Oracle数据库
文章目录
- Oracle 第一天
-
- 一、Oracle 概念介绍(了解)
- 二、Oracle 体系结构(理解)
- 三、创建表空间和用户(理解)
-
- 3.1 创建表空间
- 3.2 删除表空间
- 3.3 创建用户
- 3.4 给用户授权
- 四、Oracle 数据类型(应用)
- 五、DDL语法(应用)
-
- 5.1DDL介绍
- 5.2 创建表
- 5.3 修改表
- 六、数据库的DML(应用)
-
- 6.1 序列
-
- 6.1.1 创建序列
- 6.1.2 查看序列
- 6.2 插入数据
- 6.3 修改数据
- 6.4 删除数据
- Oracle 第二天
-
- 一、数据库的查询
-
- 1.1 scott用户下表的结构(了解)
-
- 1.1.1 EMP表
- 1.1.2 DEPT表
- 1.1.3 SALGRADE表
- 1.1.4 BONUS表
- 1.2 函数(应用)
-
- 1.2.1 单行函数
-
- 1.2.1.1 常用的字符函数
- 1.2.1.2 常用的数值函数
- 1.2.1.3 常用的日期函数
- 1.2.1.4 常用的转换函数
- 1.2.1.5 通用函数
- 1.2.1.6 条件表达式
- 1.2.2 多行函数
- 1.3 group by(应用)
- 1.4 SQL语句执行顺序
- 1.5 多表查询(应用)
- 1.6 子查询
- 1.7 分页查询
- 二、Oracle 对象
-
- 2.1 视图
-
- 2.1.1 视图的概念
- 2.1.2 视图的创建
- 2.1.3 视图的作用
- 2.2 索引(了解)
-
- 2.2.1 索引的概念
- 2.2.2 索引的分类(简单介绍)
- 三、Oracle编程
-
- 3.1 PL/SQL 编程语言
-
- 3.1.1 PL/SQL的特性(了解)
- 3.1.2 PL/SQL的声明方法(掌握)
- 3.1.3 PL/SQL的if 判断(应用)
- 3.1.4 PL/SQL的循环(应用)
-
- 3.1.4.1 while 循环(条件成立时执行)
- 3.1.4.2 exit 循环(条件成立时退出)(应用)
- 3.1.4.3 for 循环(应用)
- 3.1.5 PL/SQL的游标(应用)
- 3.2 存储过程(理解)
- 3.3 存储函数(理解)
- 3.4 存储过程和存储函数的区别
- 3.5 触发器
-
- 3.5.1 概念
- 3.5.2 语句级触发器
- 3.5.3 行级别触发器
- 四、java 调用存储过程
-
- 4.1 环境准备
- 4.2 环境测试
- 4.3 调用存储过程/函数
-
- 4.3.1 调用存储过程
- 4.3.2 调用存储函数
Oracle 第一天
一、Oracle 概念介绍(了解)
Oracle Database,又名Oracle RDBMS,或简称Oracle。是甲骨文公司的一款关系数据库管理系统。它是在数据库领域一直处于领先地位的产品。可以说Oracle数据库系统是目前世界上流行的关系数据库管理系统,系统可移植性好、使用方便、功能强,适用于各类大、中、小、微机环境。它是一种高效率、可靠性好的适应高吞吐量的数据库解决方案。
平常所说的Oracle可以指Oracle数据库管理系统。Oracle数据库管理系统是管理数据库访问的计算机软件(Oracle database manager system)。它由Oracle 数据库和Oracle 实例( instance)构成(区分mysql, mysql没有实例的概念)。
数据库(database): 物理操作系统文件或磁盘的集合。
Oracle实例 : 位于物理内存的数据结构,它由操作系统的多个后台进程和一个共享的内存池所组成,共享的内存可以被所有进程访问。Oracle用它们来管理数据库访问。用户如果要存取数据库(也就是硬盘上的文件〉里的数据,必须通过Oracle实例才能实现,不能直接读取硬盘上的文件。实际上,Oracle 实例就是平常所说的数据库服务( service)。在任何时刻,一个实例只能与一个数据库关联,访问一个数据库; 而同一个数据库可由多个实例访问(RAC)
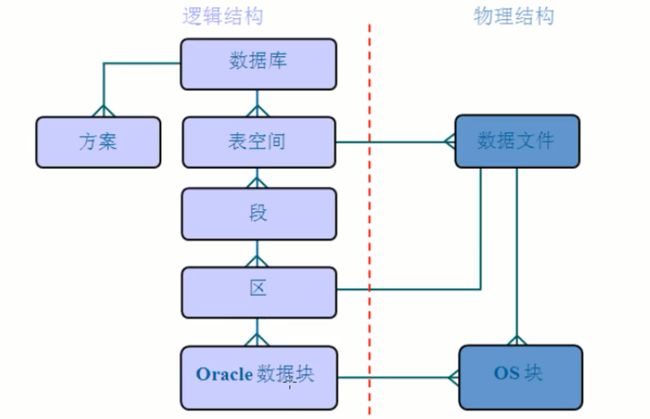
二、Oracle 体系结构(理解)
-
数据库
Oracle数据库是数据的物理存储。这就包括(数据文件ORA或者DBF、控制文件、联机日志、参数文件)。其实Oracle数据库的概念和其它数据库不一样,这里的数据库是一个操作系统只有一个库。可以看作是Oracle就只有一个大数据库。
-
实例
一个Oracle实例(Oracle Instance)有一系列的后台进程(Backguouud Processes)和内存结构(Memory Structures)组成。一个数据库可以有n个实例。
注: 一组Oracle后台进程/线程以及一个共享内存区,这些内存由同一个计算机上运行的线程/进程所共享。这里可以维护易失的、非持久性内容(有些可以刷新输出到磁盘)。就算没有磁盘存储,数据库实例也能存在。
-
用户
用户是在实例下建立的。不同实例可以建相同名字的用户。用户登陆后只能看到和操作自己的表, ORACLE 的用户与 MYSQL 的数据库类似,每建立一个应用需要创建一个用户。
注: Oracle 数据库建好后,要想在数据库里建表,必须先为数据库建立用户,并为用户指定表空间
-
表空间
表空间是Oracle对物理数据库上相关数据文件(ORA或者DBF 文件)的逻辑映射。一个数据库在逻辑上被划分成一到若干个表空间,每个表空间包含了在逻辑上相关联的一组结构。每个数据库至少有一个表空间(称之为system表空间)。
注: 每个表空间由同一磁盘上的一个或多个文件组成,这些文件叫数据文件(datafile)。一个数据文件只能属于一个表空间。
-
数据文件(dbf、ora)
数据文件 是 数据库的物理存储单位。数据库的数据是存储在表空间中的,真正是在某一个或者多个数据文件中。而一个表空间可以由一个或多个数据文件组成,一个数据文件只能属于一个表空间。一旦数据文件被加入到某个表空间后,就不能删除这个文件,如果要删除某个数据文件,只能删除其所属于的表空间才行
注: 表的数据,是由用户放入某一个表空间的,而这个表空间会随机把这些表数据放到一个或者多个数据文件中。由于oracle的数据库不是普通的概念,oracle是由用户和表空间对数据进行管理和存放的。但是表不是由表空间去查询的,而是由用户去查的。因为不同用户可以在同一个表空间建立同一个名字的表! 这里区分就是用户了!
Oracle体系结构如图2-1和图2-2。

