Linux内核有什么之内存管理子系统有什么第六回 —— 小内存分配(4)
接前一篇文章:Linux内核有什么之内存管理子系统有什么第五回 —— 小内存分配(3)
本文内容参考:
linux进程虚拟地址空间
《趣谈Linux操作系统 核心原理篇:第四部分 内存管理—— 刘超》
特此致谢!
二、小内存分配 —— brk与sbrk
上一回在讲sys_brk函数代码的时候,讲到了struct vm_area_struct,本回对于此结构体进行详细解析。
1. brk源码解析
为了便于理解,再次贴出vm_area_struct结构相关代码。struct vm_area_struct的定义也是在include/linux/mm_types.h中,代码如下:
/*
* This struct describes a virtual memory area. There is one of these
* per VM-area/task. A VM area is any part of the process virtual memory
* space that has a special rule for the page-fault handlers (ie a shared
* library, the executable area etc).
*/
struct vm_area_struct {
/* The first cache line has the info for VMA tree walking. */
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address
within vm_mm. */
struct mm_struct *vm_mm; /* The address space we belong to. */
/*
* Access permissions of this VMA.
* See vmf_insert_mixed_prot() for discussion.
*/
pgprot_t vm_page_prot;
unsigned long vm_flags; /* Flags, see mm.h. */
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap interval tree.
*
* For private anonymous mappings, a pointer to a null terminated string
* containing the name given to the vma, or NULL if unnamed.
*/
union {
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} shared;
/*
* Serialized by mmap_sem. Never use directly because it is
* valid only when vm_file is NULL. Use anon_vma_name instead.
*/
struct anon_vma_name *anon_name;
};
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
struct list_head anon_vma_chain; /* Serialized by mmap_lock &
* page_table_lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops;
/* Information about our backing store: */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units */
struct file * vm_file; /* File we map to (can be NULL). */
void * vm_private_data; /* was vm_pte (shared mem) */
#ifdef CONFIG_SWAP
atomic_long_t swap_readahead_info;
#endif
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
struct vm_userfaultfd_ctx vm_userfaultfd_ctx;
} __randomize_layout;根据函数说明,vm_area_struct结构描述了一个虚拟内存区域,每个VM区域/任务都有一个此结构。VM area(虚拟内存区域)是进程虚拟内存空间的任何部分,其具有用于页面错误异常处理(page-fault handlers)的特殊规则(即共享库、可执行区域等)。
