Android LeakCanary2.1 和 OOM说再见
前言
说起OOM相信大家都不会陌生,一旦项目进入稳定性测试阶段,长时间的使用相信大多数的应用都不一定扛的住。
别担心,不是只有你的扛不住,我的也扛不住,当然大厂他也有扛不住的时候。
简单来说如果一个程序很大,那么他就有可能产生OOM,只是概率的高低不一样,稳定性测试后可能没有经过调教的产品4个小时左右就溢出了,而好的产品大概24小时或者更长时间后才会发生溢出。其实只要我们能将OOM发生的时间不断的延长,那么这个问题发生的概率就会无限低!因为从人的生理角度来说不可能不眠不休的不停用一个APP。
好了下面我们来讲讲LeakCanary这个大杀器,放心基本有他就够了,学好它之后无论是开发阶段的检测还是上限后的检测都能得心应手的解决掉。
一、介绍一下LeakCanary2.1
LeakCanary是一个十分方便的内存泄露检测框架,几乎没有什么引入成本。简单来说我们只需要在引用中增加:
debugImplementation 'com.squareup.leakcanary:leakcanary-android:2.1'
后再在我们的AndroidManifest中声明:
<provider
android:name="leakcanary.internal.AppWatcherInstaller$MainProcess"
android:exported="false"
android:authorities="com.jandroid.myapplication.leakcanary-installer" />
就完成了LeakCanary的引入。那么当我们有页面销毁的时候,一旦发生内存泄露,就会已通知的形式出现在通知栏,当我们点进去后还很贴心的会帮我们记录下所有的历史内存泄露。是不是很贴心,强迫症患者找到一个,解决一个,删除一个,都删空的时候是不是满满的成就感!
到这我们就完成了LeakCanary的引入工作,如果出现泄露我们就可以抓他了。
下面我们开始逐步泡洗LeakCanary。
二、LeakCanary是怎么初始化的
讲完了引入,我们来看看他是怎么初始化的。
其实基础好的小伙伴已经已经知道了,在AndroidManifest里面声明了一个Provider。在Application初始化的时候就完成了ContentProvider的初始化,他们调用顺序如下:
Application —》attachBaseContext —》 ContentProvider#onCreate —》Application#onCreate —》 Activity#onCreate
由以上的顺序我们可以知道,在Application被创建出来后,调用Application#onCreate方法之前,我们的ContentProvider#onCreate就会被调用了,而这里面已经有了Context对象,所以可以顺利的完成无代码的初始化工作。
三、这样初始化的缺点是什么?
为什么会问这样的问题,那肯定是和冷启动有关系,首先我们使用了Provider的初始化模式之后,我们就不能控制他何时启动了,换句话说,他只能在Application启动的时候完成他的启动,可能一个两个框架这样做还可以,但是如果我们使用的三方都这样做,那么势必会造成冷启动时间的延长,这对APP来说显然是一个不好的体验。
不过我们话说回来,如果只是LeakCanary本身,我感觉这样初始化是没有任何问题的。因为LeakCanary他是面向开发阶段的,上线后我们是不能使用的,所以他不会引入我们冷启动时间增加的问题。另外我认为LeakCanary在程序启动后就启动是十分符合生命周期规则的,因为他的责任是抓住程序运行期间所有可能的泄漏点。
四、内存泄露和内存溢出有什么关系?
