18-flink-1.10.1-Table API & Flink SQL
目录
1 Table API 和Flink SQL 是什么
2 简单使用table api 和 flink SQL
2.1 引入依赖
2.2 代码demo
3 基本程序结构
4 创建TableEnvironment
5 table
5.1 table 是什么
5.2 创建表
5.3 代码演示
6 表的查询
6.1 表的查询 Table API
6.2 表的查询 Flink SQL
6.3 代码示例
7 将DataStream 转换成表
8 输出表
8.1 什么是输出表
8.2 输出到文件
9 更新模式
9.1 输出到kafak
9.2 输出到elasticsearch
9.3 输出到mysql
10 将Table 转换成DataStream
11 查看执行计划
12 动态表
12.1 动态表
12.2 动态表和持续查询
12.3 将流转换成动态表
12.4 持续查询
12.5 将动态表转换成DataStream
13 时间特性
13.1 定义处理时间(processing time )
13.2 定义时间时间(event time)
14 窗口
1 Table API 和Flink SQL 是什么
Flink 对流处理和批处理,提供了统一的上层API
Table API 是一套内嵌在Java 和Scala 语言中的查询API,它允许以非常直观的方式组合来自一些关系院选符的查询
Flink 的SQL支持基于实现了SQL标准的Apache calcite

2 简单使用table api 和 flink SQL
2.1 引入依赖
① flink-table-common
通过自定义函数,格式等扩展表生态系统的通用模块。
② flink-table-api-java-bridge
使用Java编程语言支持DataStream / DataSet API的Table&SQL API。
③ flink-table-api-scala-bridge
使用Scala编程语言支持DataStream / DataSet API的Table&SQL API。
④ flink-table-planner
表程序规划器和运行时。
link-table-planner引入后会自动引入上面①~④四个jar 包
老版本planner
org.apache.flink
flink-table-planner_2.12
1.10.1
flink-table-planner-blink
新版本planner
org.apache.flink
flink-table-planner-blink_2.12
1.10.1

2.2 代码demo
package com.study.liucf.table
import com.study.liucf.bean.LiucfSensorReding
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.Table
import org.apache.flink.table.api.scala._
object LiucfTableAPIDemo1 {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val inputStream: DataStream[String] = env.readTextFile("src\\main\\resources\\sensor.txt")
val ds: DataStream[LiucfSensorReding] = inputStream.map(r=>{
val arr = r.split(",")
LiucfSensorReding(arr(0),arr(1).toLong,arr(2).toDouble)
})
//定义表环境
val tableEnv = StreamTableEnvironment.create(env)
//基于流创建一张表
val flinkTable: Table = tableEnv.fromDataStream(ds)
//第一种方式:调用table api 进行转换
val resultFlinkTable1 = flinkTable
.select("id,temperature")
.filter("id == 'sensor_1'")
resultFlinkTable1.printSchema()
//基于表创建流
val resStream1 = tableEnv.toAppendStream[(String,Double)](resultFlinkTable1)
//输出结果
resStream1.print("Table API")
//第二种方式:把 Flink Table 注册成一张表然后进行转换
tableEnv.createTemporaryView("flinkTableLiucf", flinkTable)
//转换sql
val flinkSQLStr = "select id,temperature from flinkTableLiucf where id = 'sensor_1'"
//执行转换
val resultFlinkTable2: Table = tableEnv.sqlQuery(flinkSQLStr)
resultFlinkTable2.printSchema()
//基于表创建流
val resStream2 = tableEnv.toAppendStream[(String,Double)](resultFlinkTable2)
//输出结果
resStream2.print("Flink SQL")
env.execute("table api test")
}
}

3 基本程序结构

4 创建TableEnvironment
创建表的执行环境,需要将flink流处理的执行环境传入
val tableEnv = StreamTaleEnvironment.create(env)
TableEnvironment 是flink 中集成Table API 和 SQL 的核心概念,所有对表的基本操作都基于TableEnvironment
- 注册 Catalog
Catalog描述了数据集的属性和数据集的位置,这样用户不需要指出数据集的位置就可以获得某个数据集。
- 在Catalog中注册表
- 执行SQL查询
- 注册用户自定义函数(UDF)
5 table
5.1 table 是什么

