18、MapReduce的计数器与通过MapReduce读取/写入数据库示例
Hadoop系列文章目录
1、hadoop3.1.4简单介绍及部署、简单验证
2、HDFS操作 - shell客户端
3、HDFS的使用(读写、上传、下载、遍历、查找文件、整个目录拷贝、只拷贝文件、列出文件夹下文件、删除文件及目录、获取文件及文件夹属性等)-java
4、HDFS-java操作类HDFSUtil及junit测试(HDFS的常见操作以及HA环境的配置)
5、HDFS API的RESTful风格–WebHDFS
6、HDFS的HttpFS-代理服务
7、大数据中常见的文件存储格式以及hadoop中支持的压缩算法
8、HDFS内存存储策略支持和“冷热温”存储
9、hadoop高可用HA集群部署及三种方式验证
10、HDFS小文件解决方案–Archive
11、hadoop环境下的Sequence File的读写与合并
12、HDFS Trash垃圾桶回收介绍与示例
13、HDFS Snapshot快照
14、HDFS 透明加密KMS
15、MapReduce介绍及wordcount
16、MapReduce的基本用法示例-自定义序列化、排序、分区、分组和topN
17、MapReduce的分区Partition介绍
18、MapReduce的计数器与通过MapReduce读取/写入数据库示例
19、Join操作map side join 和 reduce side join
20、MapReduce 工作流介绍
21、MapReduce读写SequenceFile、MapFile、ORCFile和ParquetFile文件
22、MapReduce使用Gzip压缩、Snappy压缩和Lzo压缩算法写文件和读取相应的文件
23、hadoop集群中yarn运行mapreduce的内存、CPU分配调度计算与优化
文章目录
- Hadoop系列文章目录
- 一、计数器
-
- 1、Counter计数器介绍
- 2、MapReduce内置Counter
-
- 1)、File System Counters
- 2)、Job Counters
- 3)、File Input|Output Format Counters
- 3、MapReduce自定义Counter
-
- 1)、需求
- 2)、需求实现
- 3)、实现
- 二、读写mysql数据库
-
- 1、介绍
- 2、读取mysql数据
-
- 1)、需求
- 2)、实现说明
- 3)、实现
-
- 1、pom.xml
- 2、bean
- 3、mapper
- 4、reducer
- 5、driver
- 6、mapper与driver合并成一个java文件
- 7、验证
- 3、写数据到mysql
-
- 1)、創建需要寫入的表
- 2)、实现说明
- 3)、bean
- 4)、mapper
- 5)、reducer
- 6)、driver
- 7)、验证
本文介绍MapReduce的计数器使用以及自定义计数器、通过MapReduce读取与写入数据库示例。
本文的前提依赖是hadoop可正常使用、mysql数据库中的表可用且有数据。
本文分为2个部分,即计数器与读写mysql数据库。
一、计数器
1、Counter计数器介绍
在执行MapReduce程序的时候,控制台输出日志中通常有下面所示片段内容
Hadoop内置的计数器可以收集、统计程序运行中核心信息,帮助用户理解程序的运行情况,辅助用户诊断故障
下面是示例性日志,介绍了计数器
一次map-reduce過程的日志
2022-09-15 16:21:33,324 WARN impl.MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-jobtracker.properties,hadoop-metrics2.properties
2022-09-15 16:21:33,361 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s).
2022-09-15 16:21:33,361 INFO impl.MetricsSystemImpl: JobTracker metrics system started
2022-09-15 16:21:33,874 WARN mapreduce.JobResourceUploader: No job jar file set. User classes may not be found. See Job or Job#setJar(String).
#目錄下的文件數量
2022-09-15 16:21:33,901 INFO input.FileInputFormat: Total input files to process : 1
#maptask針對文件的切片數量
2022-09-15 16:21:33,920 INFO mapreduce.JobSubmitter: number of splits:1
#提交的任務編號
2022-09-15 16:21:33,969 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local279925986_0001
2022-09-15 16:21:33,970 INFO mapreduce.JobSubmitter: Executing with tokens: []
#跟蹤job執行的鏈接
2022-09-15 16:21:34,040 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
#運行中的job
2022-09-15 16:21:34,040 INFO mapreduce.Job: Running job: job_local279925986_0001
2022-09-15 16:21:34,041 INFO mapred.LocalJobRunner: OutputCommitter set in config null
2022-09-15 16:21:34,044 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2
2022-09-15 16:21:34,044 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2022-09-15 16:21:34,044 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
2022-09-15 16:21:34,062 INFO mapred.LocalJobRunner: Waiting for map tasks
#開始map task
2022-09-15 16:21:34,062 INFO mapred.LocalJobRunner: Starting task: attempt_local279925986_0001_m_000000_0
2022-09-15 16:21:34,072 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2
2022-09-15 16:21:34,072 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2022-09-15 16:21:34,077 INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux.
2022-09-15 16:21:34,102 INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@638e9d1a
#輸入文件
2022-09-15 16:21:34,105 INFO mapred.MapTask: Processing split: file:/D:/workspace/bigdata-component/hadoop/test/in/us-covid19-counties.dat:0+136795
2022-09-15 16:21:34,136 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
#map task 100M 内存文件存儲空間
2022-09-15 16:21:34,136 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
# map task的内存存儲空間使用上限是80M
2022-09-15 16:21:34,136 INFO mapred.MapTask: soft limit at 83886080
2022-09-15 16:21:34,136 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
2022-09-15 16:21:34,136 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
2022-09-15 16:21:34,137 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2022-09-15 16:21:34,155 INFO mapred.LocalJobRunner:
2022-09-15 16:21:34,155 INFO mapred.MapTask: Starting flush of map output
2022-09-15 16:21:34,155 INFO mapred.MapTask: Spilling map output
2022-09-15 16:21:34,155 INFO mapred.MapTask: bufstart = 0; bufend = 114725; bufvoid = 104857600
2022-09-15 16:21:34,155 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26201420(104805680); length = 12977/6553600
#以上是將map task的内存存儲空間文件spill的過程
2022-09-15 16:21:34,184 INFO mapred.MapTask: Finished spill 0
2022-09-15 16:21:34,199 INFO mapred.Task: Task:attempt_local279925986_0001_m_000000_0 is done. And is in the process of committing
2022-09-15 16:21:34,200 INFO mapred.LocalJobRunner: map
2022-09-15 16:21:34,200 INFO mapred.Task: Task 'attempt_local279925986_0001_m_000000_0' done.