内存泄露是指因为不正确的使用引用,导致本来应该销毁的对象,由于存在引用导致无法释放。那么时间长了由于只有创建没有销毁,导致类似的对象越来越多,他们会逐渐的占满整个内存空间,当我们再创建对象的时候,由于没有足够的空间了,就会产生内存溢出。简单来说,内存泄露是导致内存溢出的元凶。
这个就像一个煤气罐本来充完气后是准备放气的,结果放气失败了,还再不断的充气,那么时间长了煤气罐爆炸只是时间问题。
还是以煤气罐为例,煤气罐是否容易爆胎和煤气罐的大小是有直接关系的,这里的煤气罐其实就是我们的内存,所以当我们使用性能较好的机器作为测试机时可能不会发生内存溢出的问题,等真正上线后,在一些性能较低的机器上缺频繁发生。
五、说说内存泄露的原理
内存泄露的原因:本来应该释放的对象,由于存在引用而无法释放,导致内存无法被回收。
例如我们非静态的声明Handler的时候总是会有警告。
这一块如果细说起来可能会有一点话长,我简单说一下他的原理,简单来说就是不能回收的对象,对你要回收的对象有引用,那么需要被回收的对象无法被回收,进而导致泄漏。想知道Handler这里为什么标黄的同学可以看我Handler解析的帖子。
六、Java中的四种引用
Java中的四种引用主要是:
6.1 强引用
即我们最常使用的Object object = new Object()的写法。
只要强引用存在,垃圾回收器将永远不会回收被引用的对象,哪怕内存不足时,JVM也会直接抛出OutOfMemoryError,不会去回收。如果想中断强引用与对象之间的联系,可以显示的将强引用赋值为null,这样一来,JVM就可以适时的回收对象了
6.2 SoftReference(软引用)
软引用是用来描述一些非必需但仍有用的对象。在内存足够的时候,软引用对象不会被回收,只有在内存不足时,系统则会回收软引用对象,如果回收了软引用对象之后仍然没有足够的内存,才会抛出内存溢出异常。这种特性常常被用来实现缓存技术,比如网页缓存,图片缓存等。
例如有一个写法,非静态Handler内部声明一个SoftReference持有的Activity对象。
6.3 WeakReference(弱引用)
弱引用的引用强度比软引用要更弱一些,无论内存是否足够,只要 JVM 开始进行垃圾回收,那些被弱引用关联的对象都会被回收。在 JDK1.2 之后,用 java.lang.ref.WeakReference 来表示弱引用。
6.4 PhantomReference(虚引用)
虚引用是最弱的一种引用关系,如果一个对象仅持有虚引用,那么它就和没有任何引用一样,它随时可能会被回收,在 JDK1.2 之后,用 PhantomReference 类来表示,通过查看这个类的源码,发现它只有一个构造函数和一个 get() 方法,而且它的 get() 方法仅仅是返回一个null,也就是说将永远无法通过虚引用来获取对象,虚引用必须要和 ReferenceQueue 引用队列一起使用。
6.5 ReferenceQueue
引用队列可以与软引用、弱引用以及虚引用一起配合使用,当垃圾回收器准备回收一个对象时,如果发现它还有引用,那么就会在回收对象之前,把这个引用加入到与之关联的引用队列中去。程序可以通过判断引用队列中是否已经加入了引用,来判断被引用的对象是否将要被垃圾回收,这样就可以在对象被回收之前采取一些必要的措施。
Reference(T referent) {
this(referent, null);
}
Reference(T referent, ReferenceQueue<? super T> queue) {
this.referent = referent;
this.queue = (queue == null) ? ReferenceQueue.NULL : queue;
}
其内部提供2个构造函数,一个带queue,一个不带queue。其中queue的意义在于,我们可以在外部对这个queue进行监控。即如果有对象即将被回收,那么相应的reference对象就会被放到这个queue里。我们拿到reference,就可以再作一些事务。
而如果不带的话,就只有不断地轮询reference对象,通过判断里面的get是否返回null( phantomReference对象不能这样作,其get始终返回null,因此它只有带queue的构造函数 )。这两种方法均有相应的使用场景,取决于实际的应用。如weakHashMap中就选择去查询queue的数据,来判定是否有对象将被回收。而ThreadLocalMap,则采用判断get()是否为null来作处理。
如果我们在创建一个引用对象时,指定了ReferenceQueue,那么当引用对象指向的对象达到合适的状态(根据引用类型不同而不同)时,GC 会把引用对象本身添加到这个队列中,方便我们处理它,因为“引用对象指向的对象 GC 会自动清理,但是引用对象本身也是对象(是对象就占用一定资源),所以需要我们自己清理。”
WeakReference对象进入到queue之后,相应的referent为null。
SoftReference对象,如果对象在内存足够时,不会进入到queue,自然相应的referent不会为null。如果需要被处理( 内存不够或其它策略 ),则置相应的referent为null,然后进入到queue。通过debug发现,SoftReference是pending状态时,referent就已经是null了,说明此事referent已经被GC回收了。
FinalReference对象,因为需要调用其finalize对象,因此其reference即使入queue,其referent也不会为null,即不会clear掉。
七、什么是GCRoot
所有的可达性算法都会有起点,那么这个起点就是GC Root,也就是需要通过GC Root 找出所有活的对象,那么剩下所有的没有标记的对象就是需要回收的对象。
