Python爬虫——爬取豆瓣Top250
一、基本思路
页面分析
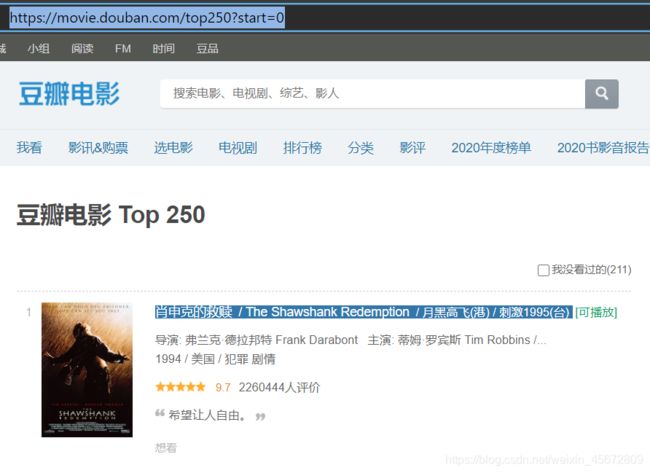
我们要爬取的网页是豆瓣Top250 https://movie.douban.com/top250
通过分析页面可以知道 每页显示25部电影
start=0 时从第1部开始显示
start=25时从第26部开始显示
电影的信息都在页面上
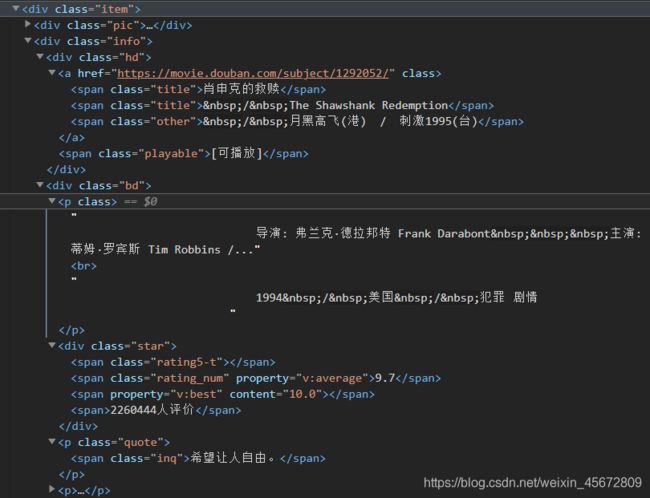
所以我们要爬取的网页链接是
https://movie.douban.com/top250/?start=0
https://movie.douban.com/top250?start=25
https://movie.douban.com/top250?start=50
…
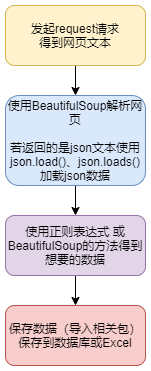
爬取的基本步骤
二、代码实现
引入相关包
from bs4 import BeautifulSoup # 网页解析
import re # 正则表达式
import xlwt # excel操作
import urllib.request, urllib.error # URL获取网页数据
Request请求
首先我们要获取浏览器的User-Agent用来伪装自己
百度百科:
User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
以Chrome浏览器为例,在浏览器地址栏输入
about:version

可以看到,浏览器User-Agent为
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36
如果你想要爬取手机端的网页,要使用手机上的User-Agent
如果你没有使用User-Agent或User-Agent错误,网址服务器就会识破你的爬虫,返回一个错误代码418
418 I’m a teapot
The HTTP 418 I’m a teapot client error response code indicates that the server refuses to brew coffee because it is a teapot. This error is a reference to Hyper Text Coffee Pot Control Protocol which was an April Fools’ joke in 1998.
翻译为:HTTP 418 I’m a teapot客户端错误响应代码表示服务器拒绝煮咖啡,因为它是一个茶壶。这个错误是对1998年愚人节玩笑的超文本咖啡壶控制协议的引用。
如果你发起的请求数过多或频率过快,服务器也会限制你爬取,要求你登录
我们可以登录豆瓣使用cookie来发起请求
先登录豆瓣 在Top250网页按 F12 选择Network网络 找到第一个发出的请求 在Headers里选择Request Headers 将cookie里的字符串复制出来
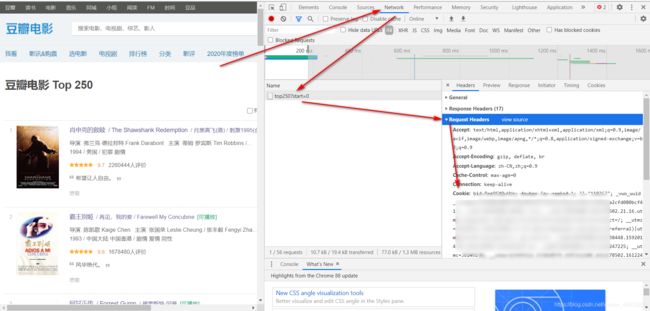
没有异常的时候可以不带cookie
# 爬取网页
def askURL(url):
cookies ='''Cookie放在这里'''
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36})",
"Cookie": cookies # 无异常可不带Cookie
}
requst = urllib.request.Request(url=url, headers=head) # 构造一个请求
html = "" # 用来保存返回的网页文本
try:
response = urllib.request.urlopen(requst) # 发起请求
html = response.read().decode("utf-8") # utf-8 解码
# print(html) # 打印测试
except urllib.error.URLError as e: # 请求失败的异常处理
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
网页处理
#影片链接
findlink = re.compile(r'') # 创建正则表达式对象
#图片
findimgsrc = re.compile(r', re.S)
#片名
findtitle = re.compile(r'(.*?)')
