【阿飞算法】面试题集锦
0.基础
0.1.java基础
进程和线程的区别
进程与线程之间的区别与联系
多线程/java基础
多线程与锁
Java中的String,StringBuilder,StringBuffer三者的区别
Java基础
Netty从使用到源码1_IO模型与多路复用详解
0.2.网络通信
HTTPS如何保证数据传输的安全性
- 对称加密
- 非对称加密
- 数字证书(终极方案)
HTTPS 怎样保证数据传输的安全性
合辑
计算机网络面试相关知识
0.3.设计模式
设计模式
0.5.排序算法
算法与数据结构
算法与数据结构
0.6.算法
github book : geek-algorithm-leetcode
1.JVM
JVM集锦
- jdk1.7 默认垃圾收集器Parallel Scavenge(新生代)+Parallel Old(老年代)
- jdk1.8 默认垃圾收集器Parallel Scavenge(新生代)+Parallel Old(老年代)
- jdk1.9 默认垃圾收集器G1
2.数据库
2.1.MySql
MySql的隔离级别
MySQL的四种事务隔离级别
MySql的底层实现原理、InnoDB原理、MyISAM原理
MySQL索引底层实现原理
MySQL数据库的底层原理,InnoDB和Myisam两种引擎的区别
myisam 更适合读取大于写入的业务,同时不支持事物。
innodb 支持事物,效率上比myisam稍慢。
文件存储:
myism物理文件结构为:
-
.frm文件:与表相关的元数据信息都存放在frm文件,包括表结构的定义信息等。
-
.myd文件:myisam存储引擎专用,用于存储myisam表的数据
-
.myi文件:myisam存储引擎专用,用于存储myisam表的索引相关信息
innodb的物理文件结构为:
-
.frm与表相关的元数据信息都存放在frm文件,包括表结构的定义信息等。
-
.ibd文件和.ibdata文件:
这两种文件都是存放innodb数据的文件,之所以用两种文件来存放innodb的数据,是因为innodb的数据存储方式能够通过配置来决定是使用共享表空间存放存储数据,还是用独享表空间存放存储数据。
独享表空间存储方式使用.ibd文件,并且每个表一个ibd文件
共享表空间存储方式使用.ibdata文件,所有表共同使用一个ibdata文件
觉得使用哪种方式的参数在mysql的配置文件中 innodb_file_per_table
B-tree/b+tree 原理以及聚簇索引和非聚簇索引,为什么选用B+/-Tree
浅谈算法和数据结构: 十 平衡查找树之B树
B-tree/b+tree 原理以及聚簇索引和非聚簇索引
聚簇索引与非聚簇索引(也叫二级索引)
-
聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据
-
非聚簇索引:将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行,myisam通过key_buffer把索引先缓存到内存中,当需要访问数据时(通过索引访问数据),在内存中直接搜索索引,然后通过索引找到磁盘相应数据,这也就是为什么索引不在key buffer命中时,速度慢的原因
为什么MySQL数据库索引选择使用B+树?
为什么使用索引查数据更快?什么时候使用索引查数据比全表扫描还更慢?使用什么关键字会触发全表扫描?
因为这个二叉树算法,让查询速度快很多,二叉树的原理,就是取最中间的一个数,然后把大于这个数的往右边排,小于这个数的就向左排,每次减半,然后依次类推,每次减半,形成一个树状结构图
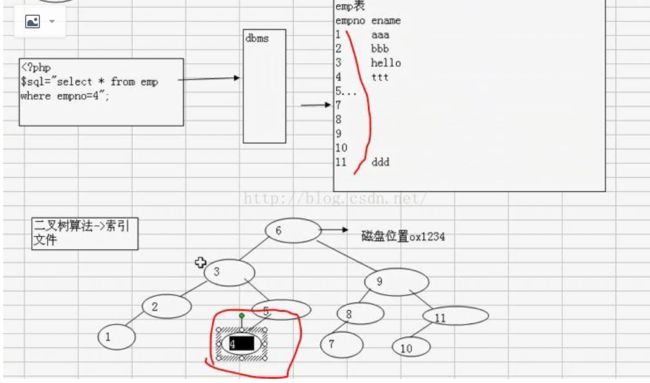
上面的例子,我们不使用索引的话,需要查询11次才把编号为4的数据取出,如果加上索引,我们只需要4次就可以取出。
举一个非常好理解的场景(scenario:通过索引读取表中20%的数据)解释一下这个有趣的概念:
假设一张表含有10万行数据--------100000行
我们要读取其中20%(2万)行数据----20000行
表中每行数据大小80字节----------80bytes
数据库中的数据块大小8K----------8000bytes
所以有以下结果:
每个数据块包含100行数据---------100行
这张表一共有1000个数据块--------1000块
上面列出了一系列浅显易懂的数据,我们挖掘一下这些数据后面的故事:
通过索引读取20000行数据 = 约20000个table access by rowid = 需要处理20000个块来执行这个查询
但是,请大家注意:整个表只有1000个块!