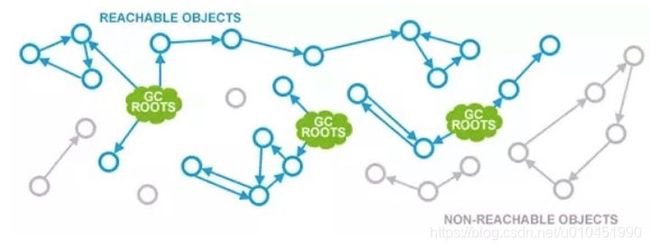
7.1 GC Root 的特点
当前时刻存活的对象!
7.2 GC Root 在哪里
- 所有Java线程当前活跃的栈帧里指向GC堆里的对象的引用;换句话说,当前所有正在被调用的方法的引用类型的参数/局部变量/临时值。
- VM的一些静态数据结构里指向GC堆里的对象的引用,例如说HotSpot VM里的Universe里有很多这样的引用。
总结来说:被栈帧内活静态数据结构所引用的GC堆里面的对象都是GCRoot。
7.3 哪些对象可以作为 GC Roots 的对象:
- 虚拟机栈中局部变量(也叫局部变量表)中引用的对象
- 方法区中类的静态变量、常量引用的对象 本地方法栈中 JNI
- (Native方法)引用的对象
八、LeakCanary初始化的时候做了什么
override fun onCreate(): Boolean {
val application = context!!.applicationContext as Application
InternalAppWatcher.install(application)
return true
}
fun install(application: Application) {
SharkLog.logger = DefaultCanaryLog()
SharkLog.d { "Installing AppWatcher" }
checkMainThread()
if (this::application.isInitialized) {
return
}
InternalAppWatcher.application = application
val configProvider = { AppWatcher.config }
ActivityDestroyWatcher.install(application, objectWatcher, configProvider)
FragmentDestroyWatcher.install(application, objectWatcher, configProvider)
onAppWatcherInstalled(application)
}
LeakCanary通过InternalAppWatcher#install方法完成了主要的初始化任务
- 通过Looper检查是否在主线程中,否则抛出异常。
- 通过ActivityDestroyWatcher完成监听 Activity.onDestroy()的操作。
- 通过FragmentDestroyWatcher完成监听 Fragment.onDestroy()的操作。
- 通过InternalLeakCanary初始化检测内存泄露过程中需要用到的对象。
为什么要说下这里那,因为这里面很直接的体现了LeakCanary的意图,他是要监听我们Activtiy和Fragment销毁后是否有效的完成了内存的清理。
注意这样是他的原理之一。
8.1 ActivityDestroyWatcher
internal class ActivityDestroyWatcher private constructor(
private val objectWatcher: ObjectWatcher,
private val configProvider: () -> Config
) {
private val lifecycleCallbacks =
object : Application.ActivityLifecycleCallbacks by noOpDelegate() {
override fun onActivityDestroyed(activity: Activity) {
if (configProvider().watchActivities) {
objectWatcher.watch(
activity, "${activity::class.java.name} received Activity#onDestroy() callback"
)
}
}
}
companion object {
fun install(
application: Application,
objectWatcher: ObjectWatcher,
configProvider: () -> Config
) {
val activityDestroyWatcher =
ActivityDestroyWatcher(objectWatcher, configProvider)
application.registerActivityLifecycleCallbacks(activityDestroyWatcher.lifecycleCallbacks)
}
}
}
8.2 FragmentDestroyWatcher
- FragmentDestroyWatcher为静态类,install方法为静态方法
- 如果SDK是android 8.0及以上,则使用AndroidOFragmentDestroyWatcher监听Fragment的生命周期。
- 通过getWatcherIfAvailable方法加载support fragment的生命周期监听AndroidSupportFragmentDestroyWatcher。
- 通过getWatcherIfAvailable方法加载AndroidX的生命周期监听类AndroidXFragmentDestroyWatcher。
