数据不均衡 | 过拟合| 模型评价指标 | 分箱 | 模型融合
数据不均衡
从数据角度
- 扩大数据集
- 数据集重采样
- 人工产生数据样本:SMOTE SMOTE算法的基本思想就是对少数类别样本进行分析和模拟,并将人工模拟的新样本添加到数据集中,进而使原始数据中的类别不再严重失衡。该算法的模拟过程采用了KNN技术,模拟生成新样本的步骤如下:
采样最邻近算法,计算出每个少数类样本的K个近邻;
从K个近邻中随机挑选N个样本进行随机线性插值;
构造新的少数类样本;
将新样本与原数据合成,产生新的训练集;
4. 基于异常检测的方式:把那些小类的样本作为异常点(outliers),因此该问题便转化为异常点检测(anomaly detection)与变化趋势检测问题(change detection)。
从算法角度
1. 尝试不同的分类算法:决策树往往在类别不均衡数据上表现不错。它使用基于类变量的划分规则去创建分类树,因此可以强制地将不同类别的样本分开。目前流行的决策树算法有:C4.5、C5.0、CART和Random Forest等。
2. 对小类错分进行加权惩罚:
- 对分类器的小类样本数据增加权值,降低大类样本的权值(这种方法其实是产生了新的数据分布,即产生了新的数据集,译者注),从而使得分类器将重点集中在小类样本身上。一个具体做法就是,在训练分类器时,若分类器将小类样本分错时额外增加分类器一个小类样本分错代价,这个额外的代价可以使得分类器更加“关心”小类样本。如penalized-SVM和penalized-LDA算法。
- 对小样本进行过采样(例如含L倍的重复数据),其实在计算小样本错分cost functions时会累加L倍的惩罚分数。
3. 从重构分类器的角度出发
仔细对你的问题进行分析与挖掘,是否可以将你的问题划分成多个更小的问题,而这些小问题更容易解决。你可以从这篇文章In classification, how do you handle an unbalanced training set?中得到灵感。例如:
- 将你的大类压缩成小类;
- 使用One Class分类器(将小类作为异常点);
- 使用集成方式,训练多个分类器,然后联合这些分类器进行分类;
- 将二分类问题改成多分类问题
过拟合(overfitting)
过拟合一般发生在神经网络中,是指模型把不具有普遍性的特征学到导致在训练集上表现很好但是在测试集上表现很差。
过拟合主要有两个原因造成的,数据太少和模型太复杂
- 数据集扩增(Data Augmentation)
- 改进模型
- Early Stopping: 运行优化方法直到若干次在验证集上的验证误差没有提升时候停止。
- 正则化:正则项通常选择L1(稀疏参数)或者L2(更小参数)正则化
- dropout: 当前Dropout被广泛应用于全连接网络,而在卷积层,因为卷积层本身的稀疏性和ReLU激活函数的使用,Dropout在卷积隐藏层中使用较少。
- 使用集成学习方法:把多个模型集成在一起,降低单个模型的过拟合风险
- 批量正则化(BN):就是将卷积神经网络的每层之间加上将神经元的权重调成标准正态分布的正则化层,这样可以让每一层的训练都从相似的起点出发,而对权重进行拉伸,等价于对特征进行拉伸,在输入层等价于数据增强。注意正则化层是不需要训练。
模型评价指标:
从模型评价指标的角度,重新审视训练好的模型性能。
混淆矩阵、准确率、精确率/查准率、召回率/查全率、F1值、ROC曲线的AUC值 - wuliytTaotao - 博客园
从前面的分析可以看出,准确度这个评价指标在类别不均衡的分类任务中并不能work,甚至进行误导(分类器不work,但是从这个指标来看,该分类器有着很好的评价指标得分)。因此在类别不均衡分类任务中,需要使用更有说服力的评价指标来对分类器进行评价。这里推荐指标:
- 混淆矩阵(Confusion Matrix):使用一个表格对分类器所预测的类别与其真实的类别的样本统计,分别为:TP、FN、FP与TN。


(TP、FP、TN、FN,第二个字母表示样本被预测的类别,第一个字母表示样本的预测类别与真实类别是否一致。)
- 精确度(Precision) (查准率) 和 召回率(Recall) (查全率)
positive class的精确率(precision)计算公式如下:

positive class的召回率(recall)计算公式如下:

positive class的精确率表示在预测为positive的样本中真实类别为positive的样本所占比例; positive class的召回率表示在真实为positive的样本中模型成功预测出的样本所占比例。
positive class的召回率只和真实为positive的样本相关,与真实为negative的样本无关;而精确率则受到两类样本的影响。
- F1得分(F1 Score):精确度与召回率的加权平均。F1值认为精确率和召回率一样重要。
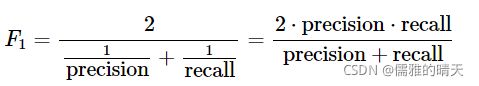

