python自动化笔记(十)——openpyxl模块,操作excel管理测试数据
这里利用第三方库openpyxl来操作excel管理测试数据(注意:此模块只支持xlsx读写操作,旧版的xls不支持)
安装第三方库 pip install openpyxl
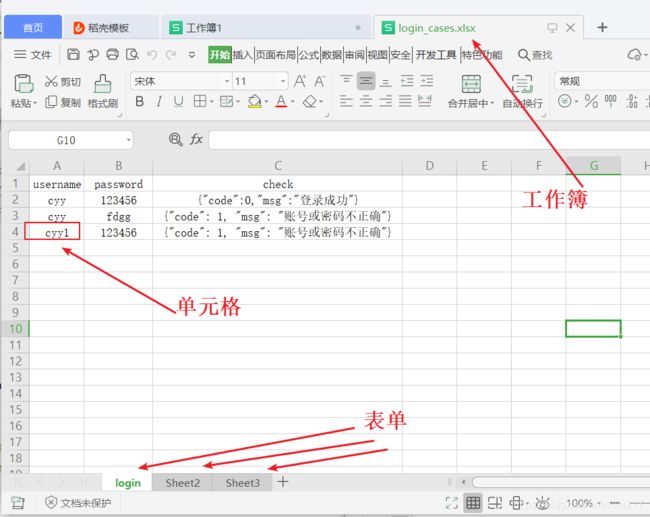
平常操作excel的流程(3个对象):
工作簿(Workbook)
表单(sheet)
单元格(cell)
一、加载excel数据文件
import os
file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),"login_cases.xlsx")
"""先找出文件的路径"""
from openpyxl import load_workbook """导入函数"""
wb = load_workbook(file_path) """加载完返回的是一个WorkBook对象"""
二、根据表单名称选择表单
变量名 = workbook[“表单名”]
import os
file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),"login_cases.xlsx")
"""先找出文件的路径"""
from openpyxl import load_workbook """导入函数"""
wb = load_workbook(file_path) """加载完返回的是一个WorkBook对象"""
###########################################################################################
sh = wb["login"] """用sh接收表单对象,括号里是表单名字"""
三、在表单当中获取单元格的数据
3.1 单元格对象:sh.cell(row,colum) # 下标从1开始(sh只是随意设置的一个接收对象的参数)
3.2 .value获取单元格的值
import os
file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),"login_cases.xlsx")
"""先找出文件的路径"""
from openpyxl import load_workbook """导入函数"""
wb = load_workbook(file_path) """加载完返回的是一个WorkBook对象"""
###########################################################################################
sh = wb["login"] """用sh接收表单对象,括号里是表单名字"""
###########################################################################################
cel = sh.cell(2,2) """取行和列都是2的一个单元格对象"""
print(cel.value) # 获取了一个单元格对象,要用.value获取单元格的值
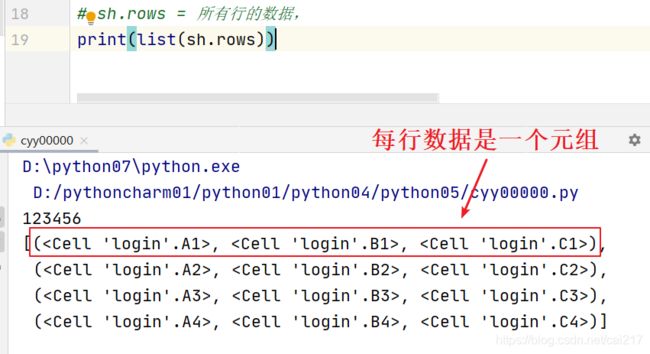
3.3 按行读取数据:
sh.rows = 所有行的数据,
list(sh.rows)返回的是一个列表,列表当中的成员:每一行的数据(元组的形式)
3.4 读取表单中所有数据
3.4.1、拿到字典的key值,通过列表切割,只取列表第一个元素(具体的excel内容布局,参考第一张图片)
import os
file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),"login_cases.xlsx")
"""先找出文件的路径"""
from openpyxl import load_workbook """导入函数"""
wb = load_workbook(file_path) """加载完返回的是一个WorkBook对象"""
###########################################################################################
sh = wb["login"] """用sh接收表单对象,括号里是表单名字"""
###########################################################################################
titles = []
for item in list(sh.rows)[0]:
titles.append(item.value)
print(titles)
输出如下:
['username', 'password', 'check'] #拿到字典的key值
3.4.2、把key和value组合到一起,形成一个字典,放到列表中。
"""这里省略之前的代码"""
all_datas = [] # 定义一个空列表,装字典数据
for item in list(sh.rows)[1:]: #遍历多个数据行
dict_value = {}
for index in range(len(item)):
dict_value[titles[index]] = item[index].value
dict_value["check"] = eval(dict_value["check"]) #去掉值的引号
all_datas.append(dict_value)
print(all_datas)
输出如下:
[{'username': 'cyy', 'password': 123456, 'check': {'code': 0, 'msg': '登录成功'}},
{'username': 'cyy', 'password': 'fdgg', 'check': {'code': 1, 'msg': '账号或密码不正确'}},
{'username': 'cyy1', 'password': 123456, 'check': {'code': 1, 'msg': '账号或密码不正确'}}]
3.4.3 用列表推导式、zip函数,读取表单数据(代码相对上个方法有减少)
"""这里省略之前的代码"""
"""1、拿到字典的key值"""
titles = [i.value for i in list(sh.rows)[0]]
all_datas = []
"""2、把key和value组合到一起,形成一个字典,放到列表中"""
for item in list(sh.rows)[1:]: #遍历多个数据行
value_list = [i.value for i in item]
res = dict(zip(titles,value_list)) # titles和每一行数据打包成字典
res["check"] = eval(res["check"]) #去掉值的引号
all_datas.append(res)
print(all_datas)
输出如下:
[{'username': 'cyy', 'password': 123456, 'check': {'code': 0, 'msg': '登录成功'}},
{'username': 'cyy', 'password': 'fdgg', 'check': {'code': 1, 'msg': '账号或密码不正确'}},
{'username': 'cyy1', 'password': 123456, 'check': {'code': 1, 'msg': '账号或密码不正确'}}]
四、得到当前表单当中,总行数和总列数
sh.max_row # 总行数
sh.max_column # 总列数
五、修改数据:
sh.cell(row,column).value = 新的值(只是在内存当中进行修改,并没有写入到文件当中)
六、保存数据(保存整个工作簿)
WorkBook对象(wb).save(文件路径)
# 若文件路径与本地文件路径不一致,则是另存为
# 若保存到原文件的时候,需要注意:文件没有被占用,
最后注意:从excel读取出来的数据只有两种,字符串或者数字。我们对excel数据的操作,都是加载到内存进行操作的,所以要想更改生效一定要保存。