#map task的計數器
2022-09-15 16:21:34,204 INFO mapred.Task: Final Counters for attempt_local279925986_0001_m_000000_0: Counters: 17
File System Counters
FILE: Number of bytes read=136992
FILE: Number of bytes written=632934
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=3245
Map output records=3245
Map output bytes=114725
Map output materialized bytes=121221
Input split bytes=140
Combine input records=0
Spilled Records=3245
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=5
Total committed heap usage (bytes)=255328256
File Input Format Counters
Bytes Read=136795
2022-09-15 16:21:34,204 INFO mapred.LocalJobRunner: Finishing task: attempt_local279925986_0001_m_000000_0
2022-09-15 16:21:34,205 INFO mapred.LocalJobRunner: map task executor complete.
2022-09-15 16:21:34,207 INFO mapred.LocalJobRunner: Waiting for reduce tasks
2022-09-15 16:21:34,207 INFO mapred.LocalJobRunner: Starting task: attempt_local279925986_0001_r_000000_0
2022-09-15 16:21:34,210 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2
2022-09-15 16:21:34,210 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2022-09-15 16:21:34,210 INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux.
2022-09-15 16:21:34,239 INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@274c3e94
2022-09-15 16:21:34,240 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@5d892772
2022-09-15 16:21:34,241 WARN impl.MetricsSystemImpl: JobTracker metrics system already initialized!
2022-09-15 16:21:34,248 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=2639842560, maxSingleShuffleLimit=659960640, mergeThreshold=1742296192, ioSortFactor=10, memToMemMergeOutputsThreshold=10
#EventFetcher 拉取map task的輸出
2022-09-15 16:21:34,249 INFO reduce.EventFetcher: attempt_local279925986_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
2022-09-15 16:21:34,263 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local279925986_0001_m_000000_0 decomp: 121217 len: 121221 to MEMORY
2022-09-15 16:21:34,264 INFO reduce.InMemoryMapOutput: Read 121217 bytes from map-output for attempt_local279925986_0001_m_000000_0
#合并reduce task從map task輸出文件拉取過來的文件
2022-09-15 16:21:34,265 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 121217, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->121217
2022-09-15 16:21:34,265 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning
#reduce task拷貝文件
2022-09-15 16:21:34,266 INFO mapred.LocalJobRunner: 1 / 1 copied.
#將内存中的文件輸出到磁盤上
2022-09-15 16:21:34,266 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
2022-09-15 16:21:34,273 INFO mapred.Merger: Merging 1 sorted segments
2022-09-15 16:21:34,274 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 121179 bytes
2022-09-15 16:21:34,278 INFO reduce.MergeManagerImpl: Merged 1 segments, 121217 bytes to disk to satisfy reduce memory limit
2022-09-15 16:21:34,279 INFO reduce.MergeManagerImpl: Merging 1 files, 121221 bytes from disk
2022-09-15 16:21:34,279 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce
2022-09-15 16:21:34,279 INFO mapred.Merger: Merging 1 sorted segments
2022-09-15 16:21:34,280 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 121179 bytes
2022-09-15 16:21:34,280 INFO mapred.LocalJobRunner: 1 / 1 copied.
2022-09-15 16:21:34,283 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
2022-09-15 16:21:34,299 INFO mapred.Task: Task:attempt_local279925986_0001_r_000000_0 is done. And is in the process of committing
2022-09-15 16:21:34,301 INFO mapred.LocalJobRunner: 1 / 1 copied.
2022-09-15 16:21:34,301 INFO mapred.Task: Task attempt_local279925986_0001_r_000000_0 is allowed to commit now
#reduce task的輸出文件位置
2022-09-15 16:21:34,306 INFO output.FileOutputCommitter: Saved output of task 'attempt_local279925986_0001_r_000000_0' to file:/D:/workspace/bigdata-component/hadoop/test/out/covid/topn
2022-09-15 16:21:34,307 INFO mapred.LocalJobRunner: reduce > reduce
2022-09-15 16:21:34,307 INFO mapred.Task: Task 'attempt_local279925986_0001_r_000000_0' done.
2022-09-15 16:21:34,307 INFO mapred.Task: Final Counters for attempt_local279925986_0001_r_000000_0: Counters: 24
File System Counters
FILE: Number of bytes read=379466
FILE: Number of bytes written=758828
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Combine input records=0
Combine output records=0
Reduce input groups=55
Reduce shuffle bytes=121221
Reduce input records=3245
Reduce output records=160
Spilled Records=3245
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=0
Total committed heap usage (bytes)=255328256
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Output Format Counters
Bytes Written=4673
2022-09-15 16:21:34,307 INFO mapred.LocalJobRunner: Finishing task: attempt_local279925986_0001_r_000000_0
#reduce task任務執行完成
2022-09-15 16:21:34,308 INFO mapred.LocalJobRunner: reduce task executor complete.
