Slurm.conf配置文件
Slurm配置文件
配置文件示例
slurm.conf是Slurm的核心配置文件,它描述了一般的Slurm 配置信息、要管理的节点、有关 如何将这些节点分组到分区中,以及各种调度 与这些分区关联的参数。该配置文件在群集中的所有节点上保持一致。如果修改了slurm.conf相关配置文件,诸如slurmctld端口等,需要使用scontrol reconfigure重新配置。(注意:slurm.conf是不区分大小写的,但是节点和分区名称除外。)常见的配置文件实例如下:
##
## This file is maintained by Ansible - ALL MODIFICATIONS WILL BE REVERTED
##
# Configuration options
AccountingStorageHost=192.168.29.136
AccountingStoragePass=/var/run/munge/munge.socket.2
AccountingStorageType=accounting_storage/slurmdbd
AccountingStorageUser=slurm
AuthAltParameters=jwt_key=/etc/slurm/jwt_hs256.key
AuthAltTypes=auth/jwt
AuthInfo=/var/run/munge/munge.socket.2
AuthType=auth/munge
ClusterName=cluster
ControlMachine=master
CryptoType=crypto/munge
FastSchedule=1
JobCompType=jobcomp/none
ProctrackType=proctrack/pgid
SchedulerType=sched/backfill
SelectType=select/cons_tres
SelectTypeParameters=CR_Core_Memory
SlurmctldDebug=3
SlurmctldLogFile=/var/log/slurm/slurmctld.log
SlurmctldPort=6817
SlurmdDebug=3
SlurmdLogFile=/var/log/slurm/slurmd.log
SlurmdPort=6818
SlurmdSpoolDir=/var/spool/slurm/slurmd
SlurmdUser=root
SlurmUser=slurm
StateSaveLocation=/var/lib/slurm/slurmctld
# Nodes
NodeName=node1 CPUs=4 RealMemory=1819 State=UNKNOWN
NodeName=node2 CPUs=4 RealMemory=1819 State=UNKNOWN
# Partitions
PartitionName=debug Default=YES MaxTime=INFINITE Nodes=node1,node2 State=UP
常规参数
- AccountingStorageBackupHost
保存存储数据库的备份主机的名称。 如果与account _ storage/slurmdbd 插件一起使用,备份 slurmdbd 将在备份主机中运行。
- AccountingStorageExternalHost
表示需要注册的外部slurmdbd(
- AccountingStorageHost
存储数据库的主机,当且尽在使用slurmdbd的机器上存在
-
AccountingStorageParameters
- SSL_CERT:客户端公钥证书文件的路径名
- SSL_CA:证书颁发机构 (CA) 证书文件的路径名
- SSL_CAPATH:包含受信任的 SSL CA 证书文件的目录的路径名。
- SSL_KEY:客户端私钥文件的路径名。
- SSL_CIPHER:SSL 加密允许的密码列表。
-
AccountingStoragePass
用于访问数据库以存储密码,对于具有 Munge 身份验证的 Slurmdbd ,可以将其配置为使用专门的Munge守护进程来提供集群之间的身份验证,而默认的 MUNGE 守护进程提供集群内的身份验证。在这种情况下,AccountingStoragePass 应该指定用于与备用 Munge守护进程通信的命名端口(例如**“/var/run/MUNGE/global.socket. 2”**),默认是NULL。
- AccountingStoragePort
记账存储数据库服务器的侦听端口。
- AccountingStorageTRES
表示可追踪的资源列表,包括CPU,GPU,内存等。也可以设置只追踪特定类型的资源列表,如AccountingStorageTRES = gres/GPU,gres/GPU: tesla,gres/GPU: volta,那么只会追踪Tesla和Volta架构的GPU资源。
- AccountingStorageType