- 通过监听activity的onCreate方法,在activity方法之后,在调用Fragment监听类的invoke方法,完成Fragment监听类的初始化任务。这里监听activity是因为Fragment需要依附于activity,当activity创建的时候,可能会有Fragment对象的创建。
总结一下,其实fragment有三个监听类,分别是:
- AndroidOFragmentDestroyWatcher
- AndroidSupportFragmentDestroyWatcher
- AndroidXFragmentDestroyWatcher
但是这三个类的本质实现没有差别。
这里的源码,建议阅读一下。
8.3 FragmentLifecycleCallbacks
上面的FragmentDestroyWatcher其实写法都差不多,这里面我们还需要注意一下FragmentLifecycleCallbacks的实现逻辑:
private val fragmentLifecycleCallbacks = object : FragmentManager.FragmentLifecycleCallbacks() {
override fun onFragmentViewDestroyed(
fm: FragmentManager,
fragment: Fragment
) {
val view = fragment.view
if (view != null && configProvider().watchFragmentViews) {
objectWatcher.watch(
view, "${fragment::class.java.name} received Fragment#onDestroyView() callback " +
"(references to its views should be cleared to prevent leaks)"
)
}
}
override fun onFragmentDestroyed(
fm: FragmentManager,
fragment: Fragment
) {
if (configProvider().watchFragments) {
objectWatcher.watch(
fragment, "${fragment::class.java.name} received Fragment#onDestroy() callback"
)
}
}
}
这里面我们可以看到Fragment的销毁主要监听了两个对象一个是View一个是Fragment自身。
8.4 InternalAppWatcher
override fun invoke(application: Application) {
this.application = application
AppWatcher.objectWatcher.addOnObjectRetainedListener(this)
val heapDumper = AndroidHeapDumper(application, leakDirectoryProvider)
val gcTrigger = GcTrigger.Default
val configProvider = { LeakCanary.config }
val handlerThread = HandlerThread(LEAK_CANARY_THREAD_NAME)
handlerThread.start()
val backgroundHandler = Handler(handlerThread.looper)
heapDumpTrigger = HeapDumpTrigger(
application, backgroundHandler, AppWatcher.objectWatcher, gcTrigger, heapDumper,
configProvider
)
application.registerVisibilityListener { applicationVisible ->
this.applicationVisible = applicationVisible
heapDumpTrigger.onApplicationVisibilityChanged(applicationVisible)
}
addDynamicShortcut(application)
disableDumpHeapInTests()
}
- 初始化一些检测内存泄露过程中需要的对象。
- 用于处理ObjectWatcher上报泄露的监听者。
- 通过AndroidHeapDumper进行内存泄漏之后进行 heap dump (写文件和通知)。
- 赋值gcTrigger , gcTrigger 手动调用 GC 再次确认内存泄露。
- 启动内存泄漏检查的线程。
- 通过registerVisibilityListener监听应用程序的可见性。
8.5 总结
通过以上的部分我们终于完成了初始化阶段的阅读。
LeakCanary的初始化阶段主要完成了对Activity onDestroy和Fragment onDestory 的监听。
同时初始化了LeakCanary的功能对象如 AndroidHeapDumper、GcTrigger.Default
同时启动了内存泄露的检测线程。
九、ObjectWatcher
9.1 watch(watchedObject: Any,description: String)
通过上面的一顿操作我们知道了,LeakCanary所有的逻辑操作最后都指向了ObjectWatcher。
ObjectWatcher类不是很长让我们慢慢拜读。
首先我们先来看核心方法,从上面的所有的onDestroy方法都调用了ObjectWatcher#watch方法。
