44.ES
目录
一、ES。
(1)es概念。
(1.1)什么是es。
(1.2)es的发展。
(1.3)总结。
(2)倒排索引。
(3)es与mysql的概念对比。
(4)部署es、kibana、IK分词器。
(4.1)部署单点es。
(4.1.1)创建网络。
(4.1.2)加载镜像。
(4.1.3)运行es容器。
(4.2)部署bibana。
(4.2.1)运行docker命令,部署kibana。
(4.2.2)DevTools。
(4.3)安装IK分词器。
(4.3.1)在线安装ik插件(较慢)。
(4.3.2)离线安装ik插件(推荐)。
(4.3.2.1)查看数据卷目录。
(4.3.2.2)解压缩分词器安装包。
(4.3.2.3)上传到es容器的插件数据卷中。
(4.3.2.4)重启容器。
(4.3.2.5)测试。
(4.3.3.6)扩展词词典。
(4.3.3.7)停用词词典。
(5)索引库操作(即表操作)。
(5.1)mapping映射属性。
(5.2)索引库的CRUD。
(5.2.1)创建索引库。
(5.2.2)查看、删除索引库。
(5.2.3)修改索引库。
(5.2.4)索引库操作有哪些?
(6)文档操作。
(6.1)新增文档。
(6.2)查询、删除文档。
(6.3)修改文档。
(6.4)文档操作总结。
(7)RestClient操作索引库。
(7.1)初始化JavaRestClient、创建索引库。
(7.2)删除索引库、判断索引库是否存在。
(7.3)总结。
(8)RestClient操作文档。
(8.1)新增文档。
(8.2)查询文档。
(8.3)修改文档。
(8.4)删除文档。
(8.5)批量导入文档。
(8.6)总结。
(9)DSL查询文档。
(9.1)DSL查询分类。
(9.2)查询所有。
(9.3)全文检索查询。
(9.4)精准查询。
(9.5)地理坐标查询。
(9.6)组合查询。
(9.6.1)Function Score Query。
(9.6.2)Boolean Query。
(10)搜索结果处理。
(10.1)排序。
(10.2)分页。
(10.3)高亮。
(11)RestClient查询文档。
(11.1)快速入门(包含获取文档内容处理)。
(11.2)match查询。
(11.3)精确查询。
(11.4)复合查询。
(11.5)排序、分页。
(11.6)高亮。
(11.7)根据经纬度排序。
(11.8)代码展示。
(12)数据聚合。
(12.1)聚合的种类。
(12.2)DSL实现聚合。
(12.2.1) Bucket聚合。
(12.2.2)Metrics 聚合。
(12.3)RestAPI实现聚合。
(12.3.1)数据聚合—按字段分组聚合。
(12.3.2)数据聚合—多条件聚合。
(12.3.3)数据聚合—带过滤条件的聚合。
(13)自动补全。
(13.1)拼音分词器。
(13.2)自定义分词器。
(13.3)自动补全查询。
(13.4)实现酒店搜索框自动补全。
(14)数据同步。
(14.1)数据同步思路分析。
(14.2)实现elasticsearch与数据库数据同步。
(15)elasticsearch集群。
(15.1)搭建ES集群。
(15.1.1)es的集群。
(15.1.2)cerebro(集群状态监控)。
(15.1.3)创建索引库。(分片)
(15.2)ES集群的节点角色 。
(15.3)集群脑裂问题。
(15.4)集群分布式存储。
(15.5)集群分布式查询。
(15.6)集群故障转移。
(16)ES的动态映射,静态映射。
(16.1)动态映射。
(16.2)静态映射。
一、ES。
注意:下面的两种id是完全不一样的id,一个是只用于es搜索的唯一标识(_id),一个是对应数据库的字段(_source里面的id字段)。
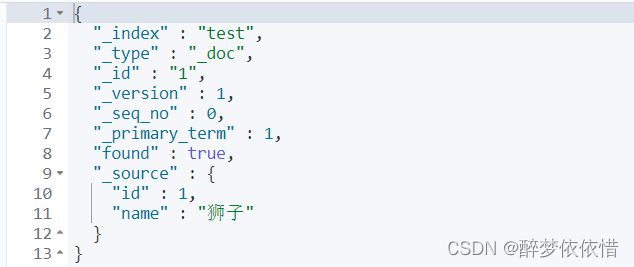
在 Elasticsearch 中,一个文档(Document)有两个 ID 相关的概念:_id 和 _source。
1._id 是文档的唯一标识符,由 Elasticsearch 自动分配或者用户显式指定。该字段在创建文档时生成,用于唯一标识每个文档。例如,在索引文档时可以指定 _id 值:
json
POST /my_index/_doc/1
{
"title": "Example",
"content": "This is an example document."
}
2._source 是文档的实际内容。它是一个存储了文档原始 JSON 内容的字段。默认情况下,当你检索文档时,会返回该文档的完整内容(即 _source 字段)。例如,以下请求会返回具有指定 ID 的文档的全部内容:
json
GET /my_index/_doc/1
返回结果如下所示:
json
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"title": "Example",
"content": "This is an example document."
}
}(1)es概念。
(1.1)什么是es。

