Hadoop学习笔记
文章目录
前言
这是关于Hadoop的学习笔记,仅供个人使用
-----2022.8.12
当前企业数据分析方向:
1.现状分析(分析当下的数据):现阶段的整体情况,各个部分的构成占比,发展,变动
2.原因分析(分析过去的数据):某一现状为什么发生,确定原因,做出调整优化
3.预测分析(结合数据预测未来):结合已有数据预测未来发展趋势
1.原因分析:离线分析(Batch Processing):
面向过去,面向历史,分析已有的数据
在时间维度明显呈批次性变化,一周一分析(T+7),一天一分析(T+1),所以也叫作批处理
2.现状分析:实时分析(real time processing|streaming): 别名是流式处理
面向当下,分析实时产生的数据
所谓的实时是指从数据产生到数据分析到数据应用的时间间隔很短,可细分秒级,毫秒级
实时和离线的主要区别就是数据产生和分析之间的间隔时间
3.机器学习(machine learning):
基于历史数据和当下产生的实时数据预测未来发生的事情
侧重于数学算法的运用,如分类,聚类,关联,预测
数据分析基本流程步骤:
数据分析步骤(流程)的重要性体现在:对如何开展数据分析提供了强有力的逻辑支撑
典型的数据分析应该包含以下几个步骤:

step1:明确分析目的和思路:
目的是整个分析流程的起点,为数据的收集,处理及分析提供清晰的指引方向
思路是使分析框架体系化,比如先分析什么,后分析什么,使各个分析点之间具有逻辑联系,保证分析维度的完整性,分析结果的有效性以及正确性,需要数据分析方法论进行支撑
数据分析方法论是一些营销管理类相关理论,比如用户行为理论,PEST分析法,5W2H分析法等
step2:数据收集:
数据从无到有的过程:比如传感器收集气象数据,埋点收集用户行为数据
数据传输搬运的过程:比如采集数据库数据到数据分析平台
step3:数据处理
准确来说应该是数据预处理
数据预处理需要对收集到的数据进行加工整理,形成适合数据分析的样式,主要包括数据清洗,数据转化,数据提取,数据计算
数据预处理可以保证数据的一致性和有效性,让数据变成干净规整的结构化数据
当下企业用于分析的数据更多的侧重于文本数据
什么是干净规整的结构化数据?专业来说就是二维表的数据,行列对应;通俗来说就是格式清晰,利于解读的数据
step4:数据分析
用适当的分析方法及分析工具,对处理过的数据进行分析,提取有价值的信息,形成有效结论的过程
需要掌握各种数据分析方法,还要熟悉数据分析软件的操作
step5:数据展现
数据展现又称为数据可视化,指的是分析结果图表展示,因为人类是视觉动物
数据可视化属于数据应用的一种
注意,数据分析的结果不是只有可视化展示,还可以继续数据挖掘,即席查询(Ad Hoc)等
step6:报告撰写
数据分析报告是对整个数据分析过程的一个总结与呈现
把数据分析的起因,过程,结果及建议完整的呈现出来,供决策者参考
需要有明确的结论,最好有建议或解决方案
一切都围绕着数据:数据从哪里来,到哪里去
大数据的5V特征

分布式和集群
分布式,集群是两个不同的概念

分布式,集群的共同点是:都是多台机器(服务器)组成的
分布式让用户感觉是一台机器
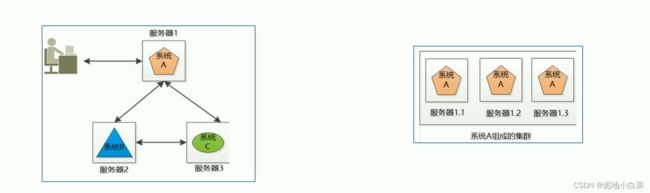
左边就是分布式,右边是集群
分布式每个机器都实现不同的功能而集群每个机器实现的功能都是一样的
分布式与集群的应用(更多涉及到分布式)

Linux操作系统概述
操作系统(Operating system 简称OS)是管理计算机硬件与软件资源的程序,需要处理如:管理与配置内存,决定系统资源供需的优先次序,控制输入设备和输出设备,操作网络与管理文件系统等基本事务
没有操作系统的机器称之为裸机,不管是开发还是使用都十分不便
操作系统也提供一个让用户与系统交互的操作界面