记账存储机制类型。目前可接受的值包括**“account _ Storage/none”和“account _ Storage/slurmdbd”。“ account _ Storage/slurmdbd”**值表示会计记录将写入 Slurmdbd。
- AccountingStorageUser
用于访问记帐存储数据库的用户帐户。
- AcctGatherInterconnectType
标识用于互连网络流量计算的插件。Jobacct _ together 插件和 slurmd 守护进程调用这个插件来收集作业和节点的网络流量数据。
- AcctGatherFilesystemType
标识用于文件系统流量计算的插件。Jobacct _ together 插件和 slurmd 守护进程调用这个插件来收集作业和节点的文件系统流量数据。
- AcctGatherProfileType
标识用于详细作业分析的插件。Jobacct _ together 插件和 slurmd 守护进程调用这个插件来收集详细的数据,比如作业和节点的 I/O 计数、内存使用或能量消耗。(注意:只有在独占作业分配的情况下,在节点级别收集的数据才与作业相关。)
- AuthAltTypes
Slurmctld 允许通信的替代身份验证插件的以逗号分隔列表。目前可接受的值包括 auth/jwt。Auth/jwt 可以通过 SLURM_ JWT 环境变量激活。激活后,它将重写默认的 AuthType。Auth/jwt 需要一个 jwt _ hs256。只能在 slurmctld 的 StateSaveLocation 目录中填充。Jwt _ hs256.键应该只对 SlurmUser 和 root 可见。
-
AuthAltParameters:用于定义可选的身份验证插件选项。
- disable_token_creation:禁止非 SlurmUser 帐户使用“ scontrol token”。
- max_token_lifespan=xxx(seconds):设置最大生命周期
- jwt_key=:JWT 密钥文件的绝对路径。密钥必须是 HS256,并且只能由 SlurmUser 访问。
-
AuthInfo
用于认证 Slurm 守护进程(slurmctld 和 slurmd)和 Slurm 客户端之间的通信的附加信息。此选项的解释特定于配置的 AuthType。
- cred_expire:默认的作业步骤凭据生命周期,单位是秒。
- socket:要使用的 MUNGE 守护套接字的路径名(例如**“socket =/var/run/MUNGE/MUNGE.socket. 2”**)。
- ttl:凭证生存期,以秒为单位。
-
AuthType
Slurm 组件间通信的认证方法。目前可接受的值包括“ auth/munge”,表示将使用 Munge。
- BatchStartTimeout
批作业在被认为丢失并释放分配之前允许启动的最长时间(以秒为单位)。如果执行Prolog、加载用户环境变量或者 slurmd 守护进程从内存中分页,则可能需要更大的值。
-
BcastParameters:控制 sbcast 和 srun的 ——bcast 行为。
- DestDir=:将文件广播到分配的计算节点的目标目录,默认当前目录
- Compression=:指定要使用的默认文件压缩库。支持的值是“ lz4”和“ none”。
- send_libs:尝试自动检测并将可执行文件的共享对象依赖关系广播到分配的计算节点。
-
CliFilterPlugins:以逗号分隔的命令行界面选项展示插件列表,指定的插件将按照列出的顺序执行。
- cli_filter/lua:这个插件允许使用 lua 编写自己的 cli_filter 实现。
- cli_filter/syslog:这个插件支持记录所执行的作业提交活动。所有 salloc/sbatch/srun 选项都以 JSON 格式与环境变量一起记录到 syslog 中。
- cli_filter/user_defaults:这个插件查找文件 $HOME/.slurm/default 并将其中的每一行读取为 key = value 对,其中 key 是 salloc/sbatch/srun 可用的任何作业提交选项,value 是用户定义的默认值。
-
ClusterName
Slurm 管理集群在数据库中的名称。
-
CommunicationParameters:通信选项列表
- block_null_hash:要求所有 Slurm 身份验证令牌都包含一个更新的(20.11.9和21.08.8版本)有效负载。
- DisableIPv4:禁用所有 slurmdbd 守护进程的 IPv4操作(slurmdbd 除外)
- EnableIPv6:允许对所有 slurmdbd 守护进程使用 IPv6地址(slurmdbd 除外)。同时使用 IPv4和 IPv6时,地址族首选项将基于您的/etc/gai.conf 文件。
- keepaliveinterval=#:指定 srun 与其 slurmstep 进程之间套接字通信上的 keepalive 探测之间的间隔。
- keepaliveprobes=#:指定在认为连接中断之前,在 srun 命令与其 slurmstep 进程之间的套接字通信上发送的 keepalive 探测的数量。