2022-09-15 16:21:35,045 INFO mapreduce.Job: Job job_local279925986_0001 running in uber mode : false
2022-09-15 16:21:35,047 INFO mapreduce.Job: map 100% reduce 100%
2022-09-15 16:21:35,048 INFO mapreduce.Job: Job job_local279925986_0001 completed successfully
2022-09-15 16:21:35,056 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=516458
FILE: Number of bytes written=1391762
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=3245
Map output records=3245
Map output bytes=114725
Map output materialized bytes=121221
Input split bytes=140
Combine input records=0
Combine output records=0
Reduce input groups=55
Reduce shuffle bytes=121221
Reduce input records=3245
Reduce output records=160
Spilled Records=6490
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=5
Total committed heap usage (bytes)=510656512
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=136795
File Output Format Counters
Bytes Written=4673
2、MapReduce内置Counter
- Hadoop为每个MapReduce作业维护了一些内置的计数器,报告程序执行时各种指标信息。用户可以根据这些信息进行判断程序:执行逻辑是否合理、执行结果是否正确。
- Hadoop内置计数器根据功能进行分组(Counter Group)。每个组包括若干个不同的计数器。
- Hadoop计数器都是MapReduce程序中全局的计数器,跟MapReduce分布式运算没有关系,不是所谓的局部统计信息。
- 内置Counter Group包括:MapReduce任务计数器(Map-Reduce Framework)、文件系统计数器(File System Counters)、作业计数器(Job Counters)、输入文件任务计数器(File Input Format Counters)、输出文件计数器(File Output Format Counters)
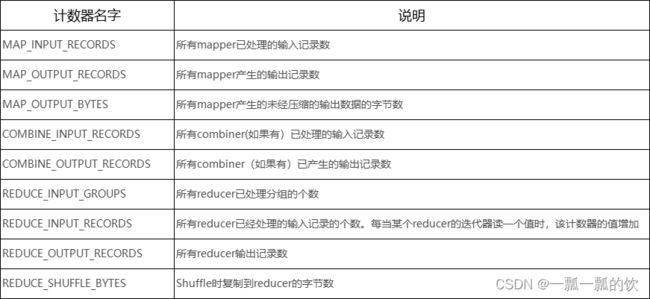
Map-Reduce Framework
Map input records=3245
Map output records=3245
Map output bytes=114725
Map output materialized bytes=121221
Input split bytes=140
Combine input records=0
Combine output records=0
Reduce input groups=55
Reduce shuffle bytes=121221
Reduce input records=3245
Reduce output records=160
Spilled Records=6490
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=5
Total committed heap usage (bytes)=510656512
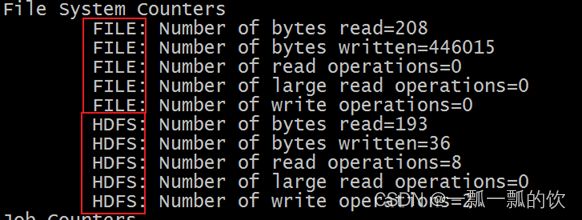
1)、File System Counters
文件系统的计数器会针对不同的文件系统使用情况进行统计,比如HDFS、本地文件系统

File System Counters
FILE: Number of bytes read=516458
FILE: Number of bytes written=1391762
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
2)、Job Counters
统计记录MapReduce 任务启动的task情况,包括:个数、使用资源情况等

3)、File Input|Output Format Counters

File Input Format Counters
Bytes Read=136795
File Output Format Counters
Bytes Written=4673
3、MapReduce自定义Counter
MapReduce提供了用户编写自定义计数器的方法,计数器是全局(整个集群)的统计
1)、需求
针对一批文件进行词频统计(wordcount)MR程序。现要求使用计数器统计出数据中apple出现的总次数。
2)、需求实现
- 通过context.getCounter方法获取一个全局计数器,创建的时候需要指定计数器所属的组名和计数器的名字
- 在程序中需要使用计数器的地方,调用counter提供的方法即可,比如+1操作
3)、实现
- Mapper
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Mapper;
public class CusCounterMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
Text outKey = new Text();
LongWritable outValue = new LongWritable();
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 从程序上下文对象获取一个全局计数器:用于统计hello出现的个数
// 需要指定计数器组 和计数器的名字
Counter counter = context.getCounter("test_cus_counters", "apple Counter");
String[] line = value.toString().split("\t");
for (String word : line) {
if (word.equals("apple")) {
counter.increment(1);
}
outKey.set(word);
outValue.set(1);
context.write(outKey, outValue);
}
}
}
- Reducer
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class CusCounterReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
LongWritable outValue = new LongWritable();
protected void reduce(Text key, Iterable<LongWritable> values, Context context)
throws IOException, InterruptedException {
int num = 0;
for (LongWritable value : values) {
num++;
}
outValue.set(num);
context.write(key, outValue);
}
}
- Driver
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class CusCounterDriver extends Configured implements Tool {
static String in = "D:/workspace/bigdata-component/hadoop/test/in";
static String out = "D:/workspace/bigdata-component/hadoop/test/out/counter";
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new CusCounterDriver(), args);
System.exit(status);
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf(), CusCounterDriver.class.getSimpleName());
job.setJarByClass(CusCounterDriver.class);
job.setMapperClass(CusCounterMapper.class);
job.setReducerClass(CusCounterReducer.class);
// map阶段输出的key-value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// reducer阶段输出的key-value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.addInputPath(job, new Path(in));
FileSystem fs = FileSystem.get(getConf());
if (fs.exists(new Path(out))) {
fs.delete(new Path(out), true);
}
FileOutputFormat.setOutputPath(job, new Path(out));
return job.waitForCompletion(true) ? 0 : 1;
}
}
- 验证
输入文件需要自己造
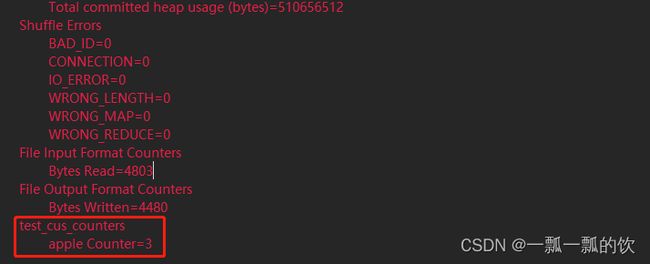
在执行程序的时候,在控制台输出的信息上就有自定义计数器组和计数器统计信息.(源文件中增加了三個apple字符串)
二、读写mysql数据库
读写mysql仅仅是示例性的,其他的数据库操作类似。
1、介绍
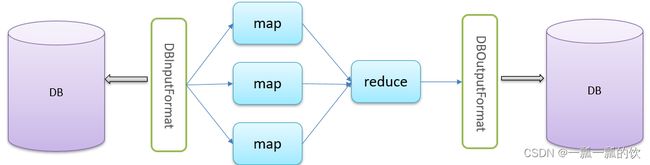
- 对于MapReduce框架来说,使用inputform进行数据读取操作,读取的数据首先由mapper处理,然后交给reducer处理,最终使用outputformat进行数据的输出操作。默认情况下,输入输出的组件实现都是针对文本数据处理的,分别是TextInputFormat、TextOutputFormat。