三、创建表空间和用户(理解)
表空间? ORACLE数据库的逻辑单元。数据库–表空间 一个表空间可以与多个数据文件(物理结构)关联
一个数据库下可以建立多个表空间,一个表空间可以建立多个用户、一个用户下可以建立多个表。
3.1 创建表空间
create tablespace jiangqi
datafile 'F:\OracleDataBase\text.dbf'
size 100m
autoextend on
next 10m;
注意:
-
jiangqi:表空间名称
-
datafile :指定表空间对应的数据文件,注意:文件名以 .dbf 结尾。
-
size :后定义的是表空间的初始大小。
-
autoextend on :自动增长,当表空间存储都占满时,自动增长。
-
next :后指定的是一次自动增长的大小。
3.2 删除表空间
drop tablespace jiangqi;
3.3 创建用户
-- 创建用户
create user jiangqi
identified by jiangqi
default tablespace jiangqi;
注意:
-
user :后定义的是用户名
-
identified by :后指定的是该用户的密码
-
default tablespace:指定用户的出生地,即所在的空间表
3.4 给用户授权
-
Oracle 数据库中常用角色
- connect – 连接角色,基本角色
- resource – 开发者角色(在公司,一般使用这个权限)
- dba --超级管理员角色(在公司,一般不会给这个权限)
-
给jiangqi 用户授予dba 角色
grant dba to jiangqi;
注意:
在创建用户以后,必须给用户授权,否则用户无法登录。
四、Oracle 数据类型(应用)
| 序号 | 数据类型 | 描述 |
|---|---|---|
| 1 | char(n) | 表示一个定长字符串,n 代表长度 |
| 2 | varchar,varchar2 | 表示一个可变字符串 |
| 3 | number | number(n) 表示一个整数,长度是 n |
| number(m,n) 表示一个小数,总长度是 m ,小数是 n ,整数是 m-n | ||
| 4 | data | 表示日期类型,精确到年月日时分秒 |
| 5 | clob | 大对象,表示大文本数据类型,可存 4G (例:图书馆里所有的书) |
| 6 | blob | 大对象,表示二进制数据,可存 4G(例:很大的视频用这个类型) |
五、DDL语法(应用)
5.1DDL介绍
SQL 语句主要可以划分为以下 3 个类别
-
DDL(Data Definition Languages)语句:数据定义语言,这些语句定义了不同的数据段、数据库、表、列、索引等数据库对象。常用的语句关键字主要包括 create、drop、alter 等。
-
DML(Data Manipulation Languages)语句:数据操纵语句,用于添加、删除、更新和查询数据库记录,并检查数据完整性。常用的语句关键字主要包括 insert、delete、update 和 select 等。
-
DCL(Data Control Language)语句:数据控制语句,用于控制不同数据段直接的许可和访问级别的语句,这些语句定义了数据库、表、字段、用户的访问权限和安全级别,主要的语句关键字包括 grant、revoke 等。
-
DDL 是数据定于语言的缩写,简单来说,就是对数据库内部的对象进行创建、删除、修改等操作的语言。它和 DML 语言的最大区别是 DML 只是对表内部数据操作,而不涉及表的定义,结构的修改,更不会涉及其他对象。DDL 语句更多的由数据库管理员(DBA)使用,开发人员一般很少使用。
-
DDL(data definition language):DDL 比 DML 要多,主要的命令有 CREATE、ALTER、DROP 等,DDL 主要是用在定义或改变表(TABLE)的结构,数据类型,表之间的链接和约束等初始化工作上,他们大多在建立表时使用。
-
DDL(Data Definition Language,数据定义语言): 用于定义数据的结构,比如 创建、修改或者删除数据库对象。
-
DDL 包括:DDL 语句可以用于创建用户和重建数据库对象。下面是 DDL 命令:
- create table:创建表
- alter table:修改表
- drop table:删除表
- create index:创建索引
- drop index:删除索引
5.2 创建表
-- 创建一个 person 表
create table person(
pid number(20),
pname varchar2(10)
);
5.3 修改表
-
修改表名
rename 原表名 to 新表名
rename person to person_new; -
修改列名
alter table 表名 rename column 列名 to 新列名
alter table person rename column gender to sex; -
修改字段类型
alter table 表名 modify(字段 类型)
-- 修改一列 alter table person modify gender char(1); -- 修改多列 alter table person modify (gender char(1),pname char(5));注意:
单列直接写,多列用括号括起来,中间用逗号隔开
-
添加列
alter table 表名 add 字段 类型
-- 添加一列 alter table person add gender number(1); -- 添加多列 alter table person add (gender number(1),age number(3)); -
删除列
alter table 表名 drop column 字段
alter table person drop column sex; -
删除表
drop table 表名;
drop table person;
六、数据库的DML(应用)
DML (Data ManipulationLanguage数据操控语言)用于操作数据库对象中包含的数据,也就是说操作的单位是记录。
Oracle数据库的 DML表数据的操作有三种:
- insert(插入)
- update(更新)
- delete(删除)
6.1 序列
在很多数据库中都存在一个自动增长的列,如果现在要想在oracle中完成自动增长的功能,则只能依靠序列完成,所有的自动增长操作,需要用户手动完成处理。
-- 语法 :
CREATE SEQUENCE 序列名
[INCREMENT BY n]
[START WITH n]
[{MAXVALUE/ MINVALUE n|NOMAXVALUE}]
[{CYCLE |NOCYCLE}]
[{CACHE n|NOCACHE}];
6.1.1 创建序列
create sequence s_person;
6.1.2 查看序列
序列创建完成之后,所有的自动增长应该由用户自己处理,所以在序列中提供了以下的两种操作:
-
nextval :取得序列的下一个内容
-
currval :取得序列的当前内容
select s_person.nextval from dual; select s_person.currval from dual;
注意:
- 序列不真的属于任何一张表,但是可以逻辑和表做绑定。
- 序列 :默认从 1 开始,依次递增,主要用来给主键赋值使用。
- dual :虚表,只是为了补全语法,没有任何意义。
6.2 插入数据
-
普通插入
insert into person (pid,pname) values (1,'小明'); commit; -
在插入数据时需要自增的主键
insert into person (pid,pname) values (s_person.nextval,'小明'); commit;注意:
在使用pl/sql工具时,凡增删改都要加上 commit 语句,防止出现脏数据的情况。
6.3 修改数据
update person set pname = '小马' where pid = 1;
commit;
6.4 删除数据
-
删除表中全部记录
delete from person; commit; -
删除表结构
drop table person; commit; -
先删除表,再创建表。效果等同于删除表中全部记录
truncate table person; commit;注意:
在数据量大的情况下,尤其是在表中带有索引的情况下,该操作效率高。
索引可以提高查询效率,但是会影响增删改的效率。
Oracle 第二天
一、数据库的查询
1.1 scott用户下表的结构(了解)
system、sys、scott,其中system和sys的区别在与能否创建数据库,sys用户登录才可以创建数据库,而scott是给初学者学习的用户,学习者可以用Scott登录系统,注意scott用户登录后,就可以使用Oracle提供的数据库和数据表,这些都是oracle提供的,学习者不需要自己创建数据库和数据表,直接使用这些数据库和数据表练习SQL。
注意默认情况,scott用户是被锁住的,所以我们要先以sys用户登录,然后进行解锁,才可以哦
--scott用户,默认密码是tiger
--解锁scott用户(安装时若使用默认情况没有解锁和设置密码进行下列操作,要超级管理员(即dba权限)操作)
alter user scott account unlock;
--解锁scott用户的密码【此句也可以用来重置密码】
alter user scott identified by tiger;
切换到scott用户有四张表,如图1-1所示。

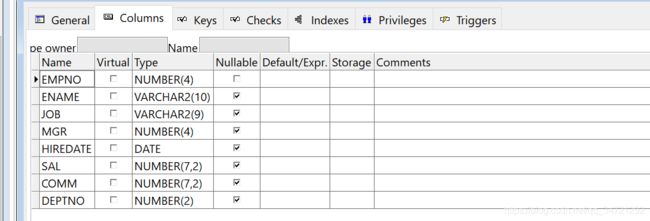
1.1.1 EMP表
字段分别是:员工编号、员工姓名、员工工作、员工直属领导编号、员工入职日期、员工工资、员工一年奖金、员工部门编号,其中DEPTNO是外键,与DEPT表的主键关联,如图1-2所示。
1.1.2 DEPT表
字段分别是:部门编号、部门名称、部门地址,如图1-3所示。

