m基于GA遗传算法的电动汽车有序充电控制策略matlab仿真
目录
1.算法描述
2.仿真效果预览
3.MATLAB核心程序
4.完整MATLAB
1.算法描述
首先介绍MATLAB部分的遗传算法的优化算法介绍:
遗传算法的原理
遗传算法GA把问题的解表示成“染色体”,在算法中也即是以二进制编码的串。并且,在执行遗传算法之前,给出一群“染色体”,也即是假设解。然后,把这些假设解置于问题的“环境”中,并按适者生存的原则,从中选择出较适应环境的“染色体”进行复制,再通过交叉,变异过程产生更适应环境的新一代“染色体”群。这样,一代一代地进化,最后就会收敛到最适应环境的一个“染色体”上,它就是问题的最优解。
一、遗传算法的目的
典型的遗传算法CGA(Canonical Genetic Algorithm)通常用于解决下面这一类的静态最优化问题:考虑对于一群长度为L的二进制编码bi,i=1,2,…,n;有
bi{0,1}L (3-84)
给定目标函数f,有f(bi),并且
0
同时f(bi)≠f(bi+1)求满足下式
max{f(bi)|bi{0,1}L}
的bi。很明显,遗传算法是一种最优化方法,它通过进化和遗传机理,从给出的原始解群中,不断进化产生新的解,最后收敛到一个特定的串bi处,即求出最优解。
二、遗传算法的基本原理
长度为L的n个二进制串bi(i=1,2,…,n)组成了遗传算法的初解群,也称为初始群体。在每个串中,每个二进制位就是个体染色体的基因。根据进化术语,对群体执行的操作有三种:
1.选择(Selection)
这是从群体中选择出较适应环境的个体。这些选中的个体用于繁殖下一代。故有时也称这一操作为再生(Reproduction)。由于在选择用于繁殖下一代的个体时,是根据个体对环境的适应度而决定其繁殖量的,故而有时也称为非均匀再生(differential reproduction)。
2.交叉(Crossover)
这是在选中用于繁殖下一代的个体中,对两个不同的个体的相同位置的基因进行交换,从而产生新的个体。
3.变异(Mutation)
这是在选中的个体中,对个体中的某些基因执行异向转化。在串bi中,如果某位基因为1,产生变异时就是把它变成0;反亦反之。
这里所指的某种结束准则一般是指个体的适应度达到给定的阀值;或者个体的适应度的变化率为零。
三、遗传算法的步骤和意义
1.初始化
选择一个群体,即选择一个串或个体的集合bi,i=1,2,...n。这个初始的群体也就是问题假设解的集合。一般取n=30-160。
通常以随机方法产生串或个体的集合bi,i=1,2,...n。问题的最优解将通过这些初始假设解进化而求出。
2.选择
根据适者生存原则选择下一代的个体。在选择时,以适应度为选择原则。适应度准则体现了适者生存,不适应者淘汰的自然法则。
给出目标函数f,则f(bi)称为个体bi的适应度。以
为选中bi为下一代个体的次数。
显然.从式(3—86)可知:
(1)适应度较高的个体,繁殖下一代的数目较多。
(2)适应度较小的个体,繁殖下一代的数目较少;甚至被淘汰。
这样,就产生了对环境适应能力较强的后代。对于问题求解角度来讲,就是选择出和最优解较接近的中间解。
3.交叉
对于选中用于繁殖下一代的个体,随机地选择两个个体的相同位置,按交叉概率P。在选中的位置实行交换。这个过程反映了随机信息交换;目的在于产生新的基因组合,也即产生新的个体。交叉时,可实行单点交叉或多点交叉。
例如有个体
S1=100101
S2=010111
选择它们的左边3位进行交叉操作,则有
S1=010101
S2=100111
一般而言,交 婊显譖。取值为0.25—0.75。
4.变异
根据生物遗传中基因变异的原理,以变异概率Pm对某些个体的某些位执行变异。在变异时,对执行变异的串的对应位求反,即把1变为0,把0变为1。变异概率Pm与生物变异极小的情况一致,所以,Pm的取值较小,一般取0.01-0.2。
例如有个体S=101011。
对其的第1,4位置的基因进行变异,则有
S'=001111
单靠变异不能在求解中得到好处。但是,它能保证算法过程不会产生无法进化的单一群体。因为在所有的个体一样时,交叉是无法产生新的个体的,这时只能靠变异产生新的个体。也就是说,变异增加了全局优化的特质。
5.全局最优收敛(Convergence to the global optimum)
当最优个体的适应度达到给定的阀值,或者最优个体的适应度和群体适应度不再上升时,则算法的迭代过程收敛、算法结束。否则,用经过选择、交叉、变异所得到的新一代群体取代上一代群体,并返回到第2步即选择操作处继续循环执行。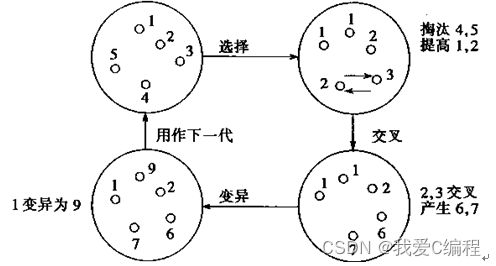
一、遗传算法的特点
1.遗传算法从问题解的中集开始嫂索,而不是从单个解开始。
这是遗传算法与传统优化算法的极大区别。传统优化算法是从单个初始值迭代求最优解的;容易误入局部最优解。遗传算法从串集开始搜索,复盖面大,利于全局择优。
2.遗传算法求解时使用特定问题的信息极少,容易形成通用算法程序。
由于遗传算法使用适应值这一信息进行搜索,并不需要问题导数等与问题直接相关的信息。遗传算法只需适应值和串编码等通用信息,故几乎可处理任何问题。
3.遗传算法有极强的容错能力
遗传算法的初始串集本身就带有大量与最优解甚远的信息;通过选择、交叉、变异操作能迅速排除与最优解相差极大的串;这是一个强烈的滤波过程;并且是一个并行滤波机制。故而,遗传算法有很高的容错能力。
4.遗传算法中的选择、交叉和变异都是随机操作,而不是确定的精确规则。
这说明遗传算法是采用随机方法进行最优解搜索,选择体现了向最优解迫近,交叉体现了最优解的产生,变异体现了全局最优解的复盖。
5.遗传算法具有隐含的并行性
遗传算法的基础理论是图式定理。它的有关内容如下:
(1)图式(Schema)概念
一个基因串用符号集{0,1,*}表示,则称为一个因式;其中*可以是0或1。例如:H=1xx 0 x x是一个图式。
(2)图式的阶和长度
图式中0和1的个数称为图式的阶,并用0(H)表示。图式中第1位数字和最后位数字间的距离称为图式的长度,并用δ(H)表示。对于图式H=1x x0x x,有0(H)=2,δ(H)=4。
(3)Holland图式定理
低阶,短长度的图式在群体遗传过程中将会按指数规律增加。当群体的大小为n时,每代处理的图式数目为0(n3)。
遗传算法这种处理能力称为隐含并行性(Implicit Parallelism)。它说明遗传算法其内在具有并行处理的特质。
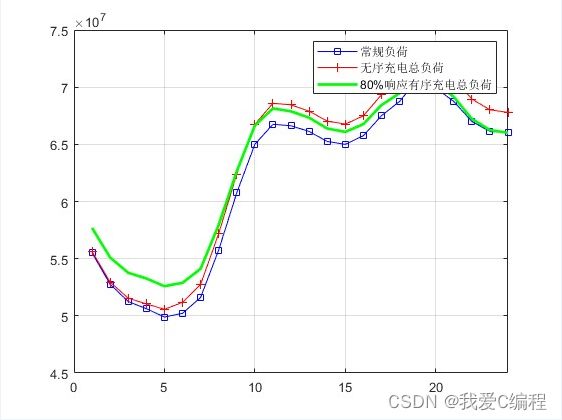
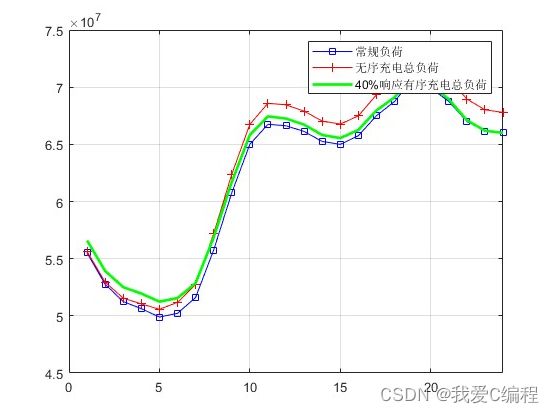
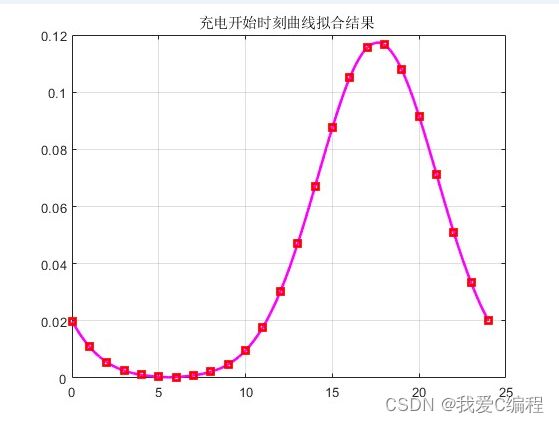
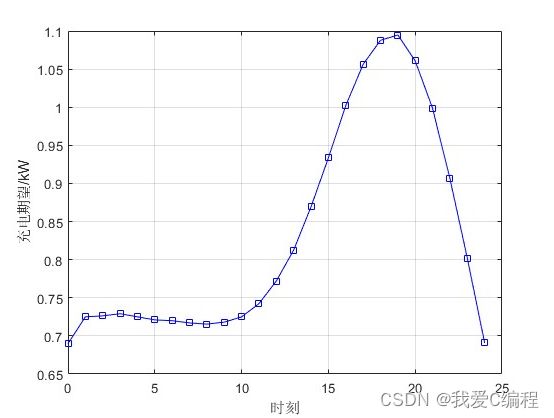
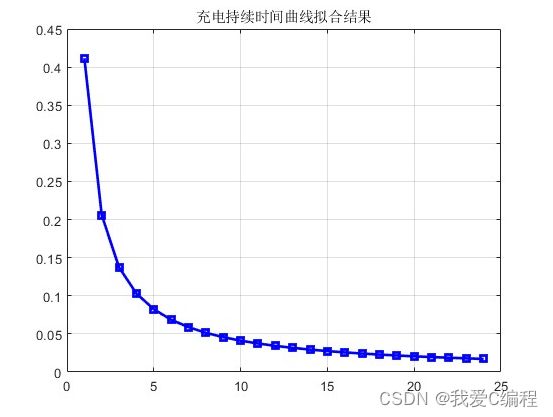
2.仿真效果预览
matlab2022a仿真如下:

3.MATLAB核心程序
global Br;
global SOC1;
global SOC2;
Br = 60e3;%电动车辆的电池容量
SOC1 = 0.3;
SOC2 = 0.9;
%不同时段价格
global pj;
p1 = 2;
p2 = 0.4;
Time = [0.25:0.25:24];
for i = 1:96
if Time(i) >= 7 & Time(i) <= 23
pj(1,i) = p1;
end
if Time(i) > 23 | Time(i) < 7
pj(1,i) = p2;
end
end
%不同车辆功率,充电功率
global Pi;
Pi = 7e3*ones(N,1);
%定义不同车辆不同时段是否充电
xij = zeros(N,96);
F = func_obj(xij);
%%
%下面开始使用遗传优化算法
%根据遗传算法进行参数的拟合
MAXGEN = 400;
NIND = 1000;
Nums = 2*N;
Chrom = crtbp(NIND,Nums*10);
Sm = 0;
Areas = [];
for i = 1:Nums
Areas =[Areas,[1;95]];
end
FieldD = [rep([10],[1,Nums]);Areas;rep([0;0;0;0],[1,Nums])];
for a=1:1:NIND
%计算对应的目标值
%初始值
xij = [ones(N,24),ones(N,72)];
epls = func_obj(xij);
E = epls;
Js(a,1) = E;
end
Objv = (Js+eps);
gen = 0;
Data1 = zeros(NIND,Nums);
Data2 = zeros(MAXGEN,Nums);
while gen < MAXGEN;
gen
Pe0 = 0.98;
pe1 = 0.01;
FitnV=ranking(Objv);
Selch=select('sus',Chrom,FitnV);
Selch=recombin('xovsp', Selch,Pe0);
Selch=mut( Selch,pe1);
phen1=bs2rv(Selch,FieldD);
for a=1:1:NIND
xij = zeros(N,96);
Start = round(phen1(a,1:N));
Ends = round(phen1(a,N+1:end))+1;
for i = 1:N
T1 = min([Start(i),Ends(i)]);
T2 = max([Start(i),Ends(i)]);
%约束设置
if Pi(i)*(T2-T1)/4 > (SOC2-SOC1)*Br
T2 = 4*(SOC2-SOC1)*Br/Pi(i) + T1;
end
xij(i,T1:T2) = 1;
end
%计算对应的目标值
epls = func_obj(xij);
E = epls;
JJ(a,1) = E;
end
Objvsel=(JJ);
[Chrom,Objv]=reins(Chrom,Selch,1,1,Objv,Objvsel);
gen=gen+1;
%保存参数收敛过程和误差收敛过程以及函数值拟合结论
index1 = isnan(JJ);
index2 = find(index1 == 1);
JJ(index2) = [];
Error2(gen) = 1/mean(JJ);
end
02_045m4.完整MATLAB
V