- ROC曲线及其AUC值
AUC全称为Area Under Curve,表示一条曲线下面的面积,ROC曲线的AUC值可以用来对模型进行评价。
从AUC判断分类器(预测模型)优劣的标准:
AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
一句话来说,AUC值越大的分类器,正确率越高。ROC值:
ROC值一般在0.5-1.0之间。值越大表示模型判断准确性越高,即越接近1越好。ROC=0.5表示模型的预测能力与随机结果没有差别。
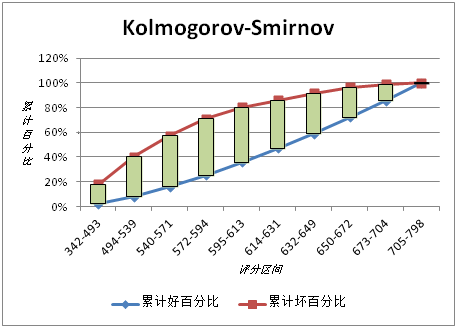
KS值表示了模型将+和-区分开来的能力。值越大,模型的预测准确性越好。一般,KS>0.2即可认为模型有比较好的预测准确性。


- KS指标: 用以评估模型对好、坏客户的判别区分能力,计算累计坏客户与累计好客户百分比的最大差距。KS值范围在0%-100%。好坏样本累计差异越大,KS指标越大,那么模型的风险区分能力越强。在风控中,KS常用于评估模型区分度。区分度越大,说明模型的风险排序能力(ranking ability)越强
判别标准如下:
KS: <20% : 差
KS: 20%-40% : 一般
KS: 41%-50% : 好
KS: 51%-75% : 非常好
KS: >75% : 过高,需要谨慎的验证模型KS的计算步骤如下:
1. 计算每个评分区间的好坏账户数。
2. 计算每个评分区间的累计好账户数占总好账户数比率(good%)和累计坏账户数占总坏账户数比率(bad%)。
3. 计算每个评分区间累计坏账户占比与累计好账户占比差的绝对值(累计good%-累计bad%),然后对这些绝对值取最大值即得此评分卡的K-S值。
WOE分箱和VI值
使用WOE对数据进行分箱:
将连续变量离散化,模型会更稳定,降低了模型过拟合的风险;同时,由于逻辑回归模型的每个变量在每种情况都会有对应的特征权值,使用分箱之后可以降低数据量,使模型泛化能力增强。
IV (Information Value)信息价值或信息量,用来衡量自变量的预测能力。单个特征的IV值就是其中各部分(各箱)iv值之和。
数据分桶:
-
特征分箱的目的:
- 从模型效果上来看,特征分箱主要是为了降低变量的复杂性,减少变量噪音对模型的影响,提高自变量和因变量的相关度。从而使模型更加稳定。
-
数据分桶的对象:
- 将连续变量离散化
- 将多状态的离散变量合并成少状态
-
分箱的原因:
- 数据的特征内的值跨度可能比较大,对有监督和无监督中如k-均值聚类它使用欧氏距离作为相似度函数来测量数据点之间的相似度。都会造成大吃小的影响,其中一种解决方法是对计数值进行区间量化即数据分桶也叫做数据分箱,然后使用量化后的结果。
-
分箱的优点:
- 处理缺失值:当数据源可能存在缺失值,此时可以把null单独作为一个分箱。
- 处理异常值:当数据中存在离群点时,可以把其通过分箱离散化处理,从而提高变量的鲁棒性(抗干扰能力)。例如,age若出现200这种异常值,可分入“age > 60”这个分箱里,排除影响。
- 业务解释性:我们习惯于线性判断变量的作用,当x越来越大,y就越来越大。但实际x与y之间经常存在着非线性关系,此时可经过WOE变换。
-
特别要注意一下分箱的基本原则:
- (1)最小分箱占比不低于5%
- (2)箱内不能全部是好客户
- (3)连续箱单调
交叉验证:
交叉验证是在机器学习建立模型和验证模型参数时常用的办法。交叉验证,顾名思义,就是重复的使用数据,把得到的样本数据进行切分,组合为不同的训练集和测试集,用训练集来训练模型,用测试集来评估模型预测的好坏。在此基础上可以得到多组不同的训练集和测试集,某次训练集中的某样本在下次可能成为测试集中的样本,即所谓“交叉”。
什么时候才需要交叉验证呢?交叉验证用在数据不是很充足的时候。比如在我日常项目里面,对于普通适中问题,如果数据样本量小于一万条,我们就会采用交叉验证来训练优化选择模型。如果样本大于一万条的话,我们一般随机的把数据分成三份,一份为训练集(Training Set),一份为验证集(Validation Set),最后一份为测试集(Test Set)。用训练集来训练模型,用验证集来评估模型预测的好坏和选择模型及其对应的参数。把最终得到的模型再用于测试集,最终决定使用哪个模型以及对应参数。
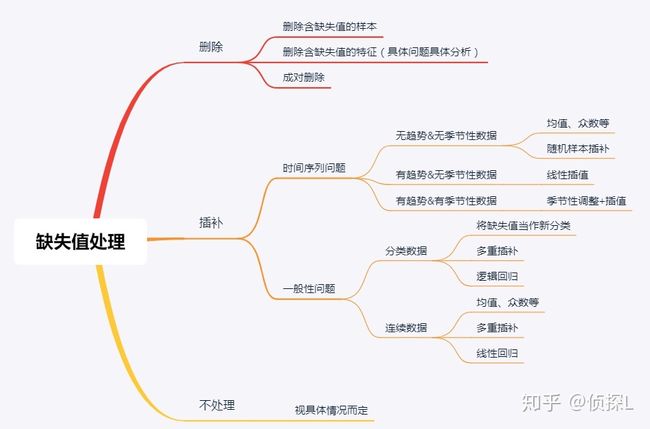
缺失值处理:
数据分析——缺失值处理详解(理论篇) - 知乎
缺失值填充:
-
把所有缺失值替换为指定的值0
-
向用缺失值上面的值替换缺失值
-
纵向用缺失值下面的值替换缺失值,且设置最多只填充两个连续的缺失值
-
按照平均数填充数值型特征
-
按照众数填充类别型特征
异常值处理
- 当你发现异常值后,一定要先分清是什么原因导致的异常值,然后再考虑如何处理。首先,如果这一异常值并不代表一种规律性的,而是极其偶然的现象,或者说你并不想研究这种偶然的现象,这时可以将其删除。其次,如果异常值存在且代表了一种真实存在的现象,那就不能随便删除。在现有的欺诈场景中很多时候欺诈数据本身相对于正常数据勒说就是异常的,我们要把这些异常点纳入,重新拟合模型,研究其规律。能用监督的用监督模型,不能用的还可以考虑用异常检测的算法来做。
- 注意test的数据不能删。
检测异常的方法一:均方差: 在统计学中,如果一个数据分布近似正态,那么大约 68% 的数据值会在均值的一个标准差范围内,大约 95% 会在两个标准差范围内,大约 99.7% 会在三个标准差范围内。
得到特征的异常值后可以进一步分析变量异常值和目标变量的关系
检测异常的方法二:箱型图 四分位数会将数据分为三个点和四个区间,IQR = Q3 -Q1,下触须=Q1 − 1.5x IQR,上触须=Q3 + 1.5x IQR;