1.1.3 SALGRADE表
字段分别是:工资等级、最低工资、最高工资,如图1-4所示。

1.1.4 BONUS表
插入数据所使用的表,如图1-5所示。
注意:
以上四张表,我们主要使用前三张表来学习查询语句。
1.2 函数(应用)
函数分为系统内置函数 ,自定义函数;了解系统内置函数(方法),重点掌握 to_date,to_char (字符和日期的转换)
根据函数的返回结果,我们将函数分为单行函数和多行函数
-
单行函数 : 作用于一行,返回一个值。
-
多行函数 : 作用于多行,返回一个值。
1.2.1 单行函数
作用于一行,返回一个值。
1.2.1.1 常用的字符函数
- concat : 拼接两个字符串,相当于 ||
select concat('jiangqi','text') from dual;

-
initcap : 首字母大写
select initcap('jiangqi') from dual;
-
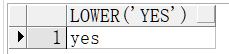
lower/upper :把字符转换成小/大写
select upper('yes') from dual; --如图1-8 select lower('YES') from dual; --如图1-9
-
instr :找出某个字符的位置
instr(‘源字符串’,‘目标字符串’ ,‘开始位置’, ‘第几次出现’)
- sourceString代表源字符串;
- destString代表要从源字符串中查找的子串;
- start代表查找的开始位置,这个参数可选的,默认为1;
- appearPosition代表想从源字符中查找出第几次出现的destString,这个参数也是可选的, 默认为1
- 如果start的值为负数,则代表从右往左进行查找,但是位置数据仍然从左向右计算
- 返回值为:查找到的字符串的位置。如果没有查找到,返回0。
select instr('jiangqi','i',1,1) from dual; --如图1-10 select instr('jiangqi','i',1,2) from dual; --如图1-11

-
length/ lengthb:字符串的长度 (返回以字符为单位的长度/返回以字节为单位的长度)
select length('jiangqi') from dual;--如图1-12 select length('江七') from dual;--如图1-13 select lengthb('jiangqi') from dual;--如图1-12 select lengthb('江七') from dual;--如图1-14

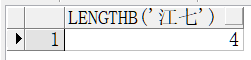
总结:当字符串是中文时,得到的值与length得到的值不同。
-
lpad/rpad:用指定的字符在左侧/右侧填充
select lpad('text', 6, '*') from dual; --如图1-15 select rpad('text', 6, '*') from dual; --如图1-16

-
ltrim/rtrim:把左边/右边的指定字符剪掉
-
基础用法
rtrim(string); --去除字符串右侧空格
ltrim(string); -去除字符串左侧空格
-
进阶用法
ltrim(x,y)/rtrim(x,y) 函数是按照y中的字符一个一个截掉x中的字符,并且是从左/ 右边开始执行的,只要遇到y中有的字符, x中的字符都会被截掉, 直到在x的字符中遇到y中没 有的字符为止函数命令才结束
select ltrim('10900094323','109') from dual; --如图1-17 select ltrim('abcdabababe','ab') from dual; --如图1-18 select rtrim('abcdabababe','be') from dual; --如图1-19 select rtrim('10900094323','23') from dual; --如图1-20



-
-
trim:剪掉左右两边的指定字符
-
普通用法
trim(string); --去除字符串首尾的空格
-
进阶用法
- trim(‘字符1’ from ‘字符串2’) 分别从字符串2的两边开始,删除指定的字符1。
- trim([leading | trailing | both] trim_char from string) 从字符串String中删除指定的字符trim_char。
- leading:从字符串的头开始删除。
- trailing:从字符串的尾部开始删除。
- borth:从字符串的两边删除。
select trim('a' from 'abcddcba') from dual; select trim(leading 'a' from 'abcddcba') from dual; select trim(trailing 'a' from 'abcddcba') from dual; select trim(both 'a' from 'abcddcba') from dual; -- 以上结果如图1-21所示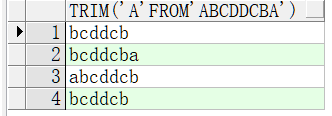
-
-
replace:替换字符
replace( char, search_string, [replace_string]) 如果没有指定replace_string 变量的值,那么当发现search_string 变量的值时,就将其删除。输入可以为任何字符数据类型——CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOB或NCLOB。
select replace('abcdab','cd','ef') from dual; --如图1-22 select replace('abcdab','cd') from dual; --如图1-23

-
substr:截取字符串
-
substr(string string, int a, int b);
- string 需要截取的字符串
- a 截取字符串的开始位置(注:当a等于0或1时,都是从第一位开始截取)
- b 要截取的字符串的长度
-
substr(string string, int a) ;
- string 需要截取的字符串
-
-
a 可以理解为从第a个字符开始截取后面所有的字符串。
select substr('HelloWorld',0,3) value from dual; select substr('HelloWorld',1,3) value from dual; select substr('Hello World',5,3) value from dual; select substr('HelloWorld',-1,3) value from dual; select substr('HelloWorld',-3,3) value from dual; select substr('HelloWorld',3) value from dual; --以上结果如图1-24所示

注意:
- 当a等于0或1时,都是从第一位开始截取(如1,2)
- 假如HelloWorld之间有空格,那么空格也将算在里面(如3)
- 只要 |a| ≤ b,取a的个数(如:4,5);当 |a| ≥ b时,才取b的个数,由a决定截取位置(如:5和1)
1.2.1.2 常用的数值函数
-
mod :求模
**mod(m,n),**其中m和n都是数字
该函数的的规则是:返回m/n的余数,如果 n 为 0,则返回 m
select mod(10, 3) mod from dual; select mod(10, 0) mod from dual; --以上结果如图1-25所示
-
round:四舍五入
round(number [,decimals]): number 待做截取处理的数值,decimals 指明需保留小数点后面的位数。可选项,忽略它则截去所有的小数部分,并四舍五入。如果为负数则表示从小数点开始左边的位数,相应整数数字用0填充,小数被去掉。需要注意的是,和trunc函数不同,对截取的数字要四舍五入。select round(1234.5678) round from dual; select round(1234.5678,1) round from dual; select round(1234.5678,-2) round from dual; select round(1234.5678,-4) round from dual; --以上结果如图1-26所示
-
trunc:截取数值
用于截取时间或者数值,返回指定的值。
-
日期处理:
**trunc(date [,fmt]):**date 为必要参数,是输入的一个date日期值,fmt 参数可忽略,是日期格式,缺省时表示指定日期的0点。
select trunc(to_date('2021-07-19 1:00:00','YYYY-MM-DD HH:MI:SS'),'yyyy') from dual ;--返回当年第一天 select trunc(to_date('2021-07-19 1:00:00','YYYY-MM-DD HH:MI:SS'),'mm') from dual ; --返回当月第一天 select trunc(to_date('2021-07-19 1:00:00','YYYY-MM-DD HH:MI:SS'),'dd') from dual ;--返回当前年月 select trunc(to_date('2021-07-19 1:00:00','YYYY-MM-DD HH:MI:SS'),'d') from dual ; --返回当前星期的第一天(星期日) select trunc(to_date('2021-07-19 1:12:12','YYYY-MM-DD HH:MI:SS'),'hh') from dual ;--返回当前日期截取到小时,分秒补0 select trunc(to_date('2021-07-19 1:12:12','YYYY-MM-DD HH:MI:SS'),'mi') from dual ;--返回当前日期截取到分,秒补0 --以上结果如图1-27所示。 -