5.2 创建表

5.3 代码演示
package com.study.liucf.table
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.{DataTypes, Table}
import org.apache.flink.table.api.scala.StreamTableEnvironment
import org.apache.flink.table.descriptors.{FileSystem, OldCsv, Schema}
import org.apache.flink.table.types.{DataType, FieldsDataType}
object LiucfTableAPIConnectFile {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val tableEnv = StreamTableEnvironment.create(env)
val path = "src/main/resources/sensor.csv"
tableEnv
.connect(new FileSystem().path(path))//定义表的数据来源,和外部系统建立连接
.withFormat(new OldCsv())//定义数据格式化方式
.withSchema(new Schema() //定义表的结构
.field("id",DataTypes.STRING())
.field("timestamp",DataTypes.BIGINT())
.field("temperature",DataTypes.DOUBLE())
).createTemporaryTable("file_table_test")//创建临时表
//把临时表转换成 Table
val table: Table = tableEnv.from("file_table_test")
table.printSchema()
//把TAble转换成数据流
val value = tableEnv.toAppendStream[(String,Long,Double)](table)
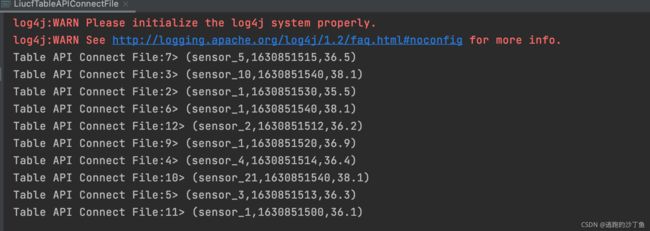
value.print("Table API Connect File")
env.execute("Table API")
}
}
 6 表的查询
6 表的查询
6.1 表的查询 Table API

6.2 表的查询 Flink SQL

6.3 代码示例
查询转换参考2.2
package com.study.liucf.table
import com.study.liucf.bean.LiucfSensorReding
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.Table
import org.apache.flink.table.api.scala._
object LiucfTableAPIDemo1 {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val inputStream: DataStream[String] = env.readTextFile("src\\main\\resources\\sensor.txt")
val ds: DataStream[LiucfSensorReding] = inputStream.map(r=>{
val arr = r.split(",")
LiucfSensorReding(arr(0),arr(1).toLong,arr(2).toDouble)
})
//定义表环境
val tableEnv = StreamTableEnvironment.create(env)
//基于流创建一张表
val flinkTable: Table = tableEnv.fromDataStream(ds)
//第一种方式:调用table api 进行转换
val resultFlinkTable1 = flinkTable
.select("id,temperature")
.filter("id == 'sensor_1'")
resultFlinkTable1.printSchema()
//基于表创建流
val resStream1 = tableEnv.toAppendStream[(String,Double)](resultFlinkTable1)
//输出结果
resStream1.print("Table API")
//第二种方式:把 Flink Table 注册成一张表然后进行转换
tableEnv.createTemporaryView("flinkTableLiucf", flinkTable)
//转换sql
val flinkSQLStr = "select id,temperature from flinkTableLiucf where id = 'sensor_1'"
//执行转换
val resultFlinkTable2: Table = tableEnv.sqlQuery(flinkSQLStr)
resultFlinkTable2.printSchema()
//基于表创建流
val resStream2 = tableEnv.toAppendStream[(String,Double)](resultFlinkTable2)
//输出结果
resStream2.print("Flink SQL")
env.execute("table api test")
}
}
7 将DataStream 转换成表



