MySQL语句大总结
-
- 基础语法
- 数据库约束
- 复杂语法
-
- 1:聚合查询(所谓聚合就是聚合函数的结果)
- 2:联合查询
- 什么是内连接;什么是外连接?
- 3:子查询(套娃,慎用)
- 4:合并查询
基础语法
建库
create database liao;
create database if not exists liao charset utf8;
不设置;默认是拉丁文;不支持中文
create database if not exists charset utf8;
查库
show databases;
选库
use liao;
删库
drop database liao;
建表
create table tablename(ziduan1 varchar , ziduan2 int);
create table if not exists tablename( ziduan1 varchar(20), ziduan2 int);
查表
show tables
查表结构
desc tablename;
删表
drop table tablename
改表(问chatgpt)
alrer table tablename modify coumn password varchar(65)
插表数据
insert into tablename values(zhangsan,19),(lisi,18)
insert into tablename (ziduan2) values(19);
insert into tablename (ziduan1,ziduan2) values(wangwu,19);
insert into tablename1 select *from tablename2; 把查询的结果插入到另一个表中;得要求列数量和类型要匹配
查表数据
select *from tablename;
select ziduan1,ziduan2 from tablename;
select ziduan1,ziduan2+10 from tablename
select ziduan1 as newtablename from tablename
select distinct ziduan1 from tablename;对结果去重复
select *from tablename order by ziduan1;小到大;升序
select *from tablename order by ziduan1 desc;大到小;降序
select *from tablename order by ziduan1,ziduan2 desc;ziduan1也重复那么就用ziduan2进行降序排序
条件查询:条件放在表名的后面;这些条件同样能放到改和删除里
运算符
大于、小于、大于等于、小于等于;不必多言
where ziduan1<20;
等于 null不适合用;null=null =》null
<==> 这个用于null=null就安全
不等于
!=, <>
范围匹配
between 范围1 and 范围2 就是你的值是这个 【范围1】 -【范围2】
where ziduan1 between 60 and 100;
集合里匹配
where ziduan1 in(20,30,“123”,“456”);
是null吗
where ziduan1 is null;
是非空吗
where ziduan1 is not null
模糊匹配
where ziduan1=孙%;
1:孙% 只要是孙开头,无论几个字符都没问题。
2:%孙 以孙结尾的
3:%孙% 不管开头结尾,只要包含孙即可
4:_ 下划线匹配一个字符:
孙_%:孙开头,并且孙后面只有一个字符
孙_ _%:两个下划线代表孙后面两个字符
孙 :肉夹馍的孙,前面一个字,后面一个字,中间夹着孙
注意:如果有别名的情况;where这里的条件不能用别名;因为是先执行条件,才看是否执行前面的表达式和别名
上面的还能搭配逻辑运算符:and、or、not。优先级就不去记了;有需要加括号呗。
限制查询数量:分页的时候能使用
select * from tablename limit n; 只能显示n个;如果超过n个具体显示哪n个?不确定
select *from tablename limit 5 offset 0; 从0的地方开始计数查5条
select *from tablename limit 0,5; 和上面等价;省略offset
各个部分的位置:select 需要查询的内容 from tablename 条件查询 限制查询 排序
改表数据
update tablename set ziduan2=22 where 1=1;
删表数据
delete from tablename where ziduan1=zhangsan
数据库约束
not null - 指示某列不能存储 NULL 值。(这一列必须得填)
unique - 保证某列的每行必须有唯一的值。(这列数据不能重复;会通过索引先查一下有没有重复再插入)
default -规定没有给列赋值时的默认值。
name varchar(20) default “太帅了”
primary key - (not null和 unique 的结合)。主键,非空且要唯一,例如身份证,学号;一个表主键只能有一个。
联合主键,把多个列放到一起作为共同主键;知道有这个东西
自增主键;作为主键的值(就是当我们指定id为主键,也就是id不为空也不重复,mysql自增主键会帮你生成符合的值);必须是数值型才能自增。id int primary key auto_increment。如果1-10你突然插入个101;下一个自增也会从101开始
foreign key - 多表关联,要求某个记录必须在另一个表里存在。
create table classid(id int primary key,name varchar(20)); 父表
create table student(id int primary key,name varchar(20),classID int,foreign key (classID) references classid(id)); 子表
学生表被关联的字段主不主键无所谓,主要是班级表的id要有主键。
第一个方面:我们得要判断插入的学生id是否在班级id出现,就需要提供索引查询(不然你默认情况要遍历表效率太低)
第二个方面:班级id主键没了,就说明他的班级都有重复的号,那我插入班级2,你有两个班级为2的号,我插入哪去;我不知道这个classID是谁的(子表引用的唯一性)
第三个方面:要想创建外键,要求父表对应的列得有primary key或者unique约束
为什么要约束:
父表对子表的约束力:插入(或修改update)的数据学生表里的classID得符合在班级表里id列存在。
子表对父表的约束力:当子表已经有创建数据的时候,你的父表或者父表的这列你是删除不了的。删库可以。其它就只能先删子表再删父表
不能两张表相互创建外键约束,因为你创建的时候得指定父表,两个都是子表,先创建的指定谁呢?
使用场景:
电商:商品表(id,名称,库存),订单表(订单数量id,商品id,购买时间); 订单表的商品id得在商品表存在
一个问题;当我要下架商品怎么办,商品表又不能删(外键约束父表)。
逻辑删除,做个标记,让其变无效。当我要重新上架的时候还能把这个标记改回来。
check - 保证列中的值符合指定的条件。(mysql5不支持,写了忽略掉)
约束组合使用:not null+unique=primary key;所以当按下面组合使用时;我们查询的表结构这列是PRI
create table tablename(id int not null unique,name varchar(20) not null unique);
复杂语法
1:聚合查询(所谓聚合就是聚合函数的结果)
针对列进行操作;我们之前的计数只是针对行进行操作;比如english+chinese
常见聚合函数
sum(求和):计算一列中所有值的总和。
avg(平均值):计算一列中所有值的平均值。
max(最大值):找到一列中的最大值。
min(最小值):找到一列中的最小值。
count(计数):计算一列中非空值的数量。
select count(ziduan1) from tablename;
select sum(ziduan2) from tablename;
select count(ziduan1),sum(ziduan2) from tablename;
聚合查询-分组查询
在聚合查询的时候把这个group by的列相同分为一组;然后进行聚合查询。
比如:
create table emp(
id int primary key auto_increment,
name varchar(20) not null,
role varchar(20) not null,
salary numeric(11,2)
);
insert into emp(name, role, salary) values
(‘马云’,‘服务员’, 1000.20),
(‘马化腾’,‘游戏陪玩’, 2000.99),
(‘孙悟空’,‘游戏角色’, 999.11),
(‘猪无能’,‘游戏角色’, 333.5),
(‘沙和尚’,‘游戏角色’, 700.33),
(‘隔壁老王’,‘董事长’, 12000.66);
select role,max(salary),min(salary),avg(salary) from emp group by role;
2:联合查询
select * from student ,class where studen.classId=class.classId; 可以直接写字段名即可;只是我们当前字段名重复了,只能这样子指定;这样写也是比较稳妥和可读。把两张表的信息都查在一起;项目里非常常用;我们选择需要的列查出来即可。
联合查询执行流程:
1:首先两张表
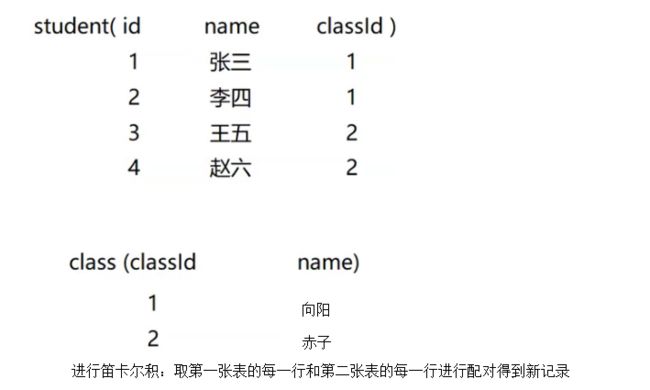
2:

3:把无意义去掉。这里有意义的全是他们的id是相同的(也就是班级对的上),这里筛选的条件where 就叫连接条件
联合查询另一种完成:
select *from tablename1 join tablename2 on studen.classId=class.classId;
这种写法有些区别;第一种的只能实现内连接,join on 内连接,外连接都能实现
什么是内连接;什么是外连接?


两者有啥区别吗?大多数情况下没区别;当表的数据是一 一对应就没有区别(就都是中间交集的一块);当不是一 一对应就有区别。

内连接:两种内连接查询的情况

外连接:
左外连接;前面加个left。会把左表的结果尽量列出来;哪部怕在右表中没有对应的记录,就使用 null填充

右外连接;前面加个right。会把右表的结果尽量列出来;哪部怕在左表中没有对应的记录,就使用 null填充
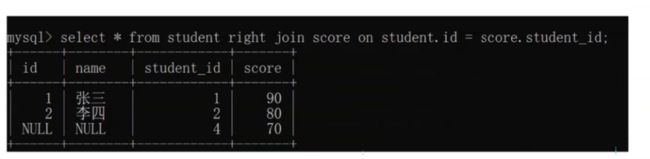
自连接:
自己和自己迪卡尔积,( 特殊问题的特殊处理手段,代价不小);可以把行转成列.sql无法行与行使用条件比较,只能列与列比较(但是有些需求就要这种效果)
比如:如下的表;同一个同学的两门成绩70.5和98.5怎么比较;好像还真没办法比较;我们之前都是行的字段进行比较。

进行自连接会产生大量无效数据;我们要条件筛选进行精简一下;两张表是一样的;我们取一个别名方便进行引用其中的字段。
select *from tablename1 as s1, tablename1 as s2 where s1.student_id=s2.student_id;

3:子查询(套娃,慎用)
把多个sql合成一个;比如一个查询的结果作为另一个查询的条件一部分
4:合并查询
比如把两个查询的结果集合并成一个;得这两个结果集的列相同才能合并
查询A union 查询B 这种写法两个查询的结果可以来自不同的表;只要查询的列匹配即可
union all两者差不多(union会去重复,把重复的只保留一份,其它的一样)