**注意:此图为连接结果(union)**后的图(下图皆为如此)。
-
数值处理:
trunc(number [,decimals]) :number 为必要参数,是输入的一个number数值,decimals 参数可忽略,是要截取的位数,缺省时表示截掉小数点后边的值。
select trunc(122.555) from dual t; --默认取整 select trunc(122.555,2) from dual t; select trunc(122.555,-2) from dual t;--负数表示从小数点左边开始截取2位 --以上结果如图1-28所示。
-
ceil:向上取整
ceil(n) :取大于等于数值n的最小整数;
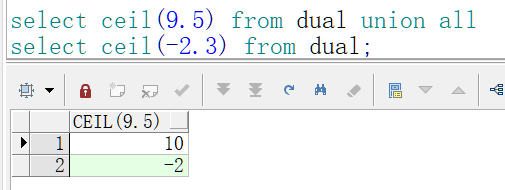
select ceil(9.5) from dual; select ceil(-2.3) from dual; -- 以上结果如图1-29所示。
-
floor:向下取整
floor(n) :取小于等于数值n的最大整数
select floor(9.5) from dual; select floor(-2.3) from dual;--以上结果如图1-30所示。

1.2.1.3 常用的日期函数
-
sysdate
用来得到系统的当前日期(如图1-31所示。)select sysdate from dual;
-
add_months
增加或减去月份select add_months(sysdate, 1) from dual; select add_months(sysdate, -1) from dual;--以上结果如图1-32所示。

-
last_day
返回日期的最后一天(如图1-33所示)
select last_day(sysdate) from dual;

