第三阶段第二章——Python高阶技巧
时间过得很快,这么快就来到了最后一篇Python基础的学习了。话不多说直接进入这最后的学习环节吧!!!
期待有一天
春风得意马蹄疾,一日看尽长安花
o(* ̄︶ ̄*)o
1.闭包
什么是闭包?
答:
Python闭包是一个函数,同时还保存了定义这个函数的环境(即在其被定义时存在的非局部变量)。换句话说,闭包是一个函数,它可以记住并访问它被定义时的所有变量和状态,即使在其被调用时,这些变量和状态不再存在于其当前环境中。闭包可以被用来隐藏数据,提供保护,并允许在函数中创建更高级别的功能。
(1)简单闭包
来看一个简单的闭包
""" 演示闭包 """ # 简单闭包 def outer(logo): def inner(msg): print(f"<{logo}>{msg}<{logo}>") return inner func1 = outer("麦科集团") func1("上市啦:)") func2 = outer("麦科科技有限公司") func2("被麦科集团全权控股")这样就达到了,既想获取外部的变量,又不想外部的变量被修改掉

(2)如何修改外部函数变量的值
使用 nonlocal 关键字
# 使用nonlocal关键字修改外部函数的值 def outer(num1): def inner(num2): nonlocal num1 num1 += num2 print(num1) return inner func3 = outer(10) func3(141)

(3)ATM级机小案例
这种写法,initial_amount很难被其他人修改
# 使用闭包实现ATM小案例 def account_create(initial_amount=0): def atm(num, deposit=True): nonlocal initial_amount if deposit: initial_amount += num print(f"存款:+{num}, 账户余额:{initial_amount}") else: initial_amount -= num print(f"取款:-{num}, 账户余额:{initial_amount}") return atm atm = account_create() atm(100) atm(200) atm(100, deposit=False)
(4)闭包优缺点
优点:

缺点:
![]()
2.装饰器
(1)什么是装饰器?
答:
Python装饰器是一种能够动态修改函数或类行为的语法结构。它们允许将一个函数或类作为输入,并返回一个修改后的函数或类。通过使用装饰器,可以在不修改原始函数或类定义的情况下添加额外的功能或行为。
装饰器通常以函数的形式定义,可以在需要时应用于任何其他函数或类。它们常用于实现缓存、验证、日志记录和性能监视等功能。在Python中,装饰器是高级编程技术,需要对函数和类的工作原理有深刻的理解。
其实就很类似于AOP编程的思路

(2)装饰器的一般写法(闭包写法)
""" 演示装饰器 """ # 一般写法,闭包 def sleep(): import random import time print("我要睡觉了...") time.sleep(random.randint(1, 5)) def sleep_pro(func): def inner(): print("我睡觉了") func() print("我起床了") return inner # sleep() sleep_pro_max = sleep_pro(sleep) sleep_pro_max()

(3)装饰器的语法(糖写法)
def outer(func): def inner(): print("我要睡觉了...") func() print("我起床了...") return inner @outer def sleep2(): import random import time print("睡眠中..") time.sleep(random.randint(1, 5)) sleep2()

3.设计模式
(1)什么是设计模式
答:
设计模式,是一种被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。一个设计模式并不会像一个类或一个库那样直接成为代码的一部分,而是更像是一种通用的解决方案,可以用来解决各种不同的问题。
例如面向对象也是一种设计模式。
设计模式有很多,这里主要讲解单例模式和工厂模式
(2)单例设计模式
单例设计模式是一种创建型模式,目的是确保在整个应用程序中只有一个唯一的实例对象被创建,并且该实例对象提供了一个全局访问点,供应用程序的其他模块或对象使用。单例模式的实现方式通常包括:
1. 隐藏构造函数:防止外部直接创建对象实例。
2. 静态方法获取对象实例:提供一个静态的、公共的方法用于获取单例对象实例,该方法会检查是否已经创建了单例对象实例,如果没有则创建一个新的实例并返回,否则直接返回已经存在的对象实例。
单例模式通常可以用于需要全局访问和管理资源的场景,比如日志系统、数据库连接池、线程池等。一个经典的单例模式实现方式是使用懒汉式单例(也有饿汉单例),即在第一次调用获取单例对象实例的方法时才创建实例对象。这种实现方式可以延迟对象的创建时间,避免不必要的资源浪费。