- 为了方便 MapReduce 直接访问关系型数据库(Mysql,Oracle),Hadoop提供了DBInputFormat和DBOutputFormat两个类。其中DBInputFormat负责从数据库中读取数据,而DBOutputFormat负责把数据最终写入数据库中
2、读取mysql数据
1)、需求
使用MapReduce程序将表中的数据导出存放在指定的文件系统目录下
2)、实现说明
DBInputFormat类用于从SQL表读取数据。底层一行一行读取表中的数据,返回
- 其中k是LongWritable类型,表中数据的记录行号,从0开始;
- 其中v是DBWritable类型,表示该行数据对应的对象类型。
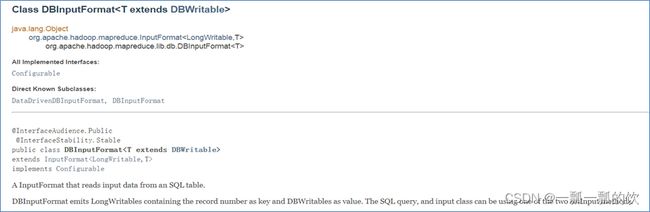
本示例本身是不需要进行数据聚合的,仅仅一个是输出到一个文件中,mapper即可完成,所以不需要reducer。
3)、实现
1、pom.xml
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>3.1.4version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>3.1.4version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>3.1.4version>
dependency>
<dependency>
<groupId>jdk.toolsgroupId>
<artifactId>jdk.toolsartifactId>
<version>1.8version>
<scope>systemscope>
<systemPath>${JAVA_HOME}/lib/tools.jarsystemPath>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-mapreduce-client-coreartifactId>
<version>3.1.4version>
dependency>
<dependency>
<groupId>com.github.pcjgroupId>
<artifactId>google-optionsartifactId>
<version>1.0.0version>
dependency>
<dependency>
<groupId>commons-iogroupId>
<artifactId>commons-ioartifactId>
<version>2.6version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-mapreduce-client-coreartifactId>
<version>3.1.4version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.46version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.22version>
dependency>
2、bean
- 用于封装查询返回的结果(如果要查询表的所有字段,那么属性就跟表的字段一一对应即可)。
- 需要实现setter、getter、toString、构造方法。
- 实现Hadoop序列化接口Writable
- 从数据库读取/写入数据库的对象应实现DBWritable。
DBWritable与Writable相似,区别在于write(PreparedStatement)方法采用PreparedStatement,而readFields(ResultSet)采用ResultSet。
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.lib.db.DBWritable;
import lombok.Data;
/**
* @author alanchan
* 实现Hadoop序列化接口Writable
* 从数据库读取/写入数据库的对象应实现DBWritable
*/
@Data
public class User implements Writable, DBWritable {
private int id;
private String userName;
private String password;
private String phone;
private String email;
private Date createDay;
private SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
@Override
public void write(PreparedStatement ps) throws SQLException {
ps.setInt(0, id);
ps.setString(1, userName);
ps.setString(2, password);
ps.setString(3, phone);
ps.setString(4, email);
ps.setDate(5, (java.sql.Date) createDay);
}
@Override
public void readFields(ResultSet rs) throws SQLException {
this.id = rs.getInt(0);
this.userName = rs.getString(1);
this.password = rs.getString(2);
this.phone = rs.getString(3);
this.email = rs.getString(4);
this.createDay = rs.getDate(5);
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(id);
out.writeUTF(userName);
out.writeUTF(password);
out.writeUTF(phone);
out.writeUTF(email);
out.writeUTF(sdf.format(createDay));
}
@Override
public void readFields(DataInput in) throws IOException {
id = in.readInt();
userName = in.readUTF();
password = in.readUTF();
phone = in.readUTF();
email = in.readUTF();
try {
createDay = sdf.parse(in.readUTF());
} catch (ParseException e) {
e.printStackTrace();
}
}
public String toString() {
return id + "\t" + userName + "\t" + password + "\t" + phone + "\t" + email + "\t" + createDay;
}
}
3、mapper
// LongWritable 是数据库记录的符合条件读取的每行行号,不是数据库中的原始行号
// User 是每行记录的字段值,经过user的DBWrite实现
public static class ReadFromMysqlMapper extends Mapper<LongWritable, User, LongWritable, Text> {
LongWritable outKey = new LongWritable();
Text outValue = new Text();
/**
* 此处加入了一个全局的计数器,看写出的记录数是否与数据库的记录数一致
*/
protected void map(LongWritable key, User value, Context context) throws IOException, InterruptedException {
Counter counter = context.getCounter("mysql_records_counters", "User Records");
outKey.set(key.get());
outValue.set(value.toString());
counter.increment(1);
context.write(outKey, outValue);
}
}
4、reducer
无
5、driver
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* @author alanchan
* 从mysql中读取数据,并写入到文件中
*
*/
public class ReadFromMysql extends Configured implements Tool {
static String out = "D:/workspace/bigdata-component/hadoop/test/out/mysql";
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
// 配置当前作业需要使用的JDBC信息
DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver", "jdbc:mysql://192.168.10.44:3306/test", "root","root");
// 创建作业实例
Job job = Job.getInstance(conf, ReadFromMysql.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(ReadFromMysql.class);
// 设置inputformat类
job.setInputFormatClass(DBInputFormat.class);
FileSystem fs = FileSystem.get(getConf());
if (fs.exists(new Path(out))) {
fs.delete(new Path(out), true);
}
FileOutputFormat.setOutputPath(job, new Path(out));
job.setMapperClass(ReadFromMysqlMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setNumReduceTasks(0);
// 配置当前作业要查询的SQL语句和接收查询结果的JavaBean
// public static void setInput(JobConf job,
// Class inputClass,
// String tableName,
// String conditions,
// String orderBy,
// String... fieldNames)
// job - The job
// inputClass - the class object implementing DBWritable, which is the Java object holding tuple fields.