-
months_between(date2,date1)
给出date2-date1的月份select months_between(to_date('2021-7-22','yyyy-mm-dd'), to_date('2020-7-22','yyyy-mm-dd')) months from dual union all select months_between(to_date('2020-7-22','yyyy-mm-dd'), to_date('2021-7-22','yyyy-mm-dd')) months from dual union all select months_between(to_date('2021-7-25','yyyy-mm-dd'), to_date('2020-7-22','yyyy-mm-dd')) months from dual union all select months_between(to_date('2020-7-25','yyyy-mm-dd'), to_date('2021-7-22','yyyy-mm-dd')) months from dual;--以上结果如图1-34所示。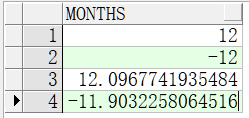
注意:
- 参数的格式需要统一
- 两个参数表示的日期不是同一天,所以返回带小数的值
例子:
-- 查询出 emp 表中所有员工入职距离现在几天 select sysdate-e.hiredate from emp e; -- 算出明天时刻 select sysdate+1 from dual; -- 查询出 emp 表中 所有员工入职距离现在几月 select months_between(sysdate,e.hiredate) from emp e; -- 查询出 emp 表中 所有员工入职距离现在几年 select months_between(sysdate,e.hiredate)/12 from emp e; -- 查询出 emp 表中 所有员工入职距离现在几周 select round((sysdate-e.hiredate)/7) from emp e;
1.2.1.4 常用的转换函数
-
to_char(date,‘format’)
把对应的数据转换为字符串类型select to_char(sysdate, 'yyyy-mm-dd hh:mi:ss') from dual; select to_char(sysdate, 'yyyy-mm-dd hh24:mi:ss') from dual; select to_char(sysdate, 'fm yyyy-mm-dd hh24:mi:ss') from dual; select to_char(122323.45, '$99999999.99') from dual; --以上对比结果如图1-35所示。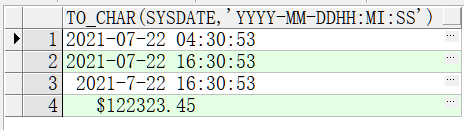
-- Q 季度,1~3月为第一季度 select to_char(sysdate, 'q') from dual;-- 3 表示第三季度 -- MM 月份数 select to_char(sysdate, 'mm') from dual;--07表示7月 -- RM 月份的罗马表示 select to_char(sysdate, 'rm') from dual;--vii表示7月 -- Month 用9个字符长度表示的月份名 select to_char(sysdate, 'month') from dual;-- 7月 -- WW 当年第几周 select to_char(sysdate, 'ww') from dual;-- 29表示2021年7月22日为第29周 -- W 本月第几周 select to_char(sysdate, 'w') from dual;-- 2021年7月22日为为第4周 -- DDD 当年第几天. 1月1日为001,2月1日为032 select to_char(sysdate, 'ddd') from dual; -- DD 当月第几天 select to_char(sysdate, 'dd') from dual; -- D 周内第几天 select to_char(sysdate, 'd') from dual;-- 5 表示第五天(从星期天开始算) -- DY 周内第几天缩写 select to_char(sysdate, 'dy') from dual;-- 星期四 -- HH或HH12 12进制小时数 select to_char(sysdate, 'hh') from dual; -- HH24 24小时制 select to_char(sysdate, 'hh24') from dual; -- MI 分钟数(0~59) select to_char(sysdate, 'mi') from dual; -- 提示注意不要将MM格式用于分钟(分钟应该使用MI)。MM是用于月份的格式,将它用于分钟也能工作,但结果是错误的。 -- SS 秒数(0~59) select to_char(sysdate, 'ss') from dual; -
to_date(string,‘format’)
将字符串转化为Oracle中的一个日期select to_date('2011-03-24', 'yyyy/mm/dd') from dual; select to_date(' 2021-7-22 16:35:10', 'fm yyyy-mm-dd hh24:mi:ss')from dual; --以上结果如图1-36所示。
-
to_number(char)
将给出的字符转换为数字
select to_number('2021') as Year from dual
1.2.1.5 通用函数
-
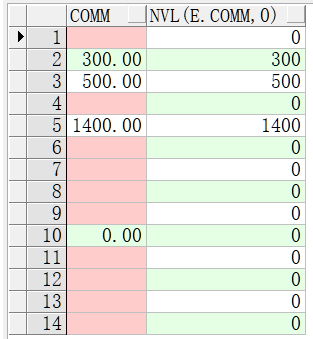
nvl(exp1,exp2)
如果oracle第一个参数为空那么显示第二个参数的值,如果第一个参数的值不为空,则显示第一个参数本来的值。
select nvl(e.comm,0) from emp e;
-
nullif(exp1,exp2)
如果表达式 exp1 与 exp2 的值相等则返回 null,否则,返回 exp1 的值
select e.comm,nullif(e.comm,300) from emp e;
-
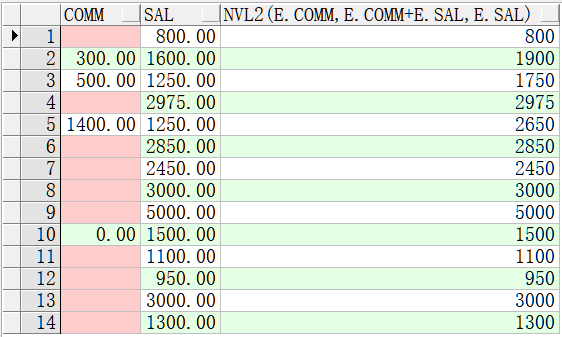
nvl2(e1, e2, e3)
如果e1为NULL,则函数返回e3 ,若e1不为null,则返回e2。
select e.comm,e.sal,nvl2(e.comm,e.comm+e.sal,e.sal) from emp e;
-
coalesce()
依次考察各参数表达式,遇到非 null 值即停止并返回该值。
此表达式的功能为返回第一个不为空的表达式,如果都为空则返回空值。注意:所有表达式必须为同一类型或者能转换成同一类型。
select empno, ename, sal, comm, coalesce(sal+comm, sal, 0)总收入 from emp;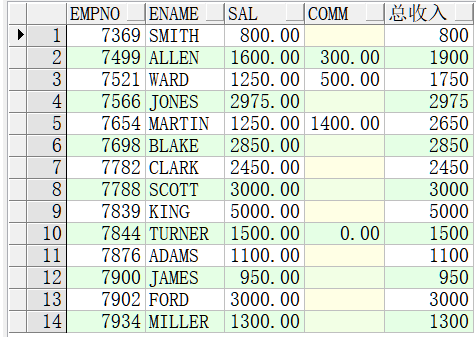
1.2.1.6 条件表达式
-
case when**(条件表达式的通用写法,mysql和oracle通用)**
case when用于SQL语句中的条件判断
-
case when 在Oracle 中的用法:
(a)已case开头,已end 结尾;
(b)分支中when后跟条件,then 显示结果;
(c)else 为除此之外的默认情况,类似于高级语言程序中的 switc case 的default可以不加;
(d)end后面跟别名;
-
case 有两种表达式:
(A)简单case表达式试用表达式确定返回值
-- 简单Case函数 -- 给 emp 员工起个中文名字 select e.ename, case e.ename when 'SMITH' then '史密斯' when 'ALLEN' then '艾伦' else '无名' end "中文名" from emp e; -- 结果如图1-41所示。
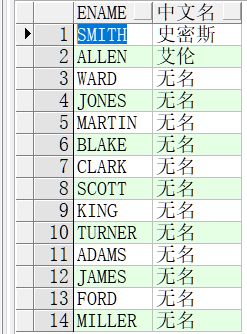
(B)搜索case表达式,使用条件确定返回值;
-- Case搜索函数 -- 判断表中员工工资,如果高于3000为高收入, -- 高于1500低于3000为中收入,其余显示低收入 select e.sal, case when e.sal>3000 then '高收入' when e.sal>1500 then '中收入' else '低收入' end "收入等级" from emp e; -- 结果如图1-42所示。
-
-
decode (oracle 专用条件表达式)
-
decode判断字符串是否一样
语法:
decode(value,if1,then1,if2,then2,if3,then3,...,else)含义为
if 条件=值1 then
return(value 1)
else if 条件=值2 then
return(value 2)
…
else if 条件=值n then
return(value 3)
else
return(default)
end
select e.ename, decode( e.ename, 'SMITH', '史密斯', 'ALLEN','艾伦', '无名') "中文名" from emp e; -- 结果如图1-41所示。decode相当于:case when then else end语句 -
decode判断大小
select decode(sign(var1-var2),-1,var1,var2) from dual;sign()函数根据某个值是0、正数还是负数,分别返回0、1、-1
select decode(sign(100-90),-1,100,90) from dual; select decode(sign(100-90),0,100,90) from dual; select decode(sign(100-90),1,100,90) from dual; -- 以上结果如图1-43所示。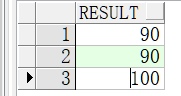
-
使用decode函数分段
-- 判断表中员工工资,如果高于3000为高收入, -- 高于1500低于3000为中收入,其余显示低收入 select e.sal, decode(sign(e.sal-3000), 1,'高收入', 0,'高收入', -1,decode(sign(e.sal-1500), 1,'中收入', 0,'中收入', -1,'低收入' )) "收入等级" from emp e; -- 结果如图1-42所示。
-
1.2.2 多行函数
多行函数又叫聚合函数,也叫组函数,作用于多行,返回一个值。
聚合函数的特性: 可以把多行记录变成一个值。
聚合函数有 : count、sum、max/min、avg
--求员工的工资总和
select sum(sal) from emp;
--求个数(统计数量)
select count(*) from emp;
--求平均工资
select sum(sal)/count(*) 方式一, avg(sal) 方式二 from emp;
--关于空值:聚合函数会自动滤空
select count(*), count(comm) from emp;
--max和min:求最高工资和最低工资
select max(sal) 最高工资,min(sal) 最低工资 from emp;
1.3 group by(应用)
分组查询中,出现在group by后面的原始列,才能出现在select后面,没有出现在group by后面的列,想在select后面,必须加上聚合函数。
-
求各个部门的平均工资
select e.deptno,avg(e.sal) from emp e group by e.deptno; -
求每个部门的平均工资大于2000的部门
select deptno,avg(sal) from emp group by deptno having avg(sal)>2000; -
求每个部门的工资高于800的员工的平均工资并且按照部门编号从小到大排列
select e.deptno,avg(e.sal) from emp e where e.sal>800 group by e.deptno order by e.deptno; -- 默认从小到大排列,从大到小排列使用关键词 desc 在后面 -
求每个部门的工资高于800的员工的平均工资然后再查询平均工资大于2000的部门
select e.deptno,avg(e.sal) from emp e where e.sal>800 group by e.deptno having avg(e.sal)>2000;注意:
(A) where是过滤分组前的数据,having是过滤分组后的数据
(B) 表现形式:where 必须在 group by 之前,having 是在 group by 之后
-
按部门,不同的工种,统计平均工资
select deptno,job,avg(sal) from emp group by deptno,job;注意:
group by作用于多列:先按照第一列分组;如果相同,再按照第二列分组
1.4 SQL语句执行顺序
select查询语句执行顺序:
-
from 子句第一个执行。
-
where子句, 通过过滤条件排除不满足条件的记录
-
group by 子句, 对where过滤后的记录(满足条件的记录进行分组)
-
having 子句, 对分组后的记录进行过滤(分组条件)
-
select子句, 用过滤后的记录生产查询列表
-
order by 子句, 对所有生成的记录进行排序
1.5 多表查询(应用)