- keepalivetime=#:指定断开连接后,srun 命令与其 slurmstep 进程之间使用的套接字通信保持活动的时间长度。
-
CompleteWait
在计划任何其他作业之前,任何作业处于 COMPLEING 状态时等待的时间(以秒为单位)。这是为了尝试将作业保留在最近使用的节点上,目标是防止碎片。如果设置为零,挂起的作业将尽快启动。
- ControlMachine
控制节点名称。
-
CoreSpecPlugin:标识用于实施核心专业化的插件。要使对此参数的更改生效,需要重新启动 slurmd 守护进程。
- core_spec/cray_aries:只用于 Cray 系统
- core_spec/none:适用于所有系统
-
CpuFreqDef:如果没有使用—— CPU-freq 选项显式设置作业步骤,则运行作业步骤时使用的默认 CPU 频率值或频率调控器。
- Conservative:试图使用保守的 CPU 调控器
- OnDemand:尝试使用 OnDemand CPU 调控器
-
CredType
用于创建作业步骤凭据的加密签名工具。要使对此参数的更改生效,需要重新启动 slurmctld。
-
DebugFlags:定义应该提供更详细事件日志记录的特定子系统。
- Accrue:应计帐款会计详情
- Agent:RPC 代理(从 Slurm 守护进程发出的 RPC)
- BackFill:作业回填计划程序详细信息
- CPU_Bind:作业和作业步的 CPU 绑定详细信息
- Dependency:工作依赖调试信息
- Elasticsearch:Elasticsearch debug info
- Gres:通用资源详细信息
- JobAccountGather:常见的工作帐户收集详细信息
- Priority:作业优先级信息
- Route:消息转发调试信息
- Steps:Slurmctld资源分配的工作步骤
-
DefCpuPerGPU
每个分配的 GPU 所分配的 CPU 的默认计数。仅当作业没有指定 ——cpus-per-task 和——cpus-per-gpu 时才使用此值。
- DefMemPerCPU
每个可用分配 CPU 可用的默认实际内存大小(MB)。用于避免过度订阅内存并导致内存分页。如果将单个处理器分配给作业,则通常使用 DefMemPerCPU。其他的诸如DefMemPerGPU(每个GPU多少内存),DefMemPerNode(每个节点多少内存)。
- DependencyParameters
- disable_remote_singleton:默认情况下,当联合作业具有单独依赖项时,联合中的每个集群必须清除单独依赖项,才能认为满足作业的单独依赖项。
- kill_invalid_depend:如果一个作业有一个无效的依赖项,它永远不能运行终止它,并将其状态设置为 JOB _ CANCELLED。默认情况下,作业保持挂起状态。
- DisableRootJobs
如果设置为“ YES”,那么用户 root 将被禁止运行任何作业。默认值是“ NO”,这意味着用户 root 将能够执行作业。DisableRootJobs 也可以通过分区设置。
- EnforcePartLimits—解决作业大小限制
如果设置为“ ALL”,那么超过分区大小和/或时间限制的作业将在提交时被拒绝。如果作业提交给多个分区,则作业必须满足所有请求分区的限制。如果设置为“ NO”,那么作业将被接受并保持排队状态,直到分区限制改变(时间和节点限制)。
- Epilog
当用户的作业完成时,作为用户根在每个节点上执行的脚本的完全限定路径名(例如“/usr/local/slurm/pilog”)。
- EpilogMsgTime
Slurmctld 守护进程处理来自 slurmd 守护进程的 Epilog 完成消息所需的微秒数。此参数可用于防止同时发送一连串 Epilog 完成消息,这应有助于防止丢失消息并提高大型作业的吞吐量。
- FairShareDampeningFactor
抑制超过用户或组所分配资源的公平份额的影响。较高的价值将提供更大的能力,以区分超过公平份额的高水平。
- FirstJobId
将用于提交给 Slurm 的第一个作业的作业 ID。生成的作业 ID 值对于后续的每个作业将递增1。
- GetEnvTimeout
控制作业在尝试从缓存文件加载用户环境之前应该等待多长时间。
- GresTypes
要管理的通用资源列表(例如,GresTypes = gpu),需要重新启动 slurmctld 和 slurmd 守护进程才能生效。
- GroupUpdateForce
如果设置为非零值,那么关于哪些用户是允许使用分区的组的成员的信息将定期更新,即使在没有更改/etc/group 文件的情况下也是如此。如果设置为零,那么只有在更新/etc/group 文件之后才会更新组成员信息。默认值为1。
- GroupUpdateTime
控制有关哪些用户是允许使用分区的组的成员的信息更新的频率,以及缓存用户组成员列表的时间,单位秒。