// inputQuery - the input query to select fields. Example : "SELECT f1, f2, f3 FROM Mytable ORDER BY f1"
// inputCountQuery - the input query that returns the number of records in the table. Example : "SELECT COUNT(f1) FROM Mytable"
// public static void setInput(JobConf job,
// Class inputClass,
// String inputQuery,
// String inputCountQuery)
DBInputFormat.setInput(job, User.class,
"select id, user_Name,pass_word,phone,email,create_day from dx_user ",
// 12606948 条数据
"select count(*) from dx_user ");
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new ReadFromMysql(), args);
System.exit(status);
}
}
6、mapper与driver合并成一个java文件
mapper和驱动类写在一个文件中了,javabean单独
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* @author alanchan
* 从mysql中读取数据,并写入到文件中
*
*/
public class ReadFromMysql extends Configured implements Tool {
static String out = "D:/workspace/bigdata-component/hadoop/test/out/mysql";
// LongWritable 是数据库记录的符合条件读取的每行行号,不是数据库中的原始行号
// User 是每行记录的字段值,经过user的DBWrite实现
public static class ReadFromMysqlMapper extends Mapper<LongWritable, User, LongWritable, Text> {
LongWritable outKey = new LongWritable();
Text outValue = new Text();
/**
* 此处加入了一个全局的计数器,看写出的记录数是否与数据库的记录数一致
*/
protected void map(LongWritable key, User value, Context context) throws IOException, InterruptedException {
Counter counter = context.getCounter("mysql_records_counters", "User Records");
outKey.set(key.get());
outValue.set(value.toString());
counter.increment(1);
context.write(outKey, outValue);
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
// 配置当前作业需要使用的JDBC信息
DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver", "jdbc:mysql://192.168.10.44:3306/test", "root",
"root");
// 创建作业实例
Job job = Job.getInstance(conf, ReadFromMysql.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(ReadFromMysql.class);
// 设置inputformat类
job.setInputFormatClass(DBInputFormat.class);
FileSystem fs = FileSystem.get(getConf());
if (fs.exists(new Path(out))) {
fs.delete(new Path(out), true);
}
FileOutputFormat.setOutputPath(job, new Path(out));
job.setMapperClass(ReadFromMysqlMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setNumReduceTasks(0);
// 配置当前作业要查询的SQL语句和接收查询结果的JavaBean
// public static void setInput(JobConf job,
// Class inputClass,
// String tableName,
// String conditions,
// String orderBy,
// String... fieldNames)
// job - The job
// inputClass - the class object implementing DBWritable, which is the Java object holding tuple fields.
// inputQuery - the input query to select fields. Example : "SELECT f1, f2, f3 FROM Mytable ORDER BY f1"
// inputCountQuery - the input query that returns the number of records in the table. Example : "SELECT COUNT(f1) FROM Mytable"
// public static void setInput(JobConf job,
// Class inputClass,
// String inputQuery,
// String inputCountQuery)
DBInputFormat.setInput(job, User.class,
"select id, user_Name,pass_word,phone,email,create_day from dx_user",
// 12606948 条数据
"select count(*) from dx_user ");
// DBInputFormat.setInput(job, User.class,
// "select id, user_Name,pass_word,phone,email,create_day from dx_user where user_name = 'alan2452'",
// "select count(*) from dx_user where user_name = 'alan2452'");
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new ReadFromMysql(), args);
System.exit(status);
}
}
7、验证
MR输出目录
打开文件后的内容
运行日志
2022-09-19 10:39:17,656 WARN impl.MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-jobtracker.properties,hadoop-metrics2.properties
2022-09-19 10:39:17,691 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s).
2022-09-19 10:39:17,691 INFO impl.MetricsSystemImpl: JobTracker metrics system started
2022-09-19 10:39:18,211 WARN mapreduce.JobResourceUploader: No job jar file set. User classes may not be found. See Job or Job#setJar(String).
2022-09-19 10:39:23,973 INFO mapreduce.JobSubmitter: number of splits:1
2022-09-19 10:39:24,016 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local996413693_0001
2022-09-19 10:39:24,017 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-09-19 10:39:24,115 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
2022-09-19 10:39:24,115 INFO mapreduce.Job: Running job: job_local996413693_0001
2022-09-19 10:39:24,116 INFO mapred.LocalJobRunner: OutputCommitter set in config null
2022-09-19 10:39:24,119 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2
2022-09-19 10:39:24,119 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2022-09-19 10:39:24,120 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
2022-09-19 10:39:24,138 INFO mapred.LocalJobRunner: Waiting for map tasks
2022-09-19 10:39:24,139 INFO mapred.LocalJobRunner: Starting task: attempt_local996413693_0001_m_000000_0
2022-09-19 10:39:24,150 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2
2022-09-19 10:39:24,151 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2022-09-19 10:39:24,157 INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux.
2022-09-19 10:39:24,181 INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@7c7106fc
2022-09-19 10:39:24,199 INFO mapred.MapTask: Processing split: org.apache.hadoop.mapreduce.lib.db.DBInputFormat$DBInputSplit@3aa21f6e
2022-09-19 10:39:25,122 INFO mapreduce.Job: Job job_local996413693_0001 running in uber mode : false
2022-09-19 10:39:25,124 INFO mapreduce.Job: map 0% reduce 0%
2022-09-19 10:39:36,173 INFO mapred.LocalJobRunner: map > map
2022-09-19 10:39:36,227 INFO mapreduce.Job: map 67% reduce 0%
2022-09-19 10:39:42,172 INFO mapred.LocalJobRunner: map > map
2022-09-19 10:39:42,178 INFO mapred.LocalJobRunner: map
2022-09-19 10:39:42,180 INFO mapred.Task: Task:attempt_local996413693_0001_m_000000_0 is done. And is in the process of committing
2022-09-19 10:39:42,181 INFO mapred.LocalJobRunner: map
2022-09-19 10:39:42,181 INFO mapred.Task: Task attempt_local996413693_0001_m_000000_0 is allowed to commit now
2022-09-19 10:39:42,184 INFO output.FileOutputCommitter: Saved output of task 'attempt_local996413693_0001_m_000000_0' to file:/D:/workspace/bigdata-component/hadoop/test/out/mysql
2022-09-19 10:39:42,184 INFO mapred.LocalJobRunner: map
2022-09-19 10:39:42,184 INFO mapred.Task: Task 'attempt_local996413693_0001_m_000000_0' done.