从多个表中获取相应的数据。
-
笛卡尔积
连接条件无效或被省略,两个表的所有行都发生连接,所有行的组合都会返回(n*m)。
select * from emp e,dept d;
-
等值连接(内连接或简单连接)
两个表的连接条件的列值必须相等,通常这样的连接包含一个主键和一个外键。
-- 等值连接 select * from emp e,dept de where e.deptno= de.deptno; --内连接 select * from emp e inner join dept de on e.deptno= de.deptno;
-
外连接
外部连接不只列出与连接条件向匹配的行,而是列出左表(左外连接时)、右表(右外连接时)或两个表(全外连接时(笛卡尔积))中所有符合搜索条件的数据行。
-
左外连接
查询出所有部门,以及部门下的员工信息
-- 通用左外连接 select * from emp e left join dept de on e.deptno= de.deptno; -- Oracle 专用左外连接 select * from emp e ,dept de where e.deptno = de.deptno (+);
-
右外连接
查询所有员工信息,以及员工所属部门
-- 通用右外连接 select * from emp e right join dept de on e.deptno= de.deptno; --Oracle 专用右外连接 select * from emp e ,dept de where e.deptno (+) = de.deptno ;
注意:
dept表为不缺乏连接信息的表,emp表为缺乏连接信息的表
外部连接运算符(+)放在缺少相关连接信息的表的一侧,它能返回该表中那些在另一个表中没有得到匹配的记录。
-
-
自连接
站在不同的角度把一张表看成多张表,并起多个别名,然后再根据要求进行连接。
-
查询出员工姓名,员工领导姓名
select e1.ename,e2.ename from emp e1 ,emp e2 where e1.mgr = e2.empno; -
查询出员工姓名,员工部门名称,员工领导姓名,员工领导部门名称
select e1.ename,d1.dname,e2.ename,d2.dname from emp e1 ,emp e2,dept d1,dept d2 where e1.mgr = e2.empno and e1.deptno=d1.deptno and e2.deptno=d2.deptno;
-
1.6 子查询
在SQL语言中,由select-from-where组成的语句称为查询块。当需要获得一个未知的但又在数据库中存在的值时,将一个查询块嵌套在另一个查询块的where子句的条件中的查询块称为子查询。子查询中还可以嵌套子查询。子查询的结果可以是一个值也可以是多个值。
子查询 (内查询) 在主查询之前一次执行完成。
子查询的结果被主查询(外查询)使用。
-
查询出工资大于SCOTT的员工姓名
select ename from emp where sal > (select sal from emp where ename='SCOTT');注意:
a. 子查询要包含在括号内,将子查询放在比较条件的右侧。
b. 单行操作符对应单行子查询,多行操作符对应多行子查询。
-
单行子查询
单行子查询,只返回一行,使用单行比较符(>, = ,<, >= ,<= ,!=, <>)
--子查询中使用聚合函数 select ename,sal from emp where sal=(select min(sal) from emp); --子查询中的having子句 --首先执行子查询 --向主查询中的having子句返回结果 select deptno, min(sal) from emp group by deptno having min(sal) > (select min(sal) from emp); -
多行子查询
多行子查询,返回多行,使用多行比较符(IN, ANY ,ALL)
-
返回一个集合
--查询出工资比部门10里任意一个人工资高的员工信息 select * from emp where sal > any (select sal from emp where deptno = 10); --查询出工资和部门10里任意一样的员工信息 select * from emp where sal in (select sal from emp where deptno = 10); --查询不是老板的员工信息 select * from emp where empno not in(select mgr from emp); -
返回一个表
-- 查询出每个部门最低工资,和最低工资员工姓名,和该员工所在部门名称 -- 1,先查询出每个部门最低工资 select deptno,min(sal) msal from emp group by deptno -- 2,三表联查,得到最终结果 select t.deptno,t.msal,e.ename,d.dname from (select deptno,min(sal) msal from emp group by deptno) t,emp e,dept d where t.deptno=e.deptno and t.msal =e.sal and e.deptno=d.deptno;
-
1.7 分页查询
rownum行号:当我们做select操作的时候,每查询出一行记录,就会在该行上加上一个行号,行号从1开始,依次递增,不能跳着走。
-
emp表工资倒叙排列后,每页五条记录,查询第二页。
select rownum,e.* from emp e order by e.sal desc
注意:排序操作会影响rownum的顺序,故如果涉及到排序,但是还要使用rownum的话,我们可以再次嵌套查询来消除影响。
select rownum ,t.* from ( select rownum,e.* from emp e order by e.sal desc) t;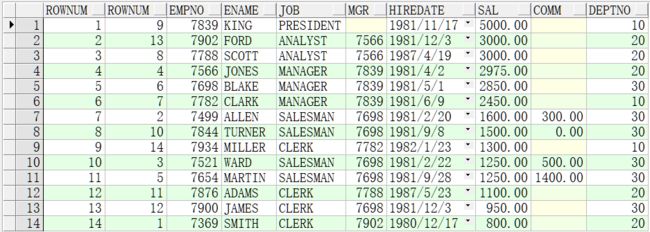
select rownum ,e.* from ( select rownum,e.* from emp e order by e.sal desc) e where rownum < 11 and rownum >5;
由图可得出:rownum 行号不能写上大于一个正数。
最后正确结果为:(也是分页查询的固定模板,其中数字为参数传进去的)
--emp表工资倒叙排列后,每页五条记录,查询第二页。 select * from( select rownum rn ,e.* from ( select rownum,e.* from emp e order by e.sal desc) e where rownum < 11) where rn > 5;
二、Oracle 对象
2.1 视图
2.1.1 视图的概念
视图是一个虚拟表,视图并不在数据库中存储数据值,数据库中只在数据字典中存储对视图的定义。
视图是从一个或多个实际表中获得的,这些表的数据存放在数据库中。那些用于产生视图的表叫做该视图的基表。一个视图也可以从另一个视图中产生。
总结:
视图就是提供一个查询的窗口,所有数据来源于原表。
2.1.2 视图的创建
创建视图必须有 dba 权限
- 语法:
create [or replace] [{force|noforce}] view view_name
as
select 查询
[with read only]
- 语法解析:
**or replace :**如果视图已经存在,则替换旧视图。
**force :**即使基表不存在,也可以创建该视图,但是该视图不能正常使用,当基表创建成功后,视图才能正常使用。
**noforce :**如果基表不存在,无法创建视图,该项是默认选项。
**with read only :**默认可以通过视图对基表执行增删改操作,但是有很多在基表上的限制(比如:基表中某列不能为空,但是该列没有出现在视图中,则不能通过视图执行insert操作),with read only说明视图是只读视图,不能通过该视图进行增删改操作。现实开发中,基本上不通过视图对表中的数据进行增删改操作。
-
代码演示
-- 查询语句创建表 create table emp as select * from scott.emp; select * from emp; -- 创建视图【必须要有 dba 权限】 create view v_emp as select ename,job from emp; -- 修改视图【不推荐】 视图里改变数据改的还是原表的数据 update v_emp set job='CLERK' where ename='ALLEN'; commit; -- 创建只读视图 create view v_emp1 as select ename,job from emp with read only;注意:修改视图不推荐使用,因为视图里改变数据改变的是原表中的数据。
2.1.3 视图的作用
- 视图可以屏蔽一些敏感字段;
- 保证总部和分部数据即使统一(因为分部用视图没数据,都是从总部中即时查询)。
2.2 索引(了解)
2.2.1 索引的概念
1)索引是数据库对象之一,用于加快数据的检索,类似于书籍的索引。在数据库中索引可以减少数据库程序查询结果时需要读取的数据量,类似于在书籍中我们利用索引可以不用翻阅整本书即可找到想要的信息。
2)索引是建立在表上的可选对象;索引的关键在于通过一组排序后的索引键来取代默认的全表扫描检索方式,从而提高检索效率
3)索引在逻辑上和物理上都与相关的表和数据无关,当创建或者删除一个索引时,不会影响基本的表;
4)索引一旦建立,在表上进行DML操作时(例如在执行插入、修改或者删除相关操作时),oracle会自动管理索引,索引删除,不会对表产生影响
5)索引对用户是透明的,无论表上是否有索引,sql语句的用法不变
6)oracle创建主键时会自动在该列上创建索引
总结:
- 索引就是在表的列上构建一个二叉树。
- 会大幅度提高查询效率的目的,但是索引会影响增删改的效率
2.2.2 索引的分类(简单介绍)
-
单列索引
create index idx_ename on emp(ename);注意
- 单列索引触发规则 : 条件必须是索引列中的原始值;
- 单行函数,模糊查询,都会影响索引的触发。
select * from emp where ename='SCOTT'; -
复合索引(基于多个列创建)
create index idx_enamejob on emp(ename,job);注意:
- 复合索引中定义列为优先检索列;
- 如果要触发复合索引,必须包含有优先检索列中的原始值。
select * from emp where ename='SCOTT' and job='xx'; -- 触发复合索引 select * from emp where ename='SCOTT' or job='xx'; -- 不触发索引 select * from emp where ename='SCOTT'; -- 触发单列索引
三、Oracle编程
3.1 PL/SQL 编程语言
3.1.1 PL/SQL的特性(了解)
pl/sql编程语言是对sql语言的扩展,使得sql语言具有过程化编程的特性;
pl/sql编程语言比一般的过程化编程语言,更加灵活高效;
pl/sql编程语言主要用来编写存储过程和存储函数等。
3.1.2 PL/SQL的声明方法(掌握)
-- 声明方法
declare
i number(2) :=10;
s varchar2(10) :='小明';
ena emp.ename%type; -- 定义emp中ename属性的类型(引用型变量)
emprow emp%rowtype; -- 记录型变量
begin
dbms_output.put_line(i);-- 输出语句
dbms_output.put_line(s);
select ename into ena from emp where empno=7788; -- select赋值给ena(into)
dbms_output.put_line(ena);
select * into emprow from emp where empno=7788;
dbms_output.put_line(emprow.ename || '的工作为'||emprow.job);
end;
注意:
- 赋值操作可以使用 :=,也可以使用into查询语句赋值。
- type : 为了使一个变量的数据类型与另一个已经定义了的变量(尤其是表的某一列)的数据类型相一致。
- rowtype : 为了使一个变量的数据类型与一个表中记录的各个列的数据类型相对应、一致;一行记录可以保存从一个表或游标中查询到的整个数据行的各列数据。一行记录的各个列与表中一行的各个列有相同的名称和数据类型。
- 在使用由 %rowtype 定义的变量时要用“ . ”运算符指定记录变量名限定词,用“||”来划分字段。
- 最后end后面的 “ ; ”不能丢
3.1.3 PL/SQL的if 判断(应用)
-- pl/ sql 中的if判晰
-- 输入小于18的数字,输出未成年
-- 输入大于18小于40的数字,输出中年人
-- 输入大于40的数字,输出老年人
declare
i number(3) :=ⅈ -- & 代表输入;后面变量随便写
begin
if i<18 then
dbms_output.put_line('未成年');
elsif i<40 then
dbms_output.put_line('中年人');
else
dbms_output.put_line('老年人');
end if; -- end if 作为 if 结束标志
end;
注意:
- 在变量后赋值时,& 代表输入,后面变量随便写
- 结束if语句判断时,用
end if结束 if
