日常小知识点之用户层网络缓冲区(固定内存,ringbuffer,chainbuffer)
1:网络缓冲区理解
1.1:理解背景
我们在网络编程时,通常以五元组,一个fd标识一个连接(套接字fd)。
==》每个连接其实有接收消息和发送消息的功能。
==》内核为每个连接分配了固定大小的发送缓冲区和接收缓冲区(套接字缓冲区)。
==》我们通过相关api接口(如send(),recv())根据五元组标识操作对应缓冲区。
以网络通信为例理解,个人理解如下:

注释: 这里套接字fd对应的缓冲区中的数据,其实是由内核协议栈解析后,我们实际发送/接收的数据。(udp/tcp协议,由内部协议栈处理,我们关注的是我们的数据)
1.2:用户层思考(引入缓冲区)
1.2.1:概述:
用户层,我们主要就是通过套接字fd,使用接口send()或者recv(),操作内核中对应套接字的发送缓冲区和接收缓冲区。
1.2.2:方案思考:
针对每个连接,每个缓冲区中存储的数据可能是多次发送的多个消息。(tcp是可靠的能保证接收顺序,udp可能需要用户层控制一下)
===》我们需要定制协议,区分多个数据包,每个数据包的完整性。
===》针对发送缓冲区,如果缓冲区剩余内存不够,我们应该怎么处理。
===》针对接收缓冲区,如果我们取数据,如果没能取到一个完整数据包的数据,该怎麽处理?
1.2.3:如何区分多个包?(用户层协议)
相关方案可以自己设计,大概方案有:
1:特定结束收尾符标识。(例如:telnet用\n标识 redis用 \r\n标识)
2:发送固定大小的数据包。(根据固定大小进行数据的解析)
3:固定内存大小标识接收数据长度+数据包。(长度+数据)
4:类似tcp/udp协议包,自己设计协议。
1.2.4:优化发送与接收,如何保证接收到完整数据包,发送时内核缓冲区不够?(缓冲区)
1.2.4.1:引入问题
接收时,如果收到的不是完整的数据包,需要对数据进行缓存。
发送时,如果缓冲区内存不够,需要对未发送的数据进行缓存。
1.2.4.2:引入解决方案(缓冲区)
问题引申为需要缓冲区的问题,在用户层处理时,我们需要缓冲区来协调业务。
这里可以知道,我们缓冲区的方案应该是:
===》每个连接(套接字fd),对应一个发送缓冲区和一个接收缓冲区。
1.2.4.3:缓冲区实现方案
1:可以用固定内存作为缓冲区(需要变量维护读写指针位置,每次完数据对缓冲区剩余数据进行移动处理)==》这个方案我用过
2:ringbuffer (用结构体标识内存地址,内存大小,数据读的位置,写的位置对结构进行控制)
3:chainbuffer(对ringbuffer的优化)
2:缓冲区实现方案。
2.1:固定内存作为缓冲区(用过)
2.1.1:认知
申请固定内存作为缓冲区,用读指针和写指针进行标识。

==》初始化,申请堆内存,作为缓冲区。
==》写数据,从write_ptr,判断数据是否可写,可写才能写入。
==》读数据,从read_ptr开始,需要根据**用户协议(如包尾特定标识,TLV)**判断是否够完整的包,取数据进行消费。(同时,为了适应业务,需要把读后read_ptr指针指向堆内存起始位置)
==》释放,释放堆内存即可。
2.1.2:实现方案:
==》申请一块内存
==》每次取数据后,始终把可读区域放在内存最前面,保证空闲内存可用。(每次都要memmove)
==》需要标识可写位置,以及剩余可写的内存的大小。
==》需要标识的参数:内存地址(也是读首地址),可写地址(指针/数字标识即可),可写内存大小(数字标识即可)
注意:前提是可判断包的完整,自定方案(TLV,或者包尾特定标识或者固定长度)
3.1.3:优缺点分析
最简单的缓存方案,能做临时缓存
==》1:可以发现可写数据包大小有限制,在包过大时,是不可行的(空间利用率低,适应业务场景局限(限制包的大小),伸缩性查,)
==》2:每次读数据,需要移动缓存中数据位置,memmove
2.2:ringbuffer作为缓冲区(用过有源码)
2.2.1:原理
==》底层还是固定内存,
==》只是针对存/取数据的方案由我们进行控制,实现api,
==》从封装后使用上看,对内存的操作,更像是一个环。
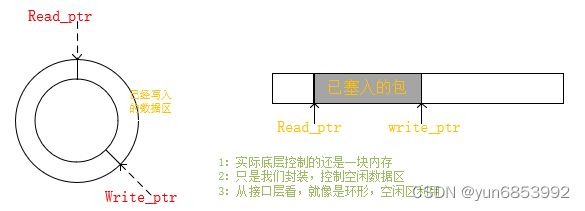
总结:起始固定缓冲区,进行封装api,使首部已取空闲区和尾部未用空闲区可以连接使用,同事消费是也要注意,到内存尾部后,取最前面的数据。
2.2.2:实现
定义结构:需要标识内存地址,可读位置,可写位置,以及剩余可写大小。