- HealthCheckNodeState:确定应该执行 HealthCheckProgram 的节点状态,默认是ANY
- ALLOC:在 ALLOC 状态的节点上运行(分配的所有 CPU)。
- ANY:在任何状态的节点上运行。
- CYCLE:在所有计算节点上循环运行。
- IDLE:在 IDLE 状态的节点上运行。
- MIXED:在 MIXED 状态的节点上运行(一些 CPU 空闲,其他 CPU 分配)。
- InactiveLimit
以秒为单位的时间间隔,在此之后,无响应的作业分配命令(例如 srun 或 salloc,对批处理作业无影响)将导致作业终止。如果执行命令的节点失败或命令异常终止,将终止其作业分配。
- JobCompLoc
当 JobCompType 为“ jobcomp/filetxt”时写入作业完成记录的完全限定文件名,例如当 JobCompType 为数据库时,存储作业放在数据库中。
-
JobCompType:作业完成的日志记录机制
- jobcomp/none:作业完成后,作业的记录将从系统中清除。
- jobcomp/elasticsearch:作业完成后,作业的记录应该写入到由 JobCompLoc 参数指定的 Elasticsearch 服务器。
- jobcomp/mysql:作业完成后,作业的记录应该写入到由 JobCompLoc 参数指定的 MySQL 或 MariaDB 数据库中。
-
JobCompUser:用于访问作业完成数据库的用户帐户。
-
JobRequeue
此选项控制要重新排队的批作业的默认能力。作业可能会被系统管理员、节点故障后或被更高优先级的作业抢占后显式地重新排队。如果 JobRequeue 设置为1,则可以重新排队批作业,除非用户显式禁用该作业。如果 JobRequeue 设置为0,那么除非用户显式启用,否则不会对批作业进行重新排队。例如,sbatch --no-requeue / sbatch --requeue
- KillOnBadExit
如果设置为1,则如果任何任务崩溃或中止,步骤将立即终止,如非零退出代码所示。使用默认值0,如果其中一个进程崩溃或中止,则在崩溃或中止的进程等待期间,其他进程将继续运行。
- KillWait
SIGTERM 和 SIGKILL 信号之间的作业进程在达到其时间限制时的间隔,以秒为单位。如果作业未能在指定的时间间隔内终止,它将被强制终止
- LogTimeFormat
Slurmctld 和 slurmd 日志文件中的时间戳格式。
- Max/Min家族
| 名称 | 含义 |
|---|---|
| MaxJobCount | Slurmctld 一次可以在内存中拥有的最大作业数。 |
| MaxJobId | 提交给 Slurm 作业所使用的最大作业 ID。作业 id 是无符号的32位整数,前26位给本地作业 id,其余6位给集群 id |
| MaxMemPerCPU | 每个分配的 CPU 可用的最大实际内存大小(MB)。避免过度使用导致内存分页 |
| MaxNodeCount | slurmctld中可能存在的节点的最大计数 |
| MaxStepCount | 任何作业可以启动的最大步骤数。默认值为40000步。 |
| MaxTasksPerNode | Slurm 将允许一个作业步骤在单个节点上产生最大任务数(0-65533)。 |
| MinJobAge | 在 slurmctld 保存在内存中的作业列表中清除其记录之前,已完成作业的最小存在时间,默认值为300秒。 |
-
PluginDir:标识 Slurm 插件的位置。
-
PreemptMode:用于抢占作业或启用帮派Gang调度的机制。当 PreemptType 参数设置为启用抢占时,PreemptMode 选择用于抢占集群的合格作业的默认机制。
- OFF:禁止抢占,与
PreemptType = preempt/none功能相同 - CANCEL:被抢占的作业将被取消。
- GANG:启用同一分区中作业的成组调度(时间切片) ,并允许恢复挂起的作业。
- REQUEUE:通过重新排队(如果可能)或取消作业来抢占作业。
- SUSPEND:抢占作业将被暂停,稍后 Gang 调度程序将恢复。
- WITHIN:对于 PreemptType = preempt/qos,允许相同 qos 中的作业相互抢占。
- OFF:禁止抢占,与
-
PreemptType
- preempt/none:默认作业抢占被禁用。
- preempt/partition_prio:作业抢占基于分区优先级层。高优先级分区中的作业可能会抢占低优先级分区中的作业。
- preempt/qos:作业抢占规则由 Slurm 数据库中的服务质量QoS规范指定。
-
PreemptExemptTime:全局选项,用于所有作业在被考虑抢占之前的最短运行时间
-
PriorityCalcPeriod
半衰期以分钟为单位重新计算半衰期的时间。只有当 PriorityType = PriorityType/multifactor 时才适用。默认值为5(分钟)。
- PriorityFavorSmall
指定应给予小作业优先调度权。只有当 PriorityType = PriorityType/multifactor 时才适用。支持的值是“ YES”和“ NO”。默认值是“ NO”。
