Hadoop3.1.2伪分布式搭建-虚拟机搭建
Hadoop3.1.2伪分布式搭建-虚拟机搭建
1.更改网路设置,设置为静态ip
vi /etc/sysconfig/network-scripts/ifcfg-ens33

BOOTPROTO=static
IPADDR=192.168.10.21
NETMASK=255.255.255.0
GATEWAY=192.168.10.2
NDS1=114.114.114.114
DNS2=192.168.10.2
DNS3=202.100.64.68
NDS4=135.149.80.62
2.更改主机名:
临时更改: hostname bigdata
永久更改:vi /etc/hostname
![]()
4.配置ssh免密登录
4.1 生成秘钥对,连续按回车键即可:
ssh-keygen -t rsa -P ‘’

4.2 进入.ssh目录,如果目录不存在则创建
cd /root/.ssh

4.3 将公钥导入至authorized_keys
cp id_rsa.pub authorized_keys
或
ssh-copy-id -i bigdata
或
cat > ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys

4.4 ssh登录测试

如果有问题,更改文件权限:
chmod 700 ~/.ssh
chmod 600 authorized_keys
5.安装jdk
5.1 解压jdk至指定目录
tar -zvxf ./jdk-8u211-linux-x64.tar.gz -C /data/soft/
5.2 配置环境变量
vim /etc/profile

export JAVA_HOME=/data/soft/jdk1.8.0_211 export
PATH= P A T H : PATH: PATH:JAVA_HOME/bin:
5.3 使配置文件生效:
source /etc/profile
验证:
java -version

6.安装hadoopp
6.1 解压安装包至指定路劲
tar -zvxf ./hadoop-3.2.1.tar.gz -C /data/soft
6.2 配置环境变量:
vim /etc/profile

export HADOOP_HOME=/data/soft/hadoop-3.2.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
6.3 使配置文件生效:
source /etc/profile
6.4 进入hadoop配置文件目录
cd /data/soft/hadoop-3.2.1/etc/hadoop/
![]()
6.5 修改hadoop配置文件,主要修改以下几个配置文件
hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、workers
创建hadoop日志存放目录
mkdir -p /data/soft/hadoop-3.2.1/logs/hadoop
创建hadoop临时数据存放目录
mkdir -p /data/soft/hadoop-3.2.1/data/tmp
6.6 修改hadoop-env.sh文件
vim hadoop-env.sh

export JAVA_HOME=/data/soft/jdk1.8.0_211/
export HADOOP_LOG_DIR=/data/soft/hadoop-3.2.1/logs/hadoop
6.7 修改 core-site.xml 文件
注意 fs.defaultFS 属性中的主机名需要和你配置的主机名保持一致
vim core-site.xml

fs.defaultFS
hdfs://bigdata:9000
hadoop.tmp.dir
/data/soft/hadoop-3.2.1/data/tmp
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
6.8 修改 hdfs-site.xml 文件,把 hdfs 中文件副本的数量设置为 1,因为现在伪分布集中只有一个节点
vim hdfs-site.xml

dfs.replication
1
6.9 修改 mapred-site.xml,设置 mapreduce 使用的资源调度为yarn

mapreduce.framework.name
yarn
6.10 修改 yarn-site.xml,设置 yarn 上支持运行的服务和环境变

yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
yarn.resourcemanager.hostname
bigdata
6.11 修改 workers,设置集群中从节点的主机名信息,在这里就一台集群,所以就填写 bigdata
vim workers
![]()
6.12 格式化HDFS
hdfs namenode -format


看到has been successfully formatted. 表示格式化成功。
6.13 修改/data/soft/hadoop-3.2.1/sbin 目录下的start-dfs.sh文件
vim start-dfs.sh

HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
6.14 修改/data/soft/hadoop-3.2.1/sbin 目录下的stop-dfs.sh文件
vim stop-dfs.sh

HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
6.15 修改/data/soft/hadoop-3.2.1/sbin 目录下的start-yarn.sh文件
vim start-yarn.sh

YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
6.16 修改/data/soft/hadoop-3.2.1/sbin 目录下的stop-yarn.sh文件
vm stop-yarn.sh

YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
6.17 启动伪分布式集群:
start-all.sh
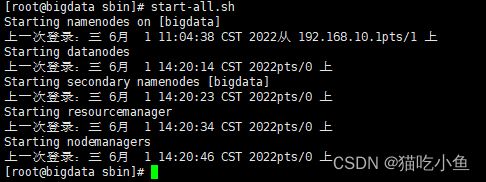
有如下进程表示,环境启动成功:

7.验证:
HDFS webui 界面:http://192.168.182.100:9870
YARN webui 界面:http://192.168.182.100:8088