需要根据业务场景做一定的协调,这里主要是放数据时,环的处理,和写数据时,环的处理。
==》其实就是需要注意:读写指针错位时,对内存的控制。
2.2.3:主要定义数据结构和api接口如下:
以前根据业务实现的一块逻辑,业务不一定适配,但是对读写指针错位环的处理思路可参考,留作自己笔记备份。
typedef struct RINGBUFF_T{
void * data;
unsigned int size;
unsigned int read_pos; //数据起始位置
unsigned int write_pos; //数据终止位置
}ringbuffer_t;
//创建ringbuffer
ringbuffer_t * ringbuffer_create(unsigned int size);
//销毁ringbuffer
void ringbuffer_destroy(ringbuffer_t * ring_buffer);
//判断是否是完整的数据 然后进行处理 自行根据业务实现
//int ringbuffer_get_len(ringbuffer_t *ring_buffer);
//往ringbuffer中存数据 写入
int ringbuffer_put(ringbuffer_t * ring_buffer, const char* buffer, unsigned int len)
{
//两块空闲区 并且可以放入
if(ring_buffer->write_pos >=ring_buffer->read_pos &&(len <(ring_buffer->size - ring_buffer->write_pos +ring_buffer->read_pos)))
{
//进行拷贝
if(ring_buffer->size - ring_buffer->write_pos >len)
{
memcpy(ring_buffer->data + ring_buffer->write_pos, buffer, len);
ring_buffer->write_pos += len;
}else
{
unsigned int right_space_len = ring_buffer->size - ring_buffer->write_pos;
memcpy(ring_buffer->data + ring_buffer->write_pos, buffer, right_space_len);
memcpy(ring_buffer->data, buffer+right_space_len, len - right_space_len);
ring_buffer->write_pos = len - right_space_len;
}
return 0;
}
if(ring_buffer->write_pos <ring_buffer->read_pos && (ring_buffer->read_pos - ring_buffer->write_pos) >len)
{
memcpy(ring_buffer->data + ring_buffer->write_pos, buffer, len);
ring_buffer->write_pos += len;
return 0;
}
return -1;
}
//从ringbuffer中取数据做处理, 判断接收到的字符是否是终结符号,就可以去做处理
//取完数据后重置ringbuffer的位置 读取
int ringbuffer_get(ringbuffer_t * ring_buffer, char * buffer, unsigned int len)
{
//这里建立在ringbuffer_get_len 的基础上,传入入参,取出数据
int data_len = ringbuffer_use_len(ring_buffer);
if(data_len >= len)
{
LOG_ERROR("para buffer is not enough space \n");
return -1;
}
if(ring_buffer->write_pos >ring_buffer->read_pos )
{
memcpy(buffer, ring_buffer->data + ring_buffer->read_pos, data_len);
}else
{