-
PriorityFlags:修改作业优先级
- CALCULATE_RUNNING:不仅会重新计算挂起作业的优先级,还会重新计算正在运行和挂起的作业的优先级。
- DEPTH_OBLIVIOUS:优先级将基于类似于正常的多因素计算,但是树中关联的深度不会对它们的优先级产生不利影响。但是默认不启动FairTree算法,即NO_FAIR_TREE。
- NO_FAIR_TREE:禁用“公平树”算法,恢复为“经典”公平共享优先级调度。
- INCR_ONLY:表示优先级只会增加,作业优先级永远不会减少。
- SMALL_RELATIVE_TO_TIME:作业的大小组件将不仅基于作业的大小,而且基于作业的大小除以其时间来计算。
-
PriorityMaxAge
在基于时长的因子中,超过最大时长的作业将获得相同的时长优先级因素值。
- PriorityType:指定用于建立作业调度优先级的插件。
- priority/basic:默认的FIFO调度
- priority/multifactor:工作的优先级取决于各种因素,包括大小、作业时长、 份额。
- PriorityUsageResetPeriod:在这个时间间隔内,关联的使用将被重置为0。
- NONE:从不清理历史使用(默认)
- NOW:现在就清除历史使用情况。
- DAILY:每天清楚一次历史使用情况。
- WEEKLY:每周;MONTHLY:每月;QUARTERLY:每季度;YEARLY:每年
- 优先级权重设置
| 名称 | 含义(默认:0) |
|---|---|
| PriorityWeightAge | 用于设置队列等待时间组件对作业优先级的贡献程度。 |
| PriorityWeightAssoc | 用于设置关联组件对作业优先级的贡献程度。 |
| PriorityWeightFairshare | 用于设置公平分享组件对作业优先级的贡献程度 |
| PriorityWeightJobSize | 用于设置作业大小组件对作业优先级的贡献程度。 |
| PriorityWeightPartition | 用于设置在计算作业优先级时使用的分区因子 |
| PriorityWeightQOS | 用于设置服务质量组件对作业优先级的贡献程度。 |
| PriorityWeightTRES | 用于设置每个 TRES 类型对作业优先级的贡献程度。 |
-
PrivateData:设置常规用户可见/不可见的信息范围
- accounts:防止用户查看任何帐户。
- jobs:防止用户查看属于其他用户的作业或作业步骤。
- nodes:防止用户查看节点状态信息。
- partitions:防止用户查看分区状态信息。
- reservations:防止用户查看无法使用的预订。
- usage:防止用户查看任何其他用户的使用情况。
- users:防止用户查看除了他们自己以外的任何用户的信息。
-
ProctrackType:进程追踪插件
- proctrack/cgroup:使用Linux中的cgroup 来约束和跟踪进程。
- proctrack/linuxproc:使用Linux 进程树的父进程 ID 。
- proctrack/pgid:使用进程组 ID。
-
ReconfigFlags:使用“ scontrol reconfig”命令时可能采取的操作。
- KeepPartInfo:保持分区原有的信息,包括内存节点等参数。
- KeepPartState:只保持分区中内存相关参数。
-
ResumeProgram
Slurm 支持一种机制,可以降低长时间空闲节点的功耗,这通常是通过降低电压和频率或关闭节点电源来实现的。
- ResumeRate
重新启动时,为每分钟启动多个节点,可用于防止节能模式下大量节点同时分配工作(如大量工作启动)时出现问题。
- ResumeTimeout
发出节点恢复请求到该节点实际可用之间允许的最长时间(以秒为单位)。在此时间框架内无法响应的节点将被标记为 DOWN,并且在节点上安排的作业将被重新排队。
-
RoutePlugin
- route/default:默认网状结构。
- route/topology:使用 toplogy.conf 文件中定义的交换机层次网络结构。
-
SchedulerType:标识使用调度程序的类型。
- sched/backfill:使用回填调度机制来支持默认的 FIFO 调度。回填调度将启动低优先级作业,这样做不延迟任何高优先级作业的预期启动时间。
- sched/builtin:这是 FIFO 调度程序,它按优先级顺序启动作业,如果无法启动作业,那么低优先级也不会被启动。
-
SlurmctldDebug:提供 slurmctld 守护进程日志的详细级别。
- quiet:什么都不记录
- fatal:只记录严重错误
- error:只记录error
- info:记录错误和一般消息
- verbose:记录错误和详细的消息
- debug、debug1、debug2
-
SlurmctldLogFile:Slurmctld 守护进程的日志写入的文件的绝对路径名。
-
