-40B [10]),以提高在具有长序列长度的任务上的性能。此外,通过使用并行注意力机制和前馈层(见下图)可以使训练吞吐量提高15%,同时将性能下降降至最低。
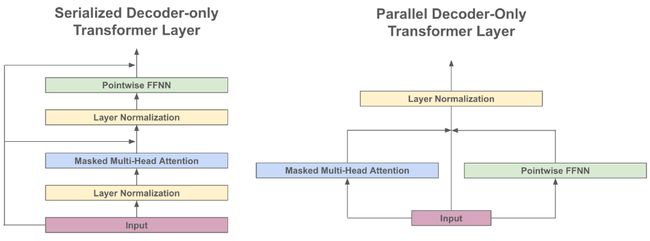
并行执行注意力层和前馈层
有趣的是,我们为GPT-NeoX-20B创建了一个可与GPT-2[11]相媲美的定制词元生成器,但重新在Pile数据集上对其进行了训练。Pile是一个大型且多样化的文本语料库,并经过修改以更一致地词元化空白字符,由此生成的词元生成器不仅在高质量语料库上进行了训练,而且在处理词元化代码时尤为高效(即代码中有很多空白字符)。因此,一些开源模型(如MPT-7B[5])至今仍在采用这个词元生成器。

(引自[6])
性能表现。GPT-NeoX-20B与GPT-3以及其他开源模型(如GPT-J) 进行了比较。从评估结果可以看出,GPT-NeoX-20B在常见的语言建模任务中表现非常出色(即便与专有模型相比也是如此),可参见上图。值得注意的是,尽管GPT-3往往在性能上表现最佳,但考虑到其规模,GPT-NeoX-20B的表现相当出色,甚至超过了具有相似参数量的专有模型。

GPT-NeoX-20B的性能虽然不算是最先进的,但考虑到其规模,该模型的表现异常出色,甚至与近期最新模型相比也毫不逊色!
开源预训练Transformer(OPT)语言模型

前文中我们已经详细讨论了开源预训练Transformer(OPT)库的相关细节。
OPT 概述。OPT由Meta AI提出,旨在向公众开放功能强大的LLM ,并提供使用机会,该库包括多个不同规模的LLM,参数量从1.25亿到1750亿不等。这些模型在经过筛选的数据集上进行了预训练,数据集来源包括Reddit、Pile和BooksCorpus等。其中最大的模型OPT-175B是最早开源的LLM之一。此外,这些模型还附带有代码仓库,甚至还有一本详细记录了所有模型的预训练过程的日志。虽然OPT模型不能用于商业用途,但它们是一种极具影响力的资源,对于推动开源研究LLM的开放可用性有重要影响。
OPT 的影响。OPT 语言模型是首个尝试开放研究社区使用的LLM,旨在使LLM摆脱隐藏在API之后的状态,完全开源。此外,OPT的开源训练代码提供了一个非常高效的训练框架,使用了常见的技术,如FSDP和张量并行,使其易于使用。这个代码的资源利用效率比NVIDIA直接发布的研究成果提高了17%,成为训练LLM的重要资源。

(引自[5])
与OPT相关的训练笔记和日志提供了大量(以前未知的)关于LLM训练过程的见解。通过这些资源,我们可以更好地理解训练LLM的全部成本,以及在这个过程中可能出现的诸多问题(如损失峰值、硬件故障等情况)。这些训练LLM时的困难已经成为了讨论的热点,并在随后开源LLM的进一步工作中得到了(在大多数情况下)解决。参考上图。
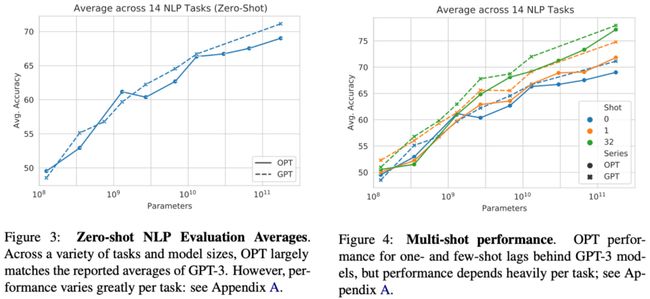
(引自[4])
OPT的性能如何?在提出时,OPT-175B与当时流行的模型进行了广泛比较,发现在零样本和少样本学习环境中取得了与GPT-3相当的性能。见上图。总体而言,OPT的性能并不突出。人们普遍认为,该模型在质量方面落后于专有模型。尽管性能平平,但OPT在人工智能研究领域迈出了重要一步,显著提升了人们对开源LLM的兴趣。这种影响力十分重要,因为专有模型的主导地位正在逐渐被接受为新标准。
BLOOM:开放的多语言语言模型
“学术界、非营利组织和较小公司的研究实验室发现,他们很难创建、研究,甚至使用LLM ,只有少数拥有必要资源和独家权限的工业实验室才能自由访问。”——引自[12]
BLOOM是一个拥有1760亿参数的LLM,作为AI研究人员进行大规模开放合作(有1000多名研究人员参与)的一部分进行训练,这次合作被称为Big Science Research Workshop,该工作坊持续了一年(2021年5月至2022年5月),旨在实现以下目标:i)创建一个大规模的多语言文本数据集;ii)在该数据集上训练一个多语言LLM,所产生的模型略大于GPT-3,并在Responsible AI License (RAIL)下开源,能够在46种不同语言和13种编程语言中生成文本。
为训练BLOOM而开发的数据集,名为ROOTS语料库,该语料库由498个HuggingFace数据集组成,覆盖46种自然语言和13种编程语言,含有超1.6兆字节的文本。该数据集在不同语言之间的分布如下图所示。