8 输出表
8.1 什么是输出表

8.2 输出到文件
package com.study.liucf.table
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.{DataTypes, Table}
import org.apache.flink.table.api.scala._
import org.apache.flink.table.descriptors.{Csv, FileSystem, OldCsv, Schema}
object LiucfTableAPIOutputFile {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val tableEnv = StreamTableEnvironment.create(env)
val path = "src/main/resources/sensor.csv"
tableEnv
.connect(new FileSystem().path(path))//定义表的数据来源,和外部系统建立连接
//.withFormat(new OldCsv())//定义数据格式化方式,OldCsv只适用文本文件的csv,
.withFormat(new Csv())//定义数据格式化方式,Csv除了适用文本文件的csv,还能格式化如kafka等非标准的csv格式数据
.withSchema(new Schema() //定义表的结构
.field("id",DataTypes.STRING())
.field("timestamp",DataTypes.BIGINT())
.field("temperature",DataTypes.DOUBLE())
).createTemporaryTable("file_input_table")//创建临时表
//1 转换操作
val inputTable: Table = tableEnv.from("file_input_table")
inputTable.printSchema()
//1.2 简单转换
val transTable = inputTable
.select('id,'temperature)
.filter('id === "sensor_1")
//1.3 聚合转换
val aggTable = inputTable
.groupBy('id)
.select('id,'id.count as 'count)
transTable.toAppendStream[(String,Double)].print("transTable")
//下面这样会报错:Table is not an append-only table. Use the toRetractStream() in order to handle add and retract messages.
// aggTable.toAppendStream[(String,Long)].print("aggTable")
aggTable.toRetractStream[(String,Long)].print("aggTable")
//2 输出到文件
val outPath1 = "src/main/resources/sensorOut1.csv"
val outPath2 = "src/main/resources/sensorOut2.csv"
tableEnv
.connect(new FileSystem().path(outPath1))
.withFormat(new Csv())
.withSchema(new Schema()
.field("id",DataTypes.STRING())
.field("temperature",DataTypes.DOUBLE())
).createTemporaryTable("file_out_table1")
transTable.insertInto("file_out_table1")
// 下面的处理会报错,所以聚合不适合写入文件的TableSink
//Exception in thread "main" org.apache.flink.table.api.TableException: AppendStreamTableSink requires that Table has only insert changes.
// tableEnv
// .connect(new FileSystem().path(outPath2))
// .withFormat(new Csv())
// .withSchema(new Schema()
// .field("id",DataTypes.STRING())
// .field("temperature",DataTypes.BIGINT())
// ).createTemporaryTable("file_out_table2")
// aggTable.insertInto("file_out_table2")
env.execute("Table API")
}
}
9 更新模式
上面8.2 示例可以知道,当一个聚合的结果写入到文件系统的时候会报错:AppendStreamTableSink requires that Table has only insert changes
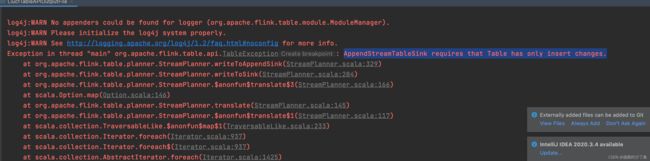
那么聚合之后的结果应该如何保存呢?这就要了解更新模式了
9.1 输出到kafak

package com.study.liucf.table
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.{DataTypes, Table}
import org.apache.flink.table.api.scala._
import org.apache.flink.table.descriptors.{Csv, Kafka, Schema}
object LiucfTableAPIKafkaPipeline {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val tableEnv = StreamTableEnvironment.create(env)
tableEnv.connect(new Kafka()//定义表的数据来源,和外部系统建立连接
.version("0.11")
.topic("flink_kafka2table")
.property("zookeeper.connect","localhost:2181")
.property("bootstrap.services","localhost:9092")
).withFormat(new Csv())//定义数据格式化方式,
.withSchema(new Schema()//定义表的结构
.field("id",DataTypes.STRING())
.field("timestamp",DataTypes.BIGINT())
.field("temperature",DataTypes.DOUBLE())
).createTemporaryTable("kafka_input_table")//创建临时表
//1 转换操作
val inputTable = tableEnv.from("kafka_input_table")
inputTable.printSchema()
//1.2 简单转换
val transTable = inputTable
.select('id,'temperature)
.filter('id === "sensor_1")
//1.3 聚合转换
val aggTable = inputTable
.groupBy('id)
.select('id,'id.count as 'count)
transTable.toAppendStream[(String,Double)].print("transTable")
//下面这样会报错:Table is not an append-only table. Use the toRetractStream() in order to handle add and retract messages.
// aggTable.toAppendStream[(String,Long)].print("aggTable")
aggTable.toRetractStream[(String,Long)].print("aggTable")
// 2 输出到kafak
tableEnv.connect(new Kafka()//定义表的数据来源,和外部系统建立连接
.version("0.11")
.topic("flink_table2kafka")
.property("zookeeper.connect","localhost:2181")
.property("bootstrap.services","localhost:9092")
).withFormat(new Csv())//定义数据格式化方式,
.withSchema(new Schema()//定义表的结构
.field("id",DataTypes.STRING())
.field("timestamp",DataTypes.BIGINT())
.field("temperature",DataTypes.DOUBLE())
).createTemporaryTable("kafka_output_table")//创建临时表
inputTable.insertInto("kafka_output_table")
// 3 上面我们吧简单转换的inputTable写到kafka了,那么aggTable能写到kafka 吗?答案,不能
//因为 KafkaTableSink extends KafkaTableSinkBase
// KafkaTableSinkBase implements AppendStreamTableSink
env.execute("LiucfTableAPIKafkaPipeline")
}
}
9.2 输出到elasticsearch