(1.2)es的发展。
es是基于lucene写的。

(1.3)总结。
es是基于lucene写的。

(2)倒排索引。
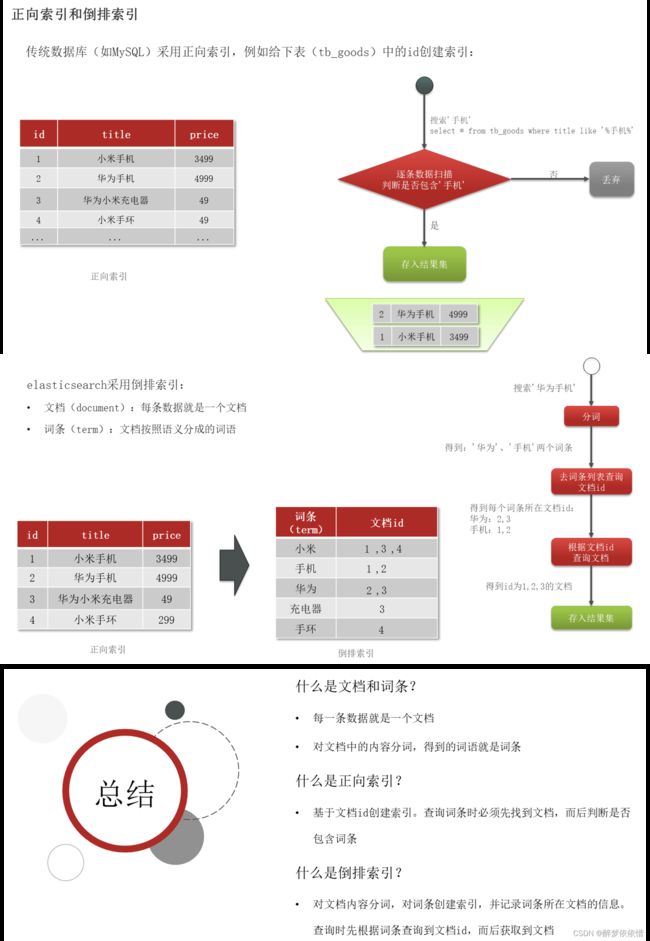
(3)es与mysql的概念对比。
索引:对应数据表。
文档:对应数据表记录。
词条:一条数据表记录有若干词条。
(4)部署es、kibana、IK分词器。
(4.1)部署单点es。
(4.1.1)创建网络。
因为我们还需要部署kibana容器,因此需要让es和kibana容器互联。这里先创建一个网络:
docker network create es-net
(4.1.2)加载镜像。
这里我们采用elasticsearch的7.12.1版本的镜像,这个镜像体积非常大,接近1G。不建议大家自己pull。
大家将其上传到虚拟机中,然后运行命令加载即可:
docker load -i es.tar
同理还有kibana的tar包也需要这样做。
(4.1.3)运行es容器。
运行docker命令,部署单点es:
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
数据卷挂载提示:docker run -v <宿主机路径>:<容器路径> <镜像名称>
命令解释:
--e "cluster.name=es-docker-cluster":设置集群名称
-e "http.host=0.0.0.0":监听的地址,可以外网访问
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小
-e "discovery.type=single-node":非集群模式
-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录
-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录
-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录
--privileged:授予逻辑卷访问权
--network es-net :加入一个名为es-net的网络中
-p 9200:9200:端口映射配置
在浏览器中输入:
http://192.168.150.101:9200
即可看到elasticsearch的响应结果。
(4.2)部署bibana。
(4.2.1)运行docker命令,部署kibana。
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
命令解释:
--network es-net :加入一个名为es-net的网络中,与elasticsearch在同一个网络中
-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch
-p 5601:5601:端口映射配置
kibana启动一般比较慢,需要多等待一会,可以通过命令:
docker logs -f kibana
查看运行日志,当查看到下面的日志,说明成功:
此时,在浏览器输入地址访问(注意该IP地址):
http://192.168.150.101:5601
即可看到结果
(4.2.2)DevTools。
点击Dev tools
kibana中提供了一个DevTools界面:
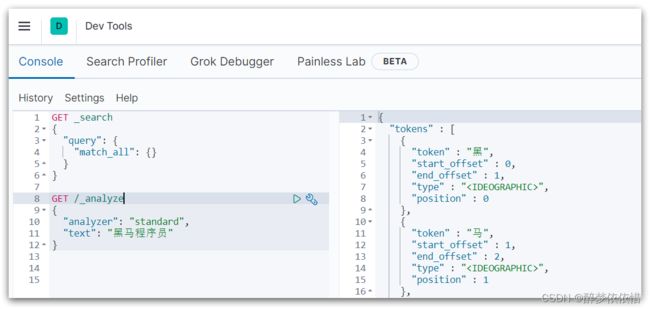
这个界面中可以编写DSL来操作elasticsearch。并且对DSL语句有自动补全功能。
(4.3)安装IK分词器。
(4.3.1)在线安装ik插件(较慢)。
# 进入容器内部
docker exec -it elasticsearch /bin/bash
# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
#退出
exit
#重启容器
docker restart elasticsearch
(4.3.2)离线安装ik插件(推荐)。
(4.3.2.1)查看数据卷目录。
安装插件需要知道elasticsearch的plugins目录位置,而我们用了数据卷挂载,因此需要查看elasticsearch的数据卷目录,通过下面命令查看:
docker volume inspect es-plugins
提示:只要将ik分词器放到挂载到容器的主机挂载目录下就行,当时运行容器的时候挂载了:
-v es-plugins:/usr/share/elasticsearch/plugins
显示结果:
[
{
"CreatedAt": "2022-05-06T10:06:34+08:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data",
"Name": "es-plugins",
"Options": null,
"Scope": "local"
}
]
说明plugins目录被挂载到了:/var/lib/docker/volumes/es-plugins/_data 这个目录中。
(4.3.2.2)解压缩分词器安装包。
下面我们需要把课前资料中的ik分词器解压缩,重命名为ik

(4.3.2.3)上传到es容器的插件数据卷中。
也就是/var/lib/docker/volumes/es-plugins/_data :
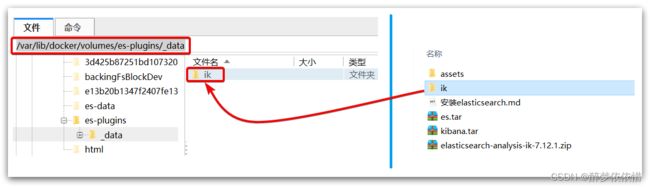
(4.3.2.4)重启容器。
# 4、重启容器
docker restart es
# 查看es日志
docker logs -f es(4.3.2.5)测试。
IK分词器包含两种模式:
-
ik_smart:最少切分 -
ik_max_word:最细切分
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "黑马程序员学习java太棒了"
}
结果:
{
"tokens" : [
{
"token" : "黑马",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "程序员",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "程序",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "员",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "学习",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "java",
"start_offset" : 7,
"end_offset" : 11,
"type" : "ENGLISH",
"position" : 5
},
{
"token" : "太棒了",
"start_offset" : 11,
"end_offset" : 14,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "太棒",
"start_offset" : 11,
"end_offset" : 13,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "了",
"start_offset" : 13,
"end_offset" : 14,
"type" : "CN_CHAR",
"position" : 8
}
]
}(4.3.3.6)扩展词词典。
随着互联网的发展,“造词运动”也越发的频繁。出现了很多新的词语,在原有的词汇列表中并不存在。比如:“奥力给”,“传智播客” 等。
所以我们的词汇也需要不断的更新,IK分词器提供了扩展词汇的功能。
1)打开IK分词器config目录:

2)在IKAnalyzer.cfg.xml配置文件内容添加:
IK Analyzer 扩展配置
ext.dic
3)新建一个 ext.dic,可以参考config目录下复制一个配置文件进行修改
传智播客
奥力给
4)重启elasticsearch
docker restart es
# 查看 日志
docker logs -f elasticsearch
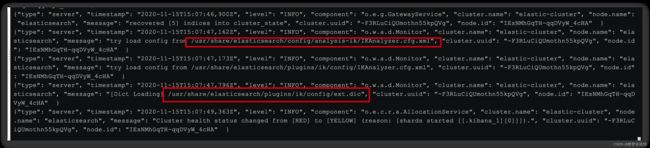
日志中已经成功加载ext.dic配置文件
5)测试效果:
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "传智播客Java就业超过90%,奥力给!"
}
注意当前文件的编码必须是 UTF-8 格式,严禁使用Windows记事本编辑
(4.3.3.7)停用词词典。
在互联网项目中,在网络间传输的速度很快,所以很多语言是不允许在网络上传递的,如:关于宗教、政治等敏感词语,那么我们在搜索时也应该忽略当前词汇。
IK分词器也提供了强大的停用词功能,让我们在索引时就直接忽略当前的停用词汇表中的内容。
1)IKAnalyzer.cfg.xml配置文件内容添加:
IK Analyzer 扩展配置
ext.dic
stopword.dic
3)在 stopword.dic 添加停用词
黑马
4)重启elasticsearch
# 重启服务
docker restart elasticsearch
docker restart kibana
# 查看 日志
docker logs -f elasticsearch
日志中已经成功加载stopword.dic配置文件
5)测试效果:
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "传智播客Java就业率超过95%,奥力给!"
}
注意当前文件的编码必须是 UTF-8 格式,严禁使用Windows记事本编辑
(5)索引库操作(即表操作)。
(5.1)mapping映射属性。