3.1.4 PL/SQL的循环(应用)
用三种方式输出1到10 的数字
3.1.4.1 while 循环(条件成立时执行)
declare
i number(2) :=1;
begin
while i<11
loop
dbms_output.put_line(i);
i:=i+1;
end loop;
end;
注意:
- 只要while循环条件的求值结果是true,循环就会继续下去,如果求值条件为false或者null,循环就会终止。这个循环条件每执行一次循环体(loop)之前都会先进行判断,因此while循环并不能保证循环体一定能被执行。
- 如果我们无法提前预知所需要巡检的次数的情况下,就可以使用While来进行循环处理。
3.1.4.2 exit 循环(条件成立时退出)(应用)
-- exit循环
declare
i number(2) :=1;
begin
loop
exit when i>10;
dbms_output.put_line(i);
i:=i+1;
end loop;
end;
注意:
使用PL/SQL退出循环时,必须遵循以下步骤。
- 在循环体之前初始化变量
- 在循环中改变变量(即增加或者减少)。
- 使用 exit when语句退出循环。否则,不带when条件的exit语句,循环中的语句仅执行一次。
3.1.4.3 for 循环(应用)
declare
begin
for i in 1..10
loop
dbms_output.put_line(i);
end loop;
end;
注意:
- 1…10表示连续区间
- 如果在开始的时候就已经知道循环的次数的情况下,就可以使用for来进行循环处理
- 注意这里不需要声明循环索引,因为PL/SQL会自动隐式的用一个integer类型的局部变量作为它的循环索引;
- 该循环默认是升序循环,如果要降序循环,必须在
in后加上reverse关键字,并且循环上边界和下边界的顺序无需改变 - 数值型for循环中,索引总是以1为单位递增或递减
3.1.5 PL/SQL的游标(应用)
-
概念
游标:指向查询结果集的指针,指向哪一行,提取哪一行的数据(PLSQL的游标默认指向结果集的第一行)
显示游标的四个属性:
- 游标变量 %found:当最近一次读入记录成功时返回true
- 游标变量 %notfound:同上 相反
- 游标变量 %isopen:判断游标是否已经打开
- 游标变量 %rowcount:返回已从游标中读取的记录数
隐式游标:固定名称sql
隐式游标的四个属性- SQL%found:如果操作有影响行,就为true,否则为false
- SQL%notfound:求反
- SQL%isopen:在隐示游标中,取值永远为false
- SQL%rowcount:操作影响的行数
必须在事务结束之前读取游标属性,而且只能读取最近的一次DML(数据操作语言)操作的游标状态
-
使用步骤
使用游标分为4个步骤
- 声明游标: cursor 游标变量 is 查询语句
- 打开游标 :open 游标变量(不能重复打开游标)
- 提取数据: fetch 游标变量 into 变量1,变量2
- 关闭游标释放系统资源: close 游标变量
-
案例分析
-
输出emp 表中所有员工的姓名
declare cursor c1 is select * from emp; emprow emp%rowtype; begin open c1; loop fetch c1 into emprow; exit when c1%notfound; dbms_output.put_line(emprow.ename); end loop; close c1; end; -
给指定部门员工涨工资
declare cursor c2(eno emp.deptno%type) is select empno from emp where deptno=eno; en emp.empno%type; begin open c2(10); loop fetch c2 into en; exit when c2%notfound; update emp set sal=sal+100 where empno=en; commit; end loop; end;注意:
- cursor cursor_name [(param1,parame2…)] is select…
//后面接的是一个查询语句,一般都是返回多行的那种。其中参数param可带可不带,根据需要,参数的定义也要定义参数名,参数类型等(这里特别要注意的是在指定参数类型的时候不需要指定类型大小 如number(20),这都是错的) - 在指定参数后,若要打开游标时,必须要在且仅在打开时进行赋值,如
open c2(10);
- cursor cursor_name [(param1,parame2…)] is select…
-
3.2 存储过程(理解)
- 概念
存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是数据库中的一个重要对象,任何一个设计良好的数据库应用程序都应该用到存储过程。
简单来说:存储过程就是提前已经编译好的一段pl/sql 语言,放置在数据库端可以直接调用。这一段pl/sql 一般都是固定步骤的业务。
-
创建存储过程的语法
create [or replace] procedure 过程名[(参数名in/out数据类型)] as 变量1 类型(值范围); 变量2 类型(值范围); begin PLSQL子程序体; end; 或者 create [or replace] procedure 过程名[(参数名in/out数据类型)] is 变量1 类型(值范围); 变量2 类型(值范围); begin PLSQL子程序体; end; -
案例分析
-
不带参数的
-- 打印“hello world” create or replace procedure p_hello is --如果需要,在此处声明变量 begin dbms_output.put_line('hello world'); end p_hello; -- 上面代码执行后,再执行下面测试代码 --测试 begin -- Call the procedure p_hello; end; --如图3-1所示。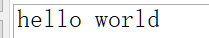
-
带输入参数的
--查询并打印某个员工的姓名,薪水,要求调用时传入员工编号,控制台自动打印 create or replace procedure p_empInfo(i_empno IN emp.empno%TYPE) as -- 声明变量 v_ename emp.ename%TYPE; v_sal emp.sal%TYPE; begin select ename, sal into v_ename, v_sal from emp where empno = i_empno; dbms_output.put_line('员工编号:' || i_empno || ',姓名:' || v_ename || ',薪水:' || v_sal); end p_empInfo; -- 上面代码执行后,再执行下面测试代码 -- 测试,调用带入参存储过程 begin -- Call the procedure p_empInfo(7788); p_empInfo(7902); end; --如图3-2所示。
-
带输入输出参数(返回值)的
--输入员工号查询某个员工(7788)信息,要求将年薪作为返回值输出,给调用的程序使用 create or replace procedure p_empInfo2(eno in emp.empno%TYPE, year_sal out number) as s number(10); pcomm emp.comm%type; begin select sal*12 ,nvl(comm,0) into s,pcomm from emp where empno = eno; year_sal :=s+pcomm; end; -- 上面代码执行后,再执行下面测试代码 --测试,测试窗口中调用该存储过程,需要事先定义一个变量作为 存储过程返回值的接收参数,在打印语句中打印该参数的值, declare yearsal number(10); begin p_empInfo2(7788,yearsal); dbms_output.put_line(yearsal); end;
-
注意:
- 存储过程参数不带取值范围,in表示传入,out表示输出;
- 变量带取值范围,后面接分号;
- 用
select … into …给变量赋值; - 凡是涉及到
into查询语句赋值或者:=赋值操作的参数,都必须使用out来修饰。
3.3 存储函数(理解)
函数(function)为一命名的存储程序,可带参数,并返回一计算值。函数和过程的结构类似,但必须有一个return子句,用于返回函数值。函数说明要指定函数名、结果值的类型,以及参数类型等。
-
语法
create or replace function 函数名(Name in type, Name in type,.) return 数据类型 is/as 结果变量 数据类型; begin return(结果变量); end 函数名;注意:
- 存储函数参数也不带取值范围;
- end 后面可写可不写
-
存储过程和存储函数的区别
- 一般来讲,过程和函数的区别在于函数可以有一个返回值;而过程没有返回值。
- 但过程和函数都可以通过out指定一个或多个输出参数。我们可以利用out参数,在过程和函数中实现返回多个值。
-
案例分析
--查询某个员工的年收入 create or replace function queryempincome(eno in number) return number as --月薪和奖金 psal emp.sal%type; pcomm emp.comm%type; begin select sal,comm into psal,pcomm from emp where empno=eno; --返回年收入 return psal*12+nvl(pcomm,0); end; -- 上面代码执行后,再执行下面测试代码 --测试 -- 存储函数再调用的时候,返回值需要接收 declare s number(10); begin s:=queryempincome(7788); dbms_output.put_line(s); end;注意: 存储函数在调用的时候,返回值必须需要接收,否则执行错误。
3.4 存储过程和存储函数的区别
-
语法区别:
- 关键字不一样
- 存储函数比存储过程多了两个return.
-
本质区别:存储函数有返回值,而存储过程没有返回值。
- 如果存储过程想实现有返回值的业务,我们就必须使用out类型的参数
- 即便是存储过程使用了out类型的参数,起本质也不是真的有了返回值,而是在存储过程内部给out类型参数赋值,在执行完毕后,我们直接拿到输出类型参数的值。
-
本质区别表现形式案例
我们可以使用存储函数有返回值的特性,用来自定义函数。而存储过程不能用来自定义函数。
案例需求:查询出员工姓名,员工所在部门名称。
-- 案例准备工作:把scott用户下的dept表复制到当前用户下 create table dept as select * from scott.dept; -- 使用传统方式来实现案例需求 select e.ename,d.dname from emp e,dept d where e.deptno=d.deptno; -- 使用存储函数来实现提供一个部门编号,输出一个部门名称 create or replace function fdna(dno dept.deptno%type) return dept.dname%type is dna dept.dname%type; begin select dname into dna from dept where deptno=dno; return dna; end; -- 使用 fdna 存储函数来实现案例需求:查询出员工姓名,员工所在部门名称。 select e.ename,fdna(e.deptno) from emp e;注意:上述过程,存储过程不能来做,因为存储过程没有返回值
3.5 触发器
3.5.1 概念
触发器,就是制定一个规则,在我们做增删改操作的时候,只要满足该规则,自动触发,无需调用。|
-
触发器事件:insert, update, insert
-
触发时间: after, before
-
触发参数: :old 和 :new
- delete 只有:old
- insert 只有:new
- update 同时存在:old 和:new
触发语句 :old :new insert 所有字段都是空的(null) 将要插入的数据 update 更新以前该行的值 更新后的值 delete 删除以前该行的值 所有字段都是空的(null) -
触发层级:行级触发器,语句级触发器
- 行级触发器是加入了
for each row - 语句级触发器不需要
for each row
注意:加
for each row是为了使用:old或者:new对象或者一行记录。 - 行级触发器是加入了
-
其他
- 触发器是不能使用rollback
- 触发器抛出异常:
raise_application_error('-20000','错误提示信息');
异常值范围: -20999到-20000
3.5.2 语句级触发器
案例:插入一条记录,输出一个新员工入职
create or replace trigger t1
after
insert
on person
declare
begin
dbms_output.put_line('一个新员工入职');
end;
-- 触发t1
insert into person values(1,'小红');
commit; -- 如图3-3所示。