memcpy(buffer, ring_buffer->data+ring_buffer->read_pos, ring_buffer->size - ring_buffer->read_pos);
memcpy(buffer+ring_buffer->size - ring_buffer->read_pos, ring_buffer->data, data_len - (ring_buffer->size - ring_buffer->read_pos));
}
//这里是符合我业务的一个处理,判断可取,一次取完,可自行设计
ring_buffer->write_pos = 0;
ring_buffer->read_pos = 0;
return 0;
}
2.2.4:优缺点分析。
封装控制了读写指针的操作,使我们不再关注细节。
==》0:需要控制读写指针错误情况。
==》1:还是固定的内存块,对包的大小有限制(空间利用率不高)
==》2:参考固定内存做缓存,虽然不必指针的移动,但在特定情况下,需要memcpy多次。
==》3:可扩展,可伸缩性差。
注意:一般控制内存都在堆上,栈上申请过多内存会导致栈溢出。
2.2.5:可优化
对多块分开的内存需要写数据,除了memcpy多次,可以用readv()
取多块不连续的内存中的数据到一块缓存,除了memcpy多次,可以用writev()
#include 2.3:chainbuffer(理论整理思路)
环形缓冲区,可以通过writev()和readv()优化多次的IO调用。
如何优化使内存可扩展,提高其伸缩性?
2.3.1:原理
固定内存和ringbuffer都是使用了一块内存作为缓冲区,需要处理读写错位的现象
我们可以使用多块内存作为缓冲区,把读写错误以及可扩展性,扩展到内存结构控制上。
参考结构定义看图:
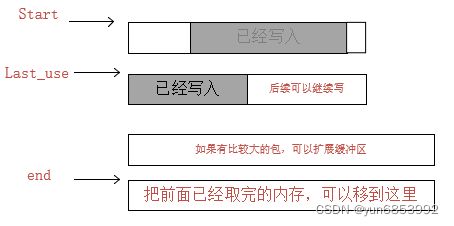
2.3.2:结构源码
//可以调整控制 就是管理一块内存的读与写
typedef struct buff_chans_s
{
struct buff_chans_s *next; //多块缓存链表,start指向链表最开始的元素,end指向最后一个,last_use是中间正在使用的块
unsigned int all_size; //内存块总大小
unsigned int misalign; //开始读数据的位置
unsigned int buffer_size; //还有数据的大小,不一定写满
unsigned char *buffer; //内存块的地址
}buff_chans_t;
typedef struct buffer_s
{
buff_chans_t* start; //缓冲区第一块内存
buff_chans_t* end; //缓冲区最后一块内存指向
buff_chans_t** last_use; //最后一个正在使用的内存块,即正在写的缓存
unsigned int total_len; //所有内存的总大小,即缓冲区总大小
}buffer_t;
2.3.3:接口分析
1:初始化:定义buffer_t结构的对象,未对内部结构进行初始化。
2:存数据:
===》申请一块内存,作为缓冲区的一个节点,开始使用。(这里可以做大小控制,也可以根据包的大小做适当调整)
===》开始申请内存,和没有可用内存时(end=*last_use)申请内存一样
===》申请内存,由buff_chans_t结构进行控制
3:取数据
==》从start节点开始取数据,符合要求则取。
==》如果start节点数据取完,可以对节点进行移动控制,达到内存可重用。
4:释放
==》释放所有节点内存
2.3.4:优缺点分析
实现了内存的可伸缩扩展。
还是会有需要多次拷贝的场景,但是理解上更直观,(本节点尾部+next节点的首部)
3:总结
其实就是对缓冲区的实现方案,在自己已有的理解上做了整理。
固定内存,ringbuffer,以及chain buffer,其实就是操作一块或者多块内存,作为中间缓冲区为业务服务。
固定内存的方案和ringbuffer的方案我有用过,且有对应的源码demo。
chain buffer局限于个人理解。
除此之外,新接触到的接口知识点readv()和writev()。
个人知识点来自课程,做理解及笔记,期待变成自己的。
C/C++Linux服务器开发/后台架构师【零声教育】:https://ke.qq.com/course/417774?flowToken=1041280