(5.2)索引库的CRUD。
(5.2.1)创建索引库。
分词器只对text类型的数据分词。(不分词代表整个内容就是一个词条,分词就是整个内容可能超过一个词条)。
index约束如果为真,则参与倒排索引,否则不参与倒排索引(即不成为词条)。
PUT /itheima
{
"mappings": {
"properties": {
"info": {
"type": "text",
"analyzer": "ik_smart"
},
"email": {
"type": "keyword",
"index": false
},
"name": {
"type": "object",
"properties": {
"firstName": {
"type": "keyword"
},
"lastName": {
"type": "keyword"
}
}
}
}
}
}
(5.2.2)查看、删除索引库。
(5.2.3)修改索引库。

(5.2.4)索引库操作有哪些?

(6)文档操作。
(6.1)新增文档。
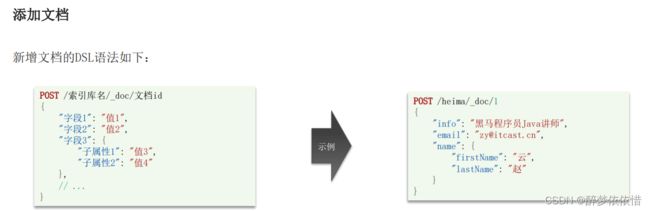
(6.2)查询、删除文档。

(6.3)修改文档。
注意:测试了一下,这也是全量修改。
POST /itheima/_doc/1
{
"info": "1黑马程序员java讲师",
"email": "zy@itcast.cn",
"name": {
"firstName": "云",
"lastName": "赵"
}
}
(6.4)文档操作总结。

(7)RestClient操作索引库。
(7.1)初始化JavaRestClient、创建索引库。

(7.2)删除索引库、判断索引库是否存在。

(7.3)总结。

(8)RestClient操作文档。
(8.1)新增文档。
案例的mapping:
# 酒店的mapping
PUT /hotel
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"name": {
"type": "text",
"analyzer": "ik_max_word"
},
"address": {
"type": "keyword",
"index": false
},
"price": {
"type": "integer"
},
"score": {
"type": "integer"
},
"brand": {
"type": "keyword"
},
"city": {
"type": "keyword"
},
"starName": {
"type": "keyword"
},
"business": {
"type": "keyword"
},
"location": {
"type": "geo_point"
},
"pic": {
"type": "binary",
"index": false
}
}
}
}
(8.2)查询文档。