引入flink-json
org.apache.flink
flink-json
1.10.1
package com.study.liucf.table
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.{DataTypes, Table}
import org.apache.flink.table.api.scala._
import org.apache.flink.table.descriptors.{Csv, Elasticsearch, FileSystem, Json, Schema}
object LiucfTableAPIOutputES {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val tableEnv = StreamTableEnvironment.create(env)
val path = "src/main/resources/sensor.csv"
tableEnv
.connect(new FileSystem().path(path))//定义表的数据来源,和外部系统建立连接
//.withFormat(new OldCsv())//定义数据格式化方式,OldCsv只适用文本文件的csv,
.withFormat(new Csv())//定义数据格式化方式,Csv除了适用文本文件的csv,还能格式化如kafka等非标准的csv格式数据
.withSchema(new Schema() //定义表的结构
.field("id",DataTypes.STRING())
.field("timestamp",DataTypes.BIGINT())
.field("temperature",DataTypes.DOUBLE())
).createTemporaryTable("file_input_table")//创建临时表
//1 转换操作
val inputTable: Table = tableEnv.from("file_input_table")
inputTable.printSchema()
//1.2 简单转换
val transTable = inputTable
.select('id,'temperature)
.filter('id === "sensor_1")
//1.3 聚合转换
val aggTable = inputTable
.groupBy('id)
.select('id,'id.count as 'count)
transTable.toAppendStream[(String,Double)].print("transTable")
//下面这样会报错:Table is not an append-only table. Use the toRetractStream() in order to handle add and retract messages.
// aggTable.toAppendStream[(String,Long)].print("aggTable")
aggTable.toRetractStream[(String,Long)].print("aggTable")
//2 输出到ES
tableEnv.connect(new Elasticsearch()
.version("5")
.host("localhost",9200,"http")
.index("liucf_es_sensor")
.documentType("temperature")
).inUpsertMode()
.withFormat(new Json())
.withSchema(new Schema()
.field("id",DataTypes.STRING())
.field("count",DataTypes.BIGINT())
).createTemporaryTable("es_output_table")
aggTable.insertInto("es_output_table")
env.execute("LiucfTableAPIOutputES")
}
}
9.3 输出到mysql
10 将Table 转换成DataStream


11 查看执行计划

12 动态表
12.1 动态表

12.2 动态表和持续查询

12.3 将流转换成动态表
12.4 持续查询

12.5 将动态表转换成DataStream


13 时间特性
 13.1 定义处理时间(processing time )
13.1 定义处理时间(processing time )
方式一
package com.study.liucf.table
import com.study.liucf.bean.LiucfSensorReding
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.{EnvironmentSettings, Table}
import org.apache.flink.table.api.scala._
import org.apache.flink.types.Row
object LiucfTableAPITimeAndWindow {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
val inputStream: DataStream[String] = env.readTextFile("src\\main\\resources\\sensor.txt")
val inputDataStream: DataStream[LiucfSensorReding] = inputStream.map(r=>{
val arr = r.split(",")
LiucfSensorReding(arr(0),arr(1).toLong,arr(2).toDouble)
})
//定义表环境
val settings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build()
val tableEnv = StreamTableEnvironment.create(env,settings)
//基于流创建一张表
val flinkTable: Table = tableEnv.fromDataStream(inputDataStream,'id,'timestamp,'temperature,'pt.proctime)
flinkTable.printSchema()
flinkTable.toAppendStream[Row].print("flinkTable")
env.execute("LiucfTableAPITimeAndWindow")
}
}