所以:**如果按照索引读取全部的数据的20%相当于将整张表平均读取了20次!!**So,这种情况下直接读取整张表的效率会更高。很幸运,Oracle也是这么想的
-
应尽量避免在where 子句中对字段进行null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,
-
应尽量避免在where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
-
应尽量避免在where 子句中使用or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描
-
in 和not in 也要慎用,否则会导致全表扫描,
-
下面的查询也将导致全表扫描:
https://www.cnblogs.com/jameslif/p/6406167.html
数据库中,exist和in的区别?
链接
数据库四大特性和隔离级别,脏读,不可重复读,虚读
不可重复读和脏读的区别是,脏读是某一事务读取了另一个事务未提交的脏数据,而不可重复读则是读取了前一事务提交的数据。
数据库的四种隔离级别
如何解决幻读
- 多版本并发控制(MVCC)(快照读/一致性读)
- next-key 锁 (当前读)
MySQL 是如何解决幻读的
全文索引,索引什么时候会失效?索引的优化,最左前缀原则
数据库设计三大范式(简单易懂)
https://www.cnblogs.com/1906859953Lucas/p/8299959.html
数据库索引类型及实现方式
唯一索引、主键索引和聚集索引
B+树,位图索引,散列索引
主键索引和非主键索引的区别
从图中不难看出,主键索引和非主键索引的区别是:非主键索引的叶子节点存放的是主键的值,而主键索引的叶子节点存放的是整行数据,其中非主键索引也被称为二级索引,而主键索引也被称为聚簇索引。
根据这两种结构我们来进行下查询,看看他们在查询上有什么区别。
1、如果查询语句是 select * from table where ID = 100,即主键查询的方式,则只需要搜索 ID 这棵 B+树。
2、如果查询语句是 select * from table where k = 1,即非主键的查询方式,则先搜索k索引树,得到ID=100,再到ID索引树搜索一次,这个过程也被称为回表。
高并发下数据库分库分表面试题整理
分库分表后会有哪些坑?
1、事务一致性问题
由于表分布在不同库中,不可避免会带来跨库事务问题。一般可使用"XA协议"和"两阶段提交"处理,但是这种方式性能较差,代码开发量也比较大。
通常做法是做到最终一致性的方案,往往不苛求系统的实时一致性,只要在允许的时间段内达到最终一致性即可,可采用事务补偿的方式。
2、分页、排序的坑
日常开发中分页、排序是必备功能,而多库进行查询时limit分页、order by排序,着实让人比较头疼。
分页需按照指定字段进行排序,如果排序字段恰好是分片字段时,通过分片规则就很容易定位到分片的位置;一旦排序字段非分片字段时,就需要先在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序,最终返回给用户,过程比较复杂。
3、全局唯一主键问题
由于分库分表后,表中的数据同时存在于多个数据库,而某个分区数据库的自增主键已经无法满足全局唯一,所以此时一个能够生成全局唯一ID的系统是非常必要的。那么这个全局唯一ID就叫分布式ID。
分库分表要解决的问题
2.2.Redis
对外封装的数据结构
最详细的Redis五种数据结构详解
内部的数据结构
redis底层设计(一)——内部数据结构
跳表(skiplist)的数据结构
【数据结构与算法】之跳表(Java实现)—第九篇
跳跃表以及跳跃表在redis中的实现
Redis 为什么不直接使用 C 字符串,而要自己构建一种字符串抽象类型 SDS(simple dynamic string)?