VM虚拟机概念与安装
Vmware wordkstation是一款虚拟机软件,允许用户将Linux,Windows等多个操作系统作为虚拟机在单台PC上运行
用户可以在虚拟机上重现服务器,桌面和平板电脑环境,无需重新启动即可跨不同操作系统同时运行应用
VMware功能,组件
通过对个人笔记本(PC)硬件资源的虚拟,在一台PC上运行其他隔离操作系统
隔离出来的操作系统虽然是虚拟的,但是硬件组成与功能上与物理实体机完全一致
VMware虚拟组件包括:网卡,交换机,DHCP,NAT设备等

Linux文件系统基础知识
文件系统概念:
1.OS中负责管理和存储文件信息的软件机构称为文件管理系统,简称文件系统
2.文件系统的结构通常叫做目录树结构,从斜杠/根目录开始
3.Linux号称“万物皆文件",意味着针对Linux的操作,大多数时间是在针对Linux文件系统操作
文件系统通用特性
1.几乎主流的文件系统都是从根目录开始的,Linux也不例外,而windows文件系统以盘符来区分不同文件系统
2.目录树中节点分为两个种类:目录(directory),文件(file)
3.从根目录开始,路径具有唯一性
4.只有在目录下才可以继续创建下一级目录,换句话说目录树到文件终止蔓延
易混概念:
1.当前路径:也叫当前工作目录,当下用户所属的位置
2.相对路径:相对当前工作目录开始的路径,会随当前路径变化而变化
3.绝对路径:不管工作目录在哪儿,绝对路径都是从/根目录开始,唯一不重复

特殊符号:

Linux常用操作命令(1)-ls,cd,mkdir,rm,mv,cp,cat,tail,管道,重定向,tar命令解压缩包
学习命令之前注意:
1.命令属于多用多会,不用就忘的知识
2.Tab键可以实现自动补全和提示,合理使用
3.history命令可以显示历史执行记录,或者使用方向键来切换前后执行过的命令









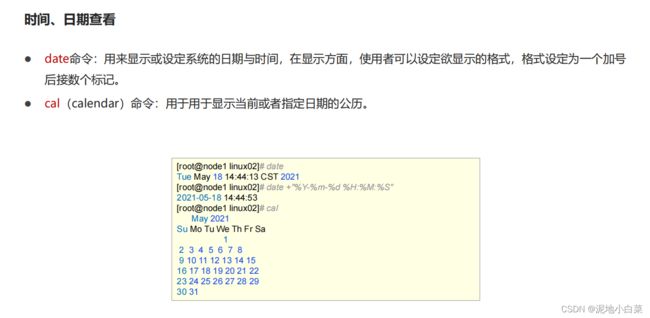
Linux常用系统命令--时间日期,内存磁盘使用率,进程查看


vim编辑器介绍,3种工作模式

打开与新建文件
vim/path/file
如果打开的文件不存在,此时就是新建文件,编辑器左下角会提示new file
如果文件已经存在,此时就打开这个文件,进入命令模式
在使用vim编辑器的过程中如果发现打开的文件内容不符合预期,可以检查一下文件路径是否正确
Vim编辑器3种工作模式:

命令模式<--->输入模式
1.i进入到编辑输入模式后,定位到当前光标前面
2.o进入到编辑输入模式后,在当前行的后面添加一行空行(当前行的下一行)
3.输入模式下按ESC退回到命令模式
命令模式<---->底线命令模式
1.在命令模式下,输入:进入底线命令模式
2.常用的底线命令有:
:q 退出 ;
:w 保存;
:wq 保存退出 ;
:wq! 强制保存退出
提示:在命令模式下按shift+zz,可以实现快速的保存退出
vim基本操作命令



-----2022.8.12
Hadoop介绍:
1.狭义上Hadoop指的是Apache软件基金会的一款开源软件
用java语言实现,开源
允许用户使用简单的编程模型实现跨机器集群对海量数据进行分布式计算处理
2.Hadoop核心组件
Hadoop HDFS(分布式文件存储系统):解决海量数据存储
Hadoop YARN(集群资源管理和任务调度框架):解决资源任务调度
Hadoop MapReduce(分布式计算框架):解决海量数据计算
3.官网: http://hadoop.apache.org/
广义上Hadoop指的是围绕Hadoop打造的大数据生态圈