SlurmctldPidFile
Slurmctld 守护进程可以将其进程 ID 写入其中的文件的绝对路径,默认是“/var/run/slurmctld.pid”。
- SlurmctldSyslogDebug:Slurmctld 守护进程将以指定的详细级别将事件记录到 syslog 文件。
- quiet:什么都不记录
- fatal:只记录严重错误,默认
- error:只记录error
- info:记录错误和一般消息
- verbose:记录错误和详细的消息
- debug、debug1、debug2
- SlurmctldTimeout
备份控制器在获得控制权之前等待主控制器响应的时间间隔,默认120秒,最大65533秒。
- SlurmdSpoolDir
将 slurmd 守护进程的状态信息和批处理作业脚本信息写入的目录的绝对路径。这必须是所有节点的公共路径名,默认路径值是“/var/spool/slurmd”。
- SlurmdUser
Slurmd 守护进程作为其执行的用户的名称。该用户必须存在于集群的所有节点上,以便对 Slurm 组件之间的通信进行身份验证。默认值是“ root”。
- SlurmUser
Slurmctld 守护进程作为其执行的用户的名称。该用户必须存在于集群的所有节点上,以便对 Slurm 组件之间的通信进行身份验证。默认值是“ root”。
- StateSaveLocation
slurmctld 将其状态保存到的目录的绝对路径名(例如“/usr/local/Slurm/check”)。Slurm 状态将保存在这里,以便从系统故障中恢复。
- SuspendExcNodes
指定不处于节能模式的节点,即使节点在较长时间内保持空闲状态。比如node[10-20]:4,则表示在10-20这个节点范围内,至少有四个节点保持IDLE状态,而不是DOWN,或者DRAINING。
- TCPTimeout
允许建立 TCP 连接的时间。默认值为2秒。
节点管理
Slurm 要管理的节点的配置也在/etc/slurm/slurm.conf 中指定。更改节点配置(例如添加节点、更改处理器数量等)需要重新启动 slurmctld 守护进程和 slurmd 守护进程。所有 slurmd 守护进程都必须知道系统中的每个节点,以便转发消息以支持分层通信。
- NodeName
Slurm 用来引用节点的名称。通常这是“/bin/hostname-s”返回的字符串。
- NodeHostname
通常这是“/bin/hostname-s”返回的字符串。与NodeName默认情况下是相同的。
- NodeAddr
在建立通信路径时应引用的节点的名称。这个名称将用作 getaddrinfo ()函数的参数,默认情况下与NodeHostName相同。
- CoreSpecCount
保留给系统使用的核心数量。这些核心将不可用于分配给用户作业。默认情况下,Slurm 守护进程 slurmd 可能被限制在这些资源中,或者被禁止使用这些资源。
- CPUs
节点上逻辑处理器的数量。可以设置为套接字的总数,核心或线程。
- Features
表示与节点关联的某些特征,例如指示处理器速度。一个节点要么有一个特性,要么没有。
- Gres
表示节点通用资源规范列表,第一个字段是资源名称,它与 GresType 配置参数名称匹配,后一个字段必须指定资源计数,表示该类型资源有多少个。
- MemSpecLimit
保留给系统使用且不可用于用户分配的内存量(MB)。
- RealMemory
节点上实际内存的大小(MB)。默认值为1。降低 RealMemory 的目标是为操作系统预留一定数量的内存。
- Reason
标识一个节点所在状态的原因。
- Sockets
节点上的物理处理器套接字/核心数。如果忽略 Sockets,则将从 CPUs、 CoresPerSocket 和 ThreadsPerCore 推断。
- State
| 关键字 | 含义 |
|---|---|
| DOWN | 表示节点失败,不可用。 |
| DRAIN | 表示节点不可用于分配工作。 |
| FAIL | 表示节点预计将很快失败,没有分配给它的作业,也不会分配任何新作业。 |
| FAILING | 表示节点预计将很快失败,已分配了一个或多个作业,但不会分配任何新作业。 |
| UNKNOWN | 表示节点的状态未定义,UNKNOWN 是默认状态。 |
注意:这里没有IDLE、BUSY状态,因为这不用在配置文件中设置,因为默认状态是UNKONWN,根据恢复的系统状态信息将节点状态设置为 BUSY、 IDLE 或其他适当的状态。
- TmpDisk
TmpFS 中临时磁盘存储的总大小(MB)。临时文件系统用来标识作业应该用于临时存储的位置。
- Weight
用于调度目的的节点的优先级。在所有条件相同的情况下,将任务分配到满足其需求的权重最低的节点。如果任何一个节点都能满足作业的需求,那么分配较小的内存节点比分配较大的内存节点更好。具有更多处理器、内存、磁盘空间、更高处理器速度等的节点将分配更大的权重。而且节点权重只在当前可用节点中考虑,即节点状态为IDLE或者BUSY。
分区管理