了解下Redis的sds结构
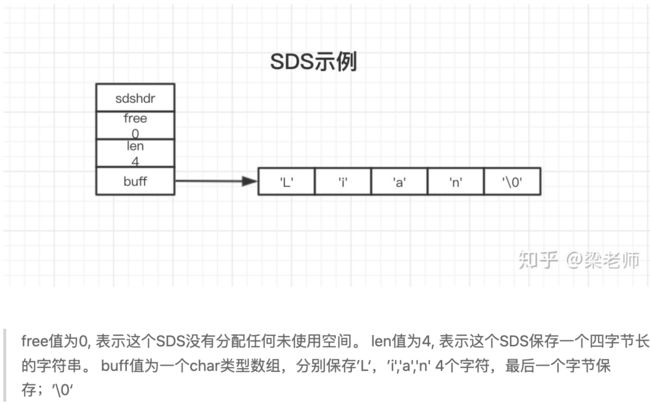
- C语言使用长度N+1的字符数组来表示长度为N的字符串,并且最后一个字符串总是空字符串’\0‘. ,而且它并不记录自身的长度信息,如果要获取,必须全部遍历;但SDS不一样,他有len属性记录了长度,所以获取长度的复杂度很高。
- C字符串容易缓冲区溢出,而SDS的空间分配策略则不会,当需要操作字符串时,会先检测空间大小,如果不满足,则需要对空间做扩展。
- C在对字符串做修改时,因为没有记录长度信息,所以需要频繁对内存做分配,而SDS通过free属性来记录未使用的空间,实现空间预分配和惰性空间释放。
Redis的字符串的底层实现SDS
Redis持久化方式
Redis持久化方式
Redis 中如何实现的消息队列?
Redis 中如何实现的消息队列?实现的方式有几种?
Redis如何实现延迟队列
延时队列:基于 Redis 的实现
3.大数据
3.1.Hadoop/HDFS
大数据笔记-有道云
3.2.Hive
3.3.HBase
详解HBase架构原理
关系型数据库与HBase的数据储存方式区别
HBase存储原理、读写原理以及flush和合并过程
Hbase原理、基本概念、基本架构
HBase为什么适合写多读少的场景?
3.4.Presto
3.5.Kudu
3.6.StarRocks
3.7.Kafka
kafka原理
深入理解Kafka(一)之基础概念
深入理解Kafka(二)之消息可靠性与一致性
kafka为什么吞吐量高?
3.7.1.Kafka的原理
kafka工作原理介绍
3.7.1.1.Kafka client 消息接收的三种模式
1.最多一次:客户端收到消息后,在处理消息前自动提交,这样kafka就认为consumer已经消费过了,偏移量增加。
2.最少一次:客户端收到消息,处理消息,再提交反馈。这样就可能出现消息处理完了,在提交反馈前,网络中断或者程序挂了,那么kafka认为这个消息还没有被consumer消费,产生重复消息推送。
3.正好一次:保证消息处理和提交反馈在同一个事务中,即有原子性。
本文从这几个点出发,详细阐述了如何实现以上三种方式。
https://blog.csdn.net/laojiaqi/article/details/79034798
3.7.1.2.为什么需要消息队列
1)解耦:
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
2)冗余:
消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
3)扩展性:
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。
4)灵活性 & 峰值处理能力:
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
5)可恢复性:
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
6)顺序保证:
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。(Kafka保证一个Partition内的消息的有序性)
7)缓冲:
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
8)异步通信:
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
Kafka在高并发的情况下,如何避免消息丢失和消息重复?kafka消费怎么保证数据消费一次?数据的一致性和统一性?数据的完整性?
3.8.Flink
3.9.Spark
3.10.ElasticSearch
原理/架构
Elasticsearch核心原理之集群与分片
图解分布式搜索引擎ElasticSearch
ElasticSearch底层原理浅析
ElasticSearch进阶篇集群+原理(看这一篇就懂原理)
elasticsearch选主流程
elasticsearch 选主流程
深入elasticsearch(三):elasticsearch选主流程详解
3.19.海量数据处理面试题
- 十道海量数据处理面试题与十个方法大总结
3.20.大数据经典博客
3.20.分布式理论
分布式系统CAP理论初探
分布式一致性算法Paxos初探
分布式事务介绍
分布式寻址算法初探
4.组件对比
RabbitMQ与Kafka的对比
RabbitMQ与Kafka选型对比
HBase与Hive的区别
Hbase与Hive的区别
hive和hbase本质区别——hbase本质是OLTP的nosql DB,而hive是OLAP 底层是hdfs,需从已有数据库同步数据到hdfs;hive可以用hbase中的数据,通过hive表映射到hbase表
OLAP、OLTP
OLAP、OLTP的介绍和比较
8.架构
图解高并发限流
9.手写题
9.1.SQL
LeetCode
手写SQL-合辑
9.2.写一个死锁
public class DeadLock implements Runnable {
public int flag = 1;//静态对象是类的所有对象共享的
private static Object o1 = new Object(), o2 = new Object();
@Override
public void run() {
System.out.println("flag=" + flag);
if (flag == 1) {
synchronized (o1) {
try {
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}
synchronized (o2) {
System.out.println("1");
}
}
}
if (flag == 0) {
synchronized (o2) {
try {
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}
synchronized (o1) {
System.out.println("0");
}
}
}
}
public static void main(String[] args) {
DeadLock td1 = new DeadLock();
DeadLock td2 = new DeadLock();
td1.flag = 1;
td2.flag = 0;