Hadoop现状:
1.HDFS作为分布式文件存储系统,处在生态圈的底层与核心地位
2.YARN作为分布式通用的集群资源管理系统和任务调度平台,支撑各种计算引擎运行,保证了Hadoop地位
3.MapReduce作为大数据生态圈第一代分布式计算引擎,由于自身设计的模型所产生的弊端,导致企业一线几乎不再直接使用MapReduce进行编程处理,但是很多软件的底层依然在使用MapReduce引擎来处理数据
Hadoop特性优点,国内外应用
Hadoop优点:
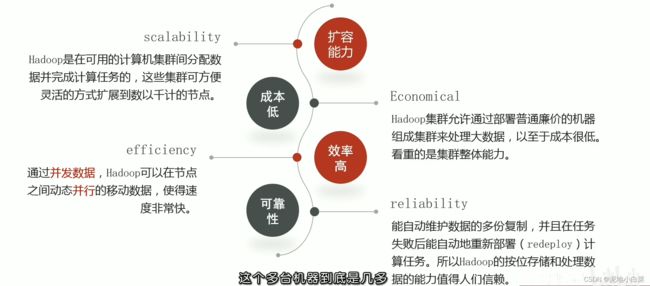
国内外应用涉及到Hadoop的有:谷歌,faceboo,IBM,腾讯,阿里巴巴,百度,华为等
Hadoop成功的原因--通用性
具体来说Hadoop精准区分做什么和怎么做;做什么属于业务问题,怎么做属于技术问题
用户负责业务,Hadoop负责技术
Hadoop发行版本


本次学习所使用的是Apache版的Hadoop,版本号是:3.3.0
Hadoop架构变迁(1.0-2.0变迁)
Hadoop 1.0:HDFS(分布式文件存储);MapReduce(资源管理和分布式数据处理)
Hadoop 2.0:HDFS(分布式文件存储);MapReduce(资源管理和分布式数据处理);
YARN(集群资源管理,任务调度)

Hadoop 3.0架构组件和Hadoop 2.0类似3.0着重于性能优化
通用方面:
精简内核,类路径隔离,shell脚本重构
Hadoop HDFS:
EC纠删码,多NameNode支持
Hadoop MapReduce:
任务本地化优化,内存参数自动推断
Hadoop YARN:
Timeline Service V2,队列配置

Hadoop集群整体概述:
Hadoop集群包括两个集群:HDFS集群,YARN集群
两个集群逻辑上分离,通常物理上连在一起
两个集群都是标准的主从架构集群 (主从:理解为一个领头的带着一堆小弟来做工作)


NN和RM相当于集群中的老大,SNN是辅助NN的,剩下的DN和NM都是小弟
由这个图可以看出来:逻辑上分离,物理上相连接的特点
逻辑上分离:指的是两个集群互相之间没有依赖,互不影响
物理上在一起:某些角色进程往往部署在同一台物理服务器上
上面并没有出现MarReduce集群是因为MapReduce是计算框架,代码层面的组件,并没有集群的概念
Hadoop集群模式安装(cluster mode)/或者叫分布式模式安装

step1:集群角色规划
角色规划的准则:
1.根据软件工作特性和服务器硬件资源情况合理分配
2.比如依赖内存工作的NameNode是不是部署在大内存机器上?
角色规划注意事项:
资源上有抢夺冲突的,尽量不要部署在一起
工作上需要互相配合的,尽量部署在一起

step2:服务器基础环境准备
1.主机名(3台机器):
vim /etc/hostname

2.Host映射(3台机器)
vim /etc/hosts

3.防火墙关闭(3台机器)
4.ssh免密登录(node1执行->node1|node2|node3)
ssh-keygen #4个回车 生成公钥,私钥
ssh-copy-id node1,ssh-copy-id node2,ssh-copy-id node3 #
5.集群时间同步(3台机器):
yum -y install update
ntpdate ntp4.aliyun.com
6.创建统一工作目录(3台机器)
mkdir -p /export.server/ # 软件安装路径
mkdir -p /export/data/ #数据存储路径
mkdir -p /export/software/ #安装包存放路径
step3:上传安装包,解压安装包
1.JDK 1.8安装(3台机器)

2.上传,解压Hadoop安装包(node1)

step4:Hadoop安装包目录结构

配置文件概述

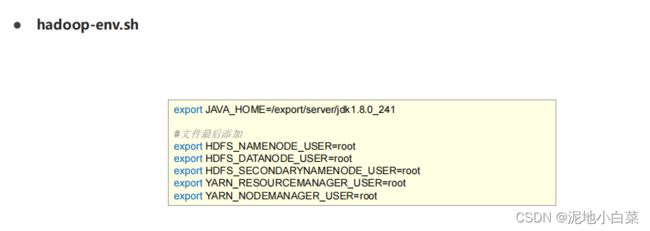
step5:编辑Hadoop配置文件