3.5.3 行级别触发器
案例一:不能给员工降薪
create or replace trigger t2
before
update
on emp
for each row
declare
begin
if :old.sal>:new.sal then
raise_application_error(-20001,'不能给员工降薪');
end if;
end;
-- 触发t2
update emp set sal=sal-1 where empno=7788;
commit; -- 如图3-4所示。

案例二:触发器实现主键自增
分析:在用户做插入操作之前,拿到即将插入的数据,给该数据中的主键列赋值
create or replace trigger auid
before
insert
on person
for each row
declare
begin
select s_person.nextval into :new.pid from dual;
end;
-- 查询person表数据
select * from person; -- 如图3-5所示。
-- 使用auid 实现主键自增
insert into person(pname) values('a');
commit; -- 连续执行四次
select * from person; -- 如图3-6所示。
insert into person values(1,'b');
commit; -- 连续执行两次
select * from person; -- 如图3-7所示。



总结: insert into person values(1,'b'); 不论序号是什么数字,其pid都是按照序列的顺序依次递增1。
四、java 调用存储过程
4.1 环境准备
我的Oracle版本是11g ,故需要oracle6_g.jar。
-
创建maven工程
-
导入jar包
<dependencies> <dependency> <groupId>com.oracle.database.jdbc.debuggroupId> <artifactId>ojdbc6_gartifactId> <version>11.2.0.4version> <scope>runtimescope> dependency> <dependency> <groupId>junitgroupId> <artifactId>junitartifactId> <version>4.13.1version> <scope>testscope> dependency> dependencies>
4.2 环境测试
public class OracleDemo {
@Test
public void javaCallOracle() throws Exception {
// 加载驱动
Class.forName("oracle.jdbc.driver.OracleDriver");
//得到Connection连接
Connection connection= DriverManager.getConnection("jdbc:oracle:thin:localhost:orcl","jiangqi","jiangqi");
// 得到预编译的Statement对象
PreparedStatement pstm = connection.prepareStatement("select * from emp where empno=?");
//给参数赋值,查询7788员工的信息
pstm.setObject(1,7788);
//执行数据库查询操作
ResultSet resultSet = pstm.executeQuery();
//输出结果
while (resultSet.next()){
// 输出7788员工姓名信息
System.out.println(resultSet.getString("ename"));
}
//释放资源
resultSet.close();
pstm.close();
connection.close();
}
}
4.3 调用存储过程/函数
CallableStatement:用于执行_SL存储过程的接口。
JDBC API 提供了一个存储过程SQL转义语法,该语法允许对所有RDBMS使用标准方式调用存储过程。
此转义语法有一个包含结果参数的形式和一个不包含结果参数的形式。
如果使用结果参数,则必须将其注册为OUT参数。其他参数可用于输入、输出或同时用于二者。
参数是根据编号按顺序引用的,第一个参数的编号是1。
4.3.1 调用存储过程
{call 调用存储过程使用
/**
* @Description: 调用存储过程
* @Author: 江七
* @Date: 2021/7/26 17:39
* @return: void
**/
@Test
public void javaCallProcedure() throws Exception {
// 加载驱动
Class.forName("oracle.jdbc.driver.OracleDriver");
//得到Connection连接
Connection connection= DriverManager.getConnection("jdbc:oracle:thin:localhost:orcl","jiangqi","jiangqi");
// 得到预编译的Statement对象
CallableStatement pstm = connection.prepareCall("{call p_empInfo2(?,?)}");
//给参数赋值
pstm.setObject(1,7788);
pstm.registerOutParameter(2, OracleTypes.NUMBER);
//执行数据库查询操作
pstm.execute();
//输出结果[第二个参数]
System.out.println(pstm.getObject(2));
//释放资源
pstm.close();
connection.close();
}
4.3.2 调用存储函数
{?=call} 调用存储函数使用
/**
* @Description: 调用存储函数
* @Author: 江七
* @Date: 2021/7/26 17:49
* @return: void
**/
@Test
public void javaCallFunction() throws Exception {
// 加载驱动
Class.forName("oracle.jdbc.driver.OracleDriver");
//得到Connection连接
Connection connection= DriverManager.getConnection("jdbc:oracle:thin:localhost:orcl","jiangqi","jiangqi");
// 得到预编译的Statement对象
CallableStatement pstm = connection.prepareCall("{?=call queryempincome(?)}");
//给参数赋值
pstm.setObject(2,7788);
pstm.registerOutParameter(1, OracleTypes.NUMBER);
//执行数据库查询操作
pstm.execute();
//输出结果[第一个参数],第一个参数是返回值
System.out.println(pstm.getObject(1));
//释放资源
pstm.close();
connection.close();
}