//td1,td2都处于可执行状态,但JVM线程调度先执行哪个线程是不确定的。
//td2的run()可能在td1的run()之前运行new Thread(td1).start();newThread(td2).start();
}
}
(写一个死锁,觉得这个问题真的很不错,经常说的死锁四个条件,背都能背上,那写一个看看,思想为:定义两个ArrayList,将他们都加上锁A,B,线程1,2,1拿住了锁A ,请求锁B,2拿住了锁B请求锁A,在等待对方释放锁的过程中谁也不让出已获得的锁。)
9.3.写一个生成者消费者
synchronized锁住一个LinkedList,一个生产者,只要队列不满,生产后往里面放,一个消费者只要队列不空。向外取,用wait() notify()来做
public class ProducerAndCustomerDemo {
private static int capacity = 150;
private static List<Integer> basket = new ArrayList<>();
public static void main(String[] args) {
int producerSize = 2;
Thread[] ps = new Thread[producerSize];
for (int i = 0, step = 500; i < producerSize; i++) {
ps[i] = new Thread(new Producer((i) * step, (i + 1) * step), "生产-->线程--" + (i + 1));
ps[i].start();
}
int customerSize = 10;
Thread[] cs = new Thread[customerSize];
for (int i = 0; i < customerSize; i++) {
cs[i] = new Thread(new Consumer(), "消费线程---" + (i + 1));
cs[i].start();
}
// 等待生产线程结束并中断消费线程
for (int i = 0; i < producerSize; i++) {
try {
ps[i].join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
for (int i = 0; i < customerSize; i++) {
cs[i].interrupt();
}
}
static class Producer implements Runnable {
private int start;
private int end;
public Producer(int start, int end) {
this.start = start;
this.end = end;
}
@Override
public void run() {
for (int i = start; i < end; i++) {
synchronized (basket) {
try {
while (basket.size() == capacity) {
basket.wait();
}
System.out.println(Thread.currentThread().getName() + "--producer--" + i);
basket.add(i);
basket.notifyAll();
// 让出当前线程的执行权,有利于看出交替线程运行的效果
Thread.yield();
} catch (Exception e) {
e.printStackTrace();
break;
}
}
}
}
}
static class Consumer implements Runnable {
@Override
public void run() {
while (true) {
synchronized (basket) {
try {
while (basket.size() == 0) {
basket.wait();
}
System.out.println(Thread.currentThread().getName() + basket.remove(0));
basket.notifyAll();
} catch (Exception e) {
e.printStackTrace();
System.out.println(Thread.currentThread().getName() + "退出");
break;
}
}
}
}
}
}
另外一种
public class Storage {
// 仓库最大存储量
private final int MAX_SIZE = 100;
// 仓库存储的载体
private LinkedList<Object> list = new LinkedList<Object>();
// 生产num个产品
public void produce(int num){
// 同步代码段
synchronized (list){
// 如果仓库剩余容量不足
while (list.size() + num > MAX_SIZE){
System.out.println("【要生产的产品数量】:" + num + "/t【库存量】:"+ list.size() + "/t暂时不能执行生产任务!");
try{
// 由于条件不满足,生产阻塞
list.wait();
}
catch (InterruptedException e){
e.printStackTrace();
}
}
// 仓库剩余容量充足,即生产条件满足情况下,生产num个产品
for (int i = 1; i <= num; ++i){
list.add(new Object());
}
System.out.println("【已经生产产品数】:" + num + "/t【现仓储量为】:" + list.size());
list.notifyAll(); //生产完产品后,通知其他被阻塞的线程
}
}
// 消费num个产品
public void consume(int num){
// 同步代码段
synchronized (list){
// 如果仓库存储量不足
while (list.size() < num){
System.out.println("【要消费的产品数量】:" + num + "/t【库存量】:"+ list.size() + "/t暂时不能执行消费任务!");
try{
// 由于条件不满足,消费阻塞
