【深度学习】我用 PyTorch 复现了 LeNet-5 神经网络(自定义数据集篇)!
在上三篇文章:
这可能是神经网络 LeNet-5 最详细的解释了!
我用 PyTorch 复现了 LeNet-5 神经网络(MNIST 手写数据集篇)!
我用 PyTorch 复现了 LeNet-5 神经网络(CIFAR10 数据集篇)!
详细介绍了卷积神经网络 LeNet-5 的理论部分和使用 PyTorch 复现 LeNet-5 网络来解决 MNIST 数据集和 CIFAR10 数据集。然而大多数实际应用中,我们需要自己构建数据集,进行识别。因此,本文将讲解一下如何使用 LeNet-5 训练自己的数据。
正文开始!
三、用 LeNet-5 训练自己的数据
下面使用 LeNet-5 网络来训练本地的数据并进行测试。数据集是本地的 LED 数字 0-9,尺寸为 28x28 单通道,跟 MNIST 数据集类似。训练集 0-9 各 95 张,测试集 0~9 各 40 张。图片样例如图所示:
![]()
3.1 数据预处理
制作图片数据的索引
对于训练集和测试集,要分别制作对应的图片数据索引,即 train.txt 和 test.txt两个文件,每个 txt 中包含每个图片的目录和对应类别 class。示意图如下:

制作图片数据索引的 python 脚本程序如下:
import os
train_txt_path = os.path.join("data", "LEDNUM", "train.txt")
train_dir = os.path.join("data", "LEDNUM", "train_data")
valid_txt_path = os.path.join("data", "LEDNUM", "test.txt")
valid_dir = os.path.join("data", "LEDNUM", "test_data")
def gen_txt(txt_path, img_dir):
f = open(txt_path, 'w')
for root, s_dirs, _ in os.walk(img_dir, topdown=True): # 获取 train文件下各文件夹名称
for sub_dir in s_dirs:
i_dir = os.path.join(root, sub_dir) # 获取各类的文件夹 绝对路径
img_list = os.listdir(i_dir) # 获取类别文件夹下所有png图片的路径
for i in range(len(img_list)):
if not img_list[i].endswith('jpg'): # 若不是png文件,跳过
continue
label = img_list[i].split('_')[0]
img_path = os.path.join(i_dir, img_list[i])
line = img_path + ' ' + label + '\n'
f.write(line)
f.close()
if __name__ == '__main__':
gen_txt(train_txt_path, train_dir)
gen_txt(valid_txt_path, valid_dir)运行脚本之后就在 ./data/LEDNUM/ 目录下生成 train.txt 和 test.txt 两个索引文件。
构建Dataset子类
pytorch 加载自己的数据集,需要写一个继承自 torch.utils.data 中 Dataset 类,并修改其中的 __init__ 方法、__getitem__ 方法、__len__ 方法。默认加载的都是图片,__init__ 的目的是得到一个包含数据和标签的 list,每个元素能找到图片位置和其对应标签。然后用 __getitem__ 方法得到每个元素的图像像素矩阵和标签,返回 img 和 label。
from PIL import Image
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, txt_path, transform = None, target_transform = None):
fh = open(txt_path, 'r')
imgs = []
for line in fh:
line = line.rstrip()
words = line.split()
imgs.append((words[0], int(words[1])))
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
def __getitem__(self, index):
fn, label = self.imgs[index]
#img = Image.open(fn).convert('RGB')
img = Image.open(fn)
if self.transform is not None:
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs)getitem 是核心函数。self.imgs 是一个 list,self.imgs[index] 是一个 str,包含图片路径,图片标签,这些信息是从上面生成的txt文件中读取;利用 Image.open 对图片进行读取,注意这里的 img 是单通道还是三通道的;self.transform(img) 对图片进行处理,这个 transform 里边可以实现减均值、除标准差、随机裁剪、旋转、翻转、放射变换等操作。
当 Mydataset构 建好,剩下的操作就交给 DataLoder,在 DataLoder 中,会触发 Mydataset 中的 getiterm 函数读取一张图片的数据和标签,并拼接成一个 batch 返回,作为模型真正的输入。
pipline_train = transforms.Compose([
#随机旋转图片
transforms.RandomHorizontalFlip(),
#将图片尺寸resize到32x32
transforms.Resize((32,32)),
#将图片转化为Tensor格式
transforms.ToTensor(),
#正则化(当模型出现过拟合的情况时,用来降低模型的复杂度)
transforms.Normalize((0.1307,),(0.3081,))
])
pipline_test = transforms.Compose([
#将图片尺寸resize到32x32
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])
train_data = MyDataset('./data/LEDNUM/train.txt', transform=pipline_train)
test_data = MyDataset('./data/LEDNUM/test.txt', transform=pipline_test)
#train_data 和test_data包含多有的训练与测试数据,调用DataLoader批量加载
trainloader = torch.utils.data.DataLoader(dataset=train_data, batch_size=8, shuffle=True)
testloader = torch.utils.data.DataLoader(dataset=test_data, batch_size=4, shuffle=False)3.2 搭建 LeNet-5 神经网络结构
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.relu = nn.ReLU()
self.maxpool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.maxpool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = x.view(-1, 16*5*5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
output = F.log_softmax(x, dim=1)
return output3.3 将定义好的网络结构搭载到 GPU/CPU,并定义优化器
#创建模型,部署gpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = LeNet().to(device)
