数据分析-numpy
numpy
numpy
- numpy
-
- 简介
- 优点
- 下载
- ndarray的属性
- 输出
- 数据类型
- routines 函数
- ndarray对象的读写操作
- ndarray的级联和切分
-
- 级联
- 切分
- ndarray的基本运算
- 广播机制(Broadcast)
- ndarry的聚合操作
- 数组元素的操作
- numpy 数学函数
- numpy 查找和排序
- 写在最后面

简介
numpy是一个基于python的扩展库
优点
提供了高纬数组对象ndarray,运算的速度碾压python的list,提供了各种高级数据编程工具,如矩阵计算,向量运算快速筛选,IO操作,傅里叶变换,线性代数,随机数等
下载
下载非常的简单在cmd中执行以下命令即可
pip install numpy
ndarray的属性
1.ndim:维度
# 导入模块
import numpy as np
# 生成一个ndarray对象
arr1 = np.array([1,2,3])
arr1.ndim # 1
# 生成一个ndarray对象
arr2 = np.array([[1,2,3],[4,5,6]])
arr2.ndim # 2
2.shape:形状(各维度的长度)
# 导入模块
import numpy as np
# 生成一个ndarray对象
arr1 = np.array([1,2,3])
arr1.shape # (2, 3)
# 生成一个ndarray对象
arr2 = np.array([[1,2,3],[4,5,6]])
arr2.shape # (3,)
3.size:(总长度)
# 生成一个ndarray对象
arr1 = np.array([1,2,3])
arr1.size # 3
arr2 = np.array([[1,2,3],[4,5,6]])
arr2.size # 6
4,dtype:元素类型
# 生成一个ndarray对象
arr1 = np.array([1,2,3])
arr1.dtype # dtype('int32')
arr2 = np.array([[1,2,3],[4,5,6]])
arr2.dtype # dtype('int32')
type(arr)和dtype(arr)的区别:
type是查询arr这个数据对象的类型,而dtype是查询arr数组中的内容的数据类型
输出
1.display(建议使用)
arr1 = np.array([1,2,3])
arr1.ndim
display(arr1)
2.print
arr1 = array([1, 2, 3])
print(arr1)
[1 2 3]
3.output
数据类型
数据类型:numpy设计初衷是用于运算 的所以对数据类型进行 统一优化(统一是为了提高运算速度)
注意:
numpy默认是ndarray的所有元素的类型相同的
如果传进来的列表中的包含不同类型,则统一为同一类型,
优先级:str->float->int
U表示unicode的简写形成
routines 函数
1.np.ones(shape,dtype=none,order=‘c’)
生成一个都是1的高维数组
shape:形状 dtype:形状
np.ones((3,4),dtype=np.float32)

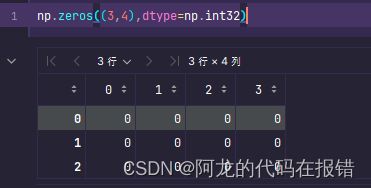
2.np.zeros(shape,dtype=none,order)
生成一个都是0的高维数组
np.zeros((3,4),dtype=np.int32)
3.np.full(shape,full_value,odert=‘c’)
生成一个指定值的高维数组
full_value:指定的值
np.full((3,4),fill_value=5)