(8.3)修改文档。

(8.4)删除文档。

(8.5)批量导入文档。

(8.6)总结。

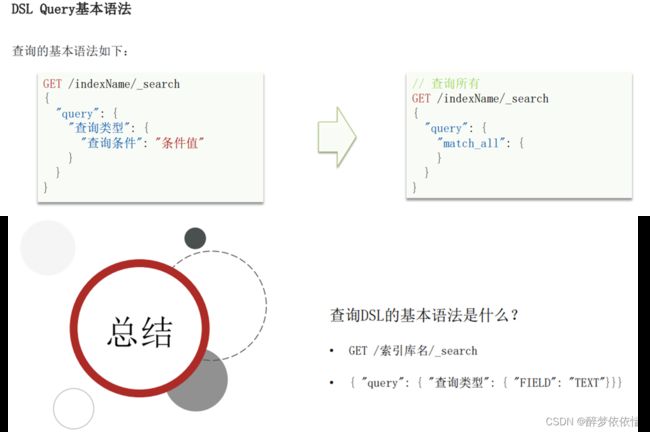
(9)DSL查询文档。
(9.1)DSL查询分类。

(9.2)查询所有。
GET /hotel/_search
{
"query": {
"match_all": {}
}
}
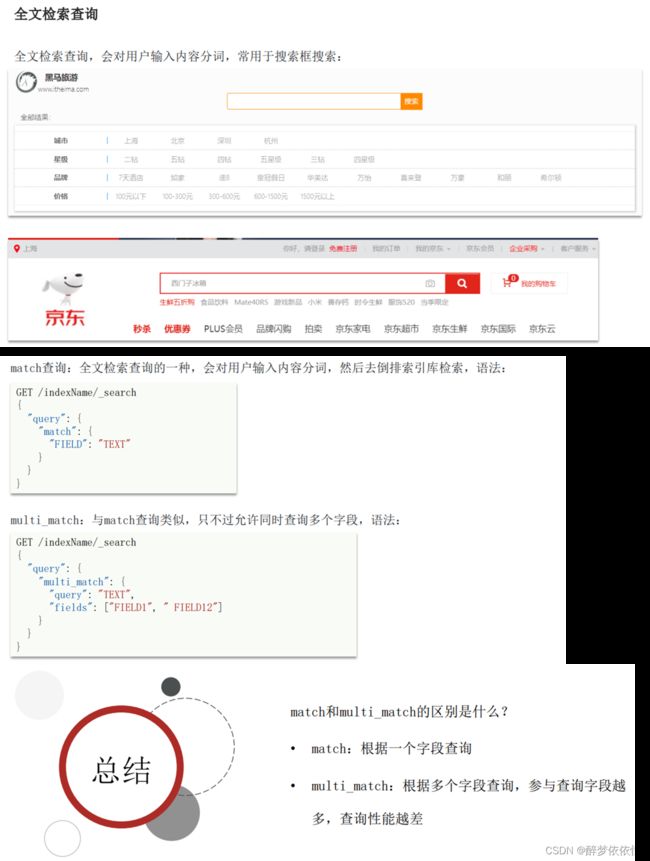
(9.3)全文检索查询。
GET /hotel/_search
{
"query": {
"match": {
"business": "交大/闵行经济开发区"
}
}
}
GET /hotel/_search
{
"query": {
"multi_match": {
"query": "上海滩",
"fields": ["name","city","brand"]
}
}
}
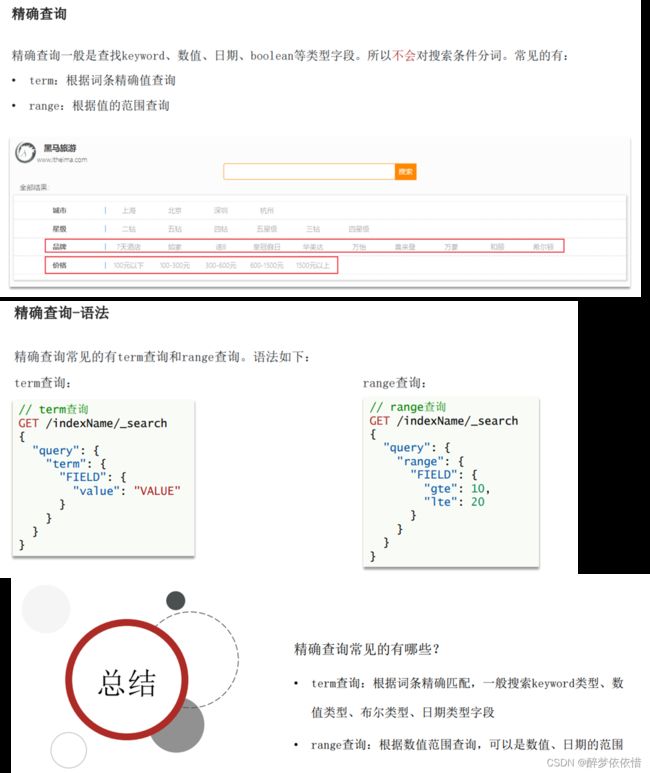
(9.4)精准查询。
# term查询
GET /hotel/_search
{
"query": {
"term": {
"city": {
"value": "上海"
}
}
}
}
# range查询
GET /hotel/_search
{
"query": {
"range": {
"price": {
"gte": 100,
"lte": 2000
}
}
}
}
(9.5)地理坐标查询。
# 地理查询
GET /hotel/_search
{
"query": {
"geo_distance": {
"distance": "150km",
"location": "31.21,122.6"
}
}
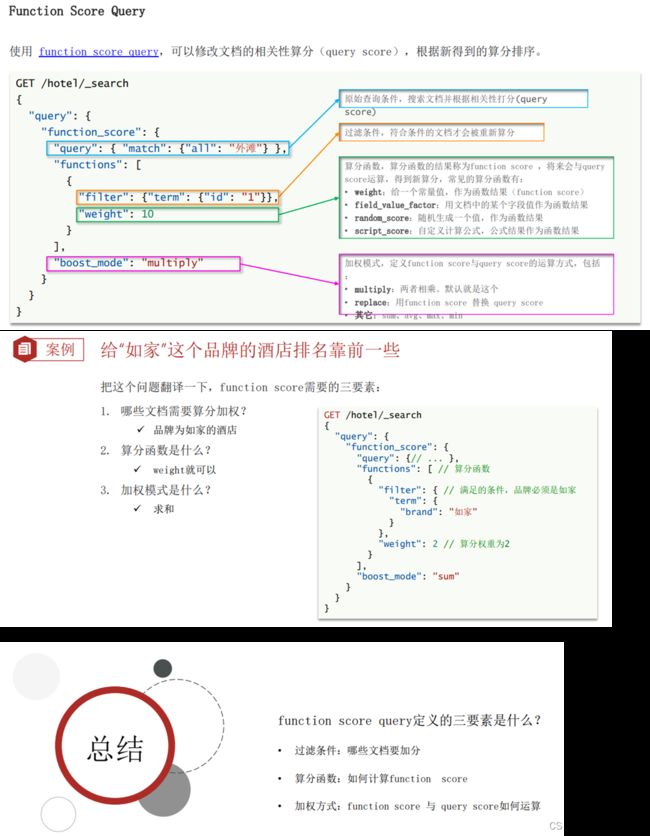
}(9.6)组合查询。

(9.6.1)Function Score Query。
# filter中 虽然指的是过滤,却是过滤出需要的数据(如下面,除了万怡,其他都不要)
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match": {
"name": "紫竹"
}
},
"functions": [
{
"filter": {
"term": {
"brand": "万怡"
}
},
"weight": 100
}
],
"boost_mode": "sum"
}
}
}
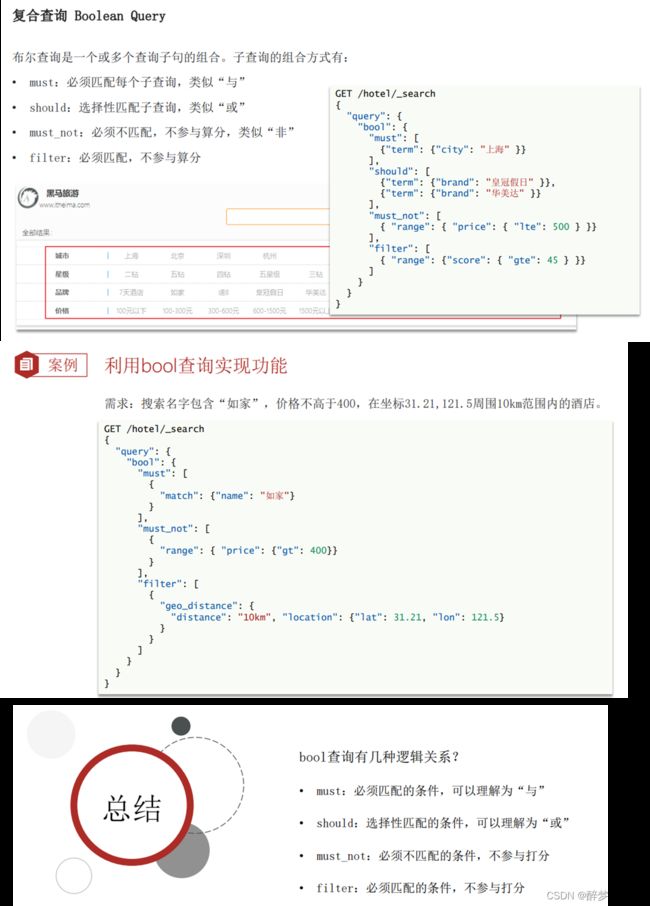
(9.6.2)Boolean Query。
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "万怡"
}
}
],
"must_not": [
{
"range": {
"price": {
"gt": 700
}
}
}
],
"filter": [
{
"geo_distance": {
"distance": "10km"
, "location": {
"lat": 31.02,
"lon": 121.46
}
}
}
]
}
}
}
(10)搜索结果处理。
(10.1)排序。
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"score": "desc"
},
{
"price": "asc"
}
]
}
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance": {
"location": "31.02118, 121.465185",
"order": "asc",
"unit": "km"
}
}
]
}
(10.2)分页。