分区配置允许为不同的节点组(或分区)建立不同的作业限制或访问控制。节点组可能位于多个分区中,使分区成为通用队列。例如,可以将同一组节点放到两个不同的分区中,每个分区都有不同的约束(时间限制、作业大小、允许使用分区的组等等)。作业在单个分区内分配资源。在slurm.conf中每个分区的所有参数放在一行中。每一行分区配置信息应该代表一个不同的分区。
- AllocNodes
用逗号分隔表示分区的节点列表,用户可以在分区中提交作业。默认值是“ ALL”。
- AllowAccounts
表示可以在分区中执行作业的帐户列表。默认值是“ ALL”。
- AllowGroups
表示可以在分区使用的组名列表,这些组名可以在这个分区中执行作业。如果 AllowGroup 至少有一个与用户关联的组,则允许用户向此分区提交作业。作为用户 root 或用户 SlurmUser 执行的作业将被允许使用任何分区,而与 AllowGroup 的值无关。默认情况下,AllowGroups 是未设置的,这意味着所有组都可以使用此分区。
- AllowQos
可以使用分区的QoS 列表,这些 QoS 可以执行分区中的作业。作为Root用户执行的作业可以使用任何分区,而不必考虑 AllowQos 的值。默认值是“ ALL”。
- Alternate
如果该分区的状态为“ DRAIN”或“ INACTIVE”,则使用的备用分区的分区名称。
- Default
如果一个分区设置了该关键字,没有分区规范提交的作业将利用这个分区。可能的值是“ YES”和“ NO”。默认值是“ NO”。
- DefaultTime
用于未指定值的作业的运行时间限制。如果未设置,则将使用 MaxTime。
- DefCpuPerGPU
每个GPU 所分配的 CPU 的默认数量。仅当作业没有指定——cpus-per-task 和—— cpus-per-gpu 时才使用这个值。
- DefMemPerCPU
每个 CPU分配可用的默认实际内存大小(MB)。用于避免过度订阅内存并导致分页。如果未设置,则将使用整个群集的 DefMemPerCPU 值。
- DefMemPerGPU
每个GPU 分配可用的默认实际内存大小(MB)。
- DefMemPerNode
每个已分配节点可用的默认实际内存大小(MB),避免过度使用内存并导致分页。如果将整个节点分配给作业并且资源超订(OverSubscribe = yes 或 OverSubscribe = force) ,则通常使用 DefMemPerNode。如果未设置,则将使用整个群集的 DefMemPerNode 值。
- 黑名单限制
| 关键字 | 含义 |
|---|---|
| DenyAccounts | 表示不执行分区中作业的帐户列表。默认情况下,所有账户都可访问: 如果使用 AllowAccount,那么 DenyAccount 将不会被强制执行,他俩是互斥的。 |
| DenyQos | 表示QoS 不会执行分区的作业。默认情况下,所有QoS都可访问: 如果使用 AllowQos,那么 DenyQos 将不会被强制执行,也是互斥的。 |
| DisableRootJobs | 如果设置为“ YES”,那么用户 root 将被阻止在这个分区上运行任何作业。默认是“ NO”,允许用户 root 执行作业)。 |
- ExclusiveUser
如果设置为“ YES”,那么节点将专门分配给用户。可以为同一个用户运行多个作业,
- Hidden
指定默认情况下是否隐藏分区及其作业。Slurm API 或命令默认情况下不会报告隐藏分区。可能的值是“ YES”和“ NO”。默认值是“ NO”。
- Min/Max家族
| 关键字 | 含义 |
|---|---|
| MaxCPUsPerNode | 此分区中所有作业可用的任何节点上的最大 CPU 数。一个节点可以与两个 Slurm 分区(例如“ cpu”和“ gpu”)相关联,而“ cpu”分区可以仅限于节点 CPU 的一个子集。 |
| MaxMemPerCPU | 每个 CPU 可用的最大实际内存大小(MB),用于避免过度订阅内存并导致分页。如果未设置,则将使用整个群集的 MaxMemPerCPU 值。 |
| MaxMemPerNode | 个分配节点可用的最大实际内存大小(MB),用于避免过度订阅内存并导致分页。如果未设置,则将使用整个群集的 MaxMemPerNode 值。 |
| MaxNodes | 可以分配给任何单个作业的节点的最大数目,默认没有限制 |
| MaxTime | 作业的最大运行时间限制。 |
| MinNodes | 可以分配给单个作业的最小节点数。默认值为0。 |
- OverSubscribe:控制分区在每个资源(节点、CPU)上一次执行多个作业的能力。默认状态是”NO“即不允许共享资源。
- EXCLUSIVE:可以将整个节点分配给作业。在 OverSubscribe = EXCLUSIVE 的分区中运行的作业将具有对所有分配节点的独占访问权限。比如CPU和GPU,但是内存却是按照分配所需的内存,因为有的作业挂起在内存中,内存不可以独占。
- FORCE:使分区中的所有资源(GRES 除外)都可以超额使用,而用户无法禁用它。可以后跟冒号和处于运行状态或挂起状态的最大作业数。例如FORCE:2表示每个资源最大可以有两个作业同时运行(如果资源分配合适的情况下)。