list.wait();
}
catch (InterruptedException e)
{
e.printStackTrace();
}
}
// 消费条件满足情况下,消费num个产品
for (int i = 1; i <= num; ++i){
list.remove();
}
System.out.println("【已经消费产品数】:" + num + "/t【现仓储量为】:" + list.size());
list.notifyAll();//消费完后,释放锁,通知其他被阻塞的线程
}
}
// get/set方法
public LinkedList<Object> getList(){
return list;
}
public void setList(LinkedList<Object> list){
this.list = list;
}
public int getMAX_SIZE(){
return MAX_SIZE;
}
}
9.4.写一个你认为最好的单例模式
单例:饿汉,懒汉,静态内部类,枚举,双检锁
Step1:错误的单例模式:
public class Singleton {
private static Singleton uniqueSingleton;
private Singleton() {
}
public Singleton getInstance() {
if (null == uniqueSingleton) {
uniqueSingleton = new Singleton();
}
return uniqueSingleton;
}
}
| Time | Thread A | Thread B |
|---|---|---|
| T1 | 检查到uniqueSingleton为空 | |
| T2 | 检查到uniqueSingleton为空 | |
| T3 | 初始化对象A | |
| T4 | 返回对象A | |
| T5 | 初始化对象B | |
| T6 | 返回对象B |
可以看到,uniqueSingleton被实例化了两次并且被不同对象持有。完全违背了单例的初衷。
Step2:加锁
public class Singleton {
private static Singleton uniqueSingleton;
private Singleton() {
}
public synchronized Singleton getInstance() {
if (null == uniqueSingleton) {
uniqueSingleton = new Singleton();
}
return uniqueSingleton;
}
}
这样虽然解决了问题,但是因为用到了synchronized,会导致很大的性能开销,并且加锁其实只需要在第一次初始化的时候用到,之后的调用都没必要再进行加锁。
Step3:错误的双重检查锁
public class Singleton {
private static Singleton uniqueSingleton;
private Singleton() {
}
public Singleton getInstance() {
if (null == uniqueSingleton) {
synchronized (Singleton.class) {
if (null == uniqueSingleton) {
uniqueSingleton = new Singleton(); // error
}
}
}
return uniqueSingleton;
}
}
如果这样写,运行顺序就成了:
- 检查变量是否被初始化(不去获得锁),如果已被初始化则立即返回。
- 获取锁。
- 再次检查变量是否已经被初始化,如果还没被初始化就初始化一个对象。
执行双重检查是因为,如果多个线程同时了通过了第一次检查,并且其中一个线程首先通过了第二次检查并实例化了对象,那么剩余通过了第一次检查的线程就不会再去实例化对象。
这样,除了初始化的时候会出现加锁的情况,后续的所有调用都会避免加锁而直接返回,解决了性能消耗的问题。
隐患
上述写法看似解决了问题,但是有个很大的隐患。实例化对象的那行代码(标记为error的那行),实际上可以分解成以下三个步骤:
- 分配内存空间
- 初始化对象
- 将对象指向刚分配的内存空间
但是有些编译器为了性能的原因,可能会将第二步和第三步进行重排序,顺序就成了:
- 分配内存空间
- 将对象指向刚分配的内存空间
- 初始化对象
现在考虑重排序后,两个线程发生了以下调用:
| Time | Thread A | Thread B |
|---|---|---|
| T1 | 检查到uniqueSingleton为空 | |
| T2 | 获取锁 | |
| T3 | 再次检查到uniqueSingleton为空 | |
| T4 | 为uniqueSingleton分配内存空间 | |
| T5 | 将uniqueSingleton指向内存空间 | |
| T6 | 检查到uniqueSingleton不为空 | |
| T7 | 访问uniqueSingleton(此时对象还未完成初始化) | |
| T8 | 初始化uniqueSingleton |
在这种情况下,T7时刻线程B对uniqueSingleton的访问,访问的是一个初始化未完成的对象
Step4:双重检查锁定(double-checked locking)
public class DoubleCheckedLocking {
private volatile static DoubleCheckedLocking instance;
public static DoubleCheckedLocking getInstance() {
if (instance == null) {
synchronized (DoubleCheckedLocking.class) {
if (instance == null) {
instance = new DoubleCheckedLocking();
}
}
}
return instance;
}
}
前加入关键字volatile。使用了volatile关键字后,重排序被禁止,所有的写(write)操作都将发生在读(read)操作之前。
9.5.使用HashMap实现HashSet
https://blog.csdn.net/m0_37499059/article/details/80619167
10.Misc
20.八股文每日一题
- 八股文每日一题
Reference
- JavaGuide