@Synchronized fun watch(watchedObject: Any,description: String) {
if (!isEnabled()) {
return
}
removeWeaklyReachableObjects()
val key = UUID.randomUUID().toString()
val watchUptimeMillis = clock.uptimeMillis()
val reference =KeyedWeakReference(watchedObject, key, description, watchUptimeMillis, queue)
SharkLog.d {"Watching " +
(if (watchedObject is Class<*>) watchedObject.toString()
else "instance of ${watchedObject.javaClass.name}") +
(if (description.isNotEmpty()) " ($description)" else "") +" with key $key"
}
watchedObjects[key] = reference
checkRetainedExecutor.execute {
moveToRetained(key)
}
}
我们先看传入的参数 :
/**
* watchedObject:Kotlin中的Any相当于Java的Object 意思就是所有对象都可以传入
* description:该对象的描述
*/
watch(watchedObject: Any,description: String)
说一下这个地方的原因是,LeakCanary只是帮我们完成了Activity和Fragment的销毁监听,但是一些其他对象的销毁他是无法感知的,那么此时我们就可以自己在对象的release方法直接调用:
AppWatcher.INSTANCE.getObjectWatcher().watch(watchedObject: Any,description: String);
来完成其他对象的监听。
9.2 removeWeaklyReachableObjects
private fun removeWeaklyReachableObjects() {
// WeakReferences are enqueued as soon as the object to which they point to becomes weakly
// reachable. This is before finalization or garbage collection has actually happened.
var ref: KeyedWeakReference?
do {
ref = queue.poll() as KeyedWeakReference?
if (ref != null) {
watchedObjects.remove(ref.key)
}
} while (ref != null)
}
这段代码也比较简单,先声明一个可空的 var ref: KeyedWeakReference?,然后从引用队列中取出已经回收的弱引用对象。如果弱引用对象不为空那么从 watchedObjects 移除该对象。
9.3 创建弱引用对象加到watchedObjects中
val key = UUID.randomUUID().toString()
val watchUptimeMillis = clock.uptimeMillis()
val reference =
KeyedWeakReference(watchedObject, key, description, watchUptimeMillis, queue)
SharkLog.d {
"Watching " +
(if (watchedObject is Class<*>) watchedObject.toString() else "instance of ${watchedObject.javaClass.name}") +
(if (description.isNotEmpty()) " ($description)" else "") +
" with key $key"
}
watchedObjects[key] = reference
接下来这一块的代码也很好理解,将被观察的对象,和LeakCanary的自定义弱引用形成关联,传入ReferenceQueue,方便例如前面对引用的管理;之后放入到watchedObjects中。
9.4 执行checkRetainedExecutor
首先我们要回顾一下,前面InternalAppWatcher中声明的:
private val checkRetainedExecutor = Executor {
mainHandler.postDelayed(it, AppWatcher.config.watchDurationMillis)
}
这个是作为ObjectWatcher的构造参数传入的,结合上面的代码再看:
checkRetainedExecutor.execute {
moveToRetained(key)
}
其意图就是在主线程延迟5秒后执行moveToRetained(key)的方法。
9.5 moveToRetained
@Synchronized private fun moveToRetained(key: String) {
removeWeaklyReachableObjects()
val retainedRef = watchedObjects[key]
if (retainedRef != null) {