要想完全弄清楚这个结构,只靠函数注释的寥寥数语是远远不够的,需要补齐相关知识,这就要“从头说起”而“说来话长”了。所谓“从头说起”,要从哪里说起?要由打Linux进程虚拟地址空间说起。
在多任务操作系统中,每个进程都运行在属于自己的内存沙盘中,这个沙盘就是虚拟地址空间(Virtual Address Space)。以32位系统为例,在32位模式下它是一个4GB的内存地址块。在Linux系统中,内核进程和用户进程所占的虚拟内存比例是1:3(比例可调整),而Windows系统则为2:2(通过设置Large-Address-Aware Executables标志也可为1:3)。然而,这并不意味着内核使用那么多物理内存,仅表示它可支配这部分地址空间,根据需要将其映射到物理内存。
Linux进程在虚拟内存中的标准内存段布局如下图所示:
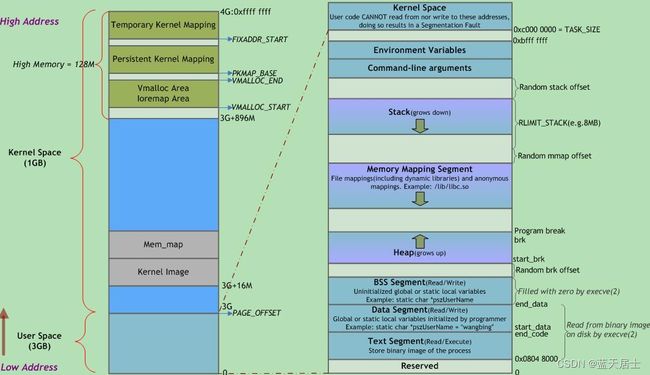
注:
(1)用户地址空间中的蓝色条带对应于映射到物理内存的不同内存段,浅黄绿色区域表示未映射的部分;
(2)Random stack offset和Random mmap offset等随机值意在防止恶意程序。Linux通过对栈、内存映射段、堆的起始地址加上随机偏移量来打乱布局,以免恶意程序通过计算访问栈、库函数等地址。
由上图可以看到,虚拟地址空间整体被划分为用户空间(User Space)和内核空间(Kernel Space)两大部分。当前我们重点关注用户空间部分。
用户进程部分内存区域(分段存储内容)主要可以分为以下几个部分(按地址由低到高递增顺序):
- 保留区域(Reserved)
位于虚拟地址空间的最低部分,未赋予物理地址。任何对它的引用都是非法的,用于捕捉使用空指针和小整型值指针引用内存的异常情况。它并不是一个单一的内存区域,而是对地址空间中受到操作系统保护而禁止用户进程访问的地址区域的总称。大多数操作系统中,极小的地址通常都是不允许访问的,如NULL。C语言将无效指针赋值为0也是出于这种考虑,因为0地址上正常情况下不会存放有效的可访问数据。
在32位x86架构的Linux系统中,用户进程可执行程序一般从虚拟地址空间0x08048000开始加载。该加载地址由ELF文件头决定,可通过自定义链接器脚本覆盖链接器默认配置,进而修改加载地址。0x08048000以下的地址空间通常由C动态链接库、动态加载器ld.so和内核VDSO(内核提供的虚拟共享库)等占用。通过使用mmap系统调用,可访问0x08048000以下的地址空间。
- 代码段(Code Segment / Text Segment)
代码段也称正文段或文本段,通常用于存放程序执行代码(即CPU执行的机器指令)。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读(某些架构也允许代码段为可写,即允许修改程序)。
在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。也就是说,代码段存储的内容包括:可执行代码、字符串字面值、只读变量。
- 数据段(Data Segment)
数据段通常用于存放程序中已初始化且初值不为0的全局变量和静态局部变量。数据段属于静态内存分配(静态存储区),可读可写。
数据段保存在目标文件中(在嵌入式系统里一般固化在镜像文件中),其内容由程序初始化。
- BSS段(Block Started by Symbol Segment)
BSS段通常用于存放以下内容:
- 未初始化的全局变量和静态局部变量;
- 初始值为0的全局变量和静态局部变量(依赖于编译器实现);
- 未定义且初值不为0的符号(该初值即common block的大小)。
在C语言中,未显式初始化的静态分配变量被初始化为0(算术类型)或空指针NULL(指针类型)。由于程序加载时,BSS会被操作系统清零,所以未赋初值或初值为0的全局变量都在BSS中。
注:
尽管均放置于BSS段,但初值为0的全局变量是强符号,而未初始化的全局变量是弱符号。若其它地方已定义同名的强符号(初值可能非0),则弱符号与之链接时不会引起重定义错误,但运行时的初值可能并非期望值(会被强符号覆盖);
数据段与BSS段的区别如下:
1)BSS段不占用物理文件尺寸,但占用内存空间;数据段占用物理文件,也占用内存空间;
2)当程序读取数据段的数据时,系统会出发缺页故障,从而分配相应的物理内存;当程序读取BSS段的数据时,内核会将其转到一个全零页面,不会发生缺页故障,也不会为其分配相应的物理内存。
- 堆(Heap)
堆用于存放进程运行时动态分配的内存段,其大小并不固定,可动态扩张或缩减。堆中内容是匿名的,不能按名字直接访问,只能通过指针间接访问。
当进程调用malloc(C)/ new(C++)等函数分配内存时,新分配的内存动态添加到堆上(扩张);当调用free(C)/ delete(C++)等函数释放内存时,被释放的内存从堆中剔除(缩减)。
堆的末端由break指针标识,当堆管理器需要更多内存时,可通过系统调用brk()和sbrk()来移动break指针以扩张堆,一般由系统自动调用。