- YES:使分区中的所有资源(GRES 除外)可以根据作业的请求共享。只有当用户使用作业提交上的“–oversubscribe”选项显式请求时,资源才会超额申请使用。可以后跟冒号和处于运行状态或挂起状态的最大作业数。例如OverSubscribe = YES: 4表示每个节点可以运行四个作业。
- NO:选定的资源分配给一个作业。不会将任何资源分配给多个作业,同时禁止该作业被抢占。
示例:
1、独占模式
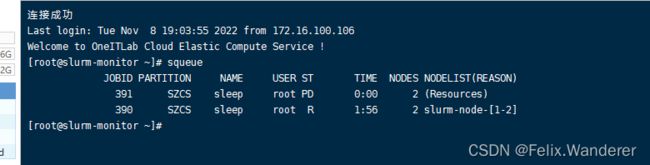
2、共享模式
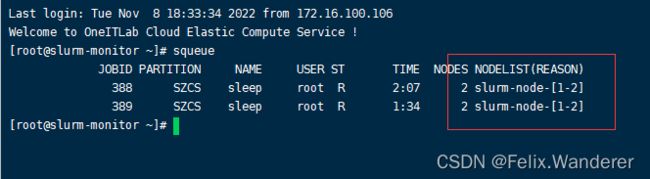
- OverTimeLimit
作业在被取消之前可以超过其时间限制的分钟数。通常情况下,一个工作的时间限制被视为一个硬限制,当达到这个限制时,该工作将被终止。配置 OverTimelimit 将导致作业的时间限制被视为软限制,给一个弹性的作业超额时间。
- PriorityJobFactor
priority/multifactor插件在计算作业优先级时使用的分区因子。该值不能超过65533。
- ReqResv
指定此分区的用户在提交作业时必须指定预订。此选项可用于限制只允许在预订中使用优先级较高或额外资源的分区使用。可能的值是“ YES”和“ NO”。默认值是“ NO”。
- ResumeTimeout
从发出节点恢复请求到该节点实际可用之间允许的最长时间(以秒为单位)。在此时间框架内无法响应的节点将被标记为 DOWN,并且在该节点上安排的作业将被重新排队。
- RootOnly
指定此分区中是否只有用户root可以分配资源。root用户可以为任何其他用户分配资源,但请求必须由root用户发起。可以防止用户直接使用这些资源。可能的值是“ YES”和“ NO”。默认值是“ NO”。
- Shared
Shared 配置参数已被 OverSubscribe 参数替换。
-
State:分区状态
- UP:指示新作业可以在分区上排队,作业可以分配节点并从分区运行。
- DOWN:示新作业可以在分区上排队,但排队的作业不能分配节点并从分区运行。已经在分区上运行的作业将继续运行。必须显式取消作业以强制终止作业。
- DRAIN:指示不能在分区上排队新作业,作业提交请求将被拒绝 ,但是已经在分区上排队的作业可以被分配节点并运行。
- INACTIVE:指示不能在分区上排队新作业,已经排队的作业可能不会被分配节点并运行。
-
SuspendTime
在此数秒内保持空闲或停机的节点将被暂停程序置于省电模式(降低频率或者关闭节点)。对于设置了此选项的多个分区中的节点,SuspendTime将取最长时间。如果未在任何分区上设置,则该节点将使用为整个群集设置的 SuspendTime 值。
- SuspendTimeout
从发出节点挂起请求到关闭节点之间允许的最长时间(秒)。此时,节点必须准备好根据新工作的需要发出恢复请求(手动)。如果未在分区上设置SuspendTimeout,则该节点将使用为整个群集设置的 SuspendTimeout 值。
- TRESBillingWeights
用于定义每种 TRES 类型的计费权重,这些权重将用于计算作业的使用情况。计费权重指定为 < TRES type > = < TRES 计费权重 > 。当一个任务在配置为 TRESBillingWeights = “ CPU = 1.0,Mem = 0.25 G,GRES/gpu = 2.0”的分区上分配了1个 CPU 和8 GB 内存时,计费的 TRES 将是: (1 * 1.0) + (8 * 0.25) + (0.* 2.0) = 3.0。
被分配节点并运行。
-
INACTIVE:指示不能在分区上排队新作业,已经排队的作业可能不会被分配节点并运行。
-
SuspendTime
在此数秒内保持空闲或停机的节点将被暂停程序置于省电模式(降低频率或者关闭节点)。对于设置了此选项的多个分区中的节点,SuspendTime将取最长时间。如果未在任何分区上设置,则该节点将使用为整个群集设置的 SuspendTime 值。
- SuspendTimeout
从发出节点挂起请求到关闭节点之间允许的最长时间(秒)。此时,节点必须准备好根据新工作的需要发出恢复请求(手动)。如果未在分区上设置SuspendTimeout,则该节点将使用为整个群集设置的 SuspendTimeout 值。
- TRESBillingWeights
用于定义每种 TRES 类型的计费权重,这些权重将用于计算作业的使用情况。计费权重指定为 < TRES type > = < TRES 计费权重 > 。当一个任务在配置为 TRESBillingWeights = “ CPU = 1.0,Mem = 0.25 G,GRES/gpu = 2.0”的分区上分配了1个 CPU 和8 GB 内存时,计费的 TRES 将是: (1 * 1.0) + (8 * 0.25) + (0.* 2.0) = 3.0。
如果没有定义 TRESBillingWeights,则根据分配的 CPU 总数对作业进行计费。