retainedRef.retainedUptimeMillis = clock.uptimeMillis()
onObjectRetainedListeners.forEach { it.onObjectRetained() }
}
}
执行到这里还是先移除一下已经回收的弱引用对象。然后根据传入的key拿到弱引用对象。
如果弱引用对象为空的话那么相安无事,不为空的话(证明没有被回收),更新他的时间,同时开始回调所有的OnObjectRetainedListener。
十、onObjectRetained
虽然,onObjectRetainedListeners是一个集合,但是在整个LeakCanary内部其实只有一个具体实现:
internal object InternalLeakCanary : (Application) -> Unit, OnObjectRetainedListener
当然我们依然可以仿照这个写法增加我们自己的ObjectRetainedListener:
AppWatcher.INSTANCE.getObjectWatcher().addOnObjectRetainedListener();
这里先看下LeakCanary的onObjectRetained做了什么操作。
这里面回应我们刚才说的LeakCanary的初始化阶段中的:AppWatcher.objectWatcher.addOnObjectRetainedListener(this)
所以ObjectWatcher中实际调用的就是InternalLeakCanary#onObjectRetained。
十一、HeapDumpTrigger
InternalLeakCanary中的onObjectRetained方法实际上执行的是heapDumpTrigger.onObjectRetained()方法:
override fun onObjectRetained() {
if (this::heapDumpTrigger.isInitialized) {
heapDumpTrigger.onObjectRetained()
}
}
11.1 HeapDumpTrigger的调用顺序
这里就不给大家粘贴源码了,这里先给出下面的执行逻辑:
- onObjectRetained继续调用
scheduleRetainedObjectCheck(reason = "found new object retained",rescheduling = false ) scheduleRetainedObjectCheck根据checkScheduledAt判断是否需要检测对象,需要检测时更新检测的延迟时间,使用backgroundHandler发出检测操作,检测操作内将checkScheduledAt置为0,检测工作由checkRetainedObjects(reason)完成,此时同时完成了线程的切换backgroundHandler.postDelayed({ checkScheduledAt = 0 checkRetainedObjects(reason) }, delayMillis)。- checkRetainedObjects里面先拿到
objectWatcher.retainedObjectCount如果大于0,那么调用:
if (retainedReferenceCount > 0) {
gcTrigger.runGc()
retainedReferenceCount = objectWatcher.retainedObjectCount
}
interface GcTrigger {
fun runGc()
object Default : GcTrigger {
override fun runGc() {
Runtime.getRuntime().gc()
enqueueReferences()
System.runFinalization()
}
private fun enqueueReferences() {
try {
Thread.sleep(100)
} catch (e: InterruptedException) {
throw AssertionError()
}
}
}
}
- 之后检测存活对象数如果为0
showNoMoreRetainedObjectNotification,大于0且小于允许存活的对象数(此数值默认为5)返回 showRetainedCountNotification scheduleRetainedObjectCheck 。以上两个操作都返回true。如果大于5,会判断两次 heap dump的间隔小于60s,则不在进行 heap dump处理,只做showRetainedCountNotification通知栏通知并在次发起scheduleRetainedObjectCheck检测,大于60时进行dumpHeap。 - 在
AndroidHeapDumper生成Debug.dumpHprofData(heapDumpFile.absolutePath)也就是 heapDumpFile。 - 这个文件是 Hprof ,Hprof二进制文件协议,需要解析。解析工作在
HeapAnalyzerService.runAnalysis中完成。 HeapAnalyzerService是一个前台服务用于分析Hprof文件,总体的思路是根据hprof文件的二进制协议将文件的内容解析成一个图的数据结构,然后广度遍历这个图找到最短路径,路径的起始就是GCRoot对象,结束就是泄漏的对象。- 结果的存储与通知主要在DefaultOnHeapAnalyzedListener中完成。DefaultOnHeapAnalyzedListener主要做了两件事 :存储泄漏分析结果到数据库中 ,展示通知,提醒用户去查看内存泄漏情况。