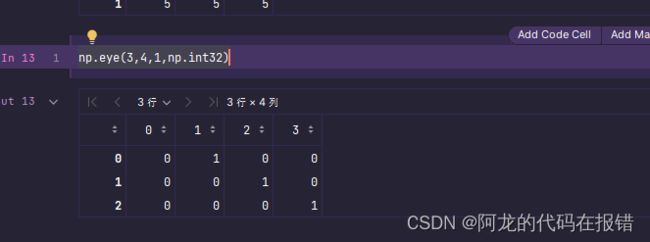
4.np.eye(n,m=None,k=0,dtype=float)
生成一个默认情况下,对角线
第一个参数:输出方阵的规模,即行数
第二个参数:输出的方阵即列数如果默认,默认为第一参数的值
第三个参数:默认情况下输出的是对角线都是1 其余的都是0的方阵如果k为正整数,则在又上方的第k条对角线全是1其余的都是0,k为负整数则在左下方第k条对角线全是1其余的都是0
第四个参数:数据类型,返回数据类型
np.eye(3,4,1,np.int32)
5.np.linespace(start,stop,num=50,endpoint=True,restep=False,dtype=None)
生成一个等差数列
start:开始的数值 stop:停止的值 num:取多少个值 endpoint=是否保留最后一个值 retstep:默认为Flase如果开启则返回的序列结果为一个元组,对应的序列在【start,end】
np.linspace(0,100,num=50,endpoint=True)

6.np.range(start,stop,[step],dtype=None)
生成一个等差数组
import numpy as np
np.arange(start=0,stop=100,step=2)

araneg 和linespace的区别
linespace通过指定需要多个数值组成的数组,arange:通过设置步长确定数值
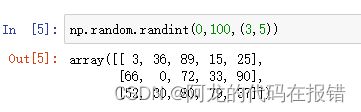
7.np.random.randint(low,hight=None,size=None,dtype=None)
生成 一个随机的整数类型的数组
8.正态分布
np.random,randn()
** 标准的正态分布**

np.random.normal() 普通的正态分析
从正态(高斯)分布中抽取随机样本
参数:
loc:float 或 array_like 的浮点数
分布的均值(“中心”)。
scale:缩放浮点数或浮点数的array_like
分布的标准差(分布或“宽度”)。必须是 非负数。
size: int 或 int 的元组,可选
输出形状。如果给定的形状是,例如,,则绘制样本。如果 size 为(默认值), 如果 和 都是标量,则返回单个值。 否则,将抽取样本。(m, n, k)m * n * kNonelocscalenp.broadcast(loc, scale).size
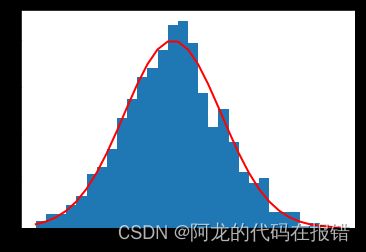
mu, sigma = 0, 0.1 # mean and standard deviation
s = np.random.normal(mu, sigma, 1000)
abs(mu - np.mean(s))
abs(sigma - np.std(s, ddof=1))
import matplotlib.pyplot as plt
count, bins, ignored = plt.hist(s, 30, density=True)
plt.plot(bins, 1/(sigma * np.sqrt(2 * np.pi)) *
np.exp( - (bins - mu)**2 / (2 * sigma**2) ),
linewidth=2, color='r')
plt.show()
9.np.random.random(size)
生成0-1的随机数左闭右开
参数:
size:大小
np.random.random((10,10))

10.np.random.permutaion(10)
生成随机索引可以与列表索引进行数组的随机索引
num:生成随机索引的个数
np.random.permutation(10)

11.np.random.seed(0)
设置种子以后,可以使随机不再发生变化
num:设置种子数
在这一步只设置种子,并不产生随机数
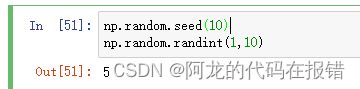
np.random.seed(10)
np.random.randint(1,10)
ndarray对象的读写操作
索引的访问
数组对象可以使用索引的方式进行获取,高维数组访问使用【dim1_index,dim2_index,…】
间接访问:arr[index][index]
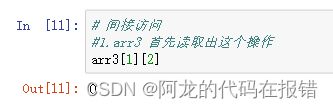
# 间接访问
arr3 = np.random.randint(0,10,size=(2,5))
#1.arr3 首先读取出这个操作
arr3[1][2]
array提供的访问方式:arr[index1,index2]
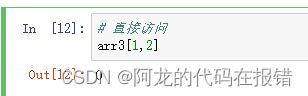
# 直接访问
arr3 = np.random.randint(0,10,size=(2,5))
#1.arr3 首先读取出这个操作
arr3[1][2]
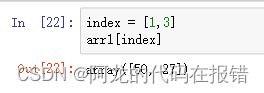
列表访问:先将需要获取的数值的索引位置统一存放在一个列表中,然后再使用索引进行逐个获取。
arr1 = np.random.randint(0,100,size=10)
index = [1,3]
arr1[index]
切片访问:通过切片进行数组的获取
arr2 = np.random.randint(0,100,size=(5,5))
arr2[1:4:5]
arr2[::-1]