(引自[12])
获得原始数据后,作者对其应用了一系列不同的质量过滤器用于去除非自然语言文本。确切的过滤组件使用取决于数据的来源,这些组件在[12]的3.1.3节中进一步详细阐释。然而,整个处理流程有一个共同目标:尽可能地滤除低质量文本。
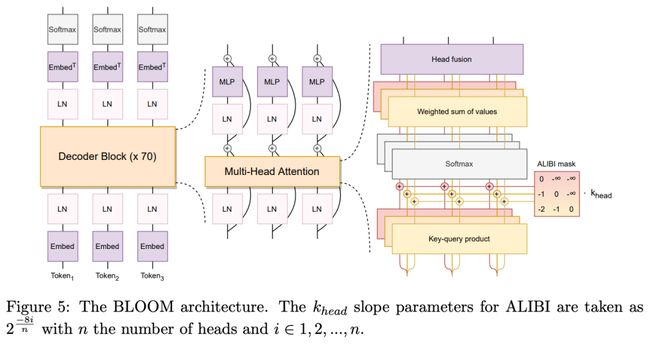
(引自[12])
BLOOM采用的是标准的仅解码器Transformer架构 。但正如上图所示,BLOOM针对这一架构进行了一些改进,例如:
-
ALiBi[13]:这种改进有助于提高模型在比训练数据更长的上下文长度下的表现,增强了泛化能力。
-
嵌入层归一化:在模型的嵌入层之后添加了一个额外的层归一化,经实证发现可以提高训练稳定性。
总的来说,BLOOM与大多数LLM的区别不大。值得注意的是,在[12]中,作者对不同类型的Transformer架构(例如,仅编码器模型、编码器-解码器模型和仅解码器模型)进行了全面分析,发现仅解码器模型(几乎所有因果语言模型都使用的模型)在预训练后取得了最佳性能。
“研究结果表明,预训练后,因果型仅解码器模型表现最佳,进一步验证了选择SOTA LLM的决策。” ——引自[12]
BLOOM的性能如何?与其他开源LLM相比,BLOOM的表现相对出色。在自然语言基准测试中,它取得了与OPT相当甚至更好的结果,尤其在机器翻译任务上表现出色,这要归功于它在多语言语料库上进行的训练。参考下图。
(引自[12])
虽然BLOOM的性能较好,但仍低于顶尖的专有模型。例如,根据HumanEval基准测试的结果(见下图),BLOOM的编码能力远不及其替代方案(如Codex [14] )。此外,当我们将BLOOM的性能与 Chinchilla[15]和PaLM[9] 等模型进行比较时,很容易发现开源模型的表现远不及其对应的专有模型。换言之,尽管业内有了BLOOM,但开源LLM领域的研究仍然滞后。

(引自[12])
其他重要模型
本文试图概括在开源LLM研究早期提出的重要模型。但除此之外还有一些值得关注的重要模型。
GPT-J [21]是一个仅支持英语的因果语言模型,拥有60亿参数,在 GPT-NeoX-20B[6]之前提出。与GPT-NeoX-20B类似,该模型在Pile数据集上进行预训练。GPT-J-6B是公开可用的GPT-3风格语言模型中规模最大的模型(截止其发布时)。
 (引自[20])
(引自[20])
GLM[20]更像是一个预训练目标,而不是传统的语言模型。GLM探索了将BERT、T5和GPT等不同预训练技术统一起来的想法,并通过引入一种自回归的空白填充目标来实现这一想法。换言之,他们以一种自回归的方式预测句子中的掩码词,类似于语言模型的方式。参见上图。尽管这种方法生成的模型参数非常小(<10亿个参数),但在多个流行的自然语言处理基准测试中,GLM表现出色,其性能超越了BERT、T5 和GPT模型。
3
未来走向