2022-09-19 10:39:42,188 INFO mapred.Task: Final Counters for attempt_local996413693_0001_m_000000_0: Counters: 16
File System Counters
FILE: Number of bytes read=125
FILE: Number of bytes written=1027755264
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=12606948
Map output records=12606948
Input split bytes=78
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=122
Total committed heap usage (bytes)=434634752
mysql_records_counters
User Records=12606948
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=1027243421
2022-09-19 10:39:42,188 INFO mapred.LocalJobRunner: Finishing task: attempt_local996413693_0001_m_000000_0
2022-09-19 10:39:42,189 INFO mapred.LocalJobRunner: map task executor complete.
2022-09-19 10:39:42,273 INFO mapreduce.Job: map 100% reduce 0%
2022-09-19 10:39:42,274 INFO mapreduce.Job: Job job_local996413693_0001 completed successfully
2022-09-19 10:39:42,284 INFO mapreduce.Job: Counters: 16
File System Counters
FILE: Number of bytes read=125
FILE: Number of bytes written=1027755264
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=12606948
Map output records=12606948
Input split bytes=78
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=122
Total committed heap usage (bytes)=434634752
mysql_records_counters
User Records=12606948
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=1027243421
3、写数据到mysql
本示例是将上述示例的文件内容读出并写入至数据库
1)、創建需要寫入的表
DROP TABLE IF EXISTS `dx_user_copy`;
CREATE TABLE `dx_user_copy` (
`id` int(11) NOT NULL,
`user_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`pass_word` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`phone` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`email` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`create_day` datetime(0) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `id_idx`(`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
2)、实现说明
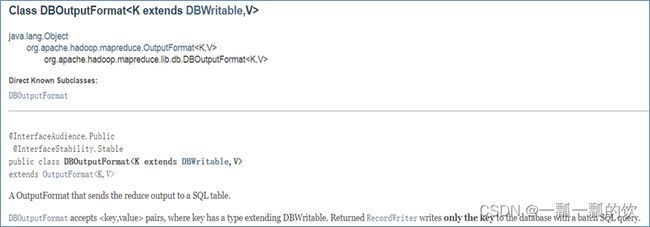
DBOutputFormat ,它将reduce输出发送到SQL表。
DBOutputFormat接受
3)、bean
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.lib.db.DBWritable;
import lombok.Data;
/**
* @author alanchan
* 实现Hadoop序列化接口Writable
* 从数据库读取/写入数据库的对象应实现DBWritable
*/
@Data
public class User implements Writable, DBWritable {
private int id;
private String userName;
private String password;
private String phone;
private String email;
private Date createDay;
private SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
@Override
public void write(PreparedStatement ps) throws SQLException {
ps.setInt(1, id);
ps.setString(2, userName);
ps.setString(3, password);
ps.setString(4, phone);
ps.setString(5, email);
ps.setDate(6, (java.sql.Date) createDay);
}
@Override
public void readFields(ResultSet rs) throws SQLException {
this.id = rs.getInt(1);
this.userName = rs.getString(2);
this.password = rs.getString(3);
this.phone = rs.getString(4);
this.email = rs.getString(5);
this.createDay = rs.getDate(6);
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(id);
out.writeUTF(userName);
out.writeUTF(password);
out.writeUTF(phone);
out.writeUTF(email);
out.writeUTF(sdf.format(createDay));
}
@Override
public void readFields(DataInput in) throws IOException {
id = in.readInt();
userName = in.readUTF();
password = in.readUTF();
phone = in.readUTF();
email = in.readUTF();
try {
createDay = sdf.parse(in.readUTF());
} catch (ParseException e) {
e.printStackTrace();
}
}
public String toString() {
return id + "\t" + userName + "\t" + password + "\t" + phone + "\t" + email + "\t" + createDay;
}
}
4)、mapper
public static class WriteToMysqlMapper extends Mapper<LongWritable, Text, NullWritable, User> {
// private SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
User outValue = new User();
// IntWritable outKey = new IntWritable();
NullWritable outKey = NullWritable.get();
// 數據格式:0 90837025 alan2452 820062 13977776789 [email protected] 2021-12-25
// 數據格式:行號 id userName password phone email createday
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Counter counter = context.getCounter("file_records_counters", "Files of User Records");
counter.increment(1);
String[] fileds = value.toString().split("\t");
if (fileds.length == 7) {
// outKey.set(Integer.parseInt(fileds[0]));
outValue.setId(Integer.parseInt(fileds[1]));
outValue.setUserName(fileds[2]);
outValue.setPassword(fileds[3]);
outValue.setPhone(fileds[4]);
outValue.setEmail(fileds[5]);
outValue.setCreateDay(fileds[6]);
context.write(outKey, outValue);
}
}
}
5)、reducer
public static class WriteToMysqlReducer extends Reducer<NullWritable, User, User, NullWritable> {
protected void reduce(NullWritable key, Iterable<User> values, Context context)
throws IOException, InterruptedException {
for (User value : values) {
context.write(value, NullWritable.get());
}
}
}
6)、driver
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* @author alanchan
* 将文件的内容写入mysql
*/
public class WriteToMysql extends Configured implements Tool {
static String in = "D:/workspace/bigdata-component/hadoop/test/out/mysql";
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
// 配置当前作业需要使用的JDBC信息
DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver", "jdbc:mysql://192.168.10.44:3306/test", "root",
"root");
// 创建作业实例
Job job = Job.getInstance(conf, WriteToMysql.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(WriteToMysql.class);
// 设置mapper相关信息LongWritable, Text, IntWritable, User
job.setMapperClass(WriteToMysqlMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(User.class);
// 设置reducer相关信息 IntWritable, User, User, NullWritable
job.setReducerClass(WriteToMysqlReducer.class);
job.setOutputKeyClass(User.class);
job.setOutputValueClass(NullWritable.class);
// 设置输入的文件的路径
FileInputFormat.setInputPaths(job, new Path(in));
// 设置输出的format类型
job.setOutputFormatClass(DBOutputFormat.class);
//设置reducetask的数量
job.setNumReduceTasks(2);
// 配置当前作业输出到数据库的表、字段信息
// public static void setOutput(Job job,
// String tableName,
// int fieldCount)
// public static void setOutput(Job job,
// String tableName,
// String... fieldNames)
// job - The job
// tableName - The table to insert data into
// fieldNames - The field names in the table.