方式二

方式三

13.2 定义时间时间(event time)
 方式一
方式一

方式二

方式三
 14 窗口
14 窗口




package com.study.liucf.table
import com.study.liucf.bean.LiucfSensorReding
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.table.api._
import org.apache.flink.table.api.scala._
import org.apache.flink.types.Row
object LiucfTableAPITimeAndWindow {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val inputStream: DataStream[String] = env.readTextFile("src\\main\\resources\\sensor.txt")
val inputDataStream: DataStream[LiucfSensorReding] = inputStream.map(r => {
val arr = r.split(",")
LiucfSensorReding(arr(0), arr(1).toLong, arr(2).toDouble)
}).assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[LiucfSensorReding](Time.seconds(1)){
override def extractTimestamp(element: LiucfSensorReding): Long = element.timestamp *1000
}
)
//定义表环境
val settings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build()
val tableEnv = StreamTableEnvironment.create(env, settings)
//基于流创建一张表
// val flinkTable: Table = tableEnv.fromDataStream(inputDataStream,'id,'timestamp,'temperature,'pt.proctime)
val flinkTable: Table = tableEnv
.fromDataStream(inputDataStream, 'id, 'timestamp, 'temperature, 'timestamp.rowtime as 'tr)
// flinkTable.printSchema()
// flinkTable.toAppendStream[Row].print("flinkTable")
// Group Window
// 1 Table API 方式
flinkTable.window(Tumble over 10.seconds on 'tr as 'tw)//每十秒统计一次,滚动时间窗口
.groupBy('id,'tw)
.select('id,'id.count,'temperature.avg,'tw.end)
// sql 方式
tableEnv.createTemporaryView("flinkTable",flinkTable)
val resultSqlTable: Table = tableEnv.sqlQuery(
"""
|select
|id,
|count(id),
|avg(temperature),
|tumble_end(tr,interval '10' second)
|from flinkTable
|group by
|id,
|tumble(tr,interval '10' second)
|""".stripMargin)
resultSqlTable.toAppendStream[Row].print("Append")
resultSqlTable.toRetractStream[Row].print("Retract")
env.execute("LiucfTableAPITimeAndWindow")
}
}

package com.study.liucf.table
import com.study.liucf.bean.LiucfSensorReding
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.table.api._
import org.apache.flink.table.api.scala._
import org.apache.flink.types.Row
object LiucfTableAPITimeAndWindow {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val inputStream: DataStream[String] = env.readTextFile("src\\main\\resources\\sensor.txt")
val inputDataStream: DataStream[LiucfSensorReding] = inputStream.map(r => {
val arr = r.split(",")
LiucfSensorReding(arr(0), arr(1).toLong, arr(2).toDouble)
}).assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[LiucfSensorReding](Time.seconds(1)){
override def extractTimestamp(element: LiucfSensorReding): Long = element.timestamp *1000
}
)
//定义表环境
val settings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build()
val tableEnv = StreamTableEnvironment.create(env, settings)
//基于流创建一张表
// val flinkTable: Table = tableEnv.fromDataStream(inputDataStream,'id,'timestamp,'temperature,'pt.proctime)
val flinkTable: Table = tableEnv
.fromDataStream(inputDataStream, 'id, 'timestamp, 'temperature, 'timestamp.rowtime as 'tr)
// flinkTable.printSchema()
// flinkTable.toAppendStream[Row].print("flinkTable")
// 1 Group Window
// 1.1 Table API 方式
flinkTable.window(Tumble over 10.seconds on 'tr as 'tw)//每十秒统计一次,滚动时间窗口
.groupBy('id,'tw)
.select('id,'id.count,'temperature.avg,'tw.end)
// 1.2 sql 方式
tableEnv.createTemporaryView("flinkTable",flinkTable)
val resultSqlTable: Table = tableEnv.sqlQuery(
"""
|select
|id,
|count(id),
|avg(temperature),
|tumble_end(tr,interval '10' second)
|from flinkTable
|group by
|id,
|tumble(tr,interval '10' second)
|""".stripMargin)
// resultSqlTable.toAppendStream[Row].print("Append")
// resultSqlTable.toRetractStream[Row].print("Retract")
// 2 Over Window:求同一个传感器最近三条温度数据的平均值
// 2.1 Table Api 方式
val owTableApi: Table = flinkTable.window(Over partitionBy 'id orderBy 'tr preceding 2.rows as 'ow)
.select('id,'tr ,'id.count over 'ow,'temperature.avg over 'ow)
owTableApi.toAppendStream[Row].print("owTableApi")
//2.2 sql 方式
val owSqlTable = tableEnv.sqlQuery(
"""
|select
|id,
|tr,
|count(id) over ow,
|avg(temperature) over ow
|from flinkTable
|window ow as (
|partition by id
|order by tr
|rows between 2 preceding and current row
|)
|""".stripMargin)
owSqlTable.toRetractStream[Row].print("owSqlTable")
env.execute("LiucfTableAPITimeAndWindow")
}
}