单一职责原则(SRP)
什么是单一职责原则
单一职责原则(英文名为Single Responsibility Principle,简称SRP)是Robert C. Martin提出的SOLID软件设计原则中的第一个字母S。
Robert C. Martin给出的定义为, 有且仅有一个原因导致类的变化。
A class should have one, and only one, reason to change.
而本人更偏向于Wiki上对SRP的描述, 其单一职责原则应该运用于模块, 类以及文件。
The single-responsibility principle (SRP) is a computer-programming principle that states that every module, class or function in a computer program should have responsibility over a single part of that program’s functionality, and it should encapsulate that part.
首先说一说职责, 如果说直接从软件说起来,还是比较抽象的。那我打算从生活中的其他可见的方面来说一说。
比如写一本小说,可能会分成3部,每一部讲述一段完整的故事,而每一部完整的故事,又有一系列单独的场景片段拼接起来,推动着故事的发展, 各个场景之间相互独立,又关联在一起。
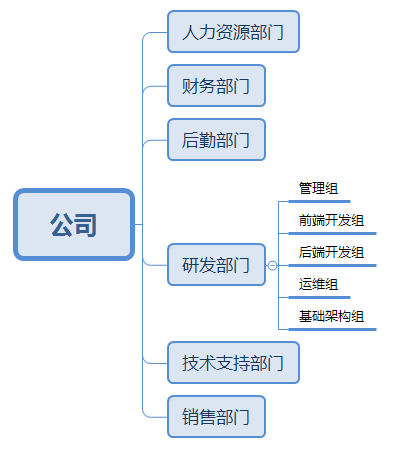
再比如说一个公司,可能由人力资源部,后勤部门,财务部门,研发部门,技术支持部门以及销售部门组成。每个部门都可以认为有着自己的单一职责,而每个部门之间都不是互相孤立有着联系,比如技术支持部门解决不了的问题会寻求研发部门的协助,研发部门会和人力资源部门合作进行技术人员招聘,人力资源部门会和财务部门进行工资结算,后勤部门会保证各个部门的后勤工作得到妥善的安排。从公司层面看,研发部门有自己的单一职责负责产品的研发相关的任务。而从研发部门内部来看,我们又可以将其划分为管理组,测试组,开发组,运维组。然后开发组可能有分为前端组,后端组,基础架构组等,每一个小组也都有着自己的单一职责。我们从不同的角度看,似乎可以进行不同维度的单一职责的划分。那么比如主要专注于后端开发这个单一职责的后端开发组,有两个人互换了不同的模块开发,其实对于其他的组来说基本是没有太多的影响和变化的。我们的软件开发也是如此,当你进行一个产品/项目开发的时候,是不是也是类似于从上而下的进行职责划分,从模块,到代码文件,到类,到每一个函数的的实现,每一个层级都有着自己的单一职责原则;并且这个原则可以让我们的程序在修改时带来更少的副作用,也便于更好做程序扩展。
本文以一个采用C++开发的样例项目为例:假设有这样一个项目,客户端需要开发一个PC端的Windows UI程序, 该程序可以从一个服务器定期获取数据,并且存储在本地后,UI程序可以对存储的数据进行展示。
那么我们将从项目架构,模块,源文件,namespace, 类,以及函数几个方面来阐述单一职责原则,并且在文末进行总结。
单一职责原则之项目架构
当分析这个需求后,我们可以画出这样一个图, 首先从项目需求方面出发,将其功能进行职能划分, 如下图:
- 数据处理功能部分,从某个服务定时拉取最新的数据,进行处理后,存储到数据库
- UI数据展示,将从数据库读取数据进行展示,可以进行条件搜索
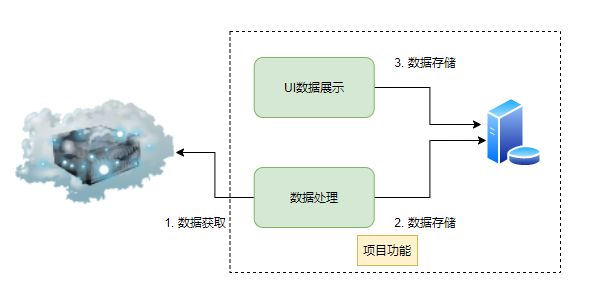
如果这个需求比较简单,我们假设先不考虑工期,那么可能有两种方案:
- 方案1:
UI数据展示功能和数据处理功能都放在一个进程内部 - 方案2:
UI数据展示功能和数据处理功能分别实现为两个进程
先说方案1, 两个模块之间不需要直接的交互,通过数据库进行了间接的交互。这种设计可能带来两个问题:
- 两个模块可能会出现互相影响。比如
UI数据展示相关的模块出现Crash,也会导致数据处理模块停止工作,反之亦然。 更比如编写C++,可能出现堆内存溢出问题,如果数据处理部分部分处理时产生内存溢出,踩到了UI数据展示功能部分的对象所在内存,那么可能追查原因也变的更加复杂。 - 两个功能模块都在同一个进程中,在使用过程中必须共进退。那么部署使用也会存在问题,比如当你做了
UI数据展示
功能的一些修复后,在做更新的时候,数据处理功能部分,一般也需要停止工作。或者说当你关闭UI退出的时候,数据处理也随之停止了。
从职能上说这两个功能完全可以通过不同的进程隔离开来,做成两个进程,我们可以做到有如下优势:
- 两个功能可以完全由不同的人去开发,甚至是不同的技术栈的人。比如
数据处理功能部分,需要和服务器交互,数据处理,以及和DB的一些操作,那么这个人员可以选择Java,Golang等等,可以提高其开发效率。 - 两个进程互不干扰,你甚至可以分布在不同的机器上,不同的操作系统。而且
数据处理可以单独做成一个服务,不用随着UI数据展示窗口关闭而停止数据更新了。 - 后续的程序更新维护也互不影响,并且问题追踪,也将更容易定位。
根据其需求功能的角度出发,对其职责进行划分,我们将其从架构层面可以分为两个部分: 数据处理部分采用Windows服务进程,而UI数据展示部分采用程序员所熟悉的图形库进行开发, 其结构如下:
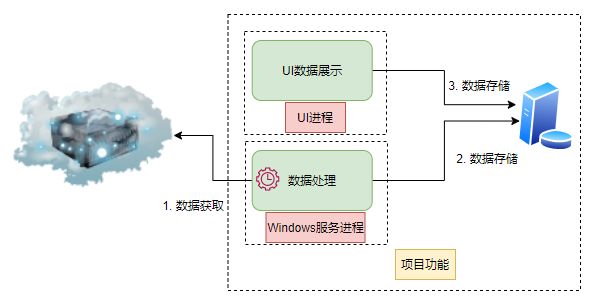
当然以上内容都是可以讨论的,如果领导和你说,1个人开发,5天代码完成,1天测试,那么请不要纠结单一职责原则。
单一职责原则之模块划分
在上学时候,当我我第一次见到真实运转的项目代码的时候,才知道原来一个程序真的需要划分为多个Libary来进行调用。也就是说会将一些独立功能的模块单独的组织在一起,编译生成DLL/SO文件,让其他模块可以进行调用。
我以Visual Studio的工程为例, Visual Studio的组织结构最上层的叫做解决方案,也就是保存为sln的文件,然后可以在解决方案中增加项目, 而每一个项目可以编译/链接生成为一个可执行程序(exe),动态链接库(dll),静态库(lib) 等。
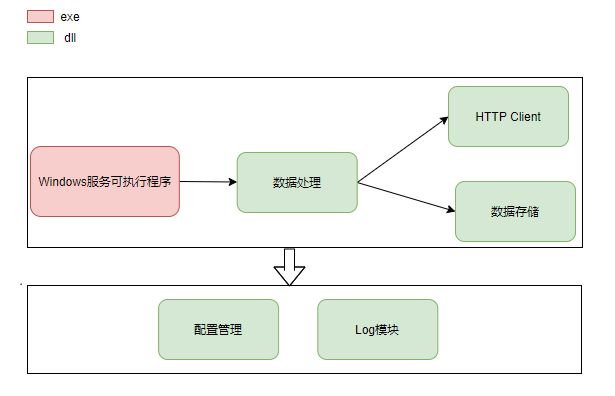
如果我们要做这个数据处理的程序,需要至少具备以下几个模块:
- Log 模块用于调试
- 获取数据,假设这里是HTTP接口获取程序
- 数据存储: 在预处理后的数据,进行数据存储,和数据库打交道的部分
- 数据操作: 组合了比如数据获取,数据预处理,以及数据存储
- 配置文件管理: 一般程序均有一个配置文件,可以控制一些参数(比如可能数据处理过程中需要一些参数)
- windows服务可执行程序
如果我们将上面6个功能全部存放在一个项目中,那就是违背了单一职责原则。比如你想对数据存储部分做一些小的改动,但数据存储所提供的接口并不改动的情况下,那会导致整个项目都需要进行编译,生成新的可执行程序。而如果将数据存储剥离成独立的项目,以动态链接库的方式提供其方法,将会有以下几个好处:
数据存储提供的接口不发生变化的情况下,只需要编译改动的项目,并且替换的时候,只需要替换当前改动的动态链接库或者可执行文件- 当如果未来需要扩展,有个新的应用程序(比如测试程序),也需要
数据存储相关的功能后,就不必编写相同的代码,直接依赖于这个数据存储项目,并通过调用动态链接库的方式使用其提供的方法。 - 维护人员也可以更容易的对代码进行维护,结构清晰,不是所有的东西都柔和在一个工程中。
其模块关系大致如下图:
当然了以上也并不是说一定是最符合单一职责原则的场景,我们重在理解遵循单一职责原则去划分不同的模块。否则讨论就容易变成谁是世界上最好的语言问题一样,哈哈。
同理我们对于模块的划分,我们也可以将其保存在不同的目录文件中,除此之外,Visual Studio也提供了,即使是同一个工程下的文件,也可以用Filter对源文件进行逻辑划分,如下图是Poco的Net库的工程:
那么对于UI数据展示模块也就不必赘述了。
单一职责原则之源文件
上一章节也有提到,C++中的源文件可以通过项目进行管理,也可以设置Filter,同样可以根据不同的功能将其放置在不同的目录。
组织.cpp和.h文件一般需要:
- 将紧密相关的类/函数放置在同一个文件中,大多数情况下你可能注意到很多第三方库的实现是一个
.h中声明了一个class。这个不是绝对的,也可以一个头文件中存放多个class,我们其实主要理解,不要将大多数相对复杂的类,都防止在同一个文件中进行声明或者实现,可以将其拆分为多个文件保存。 - 还有时候经常碰到的问题是,当你在做类的实现的时候,会需要一些比较通用的实现:比如一些字符串常见的
trim,大小写转换之类的,有时候就顺手写在了这个.cpp文件中。但如果其他cpp文件或者项目模块中也需要这一类的辅助操作呢,就容易造成重复的实现。应该做的是将这些通用实现都放到专门处理string的模块中。 - 头文件中一般会声明一些类或者函数等,也会存在宏定义或者枚举之类的。有时候会出现的问题是,比如一个头文件包含了类的声明,类依赖于一些其他的类型,所以也在
include中包含了这些依赖;如果头文件中还含有一些枚举类型,而此时你需要在另一个模块中引用这个头文件,并且只需要用到里面的枚举类型,对于其他的类声明并不关心,但会因为头文件中类对其他的头文件的依赖,需要对当前的模块也进行一些依赖配置,但这些是多余的。那么就可以将这些枚举类型,剥离出一个新的头文件进行存储。
说到这里就不得不吐槽一下,C++经常要写.h头文件中声明,然后.cpp做实现,比起C#这种只要写.cs文件来说麻烦许多。
单一职责之namespace, 类和方法
之所以把这三个放到一起说,是因为都已经属于代码层面。
先说说namespace, 本意是防止命名空间污染问题,而从另一个角度看,namespace也可以看做是模块划分的一种方式。比如C++标注库, boost, Poco等都使用了namespace,并且有不同的命名空间比如std::chrono用于时间处理相关的, Poco::Net用于网络处理相关的。
然后再来说说类,也是大多数文章提到类的单一职责原则。这些当然也扩展到其他语言的接口,或者C++的纯虚函数。我们来继续按照这个项目来看看其中一个糟糕的样例: 比如数据处理功能部分,设计了一个类DataProcess被服务调用实现了三个方法:
- QueryData: 用于从服务器定期获取数据
- HandleData: 对获取的数据进行一些验证,和一些预处理
- StoreData: 将数据存储到数据库
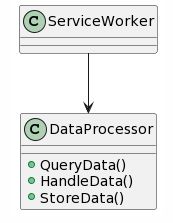
这样设计是违背单一职责原则的,因为可能会发生以下情况:
- 如果说
QueryData中从服务器端请求的格式发生了变化,其实这个并不应该影响到HandleData和StoreData, 因此他是可以剥离开来,专注于数据获取的操作 - 如果说
StoreData数据存储的位置发生了变化,比如从SQLServer切换到Mysql, 也不应该影响到QueryData和HandleData部分,其也可以剥离开来,专注于数据存储相关的操作。
那我们按照单一职责原则对其重新进行划分设计如下: 虽然图中的类只有一个方法,实际上在实现的时候会有很多的私有方法。而ServiceWorker像搭积木一样把这些类的功能组装起来,完成任务!