// id, user_Name,pass_word,phone,email,create_day
DBOutputFormat.setOutput(job, "dx_user_copy", "id", "user_name", "pass_word", "phone", "email", "create_day");
// DBOutputFormat.setOutput(job, "dx_user_copy", 6);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new WriteToMysql(), args);
System.exit(status);
}
}
7)、验证
数据库验证,登录数据库查询结果即可

运行日志验证,本日志是带条件写入后,再将读取的文件作为本示例的输入,所以记录数不是1260多万条,而是5万多条。
2022-09-20 16:52:29,476 WARN impl.MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-jobtracker.properties,hadoop-metrics2.properties
2022-09-20 16:52:29,513 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s).
2022-09-20 16:52:29,513 INFO impl.MetricsSystemImpl: JobTracker metrics system started
2022-09-20 16:52:30,038 WARN mapreduce.JobResourceUploader: No job jar file set. User classes may not be found. See Job or Job#setJar(String).
2022-09-20 16:52:30,070 INFO input.FileInputFormat: Total input files to process : 1
2022-09-20 16:52:30,090 INFO mapreduce.JobSubmitter: number of splits:1
2022-09-20 16:52:30,142 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local368221435_0001
2022-09-20 16:52:30,143 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-09-20 16:52:30,217 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
2022-09-20 16:52:30,217 INFO mapreduce.Job: Running job: job_local368221435_0001
2022-09-20 16:52:30,218 INFO mapred.LocalJobRunner: OutputCommitter set in config null
2022-09-20 16:52:30,221 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2
2022-09-20 16:52:30,221 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2022-09-20 16:52:30,221 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
2022-09-20 16:52:30,224 WARN output.FileOutputCommitter: Output Path is null in setupJob()
2022-09-20 16:52:30,237 INFO mapred.LocalJobRunner: Waiting for map tasks
2022-09-20 16:52:30,237 INFO mapred.LocalJobRunner: Starting task: attempt_local368221435_0001_m_000000_0
2022-09-20 16:52:30,248 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2
2022-09-20 16:52:30,248 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2022-09-20 16:52:30,254 INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux.
2022-09-20 16:52:30,281 INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@7c7e9f9c
2022-09-20 16:52:30,284 INFO mapred.MapTask: Processing split: file:/D:/workspace/bigdata-component/hadoop/test/out/mysql/part-m-00000:0+4659135
2022-09-20 16:52:30,313 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
2022-09-20 16:52:30,313 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
2022-09-20 16:52:30,313 INFO mapred.MapTask: soft limit at 83886080
2022-09-20 16:52:30,313 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
2022-09-20 16:52:30,313 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
2022-09-20 16:52:30,315 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2022-09-20 16:52:30,441 INFO mapred.LocalJobRunner:
2022-09-20 16:52:30,441 INFO mapred.MapTask: Starting flush of map output
2022-09-20 16:52:30,441 INFO mapred.MapTask: Spilling map output
2022-09-20 16:52:30,441 INFO mapred.MapTask: bufstart = 0; bufend = 4353577; bufvoid = 104857600
2022-09-20 16:52:30,441 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26003288(104013152); length = 211109/6553600
2022-09-20 16:52:30,481 INFO mapred.MapTask: Finished spill 0
2022-09-20 16:52:30,490 INFO mapred.Task: Task:attempt_local368221435_0001_m_000000_0 is done. And is in the process of committing
2022-09-20 16:52:30,491 INFO mapred.LocalJobRunner: map
2022-09-20 16:52:30,491 INFO mapred.Task: Task 'attempt_local368221435_0001_m_000000_0' done.
2022-09-20 16:52:30,496 INFO mapred.Task: Final Counters for attempt_local368221435_0001_m_000000_0: Counters: 18
File System Counters
FILE: Number of bytes read=4695740
FILE: Number of bytes written=4972724
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=52778
Map output records=52778
Map output bytes=4353577
Map output materialized bytes=4459145
Input split bytes=136
Combine input records=0
Spilled Records=52778
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=0
Total committed heap usage (bytes)=8236040192
file_records_counters
Files of User Records=52778
File Input Format Counters
Bytes Read=4695547
2022-09-20 16:52:30,496 INFO mapred.LocalJobRunner: Finishing task: attempt_local368221435_0001_m_000000_0
2022-09-20 16:52:30,496 INFO mapred.LocalJobRunner: map task executor complete.
2022-09-20 16:52:30,498 INFO mapred.LocalJobRunner: Waiting for reduce tasks
2022-09-20 16:52:30,498 INFO mapred.LocalJobRunner: Starting task: attempt_local368221435_0001_r_000000_0
2022-09-20 16:52:30,502 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2
2022-09-20 16:52:30,502 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2022-09-20 16:52:30,502 INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux.
2022-09-20 16:52:30,527 INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@3690ac3
2022-09-20 16:52:30,529 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@7843679b
2022-09-20 16:52:30,530 WARN impl.MetricsSystemImpl: JobTracker metrics system already initialized!
2022-09-20 16:52:30,537 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=5765228032, maxSingleShuffleLimit=1441307008, mergeThreshold=3805050624, ioSortFactor=10, memToMemMergeOutputsThreshold=10
2022-09-20 16:52:30,538 INFO reduce.EventFetcher: attempt_local368221435_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
2022-09-20 16:52:30,553 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local368221435_0001_m_000000_0 decomp: 4459135 len: 4459139 to MEMORY
2022-09-20 16:52:30,558 INFO reduce.InMemoryMapOutput: Read 4459135 bytes from map-output for attempt_local368221435_0001_m_000000_0
2022-09-20 16:52:30,559 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 4459135, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->4459135
2022-09-20 16:52:30,559 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning
2022-09-20 16:52:30,559 INFO mapred.LocalJobRunner: 1 / 1 copied.
2022-09-20 16:52:30,560 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
2022-09-20 16:52:30,567 INFO mapred.Merger: Merging 1 sorted segments
2022-09-20 16:52:30,567 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 4459133 bytes
2022-09-20 16:52:30,589 INFO reduce.MergeManagerImpl: Merged 1 segments, 4459135 bytes to disk to satisfy reduce memory limit
2022-09-20 16:52:30,589 INFO reduce.MergeManagerImpl: Merging 1 files, 4459139 bytes from disk
2022-09-20 16:52:30,590 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce
2022-09-20 16:52:30,590 INFO mapred.Merger: Merging 1 sorted segments
2022-09-20 16:52:30,591 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 4459133 bytes
2022-09-20 16:52:30,591 INFO mapred.LocalJobRunner: 1 / 1 copied.
