SQL的一些常见案例
目录
一、实现累加
方法一 :开窗
方法二:自连接
二、删除有重复的数据
三、连续问题
方法一:位移函数:
方法二:row_num()构造新列
四、基于连接的两表比较
记录一下一些处理问题的 sql 案例,持续更新,有些可能很简单,不过编程重要的是处理问题的思路
一、实现累加
建表语句:
Create table test1 (person_id int, x int);
Truncate table test1;
insert into test1 (person_id, x) values ('1', '10');
insert into test1 (person_id, x) values ('2', '20');
insert into test1 (person_id, x) values ('3', '30');
insert into test1 (person_id, x) values ('4', '40');
insert into test1 (person_id, x) values ('5', '50');
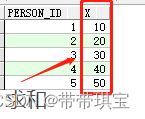
select * from test1
是一个如下的表:

方法一 :开窗
select test1.*,sum(x) over(order by person_id ) from test1
倒序排列:
select test1.*,sum(x) over(order by person_id desc) from test1
用这种方式可以实现分组累计求和
方法二:自连接
表a. 表b.

在如 MySQL 不支持开窗函数时,可以用第二种方法——自连接,用表a控制求和的位置,用表b的x求和(只用一个表就统一都是截至某行的sum值了,必须要自连接)
select a.person_id,(
SELECT SUM (b.x) FROM test1 b WHERE b.person_id <= a.person_id )from test1 a二、删除有重复的数据
建表:
Create table If Not Exists Person (Id int, Email varchar(255))
Truncate table Person
insert into Person (id, email) values ('1', '[email protected]')
insert into Person (id, email) values ('2', '[email protected]')
insert into Person (id, email) values ('3', '[email protected]')ID为唯一标识
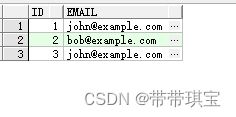
大致思路:
使用 max() 或 min() 函数对其唯一标识处理,仅保留一条数据,若无唯一标识 ORACLE 中可以使用 ROWID,筛选出需要唯一保留的数据,其他删除
DELETE FROM PERSON WHERE ID NOT IN
(SELECT MIN(ID) FROM PERSON GROUP BY EMAIL )三、连续问题
建表:
Create table Logs (id int, num int);
Truncate table Logs;
insert into Logs (id, num) values ('1', '1');
insert into Logs (id, num) values ('2', '1');
insert into Logs (id, num) values ('3', '1');
insert into Logs (id, num) values ('4', '2');
insert into Logs (id, num) values ('5', '1');
insert into Logs (id, num) values ('6', '2');
insert into Logs (id, num) values ('7', '2');ID为唯一标识
方法一:位移函数:
lead()/lag() over(),若至少重复三次,则其按ID排序前一位和后一位均为相同数字,如下:
SELECT LOGS.*,
lag(NUM,1) OVER(ORDER BY ID) as last,
lead(NUM,1) OVER(ORDER BY ID) as next
FROM LOGS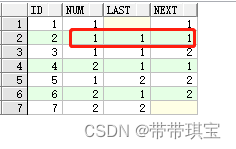
再筛选出前后一位均和 num 相等的数据,进行去重,即可得到至少重复三次的数字
SELECT distinct num ConsecutiveNums FROM(
SELECT LOGS.*,
lag(NUM,1) OVER(ORDER BY ID) last,
lead(NUM,1) OVER(ORDER BY ID) next
FROM LOGS )
where num=last and num=next 
位移函数还可以用来算移动平均哦
方法二:row_num()构造新列
这里的假设需要ID是连续的
select
Id,Num,row_number() over(partition by Num order by id) as RK,
id-row_number() over(partition by Num order by id) des
from Logs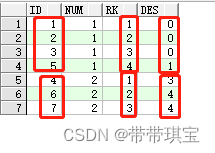
先看为何这样构造,注意到,使用开窗函数对 num 分组后,由于 row_num() 从 1 开始连续的,因此若 num 也是连续出现的,那每组内 ID - RK 之间的值将一直相等,接下来在这个表里只需要筛选出差值出现次数大于等于3次即可
SELECT num,des,count(1) FROM (
select
Id,Num,row_number() over(partition by Num order by id) as RK,
id-row_number() over(partition by Num order by id) des
from Logs) group by num,des
加上 count()>=3 的条件
注意:若ID是从0开始的序列会有误差,此时将ID+1再作差即可~~
SELECT num ConsecutiveNums FROM (
SELECT
Id,Num,row_number() over(partition by Num order by id) as RK,
id-row_number() over(partition by Num order by id) des
FROM Logs)
GROUP BY num,des HAVING count(1)>=3
这是解决连续问题比较通用的思想,如顾客连续购买日期、连续登录等等问题均可用该方法解决
四、基于连接的两表比较
两表做连接是 SQL 中最简单的处理之一,建表:
Create table A (X int);
Create table B (Y int);
Truncate table A;
Truncate table B;
insert into A (X) values (1);
insert into A (X) values (2);
insert into A (X) values (3);
insert into A (X) values (4);
insert into A (X) values (5);
insert into B (Y) values (1);
insert into B (Y) values (3);
insert into B (Y) values (5);
insert into B (Y) values (7);
insert into B (Y) values (9);
SELECT * FROM A;
SELECT * FROM B
左外连接
SELECT * FROM A left join b on a.x=b.y
右外连接
SELECT * FROM A right join b on a.x=b.y
全外连接
SELECT * FROM A FULL JOIN b on A.X=B.Y
实际上,简单外连接可以检查仅其中一表有而另外一表没有的数据(表中含有空值的),如有无某个行为的用户,某商品有无购买记录,或模拟销售退款行为等等