(10.3)高亮。
注意:高亮的字段必须是query查询语句中出现过的字段(如下面只有name能高亮,其他字段不会高亮,也就是说highlight里面的字段只能写name,写其他字段是没作用的) 。
GET /hotel/_search
{
"query": {
"match": {
"name": "万怡"
}
},
"highlight": {
"fields": {
"name": {
"require_field_match": "false"
}
}
}
}
(11)RestClient查询文档。
要构建查询条件,只要记住一个类:QueryBuilders。
(11.1)快速入门(包含获取文档内容处理)。
@Test
void testMatchAll() throws IOException {
//1.准备request
SearchRequest request = new SearchRequest("hotel");
//2.准备DSL
request.source().query(QueryBuilders.matchAllQuery());
//3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析结果
SearchHits searchHits = response.getHits();
//4.1查询总条数
long total = searchHits.getTotalHits().value;
//4.2查询结果数组
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
//4.3获取source
String json = hit.getSourceAsString();
//4.4反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println(hotelDoc);
}
}
(11.2)match查询。

(11.3)精确查询。

(11.4)复合查询。

(11.5)排序、分页。

(11.6)高亮。
注意:高亮字段在文档里面(索引库包含文档,文档包含高亮字段,每个文档都有记录它的高亮内容),即要从文档里面获取高亮字段内容显示。
GET /hotel/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"brand": {
"value": "万怡"
}
}
},
{
"match": {
"name": "上海"
}
}
]
}
},
"highlight": {
"fields": {
"name": {
"require_field_match": "false"
},
"brand": {
"require_field_match": "false"
}
}
}
} @Test
void testHighLighter() throws IOException {
//1.准备request
SearchRequest request = new SearchRequest("hotel");
//2.准备DSL
//2.1 query
request.source().query(QueryBuilders.matchQuery("name", "万怡"));
//2.2 高亮
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
//3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析结果
SearchHits searchHits = response.getHits();
//4.1查询总条数
long total = searchHits.getTotalHits().value;
//4.2查询结果数组
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
//4.3获取source
String json = hit.getSourceAsString();
//4.4反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
//获取高亮结果
Map highlightFields = hit.getHighlightFields();
if (!CollectionUtils.isEmpty(highlightFields)){
//根据字段名获取高亮结果
HighlightField highlightField = highlightFields.get("name");
if (highlightField != null){
//获取高亮值
String name = highlightField.getFragments()[0].string();
//覆盖非高亮结果
hotelDoc.setName(name);
}
}
System.out.println(hotelDoc);
}
} 
(11.7)根据经纬度排序。
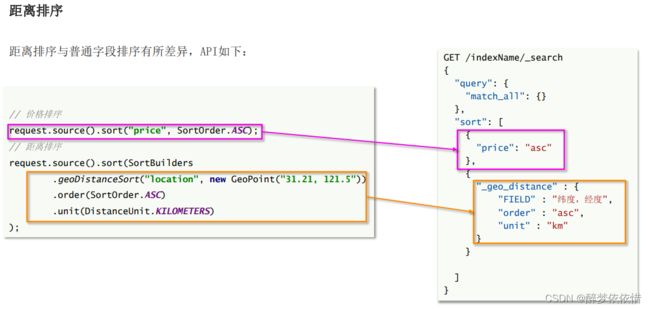
(11.8)代码展示。
@Service
public class HotelService extends ServiceImpl implements IHotelService {
@Autowired
private RestHighLevelClient client;
@Override
public PageResult search(RequestParams params){
try {
//1.准备request
SearchRequest request = new SearchRequest("hotel");
//2.准备DSL
//2.1 query
//构建BooleanQuery
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
//关键字搜索
String key = params.getKey();
if (key == null && "".equals(key)){
boolQuery.must(QueryBuilders.matchAllQuery());
}else {
boolQuery.must(QueryBuilders.matchQuery("name",key));
}
//城市条件
if (params.getCity() != null && !"".equals(params.getCity())){
boolQuery.filter(QueryBuilders.termQuery("city",params.getCity()));
}
//品牌条件
if (params.getBrand() != null && !"".equals(params.getBrand())){
boolQuery.filter(QueryBuilders.termQuery("brand",params.getBrand()));
}
//品牌条件
if (params.getStarName() != null && !"".equals(params.getStarName())){
boolQuery.filter(QueryBuilders.termQuery("starName",params.getStarName()));
}
//价格
if (params.getMinPrice() != null && params.getMaxPrice() != null){
boolQuery.filter(QueryBuilders
.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice()));
}
//算分控制
FunctionScoreQueryBuilder functionScoreQuery = QueryBuilders.functionScoreQuery(
//原始查询
boolQuery,
//function score的数组
new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{
//其中的一个function score元素
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
//过滤条件
QueryBuilders.termQuery("isAD",true),
//算分函数
ScoreFunctionBuilders.weightFactorFunction(10)
)
});
request.source().query(functionScoreQuery);
//2.2 分页
Integer page = params.getPage();
Integer size = params.getSize();
request.source().from((page - 1) * size).size(size);
//2.3排序
String location = params.getLocation();
if (location != null && !"".equals(location)){
request.source().sort(SortBuilders.geoDistanceSort("location",new GeoPoint(location))
.order(SortOrder.ASC).unit(DistanceUnit.KILOMETERS));
}
//3.发送请求,得到响应
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析响应
handleResponse(response);
return null;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private PageResult handleResponse(SearchResponse response) {
//4.解析结果
SearchHits searchHits = response.getHits();
//4.1查询总条数
long total = searchHits.getTotalHits().value;
//4.2查询结果数组
SearchHit[] hits = searchHits.getHits();
//4.3遍历
List hotels = new ArrayList<>();
for (SearchHit hit : hits) {
//获取source
String json = hit.getSourceAsString();
//反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
//获取排序值
Object[] sortValues = hit.getSortValues();
if (sortValues.length > 0){
Object sortValue = sortValues[0];
hotelDoc.setDistance(sortValue);
}
hotels.add(hotelDoc);
}
//4.4封装返回
return new PageResult(total,hotels);
}
}
(12)数据聚合。
(12.1)聚合的种类。