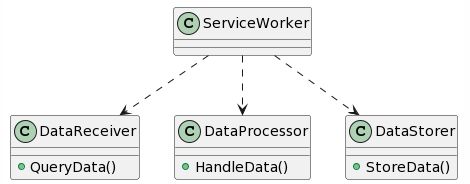
关于函数的单一职责划分也和类类似,我这里举一个不一样的,并且容易犯错误的例子。还是拿数据处理作为样例,假设获取的数据类似于如下:
{
"field1": "key1=value1;key2=value2;key3=value3",
"field2": "abc"
}
如果在DataProcessor内部有个私有函数叫做 ParseData负责解析这个数据:
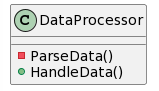
这个时候的函数样式类似于 (只是示例,并不是可编译的代码)如下,但是对于field1中我们目前只需要获取key3的值。
DataObjectPtr DataProcessor::ParseData(const JsonData& data)
{
DataObjectPtr obj(new DataObject);
obj->m_filed_2 = data["field2"];
// 这里对data["field1"]进行字符串处理若干
// 通过字符串查找先找到`;key3`的位置然后进行处理
// 假设写了10来行
return obj;
}
这个示例会存在什么问题,就是将field1字段的处理流程放置在了ParseData中,那么可能对未来扩展存在如下问题:
- 如果没有特别的性能要求,未来很可能会对
key1,key2的值同样需要解析出来,那么在这里更适合的方式是将所有的key=value都解析成map存放起来,便于访问。 单一职责原则应该将field1字段解析过程独立成一个函数;假设这个时候来了一个field3也是这种key=value的形式,则可以复用这个独立的函数去实现。
例子简单,可能觉得不会有问题,但是当你的业务相对复杂,本身函数体已经比较大的情况下,很容易出现这样的错误编程方式,从而使得函数体越来越臃肿,也越来越难维护,重构的成本也越来越高。
总结
最后引用Robert C. Martin的一段话:
What do I mean by “Principle”
The SOLID principles are not rules. They are not laws. They are not perfect truths. The are statements on the order of “An apple a day keeps the doctor away.” This is a good principle, it is good advice, but it’s not a pure truth, nor is it a rule.
这些原则并不是真理,而是一些从实践中得到的一些经验,让你远离未来可能碰到的麻烦。
单一职责原则的职责划分,每个人对于不同的业务和实现都有着自己的理解,而且项目也有着截止日期的约束,千万不要让原则束缚住我们,按照要求发布符合质量的产品是第一位的。
世界上不是只有好与坏,我们很难用一个好或坏去界定所有的东西;但也要记住我们要懂得什么是好,什么是坏。
本文也只是个人的一些总结,欢迎大家一起讨论,一起进步。
参考
这部分主要是列举了一些在文章编写时候,看过的书籍或者网站:
[1]: 秦小波的<<设计模式之禅>>
[2]: Robert C. Martin的<<架构整洁之道>> (孙宇聪 译)
[3]: Wikipedia: Single-responsibility principle