通过布尔类型进行获取
arr3 = np.random.randint(0,100,size=(5,))
bool_index = [False,True,False,True,False]
arr3[bool_index]

数组支持访问形式:int 【int】 切片 bool类型
ndarray的级联和切分
级联
级联的注意事项:
1.级联的参数是列表:一定要加中括号或者小括号
2.维度相同
# 维度不同无法级联
r1 = np.random.random(size=(3,))
r2 = np.random.random(size=(3,4))
r3 = np.concatenate((r1,r2))
r3
ValueError: all the input arrays must have same number of dimensions
3.形状相同
# 不同形状无法级联
s1 = np.random.random(size=(3,4))
s2 = np.random.random(size=(3,3))
s3 = np.concatenate((s1,s2))
#ValueError: all the input array dimensions except for the concatenation axis must match exactly
4.级联的方向是默认的是shape这个元组的第一个值所代表的方向
5.可以通过axis参数修改级联的方向
1.np.concatenate((a1,a2),axis=0)
参数:
(a1,a2) :要拼接的数组 axis:拼接的方向
axis=0 的时候数组进行纵连接 axis=1:数组进行横向拼接
a1 = np.random.randint(0,10,size=(3,4))
a2 = np.random.randint(10,20,size=(3,4))
print(a1)
print(a2)
np.concatenate((a1,a2),axis=0)
np.concatenate((a1,a2),axis=1)

2.np.hstack((a1,a2))
横向拼接
参数
(a1,a2): 要拼接的数组
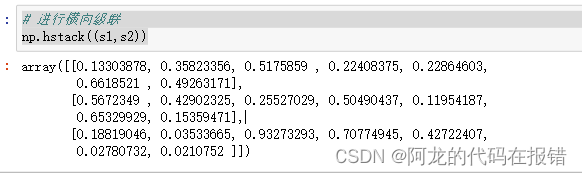
# 进行横向级联
np.hstack((a1,a2))
切分
与级联类似以下三个函数可以完成切分工作:
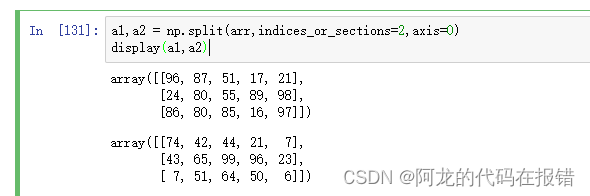
# 创建一个可以拆分的数组
a1,a2 = np.split(arr,indices_or_sections=2,axis=0)
display(a1,a2)
1.np.split(arr,切分规则,轴向)
如果切分规则为数组【m:n】那么数组的分割方式为0:m m:n n:最后
a1,a2 = np.hsplit(arr,2)
display(a1,a2)
2.np.hsplit()
横向切分
arr:要拆分的数组 indices_or_sections:拆分规则
a1,a2 = np.hsplit(arr,2)
display(a1,a2)