(12.2)DSL实现聚合。
(12.2.1) Bucket聚合。

(12.2.2)Metrics 聚合。

(12.3)RestAPI实现聚合。
(12.3.1)数据聚合—按字段分组聚合。
@Test
void testAggregation() throws IOException {
// 1.准备request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1设置size
request.source().size(0);
// 2.2聚合
request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(20));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析结果
Aggregations aggregations = response.getAggregations();
// 4.1根据聚合名称获取聚合结果
Terms brandTerms = aggregations.get("brandAgg");
// 4.2获取buckets
List buckets = brandTerms.getBuckets();
// 4.3遍历
for (Terms.Bucket bucket : buckets) {
// 4.4获取key
String key = bucket.getKeyAsString();
long docCount = bucket.getDocCount();
System.out.println(key);
}
}
(12.3.2)数据聚合—多条件聚合。
@Override
public Map> filter() {
try {
// 1.准备request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1设置size
request.source().size(0);
// 2.2聚合
buildAggregation(request);
// 3.发送请求
SearchResponse response = null;
response = client.search(request, RequestOptions.DEFAULT);
// 4.解析结果
Map> result = new HashMap<>();
Aggregations aggregations = response.getAggregations();
//根据品牌名称,获取品牌结果
List brandList = getAggByName(aggregations,"brandAgg");
result.put("品牌",brandList);
List cityList = getAggByName(aggregations,"cityAgg");
result.put("城市",cityList);
List starList = getAggByName(aggregations,"starAgg");
result.put("星级",starList);
return result;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private List getAggByName(Aggregations aggregations,String aggName) {
// 4.1根据聚合名称获取聚合结果
Terms brandTerms = aggregations.get(aggName);
// 4.2获取buckets
List buckets = brandTerms.getBuckets();
// 4.3遍历
List brandList = new ArrayList<>();
for (Terms.Bucket bucket : buckets) {
// 4.4获取key
String key = bucket.getKeyAsString();
brandList.add(key);
}
return brandList;
}
private void buildAggregation(SearchRequest request) {
request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(20));
request.source().aggregation(AggregationBuilders.terms("cityAgg").field("city").size(20));
request.source().aggregation(AggregationBuilders.terms("starAgg").field("starName").size(20));
} 
(12.3.3)数据聚合—带过滤条件的聚合。
@Override
public Map> filter(RequestParams params) {
try {
// 1.准备request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
//query
request.source().query(QueryBuilders.matchQuery("city",params.getCity()));
// 2.1设置size
request.source().size(0);
// 2.2聚合
buildAggregation(request);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析结果
Map> result = new HashMap<>();
Aggregations aggregations = response.getAggregations();
//根据品牌名称,获取品牌结果
List brandList = getAggByName(aggregations,"brandAgg");
result.put("品牌",brandList);
List cityList = getAggByName(aggregations,"cityAgg");
result.put("城市",cityList);
List starList = getAggByName(aggregations,"starAgg");
result.put("星级",starList);
return result;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private List getAggByName(Aggregations aggregations,String aggName) {
// 4.1根据聚合名称获取聚合结果
Terms brandTerms = aggregations.get(aggName);
// 4.2获取buckets
List buckets = brandTerms.getBuckets();
// 4.3遍历
List brandList = new ArrayList<>();
for (Terms.Bucket bucket : buckets) {
// 4.4获取key
String key = bucket.getKeyAsString();
brandList.add(key);
}
return brandList;
}
private void buildAggregation(SearchRequest request) {
request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(20));
request.source().aggregation(AggregationBuilders.terms("cityAgg").field("city").size(20));
request.source().aggregation(AggregationBuilders.terms("starAgg").field("starName").size(20));
} 
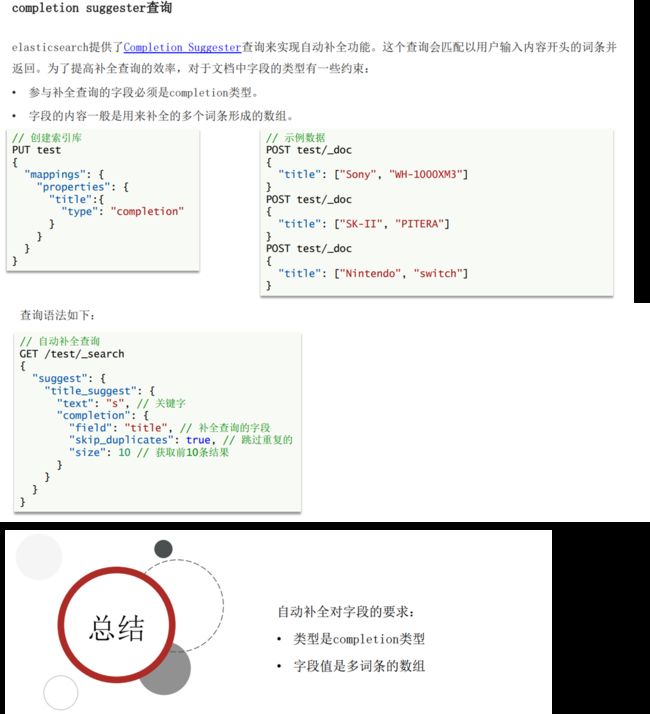
(13)自动补全。