2022-09-20 16:52:30,745 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
2022-09-20 16:52:31,224 INFO mapreduce.Job: Job job_local368221435_0001 running in uber mode : false
2022-09-20 16:52:31,224 INFO mapreduce.Job: map 100% reduce 0%
2022-09-20 16:52:42,524 INFO mapred.LocalJobRunner: reduce > reduce
2022-09-20 16:52:43,342 INFO mapreduce.Job: map 100% reduce 50%
2022-09-20 16:53:03,408 INFO mapred.Task: Task:attempt_local368221435_0001_r_000000_0 is done. And is in the process of committing
2022-09-20 16:53:03,409 INFO mapred.LocalJobRunner: reduce > reduce
2022-09-20 16:53:03,409 INFO mapred.Task: Task 'attempt_local368221435_0001_r_000000_0' done.
2022-09-20 16:53:03,410 INFO mapred.Task: Final Counters for attempt_local368221435_0001_r_000000_0: Counters: 24
File System Counters
FILE: Number of bytes read=13614080
FILE: Number of bytes written=9431863
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Combine input records=0
Combine output records=0
Reduce input groups=1
Reduce shuffle bytes=4459139
Reduce input records=52778
Reduce output records=52778
Spilled Records=52778
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=29
Total committed heap usage (bytes)=8236040192
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Output Format Counters
Bytes Written=0
2022-09-20 16:53:03,410 INFO mapred.LocalJobRunner: Finishing task: attempt_local368221435_0001_r_000000_0
2022-09-20 16:53:03,410 INFO mapred.LocalJobRunner: Starting task: attempt_local368221435_0001_r_000001_0
2022-09-20 16:53:03,411 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2
2022-09-20 16:53:03,411 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2022-09-20 16:53:03,411 INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux.
2022-09-20 16:53:03,432 INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@68ad8cf0
2022-09-20 16:53:03,432 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@4d1099c4
2022-09-20 16:53:03,432 WARN impl.MetricsSystemImpl: JobTracker metrics system already initialized!
2022-09-20 16:53:03,433 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=5765228032, maxSingleShuffleLimit=1441307008, mergeThreshold=3805050624, ioSortFactor=10, memToMemMergeOutputsThreshold=10
2022-09-20 16:53:03,433 INFO reduce.EventFetcher: attempt_local368221435_0001_r_000001_0 Thread started: EventFetcher for fetching Map Completion Events
2022-09-20 16:53:03,436 INFO reduce.LocalFetcher: localfetcher#2 about to shuffle output of map attempt_local368221435_0001_m_000000_0 decomp: 2 len: 6 to MEMORY
2022-09-20 16:53:03,436 INFO reduce.InMemoryMapOutput: Read 2 bytes from map-output for attempt_local368221435_0001_m_000000_0
2022-09-20 16:53:03,436 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 2, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->2
2022-09-20 16:53:03,436 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning
2022-09-20 16:53:03,437 INFO mapred.LocalJobRunner: 1 / 1 copied.
2022-09-20 16:53:03,437 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
2022-09-20 16:53:03,440 INFO mapred.Merger: Merging 1 sorted segments
2022-09-20 16:53:03,440 INFO mapred.Merger: Down to the last merge-pass, with 0 segments left of total size: 0 bytes
2022-09-20 16:53:03,441 INFO reduce.MergeManagerImpl: Merged 1 segments, 2 bytes to disk to satisfy reduce memory limit
2022-09-20 16:53:03,441 INFO reduce.MergeManagerImpl: Merging 1 files, 6 bytes from disk
2022-09-20 16:53:03,441 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce
2022-09-20 16:53:03,441 INFO mapred.Merger: Merging 1 sorted segments
2022-09-20 16:53:03,442 INFO mapred.Merger: Down to the last merge-pass, with 0 segments left of total size: 0 bytes
2022-09-20 16:53:03,442 INFO mapred.LocalJobRunner: 1 / 1 copied.
2022-09-20 16:53:03,451 INFO mapred.Task: Task:attempt_local368221435_0001_r_000001_0 is done. And is in the process of committing
2022-09-20 16:53:03,452 INFO mapred.LocalJobRunner: reduce > reduce
2022-09-20 16:53:03,452 INFO mapred.Task: Task 'attempt_local368221435_0001_r_000001_0' done.
2022-09-20 16:53:03,452 INFO mapred.Task: Final Counters for attempt_local368221435_0001_r_000001_0: Counters: 24
File System Counters
FILE: Number of bytes read=13614148
FILE: Number of bytes written=9431869
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Combine input records=0
Combine output records=0
Reduce input groups=0
Reduce shuffle bytes=6
Reduce input records=0
Reduce output records=0
Spilled Records=0
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=0
Total committed heap usage (bytes)=8236040192
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Output Format Counters
Bytes Written=0
2022-09-20 16:53:03,452 INFO mapred.LocalJobRunner: Finishing task: attempt_local368221435_0001_r_000001_0
2022-09-20 16:53:03,452 INFO mapred.LocalJobRunner: reduce task executor complete.
2022-09-20 16:53:03,455 WARN output.FileOutputCommitter: Output Path is null in commitJob()
2022-09-20 16:53:03,551 INFO mapreduce.Job: map 100% reduce 100%
2022-09-20 16:53:03,552 INFO mapreduce.Job: Job job_local368221435_0001 completed successfully
2022-09-20 16:53:03,563 INFO mapreduce.Job: Counters: 31
File System Counters
FILE: Number of bytes read=31923968
FILE: Number of bytes written=23836456
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=52778
Map output records=52778
Map output bytes=4353577
Map output materialized bytes=4459145
Input split bytes=136
Combine input records=0
Combine output records=0
Reduce input groups=1
Reduce shuffle bytes=4459145
Reduce input records=52778
Reduce output records=52778
Spilled Records=105556
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=29
Total committed heap usage (bytes)=24708120576
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
file_records_counters
Files of User Records=52778
File Input Format Counters
Bytes Read=4695547
File Output Format Counters
Bytes Written=0
至此,已经完成了MR的计数器、读写数据库的介绍。