通过对多个思维链进行元推理来回答问题11.8
通过对多个思维链进行元推理来回答问题
- 摘要
- 1 引言
- 2 背景
- 3 方法
-
- 3.1 生成推理链
- 3.2 对推理链进行元推理
- 4 实验
-
- 4.1 实验设置
-
- 4.1.1 数据集
- 4.1.2 方法

摘要
现代的多跳问题回答(QA)系统通常将问题分解为一系列推理步骤,称为思维链(CoT),然后才得出最终答案。通常会对多个链进行采样,并通过对最终答案进行投票机制进行聚合,但中间步骤本身被丢弃。尽管这样的方法提高了性能,但它们不考虑链之间的中间步骤关系,并且不提供预测答案的统一解释。我们引入了多链推理(MCR),一种方法,它引导大型语言模型对多个思维链进行元推理,而不是聚合它们的答案。MCR检查不同的推理链,在它们之间混合信息,并选择生成解释和预测答案中最相关的事实。MCR在7个多跳QA数据集上优于强基线模型。此外,我们的分析表明,MCR的解释具有很高的质量,使人类能够验证其答案。
1 引言
在思维链(CoT)提示中,通过对一个大型语言模型进行提示,让其按照逐步解释的方式生成答案。已经证明,CoT提示可以显著提高在推理密集型任务上的性能。此外,Wang等(2023)表明,采样多个思维链并返回它们的多数输出进一步提高了准确性,他们将这种方法称为自洽性(SC)。
尽管SC可以提高性能,但它也有几个缺点。
- 首先,在可能的输出空间很大时,每个推理链可能会导致不同的输出,这种情况下不会形成明显的多数。
- 其次,专注于最终输出会丢弃中间推理步骤中存在的相关信息。考虑回答问题“Brad Peyton需要了解地震学吗?”(图1)。推理链#1导致了一个错误的答案(“不需要”),但它的步骤提供了有用的信息。例如,关于“地震学是什么”的中间问题和随后的答案构成了一个重要的事实,在其他两个链中是不存在的。
- 最后,将SC与思维链提示结合使用会降低可解释性,因为没有单个推理链可以被视为解释。

在这项工作中,提出了多链推理(MCR)的方法,其中引导一个大型语言模型(LLM)在多个推理链上进行元推理,并生成最终答案和解释。 与先前的工作不同,采样的推理链不是用于预测(如SC中),而是作为收集多个链的证据的手段。图1对比了MCR和SC的方法。虽然这两种方法都依赖于采样多个推理链,但SC返回了多数答案“不需要”(灰色框,右下角)。相比之下,MCR将每个链的中间步骤(蓝色框,左上角)连接在一起形成一个统一的上下文,并将其与原始问题一起传递给元推理模型。元推理模型是一个独立的LLM,被提示在多个推理链上进行元推理,并生成最终答案和解释(粉色框,左下角)。通过对多个推理链进行推理,MCR能够减轻前面提到的缺点-它结合了多个链的事实来生成正确的最终答案,并给出了答案有效性的解释。