3.vsplit()
纵向切分
arr:要拆分的数组 indices_or_sections:拆分规则
a1,a2 = np.vsplit(arr,2)
display(a1,a2)

ndarray的基本运算
基本运算规则:
如果数组的形状相同的时候使用加法:相对应位置的数值进行计算
如果数组与单个数值进行计算:这个数值与数组的每个位置的数值进行计算
广播机制(Broadcast)
ndarray的广播机制的两条规则:
- 两个数组的后缘维度(即从末尾到开始的算起的为度)轴长度相符
- 或者其中一方长度为1
符合上面的两个规则的,则认为他们广播兼容的。广播会在缺失和(或)长度为1 的维度上进行
广播的过程:
将维度少和维度多的数组并且符合上面的规则将会把维度少的数值进行数组的扩展到相同的形状再进行相对位置的运算最后得到结果
ndarray可以和任何整数进行广播

ndarry的聚合操作
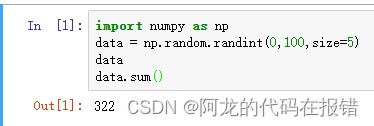
1.求和 arr.sum()
import numpy as np
data = np.random.randint(0,100,size=5)
data
data.sum()
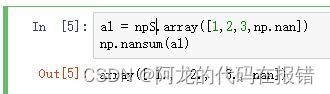
2.arr.nannum()
计算带有空值的数组
a1 = np.array([1,2,3,np.nan])
np.nansum(a1)
3.arr.max()|arr.min()
获取数组中的最大值或最小值
a1 = np.array([1,2,3,11])
# 最大值
np.max(a1)
# 最小值
np.min(a1)

4.any() | all()
np.any():
一个数组中如果数组中至少有一个返回的结果就为True
np.all(np.array([True,True,False,False]))

np.all()
一个数组中。如果数组中全部为True则返回True否则返回的结果就是Flase
5.np.nan
np.nan是一个浮点数,在python中None是None类型
np.nan与任何值相加都会得到np.nan
数组元素的操作
添加元素
numpy.append
在数组末尾添加值。追加会为分配整个数组,并且把原来的数组复制到新的数组
参数
arr:原数组 values:追加的值(可以为数组) axis :要追加的形式(追加到行还是列)
注意:如果是追加数组,需要将追加的数组设置为相同维度的数组进行追加
a1 = np.random.randint(1,100,size=(6,6))
np.append(a1,[[64, 63, 13, 89, 33, 55]],axis=0)
如果没有设置轴,数组将会被展开
a1 = np.random.randint(1,100,size=(6,6))
a2 = np.array([1,2,3,4,5,6])
a3 = np.append(a1,a2)
display(a1,a2,a3)

插入元素
np.insert
函数在给定索引之前,沿着给定的轴在输入数值中插入的值
参数:
arr:被插入的数组 obj:要插入的位置 values:要插入的值
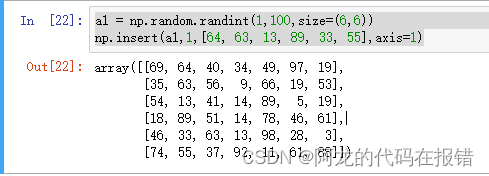
a1 = np.random.randint(1,100,size=(6,6))
np.insert(a1,1,[64, 63, 13, 89, 33, 55],axis=1)
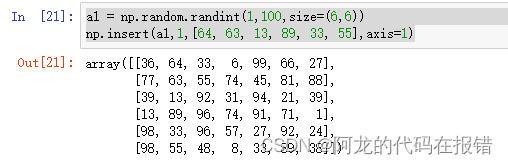
如果没有提供轴,数据将会被展开
a1 = np.random.randint(1,100,size=(6,6))
np.insert(a1,1,10)

删除元素
np.delete
函数返回输入数值中删除指定数组的新数组
a1 = np.random.randint(1,100,size=(6,6))
np.delete(a1,[32, 10, 86, 3, 34, 46],axis=0)

如果没有提供轴,数据将会被展开
a1 = np.random.randint(1,100,size=(6,6))
np.delete(a1,[32, 10, 86, 3, 34, 46])