- 栈(Stack)
栈又称堆栈,由编译器自动分配释放,行为类似数据结构中的栈(先进后出、后进先出)。堆栈主要有三个用途:
- 为函数内部声明的非静态局部变量(C语言中称“自动变量”)提供存储空间;
- 记录函数调用过程相关的维护性信息,称为栈帧(Stack Frame)或称为过程活动记录(Procedure Activation Record)。其包括:函数返回地址、不适合装入寄存器的函数参数及一些寄存器值。除递归调用外,堆栈并非必需。因为编译时可获知局部变量、参数和返回地址所需空间,并将其分配于BSS段;
- 临时存储区,用于暂存长算术表达式部分计算结果或alloca()函数分配的栈内内存。
由于后进先出(LIFO)的特点,栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。
############################################################################
补充知识:堆与栈的区别
1)管理方式
栈由编译器自动管理;
堆由程序员控制,使用方便,但易产生内存泄露。
2)生长方向
栈向低地址扩展(即“向下生长”),是连续的内存区域;
堆向高地址扩展(即“向上生长”),是不连续的内存区域。
3)空间大小
栈顶地址和栈的最大容量由系统预先规定(通常默认2MB或10MB);
堆的大小则受限于计算机系统中有效的虚拟内存,32位Linux系统中堆内存可达2.9G空间。
4)存储内容
栈在函数调用时,首先压入主调函数中下条指令(函数调用语句的下条可执行语句)的地址,然后是函数实参,然后是被调函数的局部变量。本次调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的指令地址,程序由该点继续运行下条可执行语句;
堆通常在头部用一个字节存放其大小,堆用于存储生存期与函数调用无关的数据,具体内容由程序员安排。
5)分配方式
栈可静态分配或动态分配。静态分配由编译器完成,如局部变量的分配;动态分配由alloca函数在栈上申请空间,用完后自动释放;
堆只能动态分配且手工释放。
6)分配效率
栈由计算机底层提供支持。分配专门的寄存器存放栈地址,压栈出栈由专门的指令执行,因此效率较高;
堆由函数库提供,机制复杂,效率比栈低得多。
7)分配后系统响应
只要栈剩余空间大于所申请空间,系统将为程序提供内存,否则报告异常提示栈溢出;
操作系统为堆维护一个记录空闲内存地址的链表。当系统收到程序的内存分配申请时,会遍历该链表寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点空间分配给程序。若无足够大小的空间(可能由于内存碎片太多),有可能调用系统功能去增加程序数据段的内存空间,以便有机会分到足够大小的内存,然后进行返回。
8)碎片问题
栈不会存在碎片问题,因为栈是先进后出的队列,内存块弹出栈之前,在其上面的后进的栈内容已弹出;
而堆则存在碎片问题,因为频繁申请释放操作会造成堆内存空间的不连续,从而造成大量碎片,使程序效率降低。
############################################################################
在应用程序加载到内存空间执行时,操作系统负责代码段、数据段和BSS段的加载,并在内存中为这些段分配空间。栈也由操作系统分配和管理;堆由程序员自己管理,即显式地申请和释放空间。

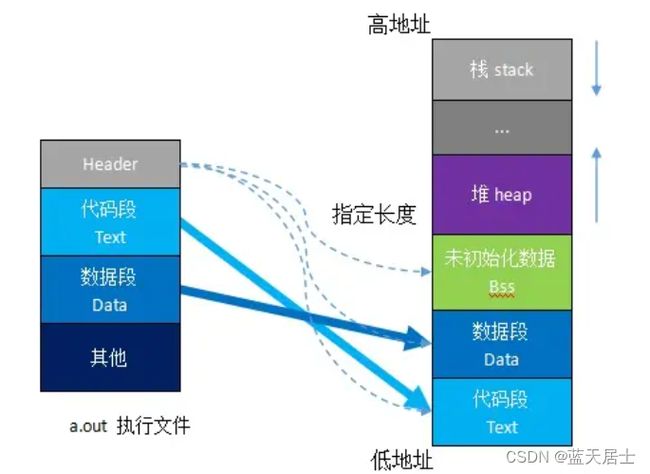
经过了这么一大段“倒序”即所谓的“说来话长”,终于回到正题。此时再来看结构体注释,是不是种豁然开朗的感觉?
vm_area_struct结构描述了一个虚拟内存区域,每个VM区域/任务都有一个此结构。VM area(虚拟内存区域)是进程虚拟内存空间的任何部分,其具有用于页面错误异常处理(page-fault handlers)的特殊规则(即共享库、可执行区域等)。
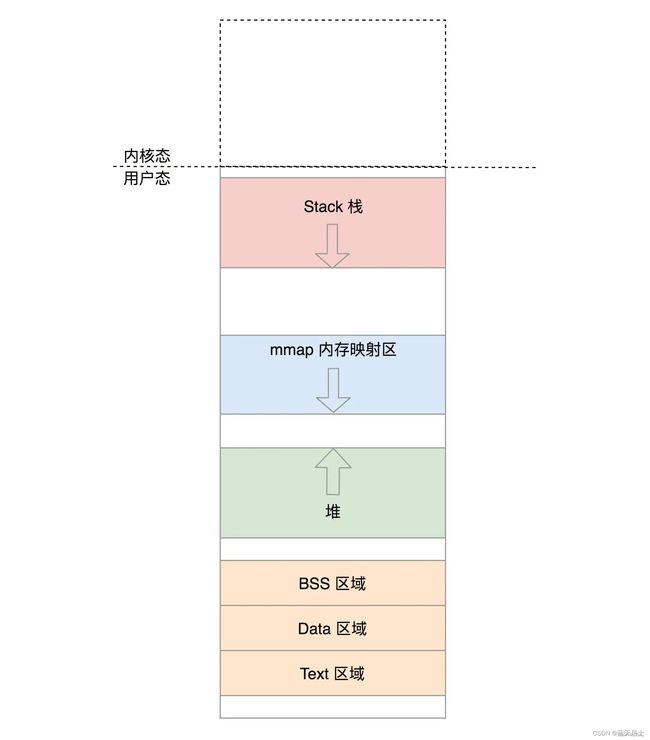
说得更明白一些,就是每个vm_area_struct结构对应于虚拟内存空间中的唯一虚拟内存区域 VMA。虚拟内存区域就是上边的代码段(Text区域)、数据段(Data区域)、BSS段(BSS区域)、堆、栈等,它们每一个都对应一个唯一的vm_area_struct结构(实例)。如下图所示:
这样就弄清楚了vm_area_struct结构的总体意义,关于其成员的详细解析,请看下回。
来看具体成员:
- unsigned long vm_start
vm_mm内的起始地址。
- unsigned long vm_end
vm_mm结束地址后的第一个字节。
vm_start和vm_end指定了该区域在用户空间中的起始地址和结束地址。
- struct mm_struct *vm_mm
所属的地址空间。