(13.1)拼音分词器。
与ik分词器同级目录。


(13.2)自定义分词器。
DELETE /test
// 自定义拼音分词器
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}
POST /test/_doc/1
{
"id": 1,
"name": "狮子"
}
POST /test/_doc/2
{
"id": 2,
"name": "虱子"
}
POST /test/_doc/222
{
"name": "耗子"
}
POST /test/_doc
{
"id": 3,
"name": "老鼠"
}
GET /test/_search
{
"query": {
"match": {
"name": "掉入狮子笼咋办"
}
}
}
(13.3)自动补全查询。
// 自动补全的索引库
PUT test2
{
"mappings": {
"properties": {
"title":{
"type": "completion"
}
}
}
}
// 示例数据
POST test2/_doc
{
"title": ["Sony", "WH-1000XM3"]
}
POST test2/_doc
{
"title": ["SK-II", "PITERA"]
}
POST test2/_doc
{
"title": ["Nintendo", "switch"]
}
// 自动补全查询
POST /test2/_search
{
"suggest": {
"title_suggest": {
"text": "s", // 关键字,补全前缀为s的title内容变成text字段
"completion": {
"field": "title", // 补全字段
"skip_duplicates": true, // 跳过重复的
"size": 10 // 获取前10条结果
}
}
}
}
(13.4)实现酒店搜索框自动补全。
DELETE /hotel
GET /hotel/_mapping
// 酒店数据索引库
PUT /hotel
{
"settings": {
"analysis": {
"analyzer": {
"text_anlyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
},
"completion_analyzer": {
"tokenizer": "keyword",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart",
"copy_to": "all"//all字段三个属性值必须和上面三个属性值一样,name字段才能复制到all字段
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword",
"copy_to": "all"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart"
},
"suggestion":{//该字段是自动补全的字段
"type": "completion",//该类型是自动补全需要的类型
"analyzer": "completion_analyzer"//对该字段的值使用这个自定义分词器分词
}
}
}
}
GET /hotel/_search
{
"suggest": {
"suggestions": {
"text": "sh",
"completion": {
"field": "suggestion",//注意:FIELD要改成小写,不然报错
"skip_duplicates":true,
"size": 10
}
}
}
}
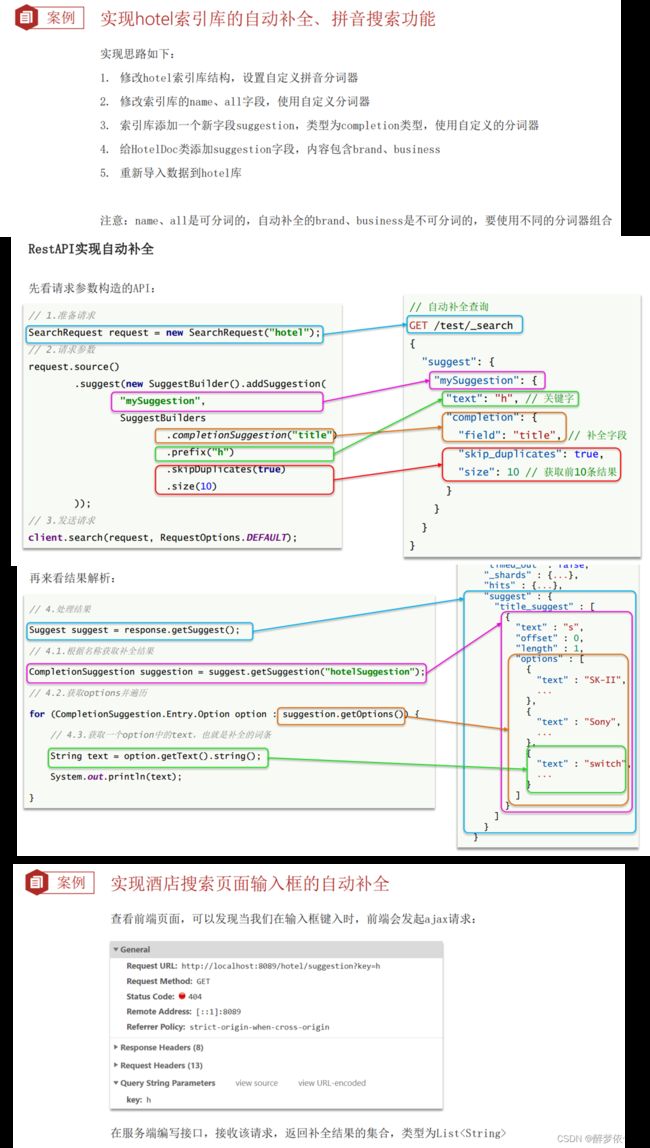
@Test
void testSuggest() throws IOException {
//1.准备Request
SearchRequest request = new SearchRequest("hotel");
//2.准备DSL
request.source().suggest(new SuggestBuilder().addSuggestion(
"suggestions",
SuggestBuilders.completionSuggestion("suggestion")
.prefix("h")
.skipDuplicates(true)
.size(10)));
//3.发起请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析结果
Suggest suggest = response.getSuggest();
//4.1根据补全查询名称,获取补全结果
CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");
//4.2获取options并遍历
for (CompletionSuggestion.Entry.Option option : suggestions.getOptions()) {
String text = option.getText().toString();
System.out.println(text);
}
}(14)数据同步。
(14.1)数据同步思路分析。

(14.2)实现elasticsearch与数据库数据同步。
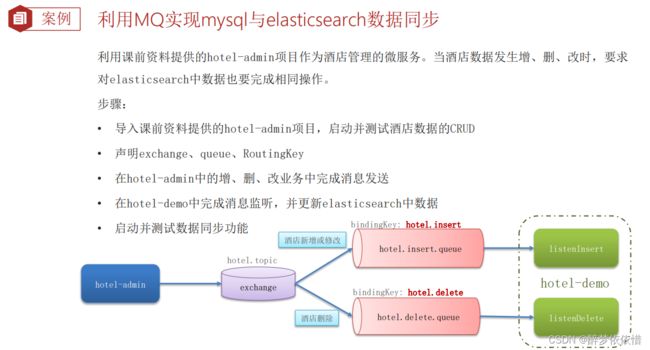
下面是部分代码:
spring:
datasource:
url: jdbc:mysql://localhost:3306/test?useSSL=false
username: root
password: tan
driver-class-name: com.mysql.cj.jdbc.Driver
rabbitmq:
host: 192.168.0.101
port: 5672
username: itcast
password: 123321
virtual-host: / #每个虚拟主机都有自己的队列、交换机、绑定和权限控制等配置。
#假设有一个消息中间件服务器,其中运行着多个应用程序,每个应用程序都需要使用消息队列来进行异步通信。
#如果所有应用程序都共享同一个消息队列空间,那么它们之间的消息可能会相互干扰,导致消息丢失或处理错误。
#而如果为每个应用程序创建一个独立的虚拟主机,那么它们之间的消息就可以得到有效的隔离和保护,避免了潜在的冲突和错误。
@Configuration
public class MqConfig {
@Bean
public TopicExchange topicExchange(){
return new TopicExchange(MqConstants.HOTEL_EXCHANGE,true,false);
}
@Bean
public Queue insertQueue(){
return new Queue(MqConstants.HOTEL_INSERT_QUEUE,true);
}
@Bean
public Queue deleteQueue(){
return new Queue(MqConstants.HOTEL_DELETE_QUEUE,true);
}
@Bean
public Binding insertQueueBinding(){
return BindingBuilder.bind(insertQueue()).to(topicExchange()).with(MqConstants.HOTEL_INSERT_KEY);
}
@Bean
public Binding deleteQueueBinding(){
return BindingBuilder.bind(deleteQueue()).to(topicExchange()).with(MqConstants.HOTEL_DELETE_KEY);
}
}
@PostMapping
public void saveHotel(@RequestBody Hotel hotel){
hotelService.save(hotel);
amqpTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE,MqConstants.HOTEL_INSERT_KEY,hotel.getId());
}
@PutMapping()
public void updateById(@RequestBody Hotel hotel){
if (hotel.getId() == null) {
throw new InvalidParameterException("id不能为空");
}
hotelService.updateById(hotel);
amqpTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE,MqConstants.HOTEL_INSERT_KEY,hotel.getId());
}
@DeleteMapping("/{id}")
public void deleteById(@PathVariable("id") Long id) {
hotelService.removeById(id);
amqpTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE,MqConstants.HOTEL_DELETE_KEY,id);
}@Component
public class HotelListener {
@Autowired
private IHotelService hotelService;
/**
* 监听酒店新增或修改的业务
*/
@RabbitListener(queues = MqConstants.HOTEL_INSERT_QUEUE)
public void listenerHotelInsertOrUpdate(Long id){
hotelService.insertById(id);
}
/**
* 监听酒店删除的业务
*/
@RabbitListener(queues = MqConstants.HOTEL_DELETE_QUEUE)
public void listenerHotelDelete(Long id){
hotelService.deleteById(id);
}
}@Override
public void insertById(Long id) {
try {
//0.根据id查询酒店数据
Hotel hotel = getById(id);
//转换为文档类型
HotelDoc hotelDoc = new HotelDoc(hotel);
//1.准备Request
IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());
//2.准备DSL
request.source(JSON.toJSONString(hotelDoc),XContentType.JSON);
//3.发送请求
client.index(request,RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Override
public void deleteById(Long id) {
try {
//1.准备Request
DeleteRequest request = new DeleteRequest("hotel",id.toString());
//2.准备发送请求
client.delete(request,RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}(15)elasticsearch集群。
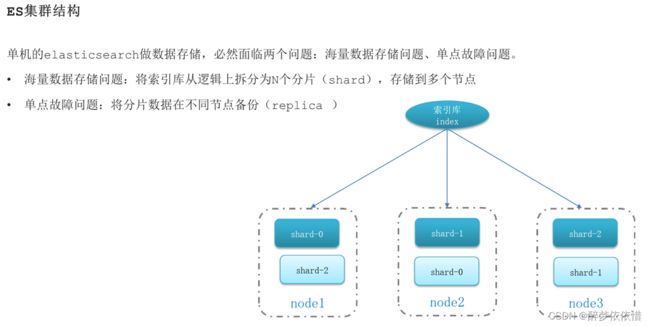
(15.1)搭建ES集群。
(15.1.1)es的集群。
首先编写一个docker-compose.yml文件,内容如下:
version: '2.2' # Docker Compose 版本号
services: # 定义服务
es01: # Elasticsearch 服务1
image: elasticsearch:7.12.1 # 使用 elasticsearch:7.12.1 镜像
container_name: es01 # 容器名称为 es01
environment: # 设置环境变量
- node.name=es01 # 节点名称为 es01
- cluster.name=es-docker-cluster # 集群名称为 es-docker-cluster
- discovery.seed_hosts=es02,es03 # 发现种子主机为 es02 和 es03
- cluster.initial_master_nodes=es01,es02,es03 # 集群初始主节点为 es01、es02 和 es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m" # 设置 JVM 内存
volumes: # 挂载数据卷
- data01:/usr/share/elasticsearch/data # 将 data01 挂载到 /usr/share/elasticsearch/data 目录下
ports: # 端口映射
- 9200:9200 # 将主机的 9200 端口映射到容器的 9200 端口
networks: # 指定使用的网络
- elastic # 使用 elastic 网络
es02: # Elasticsearch 服务2
image: elasticsearch:7.12.1
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03 # 发现种子主机为 es01 和 es03
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data02:/usr/share/elasticsearch/data
ports:
- 9201:9200 # 将主机的 9201 端口映射到容器的 9200 端口
networks:
- elastic
es03: # Elasticsearch 服务3
image: elasticsearch:7.12.1
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02 # 发现种子主机为 es01 和 es02
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data03:/usr/share/elasticsearch/data
ports:
- 9202:9200 # 将主机的 9202 端口映射到容器的 9200 端口
networks:
- elastic
volumes: # 定义数据卷
data01:
driver: local # 使用本地驱动
data02:
driver: local
data03:
driver: local
networks: # 定义网络
elastic:
driver: bridge # 使用 bridge 网络模式
es运行需要修改一些linux系统权限,修改`/etc/sysctl.conf`文件:
vi /etc/sysctl.conf添加下面的内容:
vm.max_map_count=262144是一条Linux系统内核参数的配置命令,用于设置系统中单个进程最大允许的内存区域数量。其作用是控制一个进程可以拥有多少个内存映射区域,以及每个内存映射区域能够映射的最大虚拟内存大小。
vm.max_map_count=262144然后执行命令,让配置生效:
sysctl -p通过docker-compose启动集群:
docker-compose up -d(15.1.2)cerebro(集群状态监控)。
(15.1.3)创建索引库。(分片)

(15.2)ES集群的节点角色 。
默认情况下,每个节点同时具备这四种功能,但实际开发中一般不这样做,因为每种功能需要的硬件不一样。(比如data节点,处理这些数据需要内存大,硬盘大,性能好等等) 。

(15.3)集群脑裂问题。

(15.4)集群分布式存储。
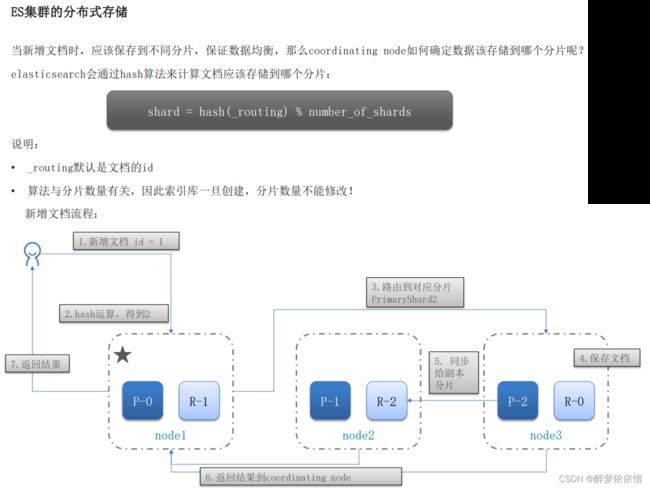

(15.5)集群分布式查询。
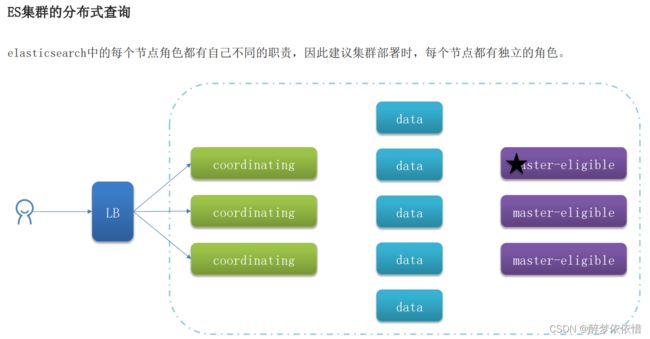
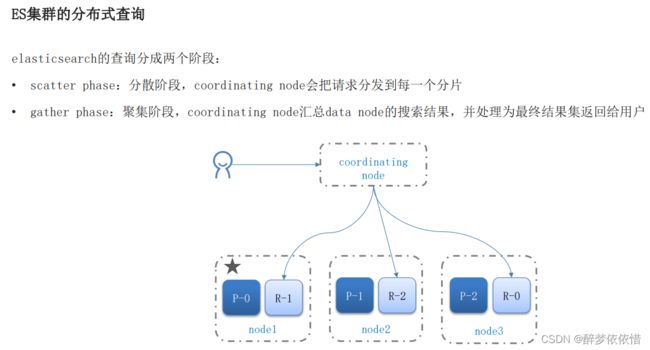

(15.6)集群故障转移。

(16)ES的动态映射,静态映射。
(16.1)动态映射。
底层会自动的根据存入的数据判断数据类型,这种自动分析就叫动态映射。
即添加新字段时(mapping中没有定义的字段),自动帮你加上映射。
dynamic 属性有三种取值:
- true:默认即此。自动添加新字段。
- false:忽略新字段。
- strict:严格模式,发现新字段会抛出异常。
(16.2)静态映射。
创建索引库时指定mapping映射。