模型融合
零基础数据挖掘入门系列(六) - 模型的融合技术大总结与结果部署_Miracle8070-CSDN博客
数据挖掘终篇!一文学习模型融合!从加权融合到stacking, boosting - 云+社区 - 腾讯云
模型融合:通过融合多个不同的模型,可能提升机器学习的性能。
1. 简单加权融合:
- 回归(分类概率):算术平均融合(Arithmetic mean),几何平均融合(Geometric mean);
- 分类:投票(Voting);
- 综合:排序融合(Rank averaging),log融合。
2. stacking/blending:
- stacking:构建多层模型,并利用预测结果再拟合预测。
- blending:选取部分数据预测训练得到预测结果作为新特征,带入剩下的数据中预测。
3. boosting/bagging:
- 多树的提升方法,在xgboost,Adaboost,GBDT中已经用到。
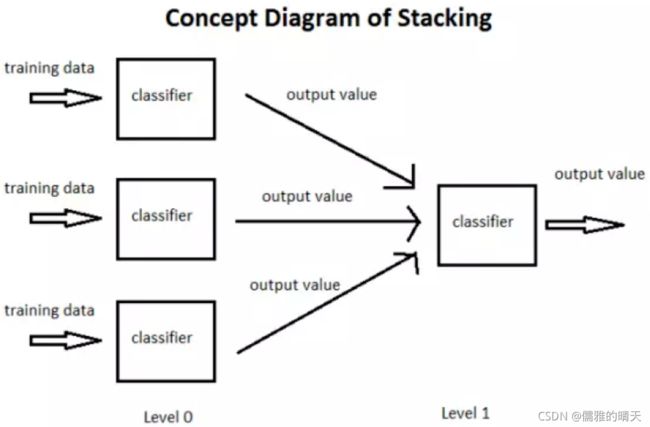
stacking 就是当用初始训练数据学习出若干个基学习器后,将这几个学习器的预测结果作为新的训练集,来学习一个新的学习器。对不同模型预测的结果再进行建模。
在stacking方法中,我们把个体学习器叫做初级学习器,用于结合的学习器叫做次级学习器或元学习器(metalearner),次级学习器用于训练的数据叫做次级训练集。次级训练集是在训练集上用初级学习器得到的。