# 测试类
from str_tools import str_tool
s1 = str_tool
s2 = str_tool
print(id(s1))
print(id(s2))
# 导入的类
class StrTools:
pass
str_tool = StrTools()
(3)工厂设计模式
工厂设计模式是一种创建型模式,它定义了一个创建对象的接口,但是由子类来决定要实例化哪个类。即通过一个工厂类来创建其它对象,而不是直接使用 new 关键字来创建对象。这样可以将对象的创建与使用进行解耦,从而使代码更加灵活和可扩展。
工厂设计模式的实现包括以下角色:
1. 抽象工厂(Abstract Factory):定义了创建对象的接口,它包含多个工厂方法,用于创建不同类型的对象。
2. 具体工厂(Concrete Factory):实现抽象工厂接口中的工厂方法,用于创建具体的产品对象。
3. 抽象产品(Abstract Product):定义了产品对象的接口。
4. 具体产品(Concrete Product):实现抽象产品接口中定义的方法,完成具体的业务逻辑。
使用工厂设计模式的好处是,当需要增加新的产品时,只需要扩展具体工厂和具体产品的实现,而无需修改现有的代码。同时,工厂设计模式可以为复杂的产品对象创建提供一个相对简单的统一接口,从而降低了代码的复杂度和耦合度。
工厂设计模式应用广泛,比如在Java中,就有许多标准库和框架中都用到了工厂设计模式,比如:JDBC、Servlet、Spring等。
"""
演示工厂模式
"""
class Person:
pass
class Worker(Person):
pass
class Student(Person):
pass
class Teacher(Person):
pass
class PersonFactory:
def get_person(self, p_type):
if p_type == 'w':
return Worker()
elif p_type == 's':
return Student()
else:
return Teacher()
pf = PersonFactory()
worker = pf.get_person('w')
print(type(worker))
stu = pf.get_person('s')
print(type(stu))
tea = pf.get_person('t')
print(type(tea))
4.多线程
(1)进程,线程和并行执行
1.进程和线程
什么是进程和线程?
答:
进程和线程都是操作系统中用于支持多任务的概念。
进程是操作系统中分配资源的基本单位,它有自己独立的地址空间、堆栈以及数据段等,它由操作系统来分配资源,每个进程都有一个独立的进程控制块来管理进程的运行状态。
线程是操作系统中独立调度的基本单位,它是进程中的一个执行单位,与同一进程中的其它线程共享进程的资源,包括地址空间、文件描述符、信号处理等。线程的引入可以使得进程中的多个任务可以并发执行,提高了系统的执行效率。
相比于进程,线程的创建、销毁以及切换开销更小,可以更好地利用CPU资源。但是,由于线程共享进程的资源,线程之间的安全问题也要格外注意。
需要注意的是,进程和线程的概念并不是Python特有的,而是操作系统的基本概念,在不同操作系统上还可能有所区别。在Python中,我们可以通过多线程和多进程模块来实现线程和进程的操作。
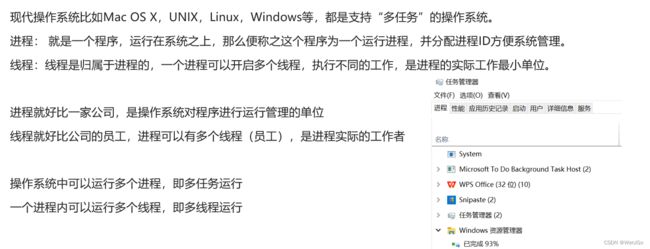
注意点:
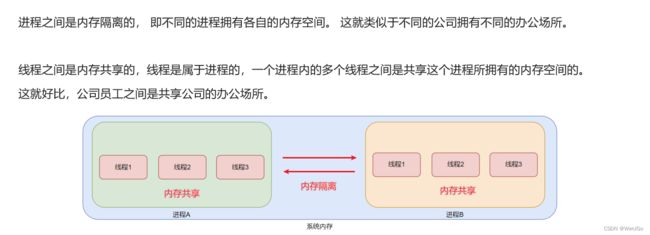
2.什么是并行执行?

(2)多线程编程
1.什么是多线程编程,如何实现
threading模块是Python中用于支持多线程编程的模块,它提供了一些用于创建和管理线程的类和函数。以下是一些常用的threading模块中的类和函数:
- threading.Thread:用于创建线程的类,继承自object类。可以通过继承Thread类并重写run()方法来创建自己的线程类。
- threading.current_thread():用于获取当前线程对象。
- threading.active_count():用于获取当前活动线程的数量。
- threading.enumerate():返回当前活动的线程列表。
- threading.Lock():创建一个锁对象,用于控制多个线程对共享资源的访问。
- threading.RLock():创建一个可重入锁对象,支持单个线程对同一锁的多次调用。
- threading.Condition():创建一个条件变量对象,用于多个线程之间的等待、唤醒操作。
- threading.Event():创建一个事件对象,用于多个线程之间的信号通知和等待操作。
- threading.Timer():创建一个定时器对象,用于在指定时间后执行某个操作。
- threading.ThreadLocal():创建一个线程局部变量对象,用于在不同线程之间共享数据。使用threading模块可以方便地实现多线程编程,提高程序性能和效率。但是,在多线程编程中需要注意线程安全问题,尤其是对共享资源的访问,需要使用锁等机制进行控制,以保证程序的正确性和可靠性。
2.小练习(没有传参)

代码示例:
"""
多线程演示示例
"""
import time
import threading
def sing():
while True:
print("我在唱歌,呀啦嗦~~~~~~")
time.sleep(1)
def dance():
while True:
print("我在跳舞,动次打次动次打次")
time.sleep(1)
if __name__ == '__main__':
# 唱歌线程
sing_thread = threading.Thread(target=sing)
# 跳舞线程
dance_thread = threading.Thread(target=dance)
# 线程工作
sing_thread.start()
dance_thread.start()
3.小练习(有传参)

"""
多线程演示示例
"""
import time
import threading
def sing(msg):
while True:
print(msg)
time.sleep(1)
def dance(msg):
while True:
print(msg)
time.sleep(1)
if __name__ == '__main__':
# 唱歌线程,使用元组传参
sing_thread = threading.Thread(target=sing, args=("我要唱歌 哈哈哈", ))
# 跳舞线程,使用字典传参
dance_thread = threading.Thread(target=dance, kwargs={"msg": "我在跳舞,动次打次"})
# 线程工作
sing_thread.start()
dance_thread.start()
5.网络编程
(1)服务端开发
1.初识socket
Socket(套接字)是一种用于网络通信的底层技术,是网络编程的基础。它是一种抽象的概念,可以用来创建网络连接、进行数据传输和接收。
在编程中,套接字通常被用来实现客户端与服务器之间的通信,通过套接字可以在两个计算机之间建立一条通信管道。在网络编程中,我们常用的套接字有两种,即TCP套接字和UDP套接字。其中,TCP套接字是面向连接的可靠传输协议,它提供了一种可靠的数据传输方式,确保数据的可靠性和完整性;UDP套接字则是一种无连接的不可靠传输协议,它没有连接的概念,也不保证数据的可靠性和完整性。
Python中提供了socket模块,可以用来实现网络编程中的套接字操作。在socket模块中,常用的方法包括socket()、bind()、listen()、accept()、connect()、send()和recv()等,用于创建套接字、绑定IP地址和端口、监听客户端连接请求、接受客户端连接、连接服务器、发送数据和接收数据等。

2.客户端和服务端
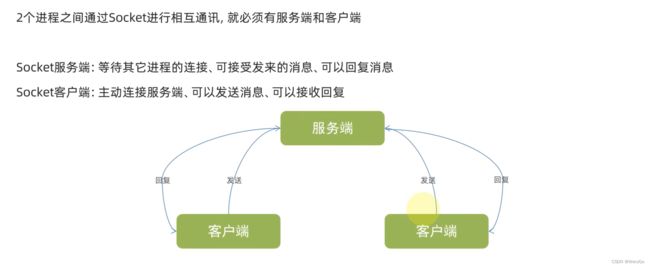
3.服务端开发主要分为一下几个步骤

"""
服务端开发
"""
import socket
# 创建socket对象
socket_server = socket.socket()
# 绑定socket_server到指定IP和地址
socket_server.bind(("127.0.0.1", 8888))
# 服务端开始监听端口,参数为允许链接的数量
socket_server.listen(1)
# 接收客户端连接,获得连接对象
# 返回的是一个二元组,可以使用两个变量接收
# 返回的分别是连接对象和客户端地址信息
# accept()是阻塞的方法,也就是如果没有客户端连接,就会卡在这里等待
conn, address = socket_server.accept()
print(f"接收客户端连接,连接来自:{address}")
while True:
# 发送客户端消息
# recv接收的参数是缓冲区大小,一般赋值1024
# 返回值是一个字节数组bytes,通过decode方法转换为字符串对象
data: str = conn.recv(1024).decode("UTF-8")
print(f"客户端发来消息是:{data}")
# 发送回复消息
# 通过encode,将字符串编码为字节数组
msg = input("请输入回复消息")
if msg == 'exit':
break
conn.send(msg.encode("UTF-8"))
# 关闭链接
conn.close()
socket_server.close()
(2)客户端开发

"""
客户端开发
"""
import socket
# 创建socket对象
socket_client = socket.socket()
# 连接到服务端
socket_client.connect(("127.0.0.1", 8888))
while True:
# 发送消息
msg = input("请输入要被服务端发送的消息")
if msg == "exit":
break
socket_client.send(msg.encode("UTF-8"))
# 接收返回消息
# 同样是阻塞的
recv_data = socket_client.recv(1024)
print(f"服务端回复的消息是:{recv_data.decode('UTF-8')}")
# 关闭链接
socket_client.close()
6.正则表达式
(1)基础匹配
1.什么是正则表达式

2.正则的三个基础方法
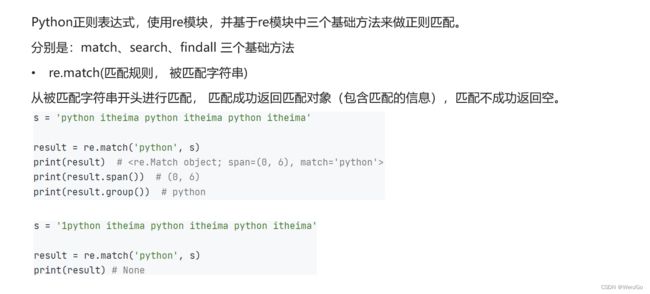
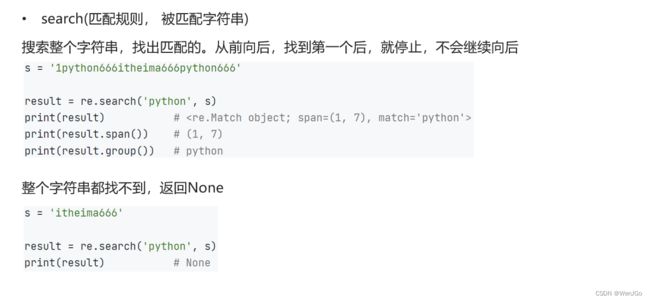
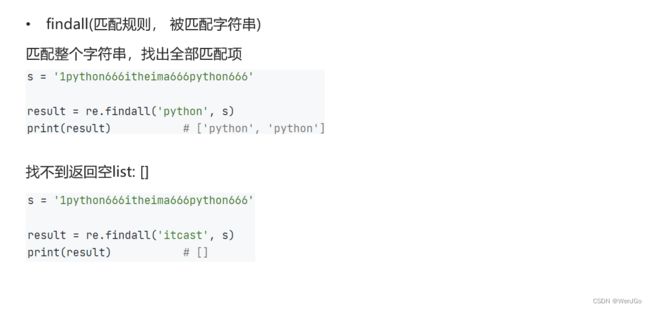
代码示例:
"""
演示正则表达式的三个基础方法
"""
import re
s1 = "mmm wakanda"
# match方法 从头匹配,头部匹配不到会返回none
result1 = re.match("mmm", s1)
print(result1)
print(result1.span())
print(result1.group())
# 分别打印
#
# (0, 3)
# mmm
print('------------')
s2 = "a python haha python"
# search方法 搜索匹配
result2 = re.search("python", s2)
print(result2)
print(result2.span())
print(result2.group())
print("--------")
s3 = "a python haha python la la la python python"
# findall 方法 搜索全部匹配
result3 = re.findall("python", s3)
print(result3)
(2)元字符匹配
1.单字符匹配
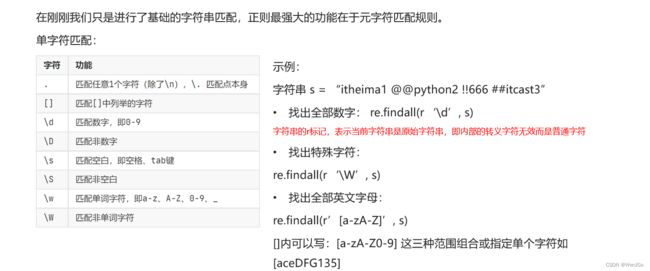
2.数量匹配

3.边界匹配

4.分组匹配
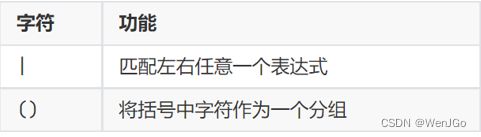
5.案例

代码示例:
"""
案例
"""
import re
# 匹配账号,只能由字母和数字组成,长度限制6到10位
# 在正则表达式里千万不要带空格了
r1 = '^[0-9a-zA-Z]{6,10}$'
s01 = '123456789012345'
s02 = '12345678'
s03 = '12345678_'
print(re.findall(r1, s01))
print(re.findall(r1, s02))
print(re.findall(r1, s03))
print("--------------")
# 匹配QQ号,要求纯数字,长度5-11,第一位不为0
r2 = '^[1-9][0-9]{4,10}$'
s11 = '012345678'
print(re.findall(r2, s11))
# 匹配邮箱地址,只允许qq,163,gmail这三种邮箱格式
# {}.{}@{}.{}.{}
# [email protected]
# [email protected]
r3 = '(^[\w-]+(\.[\w-]+)*@(qq|163|gmail)(\.[\w-]+)+$)'
s31 = '[email protected]'
s32 = '[email protected]'
print(re.match(r3, s31))
print(re.match(r3, s32))
7.递归
什么是递归?
答:递归是指在编程中一个函数调用自己的过程。递归可以用来解决一些分治的问题,如快速排序,归并排序等。
在递归函数中,通常存在一个停止递归的条件,即递归终止条件。当递归到达终止条件时,递归就会停止,并开始回溯执行之前的操作。
递归函数具有一定的优点和缺点。优点是可以简化代码,使代码更加清晰、易懂,适用于一些可分解为重复子问题的场景。缺点是递归过程中会产生多次函数调用和多次栈的开辟和回收,会导致时间和空间上的性能问题,如果递归调用次数太多,可能会导致栈溢出。
在Python中,递归函数需要考虑Python的递归深度限制,如果递归深度太大,可能会导致程序崩溃。可以使用sys模块中的setrecursionlimit()方法来设置递归深度限制。


或者是例如在算法的二叉树那里,遍历二叉树很多操作都可以使用递归完成
例如:实现x的n次幂,使用递归实现
def power(x, n):
if n == 0:
return 1
else:
return x * power(x, n-1)
print(power(2, 3))
结语
好了有关python的全部基础内容就全部结束了,大家在学习完Python基础之后是不是感觉到了无限的快乐呐^_^
离成功又进一步~~~~!!!!!!
\(^o^)/欧耶~!
再见ヾ( ̄▽ ̄)Bye~Bye~