#定义优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)3.4 定义训练函数
def train_runner(model, device, trainloader, optimizer, epoch):
#训练模型, 启用 BatchNormalization 和 Dropout, 将BatchNormalization和Dropout置为True
model.train()
total = 0
correct =0.0
#enumerate迭代已加载的数据集,同时获取数据和数据下标
for i, data in enumerate(trainloader, 0):
inputs, labels = data
#把模型部署到device上
inputs, labels = inputs.to(device), labels.to(device)
#初始化梯度
optimizer.zero_grad()
#保存训练结果
outputs = model(inputs)
#计算损失和
#多分类情况通常使用cross_entropy(交叉熵损失函数), 而对于二分类问题, 通常使用sigmod
loss = F.cross_entropy(outputs, labels)
#获取最大概率的预测结果
#dim=1表示返回每一行的最大值对应的列下标
predict = outputs.argmax(dim=1)
total += labels.size(0)
correct += (predict == labels).sum().item()
#反向传播
loss.backward()
#更新参数
optimizer.step()
if i % 100 == 0:
#loss.item()表示当前loss的数值
print("Train Epoch{} \t Loss: {:.6f}, accuracy: {:.6f}%".format(epoch, loss.item(), 100*(correct/total)))
Loss.append(loss.item())
Accuracy.append(correct/total)
return loss.item(), correct/total3.5 定义测试函数
def test_runner(model, device, testloader):
#模型验证, 必须要写, 否则只要有输入数据, 即使不训练, 它也会改变权值
#因为调用eval()将不启用 BatchNormalization 和 Dropout, BatchNormalization和Dropout置为False
model.eval()
#统计模型正确率, 设置初始值
correct = 0.0
test_loss = 0.0
total = 0
#torch.no_grad将不会计算梯度, 也不会进行反向传播
with torch.no_grad():
for data, label in testloader:
data, label = data.to(device), label.to(device)
output = model(data)
test_loss += F.cross_entropy(output, label).item()
predict = output.argmax(dim=1)
#计算正确数量
total += label.size(0)
correct += (predict == label).sum().item()
#计算损失值
print("test_avarage_loss: {:.6f}, accuracy: {:.6f}%".format(test_loss/total, 100*(correct/total)))3.6 运行
#调用
epoch = 5
Loss = []
Accuracy = []
for epoch in range(1, epoch+1):
print("start_time",time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
loss, acc = train_runner(model, device, trainloader, optimizer, epoch)
Loss.append(loss)
Accuracy.append(acc)
test_runner(model, device, testloader)
print("end_time: ",time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())),'\n')
print('Finished Training')
plt.subplot(2,1,1)
plt.plot(Loss)
plt.title('Loss')
plt.show()
plt.subplot(2,1,2)
plt.plot(Accuracy)
plt.title('Accuracy')
plt.show()
经历 5 次 epoch 的 loss 和 accuracy 曲线如下:
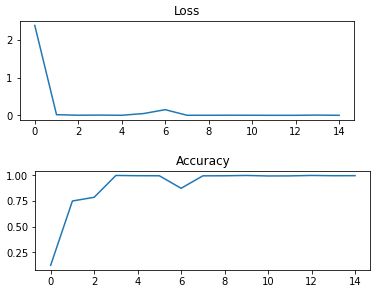
3.7 模型保存
torch.save(model, './models/model-mine.pth') #保存模型3.8 模型测试
下面使用上面训练的模型对一张 LED 图片进行测试。
from PIL import Image
import numpy as np
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = torch.load('./models/model-mine.pth') #加载模型
model = model.to(device)
model.eval() #把模型转为test模式
#读取要预测的图片
# 读取要预测的图片
img = Image.open("./images/test_led.jpg") # 读取图像
#img.show()
plt.imshow(img,cmap="gray") # 显示图片
plt.axis('off') # 不显示坐标轴
plt.show()
# 导入图片,图片扩展后为[1,1,32,32]
trans = transforms.Compose(
[
#将图片尺寸resize到32x32
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
img = trans(img)
img = img.to(device)
img = img.unsqueeze(0) #图片扩展多一维,因为输入到保存的模型中是4维的[batch_size,通道,长,宽],而普通图片只有三维,[通道,长,宽]
# 预测
output = model(img)
prob = F.softmax(output,dim=1) #prob是10个分类的概率
print("概率:",prob)
value, predicted = torch.max(output.data, 1)
predict = output.argmax(dim=1)
print("预测类别:",predict.item())
概率:tensor([[7.2506e-11, 7.0065e-18, 7.1749e-06, 7.4855e-13, 7.3532e-08, 8.5405e-17,
2.5753e-15, 9.7887e-10, 2.7855e-05, 9.9996e-01]],
grad_fn=)
预测类别:9 模型预测结果正确!
以上就是 PyTorch 构建 LeNet-5 卷积神经网络并用它来识别自定义数据集的例子。全文的代码都是可以顺利运行的,建议大家自己跑一边。
总结:
是我们目前分别复现了 LeNet-5 来识别 MNIST、CIFAR10 和自定义数据集,基本上涵盖了基于 PyToch 的 LeNet-5 实战的所有内容。希望对大家有所帮助!
所有完整的代码我都放在 GitHub 上,GitHub地址为:
https://github.com/RedstoneWill/ObjectDetectionLearner/tree/main/LeNet-5
也可以点击阅读原文进入~
往期精彩回顾
适合初学者入门人工智能的路线及资料下载中国大学慕课《机器学习》(黄海广主讲)机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载本站qq群955171419,加入微信群请扫码: