vue+springboot实现语音控制页面操作
目录
第一种方案:在页面上实现录音
1、实现原理图
2、主要的实现思路
3、实现代码:
4、数据库设计及数据结构
5、优化方案
第二种方案:企业微信录音
1、实现原理图
2、实现思路
3、实现代码
工作中遇到了一个需求:语音控制大屏。说的清楚一点就是,使用麦克风说话来控制页面的跳转等操作;如:打开xxx,页面响应对应的操作。
此功能提供两种实现方案参考,第一种是在页面上提供按钮,页面录音,转向后台解析语音,转成命令,再返回给前端实现相应的操作;第二种方案是使用企业微信创建应用,使用手机录音转向后台解析,再返回给前端实现相应的操作。这里两种方案只是录音的方式不同,后台的思想是相同的。
这里踩的坑分享出来,提供大家参考。会提供主要的实现代码,包括前端、后台,以及提高语音识别率的优化方案。
第一种方案:在页面上实现录音
1、实现原理图

2、主要的实现思路
客户端录音,将音频文件传给后台服务端,后台(服务端)将音频文件发送给第三方(第三方可以选择百度或者讯飞,这里我选择百度)解析成文字,后台(服务端)接收到返回的中文,去查库将中文转成对应的指令(自己设计的数据结构),将指令返回给前端页面执行。
说明:这里选择使用数据库来解析,没有写死在后台是考虑到后期扩展,将服务端设计成无状态,可以动态扩展指令,以后只有修改数据库及前端实现指令的代码即可。
3、实现代码:
前端代码
页面实现录音代码:参考链接:https://www.jianshu.com/p/f5637e838af0
说明:录音vue实现的代码参考了上面给连接,在此基础上做了修改,设置音量大小达到值时开始录音,当录音结束后再一定的时间内自动保存音频文件(recorder.js中有说明)并自动调用服务端接口。
//recorder.js
export default class Recorder {
constructor(stream, config) {
//兼容
window.URL = window.URL || window.webkitURL;
navigator.getUserMedia = navigator.getUserMedia || navigator.webkitGetUserMedia || navigator.mozGetUserMedia || navigator.msGetUserMedia;
config = config || {};
config.sampleBits = config.sampleBits || 16; //采样数位 8, 16
config.sampleRate = config.sampleRate || 8000; //采样率(1/6 44100)
this.context = new (window.webkitAudioContext || window.AudioContext)();
this.audioInput = this.context.createMediaStreamSource(stream);
this.createScript = this.context.createScriptProcessor || this.context.createJavaScriptNode;
this.recorder = this.createScript.apply(this.context, [4096, 1, 1]);
this.audioData = {
size: 0, //录音文件长度
buffer: [], //录音缓存
inputSampleRate: this.context.sampleRate, //输入采样率
inputSampleBits: 16, //输入采样数位 8, 16
outputSampleRate: config.sampleRate, //输出采样率
oututSampleBits: config.sampleBits, //输出采样数位 8, 16
input: function (data) {
this.buffer.push(new Float32Array(data));
this.size += data.length;
},
compress: function () { //合并压缩
//合并
let data = new Float32Array(this.size);
let offset = 0;
for (let i = 0; i < this.buffer.length; i++) {
data.set(this.buffer[i], offset);
offset += this.buffer[i].length;
}
//压缩
let compression = parseInt(this.inputSampleRate / this.outputSampleRate);
let length = data.length / compression;
let result = new Float32Array(length);
let index = 0, j = 0;
while (index < length) {
result[index] = data[j];
j += compression;
index++;
}
return result;
},
encodeWAV: function () {
let sampleRate = Math.min(this.inputSampleRate, this.outputSampleRate);
let sampleBits = Math.min(this.inputSampleBits, this.oututSampleBits);
let bytes = this.compress();
let dataLength = bytes.length * (sampleBits / 8);
let buffer = new ArrayBuffer(44 + dataLength);
let data = new DataView(buffer);
let channelCount = 1;//单声道
let offset = 0;
let writeString = function (str) {
for (let i = 0; i < str.length; i++) {
data.setUint8(offset + i, str.charCodeAt(i));
}
};
// 资源交换文件标识符
writeString('RIFF');
offset += 4;
// 下个地址开始到文件尾总字节数,即文件大小-8
data.setUint32(offset, 36 + dataLength, true);
offset += 4;
// WAV文件标志
writeString('WAVE');
offset += 4;
// 波形格式标志
writeString('fmt ');
offset += 4;
// 过滤字节,一般为 0x10 = 16
data.setUint32(offset, 16, true);
offset += 4;
// 格式类别 (PCM形式采样数据)
data.setUint16(offset, 1, true);
offset += 2;
// 通道数
data.setUint16(offset, channelCount, true);
offset += 2;
// 采样率,每秒样本数,表示每个通道的播放速度
data.setUint32(offset, sampleRate, true);
offset += 4;
// 波形数据传输率 (每秒平均字节数) 单声道×每秒数据位数×每样本数据位/8
data.setUint32(offset, channelCount * sampleRate * (sampleBits / 8), true);
offset += 4;
// 快数据调整数 采样一次占用字节数 单声道×每样本的数据位数/8
data.setUint16(offset, channelCount * (sampleBits / 8), true);
offset += 2;
// 每样本数据位数
data.setUint16(offset, sampleBits, true);
offset += 2;
// 数据标识符
writeString('data');
offset += 4;
// 采样数据总数,即数据总大小-44
data.setUint32(offset, dataLength, true);
offset += 4;
// 写入采样数据
if (sampleBits === 8) {
for (let i = 0; i < bytes.length; i++, offset++) {
let s = Math.max(-1, Math.min(1, bytes[i]));
let val = s < 0 ? s * 0x8000 : s * 0x7FFF;
val = parseInt(255 / (65535 / (val + 32768)));
data.setInt8(offset, val, true);
}
} else {
for (let i = 0; i < bytes.length; i++, offset += 2) {
let s = Math.max(-1, Math.min(1, bytes[i]));
data.setInt16(offset, s < 0 ? s * 0x8000 : s * 0x7FFF, true);
}
}
return new Blob([data], { type: 'audio/wav' });
}
};
}
//开始录音
start(param) {
this.audioInput.connect(this.recorder);
this.recorder.connect(this.context.destination);
//音频采集
let self = this;
let emptydatacount = 0;
let startVoice = false
this.recorder.onaudioprocess = function (e) {
let data = e.inputBuffer.getChannelData(0)
let l = Math.floor(data.length/10);
let vol = 0;
for(let i=0;i 10){
param.success(self.getBlob());
}
}else{
emptydatacount = 0;
startVoice = true;
self.audioData.input(data);
}
};
};
//停止
stop() {
this.recorder.disconnect();
};
//获取音频文件
getBlob() {
this.stop();
return this.audioData.encodeWAV();
};
//回放
play(audio) {
audio.src = window.URL.createObjectURL(this.getBlob());
};
//清理缓存的录音数据
clear(audio) {
this.audioData.buffer = [];
this.audioData.size = 0;
audio.src = ''
};
static checkError(e) {
const { name } = e;
let errorMsg = ''
switch (name) {
case 'AbortError': errorMsg = '录音设备无法被使用'; break;
case 'NotAllowedError': errorMsg = '用户已禁止网页调用录音设备'; break;
case 'PermissionDeniedError': errorMsg = '用户已禁止网页调用录音设备'; break; // 用户拒绝
case 'NotFoundError': errorMsg = '录音设备未找到'; break;
case 'DevicesNotFoundError': errorMsg = '录音设备未找到'; break;
case 'NotReadableError': errorMsg = '录音设备无法使用'; break;
case 'NotSupportedError': errorMsg = '不支持录音功能'; break;
case 'MandatoryUnsatisfiedError': errorMsg = '无法发现指定的硬件设备'; break;
default: errorMsg = '录音调用错误'; break;
}
return { error: errorMsg }
};
static get(callback, config) {
if (callback) {
if (navigator.mediaDevices && navigator.mediaDevices.getUserMedia) {
navigator.mediaDevices.getUserMedia({ audio: true, video: false }).then((stream) => {
let rec = new Recorder(stream, config);
callback(rec);
}).catch((e) => {
callback(Recorder.checkError(e));
})
} else {
navigator.getUserMedia({ audio: true, video: false }).then((stream) => {
let rec = new Recorder(stream, config);
callback(rec);
}).catch((e) => {
// Recorder.checkError(e)
callback(Recorder.checkError(e));
})
}
}
};
} //record-sdk.js
import Recorder from "./recorder";
export default class Record {
startRecord (param) {
let self = this;
try {
Recorder.get(rec => {
if (rec.error) return param.error(rec.error);
self.recorder = rec;
self.recorder.start(param);
})
} catch (e) {
param.error("开始录音失败" + e);
}
}
stopRecord (param) {
let self = this;
try {
let blobData = self.recorder.getBlob();
param.success(blobData);
} catch (e) {
param.error("结束录音失败" + e);
}
}
play (audio) {
let self = this;
try {
self.recorder.play(audio);
} catch (e) {
console.error("录音播放失败" + e);
}
}
clear (audio) {
let self = this;
try {
self.recorder.clear(audio);
} catch (e) {
console.error("清空录音失败" + e);
}
}
}
前端调用录音方法:
服务端代码实现:调用百度AI提供的短语音识别功能:https://ai.baidu.com/tech/speech/asr
引入百度api
com.baidu.aip
java-sdk
4.1.1
后台接口:
package com.gzstrong.bigscreen.baidu;
import com.alibaba.fastjson.JSONObject;
import com.gzstrong.bigscreen.guavaCache.CacheService;
import com.gzstrong.bigscreen.homePage.service.HomePageService;
import com.gzstrong.cloud.common.core.util.R;
import com.gzstrong.cloud.common.security.annotation.Inner;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.math.BigDecimal;
import java.text.DecimalFormat;
import java.util.*;
import java.util.stream.Collectors;
@RestController
@RequestMapping("/aip")
public class AipClientController {
private static final long serialVersionUID = 8315927863115246061L;
// 上传配置
private final int MEMORY_THRESHOLD = 1024 * 1024 * 3; // 4MB
private final int MAX_FILE_SIZE = 1024 * 1024 * 10; // 10MB
private final String FORMAT = "wav"; //语音文件后缀
private final String FPATH = System.getProperty("user.dir")+"/voice"; //将录音的文件存放到根目录下语音文件夹下
@Autowired
private CacheService cacheService;
@Autowired
private HomePageService homePageService;
@PostMapping("/getResult")
@Inner(false)
public R getResult(@RequestParam(name="audioData")MultipartFile file) throws IOException {
return saveVoice(file);
}
/**
* 保存语音并识别
*/
public R saveVoice(MultipartFile file) {
try {
//保存录音
String filePathName = saveAudio(file);
//识别语音,返回结果
if(filePathName != null) {
AipClient aipClient = new AipClient();
JSONObject data = aipClient.getSynthesis(filePathName, FORMAT);
//识别完成后,删除音频文件
deleteFile(filePathName);
if (data.containsKey("err_no") && data.getInteger("err_no")==0) {
String _res = data.getJSONArray("result").getString(0);
if (_res != null) {
return this.command(_res);
}
}
return R.failed("语音识别失败。","");
} else {
return R.failed("语音文件为空!");
}
} catch (Exception e) {
e.printStackTrace();
return R.failed("语音识别失败。","");
}
}
/**
* 保存音频文件
* @param
* @return
* @throws Exception
*/
private String saveAudio(MultipartFile file) throws Exception {
String filePathName = null;
String fName = System.currentTimeMillis() + "." + FORMAT;
//将录音的文件存放到D盘下语音文件夹下
File filePath = new File(FPATH);
if(!filePath.exists()) {//如果文件不存在,则创建该目录
filePath.mkdir();
}
filePathName = FPATH+"/"+fName;
System.out.println("路径:"+filePathName);
FileOutputStream out = new FileOutputStream(new File(filePathName));
out.write(file.getBytes());
out.flush();
out.close();
return filePathName;
}
/**
* 删除单个文件
* @param filePathName 要删除的文件的文件名
*/
private void deleteFile(String filePathName) {
File file = new File(filePathName);
// 如果文件路径所对应的文件存在,并且是一个文件,则直接删除
if (file.exists() && file.isFile()) {
file.delete();
}
}
// 处理结果,并转成指令
private R command(String result) {
String _result = result.substring(0,result.length()-1);
// 在缓存中查询
JSONObject comm = cacheService.getCache(_result);
//若缓存中 没有,则查询数据库
if (comm == null) {
comm = homePageService.getCommand(_result);
if (comm ==null) {
//模糊匹配结果
List> match = this.match(result);
if (match.size()>0) {
Map map = match.get(0);
this.splitParam(map);
return new R<>(3,"模糊匹配结果",map);
}
return R.failed(result,"语音识别错误或指令不存在!");
}
//解析数据
String[] commands = comm.getString("command").split(",");
List list = new LinkedList<>();
for (String command : commands) {
list.add(command);
}
comm.put("command",list);
comm.put("res",result);
System.out.println("homePageService:"+comm.get("command"));
cacheService.setCache(result,comm);
return R.ok(comm,result);
}
System.out.println("homePageService:"+comm.get("command"));
return R.ok(comm,result);
}
//解析参数
private void splitParam(Map map){
String[] commands = ((String) map.get("command")).split(",");
List list = new LinkedList<>();
for (String command : commands) {
list.add(command);
}
map.put("command",list);
}
}
调用第三方百度api:
package com.gzstrong.bigscreen.baidu;
import com.alibaba.fastjson.JSON;
import com.baidu.aip.speech.AipSpeech;
import com.alibaba.fastjson.JSONObject;
public class AipClient {
public final String APP_ID = "xxxx";
public final String API_KEY = "xxxxx";
public final String SECRET_KEY = "xxxxx";
// 初始化语音识别类
AipSpeech client = new AipSpeech(APP_ID, API_KEY, SECRET_KEY);
/**
* 语音识别
* @param filePathName 语音文件所在路径
* @param format pcm(不压缩)、wav、opus、speex、amr
* @return
*/
public JSONObject getSynthesis(String filePathName, String format){
// 可选:设置网络连接参数
client.setConnectionTimeoutInMillis(2000); //建立连接的超时时间(单位:毫秒)
client.setSocketTimeoutInMillis(60000); //通过打开的连接传输数据的超时时间(单位:毫秒)
org.json.JSONObject asrRes = client.asr(filePathName, format, 8000, null);
System.out.println("打印结果:");
System.out.println(asrRes);
//转换成fastjson
JSONObject jsonObject = JSON.parseObject(asrRes.toString());
return jsonObject;
}
}
说明:APP_ID、API_KEY、SECRET_KEY需要去百度开放平台申请,如下图所示

4、数据库设计及数据结构

返回的数据结构:如下
{
"name":"",//定义好的中文名字
"command":"",//需要传递给前端的参数
"type":""//前端判断指令的类型
}5、优化方案
使用本地缓存优化数据查询问题。将匹配到的指令保存在本地缓存中,下次取的时候,可以直接获取即可,不需要再次查询数据库。
使用第三方百度AI语音识别的结果有时候不准确,显得有些不可用,以下提供两种方案:
第一种优化方案:使用算法模糊匹配。思路:将定义好的需要匹配的指令放在了数据库中,然后将百度ai识别的中文与之匹配计算,获取相似度,将相似度的超过0.6的指令放在数组中,并排序(相似度由高到底,若相同则以指令的长度排序由长到短),并取第一个指令。
//匹配结果
private List> match(String result){
List> allCommand = homePageService.getAllCommand();
List> list = new ArrayList<>();
Map res = null;
String similar = "";
String _tar =null;
for (Map map : allCommand) {
_tar = (String) map.get("name");
similar = this.getResult(result, _tar);
if (Float.parseFloat(similar) > 0.6){
map.put("similar",similar);
map.put("res" ,result);
list.add(map);
}
}
if (list.size() > 2){
list = this.sortList(list);
}
return list;
}
//字符串匹配
private String getResult(String str, String target){
String[] _str = str.split("");
String[] _tar = target.split("");
int[] mak = new int[_tar.length];
int k=0;
for (int i = 0; i < _tar.length; i++) {
for (int j = k; j < _str.length; j++) {
if (_str[j].equals(_tar[i]) && mak[i] !=1) {
mak[i] =1;
k = j;
}
}
}
return this.getsemblance(mak);
}
// 获取相似度
private String getsemblance(int[] mak){
int time = 0;
int total = mak.length;
for (int i = 0; i < total; i++) {
time +=mak[i];
}
DecimalFormat df = new DecimalFormat("0.00");//格式化小数
return df.format((float)time/total);//返回的是String类型
// return new BigDecimal((float)time/total).setScale(2, BigDecimal.ROUND_HALF_UP).floatValue();
}
// 以相似度降序,再以命令长度降序排序
private List> sortList(List> list){
return list.stream().sorted(Comparator.comparing(AipClientController::comparingBySimilar).reversed()
.thenComparing(Comparator.comparing(AipClientController::comparingByCommand).reversed()))
.collect(Collectors.toList());
}
//以相似度排序
private static String comparingBySimilar(Map map){
return (String) map.get("similar");
}
//以指令长度排序
private static Integer comparingByCommand(Map map){
return ((String) map.get("command")).length();
} 第二种方案:在百度ai设置自定义词库,此方案准确率较高。
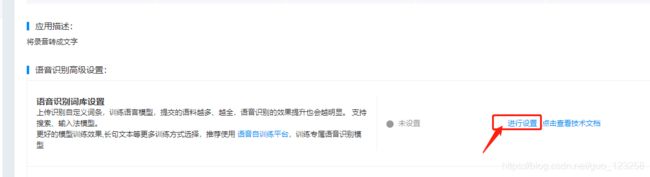
上传的数txt文件,对应的格式也简单,如下所示:

第二种方案:企业微信录音
1、实现原理图

2、实现思路
使用企业微信提供的录音接口,将语音上传到微信服务器,再下载到本地服务器进行解析。后面的思路同上。区别在于提供的音频文件方式不同而已,当然微信的客户端提供了语音转文字接口,但是识别率不高,好像不提供自定义词库,故还是将音频文件交给百度AI解析。
3、实现代码
后面补上,先写到这里。有其他想法,欢迎讨论。