十二、为什么LeakCanary不能用于线上
1.每次内存泄漏以后,都会生成一个.hprof文件,然后解析,并将结果写入.hprof.result。增加手机负担,引起手机卡顿等问题。
2.多次调用GC,可能会对线上性能产生影响
3.同样的泄漏问题,会重复生成 .hprof 文件,重复分析并写入磁盘。
4.hprof文件较大,信息回捞成问题。
了解了这些问题,我们可以尝试提出一些解决方案:
1.可以根据手机信息来设定一个内存阈值 M ,当已使用内存小于 M时,如果此时有内存泄漏,只将泄漏对象的信息放入内存当中保存,不生成.hprof文件。当已使用大于 M 时,生成.hprof文件
2.当引用链路相同时,可根据实际情况去重。
3.不直接回捞.hprof文件,可以选择回捞分析的结果
4.可以尝试将已泄漏对象存储在数据库中,一个用户同一个泄漏只检测一次,减少对用户的影响
十三、如何解决线上的泄露问题
其实LeakCanary的设计时十分良好的,他是面向接口的,里面只是给出了默认的实现,我们完全可以重写里面的模块进而实现线上检测内存泄露的问题。
他的缺点我们上面已经提到了:
- 主要就是多次GC,GC必然导致卡顿。
- 会从堆栈中取出hprof文件,在对文件进行解析,这个过程都是耗时操作。
- 每次泄露都会上报,其实我们并不需要每次都上报,只需要一次就可以了-》引入去重操作。
完成以上操作只有我们,再补充其他的内存处理策略,就可以极大的降低OOM发生的概率。
基于上面的流程分析我们可以知道真正的核心逻辑是在ObjectWatcher.watch方法中开始进行的。
这里我们再回顾一下watch方法的调用流程,只贴出核心代码:
@Synchronized fun watch(watchedObject: Any,description: String) {
...
checkRetainedExecutor.execute {
moveToRetained(key)
}
}
@Synchronized private fun moveToRetained(key: String) {
removeWeaklyReachableObjects()
val retainedRef = watchedObjects[key]
if (retainedRef != null) {
retainedRef.retainedUptimeMillis = clock.uptimeMillis()
onObjectRetainedListeners.forEach { it.onObjectRetained() }
}
}
同时他还有这样两个方法:
@Synchronized fun addOnObjectRetainedListener(listener: OnObjectRetainedListener) {
onObjectRetainedListeners.add(listener)
}
@Synchronized fun removeOnObjectRetainedListener(listener: OnObjectRetainedListener) {
onObjectRetainedListeners.remove(listener)
}
那么我们完全可以这样操作:
AppWatcher.INSTANCE.getObjectWatcher().removeOnObjectRetainedListener(InternalLeakCanary.INSTANCE);
AppWatcher.INSTANCE.getObjectWatcher().addOnObjectRetainedListener(() -> {
//My ObjectRetainedListener
});
我们前面也说了整个LeakCanary中仅初始化了一个OnObjectRetainedListener,那么一旦移除了他,换成我们自己的,那么上面的问题就有了逐个被击破的可能。
这里我们就不再一一展开了。
十四、兜底策略
14.1 彻底释放我们View层引用
我们知道LeakCanary对Fragment的View也是有观察的,那么我们是不是仍然可以在Activity销毁的时候再次释放所有已经注入的资源,以下仅供参考。
fun clearView(viewGroup: ViewGroup) {
val childCount: Int = viewGroup.getChildCount()
for (i in 0 .. childCount) {
val child: View = viewGroup.getChildAt(i)
if (child is ViewGroup) {
child.setBackground(null)
clearView(child)
} else {
if (child != null) {
child.background = null
}
if (child is ImageView) {
child.setImageDrawable(null)
} else if (child is EditText) {
child.removeTextChangedListener()//此方法需要自行反射
}
}
}
}
14.2 注意内存缓存
举个例子,一般来说,我们无论使用哪种图片加载框架,他都会对图片进行缓存,当然这是为了更好的用户体验。
但是从内存泄露的角度来说,他们也可能是引起OOM的一个因素,所以当我们检测到内存不足时,可以强行的释放图片框架所占用的内存。
此处仅是一个参考,当我们有大内存对象缓存时,在我们发现可能发生OOM前可以清理掉他们来应应急。还是那句话,只要发生OOM的时间无限远,即使有泄露也不会发生OOM。