开源 LLM研究的演化
考虑到最初的开源LLM尝试产出的模型在性能上远不及专有模型,我们可以合理地思考:如何才能提升这些模型的性能?随着这一研究领域的发展,我们看到人们在两个主要方向上进行了积极探索:
-
创建更出色的基础LLM
-
对开源LLM进行微调(即进行对齐和模仿)
鉴于每个人都可访问开源LLM,这些领域的研究进展非常迅速——令人难以置信的是,在不到一年的时间里,我们就从OPT发展到了近乎最先进的模型,如LLaMA-2或Falcon-40B[10]。
“我们认为,改进开源模型的最大潜力在于应对创建更优秀的基础 LM 的艰巨挑战。”——引自[16]
在此期间,上述两个研究方向同时展开,每个方向都为AI从业者开发出了有价值的技术。
接下来的文章中,我将概述这两个领域及其各自的关键贡献,探讨最初的开源LLM尝试是如何演变为像LLaMA-2这样能力超群的模型。
参考文献(请上下滑动)
[1] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[2] Rae, Jack W., et al. "Scaling language models: Methods, analysis & insights from training gopher." arXiv preprint arXiv:2112.11446 (2021).
[3] Smith, Shaden, et al. "Using deepspeed and megatron to train megatron-turing nlg 530b, a large-scale generative language model." arXiv preprint arXiv:2201.11990 (2022).
[4] Zhang, Susan, et al. “OPT: Open Pre-trained Transformer Language Models.” arXiv preprint arXiv:2205.01068 (2022).
[5] “Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable Llms.” MosaicML, 5 May 2023, www.mosaicml.com/blog/mpt-7b.
[6] Black, Sid, et al. "Gpt-neox-20b: An open-source autoregressive language model." arXiv preprint arXiv:2204.06745 (2022).
[7] Gao, Leo, et al. "The pile: An 800gb dataset of diverse text for language modeling." arXiv preprint arXiv:2101.00027 (2020).
[8] Su, Jianlin, et al. "Roformer: Enhanced transformer with rotary position embedding." arXiv preprint arXiv:2104.09864 (2021).
[9] Chowdhery, Aakanksha, et al. "Palm: Scaling language modeling with pathways." arXiv preprint arXiv:2204.02311 (2022).
[10] “Introducing Falcon LLM”, Technology Innovation Institute, 7 June 2023, https://falconllm.tii.ae/.
[11] Radford, Alec, et al. "Language Models are Unsupervised Multitask Learners."
[12] Scao, Teven Le, et al. "Bloom: A 176b-parameter open-access multilingual language model." arXiv preprint arXiv:2211.05100 (2022).
[13] Press, Ofir, Noah A. Smith, and Mike Lewis. "Train short, test long: Attention with linear biases enables input length extrapolation." arXiv preprint arXiv:2108.12409 (2021).
[14] Chen, Mark, et al. "Evaluating large language models trained on code." arXiv preprint arXiv:2107.03374 (2021).
[15] Hoffmann, Jordan, et al. "Training compute-optimal large language models." arXiv preprint arXiv:2203.15556 (2022).
[16] Gudibande, Arnav, et al. "The false promise of imitating proprietary llms." arXiv preprint arXiv:2305.15717 (2023).
[17] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
[18] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[19] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
[20] Du, Zhengxiao, et al. "Glm: General language model pretraining with autoregressive blank infilling." arXiv preprint arXiv:2103.10360 (2021).
[21] Ben Wang and Aran Komatsuzaki. GPT-J-6B: A 6 billion parameter autoregressive language model, 2021.
[22] Sid Black, Leo Gao, Phil Wang, Connor Leahy, and Stella Biderman. 2021. GPT-Neo: Large scale autoregressive language modeling with MeshTensorflow.
注释
1. LLaMA-2提出后正式取代Falcon-40B成为开源LLM的SOTA。本系列的第二部分即将推出更多内容!
2. 目前LLM最常用的词元化技术是字节对编码词元化(https://huggingface.co/learn/nlp-course/chapter6/5?fw=pt)。
3. 这些任务将序列作为输入并生成序列作为输出,例如语言翻译或文本摘要。
4. 这仅仅意味着相同的前馈变换被单独应用于输入序列中每个词元向量的嵌入。
5. 残差连接只是意味着我们将模块的输入值添加到其输出中。换言之,如果模块执行函数f(x)给出运算,则具有残差连接的相同运算将具有g(x) = f(x) + x的形式。
6. 这句话的意思是,给定一个起始输入序列,我们依次:i) 生成一个输出;ii) 将此输出添加到我们的输入序列中;iii) 重复。
7. 根据OPT的提议,Meta AI继续为开源LLM研究作贡献。他们催生了多种模型,如OPT-IML、LLaMa、LIMA、LLaMA-2等。
8. 对于几乎所有语言(例如西班牙语、法语和阿拉伯语),BLOOM是第一个对这些语言进行训练的100B+参数的语言模型。
9. 微调开源LLM非常强调创建更好的基础LLM的价值。基础LLM也能从微调中获得收益!
其他人都在看
-
开源语言大模型的正确姿势
-
为什么开源大模型终将胜出
-
OpenAI规模经济与第二护城河
-
大模型长上下文运行的关键问题
-
通俗解构语言大模型的工作原理
-
揭示GPT Tokenizer的工作原理
-
LLVM之父:我的AI基础设施软件构建理念
试用OneFlow: github.com/Oneflow-Inc/oneflow/