MCR具有三个主要组成部分。为了生成推理链,使用两个组件,即分解模型和检索器,它们共同生成链(图2),类似于先前的工作。然后将这些链连接成一个统一的多链上下文,并将其输入到上述的元推理模型中。图1突出了元推理器将来自不同推理链的事实进行组合的能力(粉色的中间答案)。输出的解释结合了每个链的事实:
(1)“地震学是研究地震的学科”;
(2)“《圣安地列斯》是一部电影…”;
(3)“Brad Peyton是一位电影导演、编剧…”。SC(灰色部分)由于仅使用答案而出错,而元推理器会读取整个推理链,并能够正确回答问题。
在开放域环境中对各种具有挑战性的多跳问答(QA)数据集进行了MCR的评估。这些数据集可以分为两类任务:隐含推理任务,其中推理步骤在问题文本中是隐含的,需要使用策略进行推断;显式推理任务,其中存在一种单一的推理策略,可以直接根据问题的语言进行推断。作为基准,将MCR与SC进行了比较,并与SelfAsk(Press等,2022年)和增加检索功能的CoT的变体进行了比较,这是根据Trivedi等人的方法进行的(2022a)。结果表明,MCR始终优于所有其他基线模型,特别是在使用相同的推理链时,比SC提高了高达5.7%(§4)。
通过手动评分其生成的解释并估计其准确性来分析MCR的质量(§5)。分析结果显示,MCR对于超过82%的示例生成了高质量的解释,而少于3%的示例是无用的。总之,本文主要贡献包括:
- 介绍了用于多重思维链元推理的MCR方法。
- 展示了MCR在所有7个多跳开放域QA基准测试中优于所有基准模型,包括自一致性。
- 分析了MCR的解释质量和其多链推理能力。
数据和代码库已公开提供。
2 背景
最近,通过对LLM进行少量提示来回答多跳问题引起了广泛的兴趣。这些工作大多遵循一个共同的标准:首先,给定一个问题,规划一个逐步推理链条来得出答案并解决所有中间步骤,借助检索器来减少模型的幻觉。然后,将多个推理链与答案结合起来得出最终答案。在我们的工作中,我们遵循了这个模板,并专注于后半部分。然而,我们的元推理方法与先前的工作不同之处在于对多个推理链进行推理。换句话说,我们使用多个链条来收集与问题回答相关的证据。
3 方法
本文提出了一种通过对多个推理链进行元推理来回答问题的方法。重点是开放域问答(QA),其中输入是一个问题q,回答问题的证据可以在语料库C中的一个或多个句子中找到。当回答q需要多个推理步骤时,可以通过推理链r来表示。推理链是一个包含一个或多个中间问题-证据-答案三元组( q i , e i , a i q_i, e_i, a_i qi,ei,ai)的列表。
证据 e i ∈ C e_i∈C ei∈C是与回答中间问题 q i q_i qi相关的句子。
图2描述了回答“The Shard能容纳多少只蚂蚁?”这个问题的方法。首先,使用一个提示的LLM生成多个推理链r(1),…,r(k)(步骤1-2)。每个r(j)通过将生成的中间问题与检索到的上下文交错生成(§3.1)。主要贡献是第3步:引入了第二个LLM,通过在多个推理链上进行元推理,将证据事实作为解释收集起来并生成最终答案(§3.2)。
3.1 生成推理链
给定一个问题q,使用以下方法生成它的推理链:
(1)分解模型,
(2)检索器组件。
推理链生成过程在很大程度上基于先前的工作,在第2节中进行了讨论。图3描述了分解和检索的交错过程。在每个步骤中,分解模型根据原始问题q和先前的推理步骤生成一个中间问题 q i q_i qi。然后,检索器使用 q i q_i qi来检索相关的证据 e i ∈ C e_i ∈ C ei∈C。将 e i e_i ei和 q i q_i qi提供给分解模型(以及先前的步骤),以生成中间答案 a i a_i ai。在答案生成过程中,将中间证据句子置于推理链的开头,而不是交错插入,因为这样可以提高所有基线模型的准确性。有关分解提示,请参阅附录D。
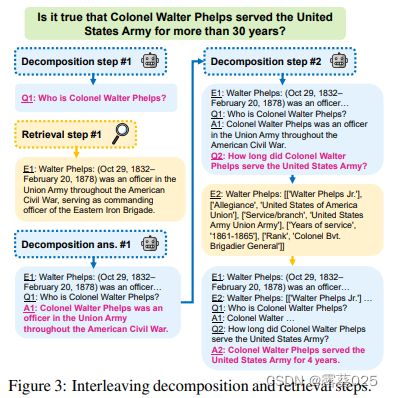
3.2 对推理链进行元推理
元推理模块是MCR的核心贡献。不像之前的方法那样对预测的答案进行多链采样,而是利用它们来生成上下文。这个上下文被输入到一个提示的LLM中,用于读取生成的链条并在其上进行推理,以返回答案。
在第3.1节中,将推理链定义为一个( q i , e i , a i q_i,e_i,a_i qi,ei,ai)三元组的列表。首先采样多个链条,并使用它们所有的中间问题-答案对( q i , a i q_i,a_i qi,ai)作为多链上下文(使用问题-证据对( q i , e i q_i,e_i qi,ei)的变体在附录B.4中描述)。图2展示了三个采样链条的多链上下文(下方粉色框)。接下来,将多链上下文和原始问题输入到元推理模块中。该模型是一个LLM,在多链上下文下进行少量示例问题回答的提示。图4展示了FEVEROUS数据集中元推理模块提示的一个示例(完整的提示在附录D中)。我们指示LLM在给定多链上下文的情况下“逐步回答问题”,其中每一行描述了来自一个采样链的( q i , a i q_i,a_i qi,ai)对。接下来,将问题和逐步推理链以及最终答案追加到提示中。这最后的链条作为解决问题的解释。根据数据集(§4.1),元推理模块被提示6-10个示例。
通过提供多个链条给元推理模块,它可以将跨链条的事实进行组合和聚合。此外,模型需要从链条中提取最相关的事实作为其解释。这使得MCR比过去的多链方法更准确、更可解释(正如我们在第5节中所分析的)。
4 实验
我们将MCR与现有方法在7个多跳QA基准测试上进行了比较。这些基准测试涵盖了广泛的推理技巧,包括常识推理、组合推理、比较和事实验证。在使用两种不同的LLM和检索器进行实验时,MCR在所有基准测试上都一致优于现有方法。我们的设置在第4.1节中描述,主要结果在第4.2节中讨论。
4.1 实验设置
4.1.1 数据集
由于我们关注的是多跳问题(在开放域环境下),所有数据集都需要多个推理步骤。我们遵循之前的工作并为了限制模型API调用的成本,从每个数据集的开发集中随机选择500-1000个示例进行评估。此外,我们还在STRATEGYQA和FERMI的官方测试集上进行评估,因为它们针对隐含推理,具有多个有效策略,并且测试集的评估成本合理。对于所有数据集,确保我们的提示中不包含任何评估问题。