#评分
findrating = re.compile(r'')
#评价人数
findjudge = re.compile(r'(\d*)人评价')
#简评
findinq = re.compile(r'(.*?)')
#相关内容
findbd = re.compile(r'(.*?)
', re.S)
# 数据处理
baseurl = "https://movie.douban.com/top250?start="
def getData(url):
datalist = [] # 创建数据存储的对象
for index in range(0, 10):
url = baseurl + str(index * 25) # 链接处理
html = askURL(url) # 用来保存网页源码
soup = BeautifulSoup(html, "html.parser") # 解析html
for item in soup.find_all('div', class_="item", ): # 查找符合要求的字符串,形成列表
#print(item)
data = [] # 保存一部电影的所有信息
item = str(item) # 转换为str
link = re.findall(findlink, item)[0] # re.findall 指定的字符串
data.append(link) # 添加到data列表里
imgsrc = re.findall(findimgsrc, item)[0]
data.append(imgsrc)
titles = re.findall(findtitle, item)
if(len(titles) ==2 ): #电影名称的处理,有的电影名只有一个中文或外文名
ctitle = titles[0]
data.append(ctitle)
otitle = titles[1].replace("/", "") # 将名字里的'/'删去
data.append(otitle)
else:
data.append(titles[0])
data.append(" ")
rating = re.findall(findrating, item)[0] # 评分
data.append(rating)
judge = re.findall(findjudge, item)[0] # 评价人数
data.append(judge)
inq = re.findall(findinq, item) #简评
if len(inq) != 0:
inq = inq[0].replace("。", "")
data.append(inq)
else:
data.append(" ")
bd = re.findall(findbd, item)[0] #相关内容
bd = re.sub(' 保存数据
def saveData(savePath,datalist):
workbook = xlwt.Workbook(encoding="utf-8") # 设置编码
worksheet = workbook.add_sheet("TOP250") # 添加工作表
col = ("电影链接","图片链接","影片名","外文名","评分","评价数","简评","相关信息")
for i in range(0,8):
worksheet.write(0,i,col[i]) # 写入第一行
for i in range(0,250): # 写入电影数据
print("第%d条"%(i+1))
data = datalist[i]
for j in range(0,8):
worksheet.write(i+1, j, data[j])
workbook.save(savePath) # 保存文件
完整源码
spider.py
# -*- coding:utf-8 -*-
# @TIME : 2021/1/24 18:16
# @Author : Wenhao
# @File : spider.py
# @Software : PyCharm
from bs4 import BeautifulSoup # 网页解析
import re # 正则表达式
import xlwt # excel操作
import urllib.request, urllib.error # URL获取网页数据
baseurl = "https://movie.douban.com/top250?start="
def main():
datalist = getData(baseurl)
savePath = "豆瓣Top250.xls"
saveData(savePath, datalist)
#影片链接
findlink = re.compile(r'') # 创建正则表达式对象
#图片
findimgsrc = re.compile(r', re.S)
#片名
findtitle = re.compile(r'(.*?)')
#评分
findrating = re.compile(r'')
#评价人数
findjudge = re.compile(r'(\d*)人评价')
#简评
findinq = re.compile(r'(.*?)')
#相关内容
findbd = re.compile(r'(.*?)
', re.S)
# 数据处理
def getData(url):
datalist = []
for index in range(0, 10):
url = baseurl + str(index * 25)
html = askURL(url) # 保存网页源码
# 解析html
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="item", ): # 查找符合要求的字符串,形成列表
#print(item)
data = [] # 保存一部电影的所有信息
item = str(item)
link = re.findall(findlink, item)[0] # re.findall 指定的字符串
data.append(link)
imgsrc = re.findall(findimgsrc, item)[0]
data.append(imgsrc)
titles = re.findall(findtitle, item)
if(len(titles) ==2 ):
ctitle = titles[0]
data.append(ctitle)
otitle = titles[1].replace("/", "")
data.append(otitle)
else:
data.append(titles[0])
data.append(" ")
rating = re.findall(findrating, item)[0]
data.append(rating)
judge = re.findall(findjudge, item)[0]
data.append(judge)
inq = re.findall(findinq, item)
if len(inq) != 0:
inq = inq[0].replace("。", "")
data.append(inq)
else:
data.append(" ")
bd = re.findall(findbd, item)[0]
bd = re.sub(' 参考
0.Python爬虫基础5天速成(2021全新合集)Python入门+数据可视化
https://www.bilibili.com/video/BV12E411A7ZQ
1.python 爬虫提取文本之BeautifulSoup详细用法https://blog.csdn.net/IT_arookie/article/details/82824620
2.Beautiful Soup 4.4.0 文档
https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
3.Beautiful Soup 4.2.0 文档
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
4.Python爬虫入门:urllib.request详细介绍
https://blog.csdn.net/qq_43546676/article/details/88777227
5.Python爬虫:短视频平台无水印下载
https://blog.csdn.net/qq_44700693/article/details/108089085