表1中列举了每个数据集的示例问题。我们的多跳QA基准测试可以根据所需的推理技能进行分类:
隐含推理: 需要隐含推理步骤的问题(Geva等,2021年)。解决这类问题的推理步骤不能从问题的语言中明确推导出来,需要常识或算术推理。这类问题可能有多个有效的推理链。我们在以下数据集上进行评估:STRATEGYQA和QUARTZ。
显式推理: 多跳问题,其中推理步骤在问题的语言中明确表达(组合、比较)。这包括HOTPOTQA、2WIKIMQA和BAMBOOGLE。我们还在FEVEROUS上进行评估,这是一个事实验证数据集,其中的主张需要验证多个事实,证据可以是句子、表格或两者兼有。
在评估中,使用F1来比较预测答案和真实答案,适用于所有显式推理数据集,并使用精确匹配来评估二选一的数据集。在FERMI中,我们使用Kalyan等人(2021年)的官方数量级评估方法。关于评估的其他技术细节,请参见附录A。

4.1.2 方法
主要模型和基线都是检索增强的代码-davinci-002实例,其使用上下文学习示例来作为提示。在第4.3节中,还使用了开源的Vicuna-13B LLM进行了额外的实验。提示示例按照第3.2节中描述的格式进行格式化。示例的数量在不同数据集之间为6到12个不等。分解提示示例基于训练集和开发集中的随机示例,以及它们的黄金推理链。对于元推理器示例,使用从分解模型中采样的推理链作为多链上下文。确保可以使用采样的链推断答案,并在最终答案之前添加解释,如图4所示。对于二元选择数据集STRATEGYQA、QUARTZ和FEVEROUS,提示中包含相同数量的每个标签的示例。有关完整提示的详细信息,长度统计和对不同提示选择的鲁棒性,请参阅第D节。
元推理器: 尝试了两种元推理器的变体,以衡量对多个推理链进行推理的效果。
MCR: 元推理器的多链上下文给出了五个推理链(第3.2节)。使用贪婪解码解码一个链条,并使用温度t=0.7采样另外四个推理链。这使得元推理器在回答完整问题时可以回顾不同的证据片段(第5节)。
SCR: 单链推理(SCR)用作多链上下文效果的消融实验。在SCR中,元推理器与MCR相同的提示,除了其上下文中只有贪婪解码的链条。这将多链的使用效果与将LLM与分解模型分离生成最终答案的效果分离开来。
基线: 评估以下基线:
-
SA: 自问自答(Press等人,2022)返回使用贪婪解码生成的单个推理链的答案。
-
SC: 自一致性作为基线,结合了多个推理链(Wang等人,2023)。它基于从分解模型中采样的多个链条的多数答案返回结果。我们尝试了3、5和15个采样链条的变体(SC@3、SC@5和SC@15),与先前的工作(Wang等人,2023;Khattab等人,2022;Sun等人,2023)保持一致。与MCR类似,我们使用贪婪解码生成的链条以及使用t=0.7采样的额外链条。
检索: 与Press等人、Lazaridou等人和Paranjape等人类似,我们的模型和基线使用基于Google搜索的检索器,通过SerpAPI服务进行检索。然而,在第4.3节中,我们还使用了开源的检索器。由于我们的大多数数据集包含来自维基百科的证据(第4.1.1节),我们将其作为我们的检索语料库。因此,我们将搜索查询格式化为“en.wikipedia.org qi”,其中维基百科域名在中间问题之前。返回Google检索到的排名第一的证据。检索到的证据可以是句子或解析列表。根据Trivedi等人的方法,我们还为原始问题q检索证据。最后,所有检索到的证据句子都被添加到分解模型中(第3.1节)。