数组变形(reshape)
np.reshape:函数可以在不改变数据条件下修改形状
参数:
arr:要改变形状的数组 new_shape:想要修改成的形状,整数或者整数数组,新的形状应该兼容之前的形状
order:‘c’ — 按行 ‘F’ — 按列 ‘A’- -----按照原来的顺序 ‘K’-----元素在内存中出现的顺序
a1 = np.random.randint(1,100,size=(6,6))
np.reshape(a1,(4,9))
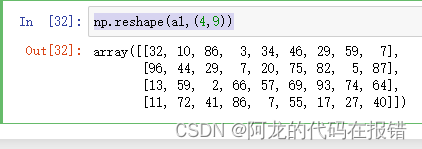
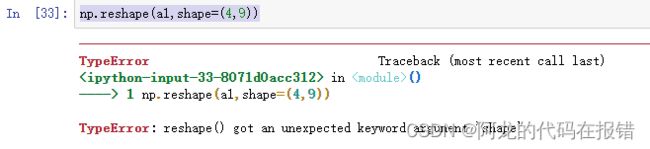
注意:不能显示的使用shape参数,否则会报错
np.reshape(a1,shape=(4,9))
数组的迭代器
ndarray.flat
两段代码的最后实现的效果是一样的
for i in a1.flat for i in a1:
========> for i1 in i:
print(i1)
print(i)
数组的扁平化处理
ndarray.flatten():返回一份展开数组的拷贝,对拷贝的数组进行修改,对原来的数组不会影响到原来的数组
ndarray.ravel():展开数组,返回一个展开的数组引用,修改会影响原始数组。
数组翻转
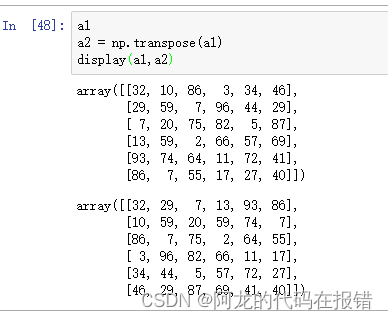
np.transpose:翻转数组的维度
这个函数只有两个参数
a:需要翻转的数组 ,axes=选择的列或行
a1
a2 = np.transpose(a1)
display(a1,a2)
numpy 数学函数
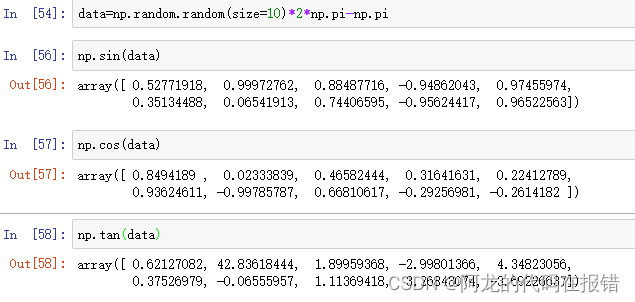
三角函数(这里需要注意:三角函数接受的参数是弧度不是角度):
np.sin() np.cos np.tan()
data=np.random.random(size=10)*2*np.pi-np.pi
np.sin(data)
np.cos(data)
np.tan(data)
舍入函数
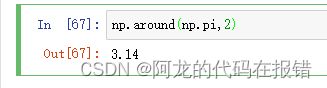
np.around()
参数:
a:数组 decimals:舍入的小数位。默认值为0,如果为负,整数将四舍五入到小数点最左侧的位置
np.around(np.pi,2)
算数函数
加减乘除:add(),subtract(),multipy(),divide()
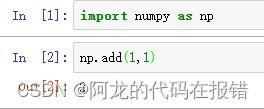
np.add()
import numpy as np
# 1+1
np.add(1,1)
# 7-1
np.subtract(7,1)
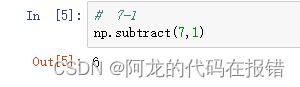
乘
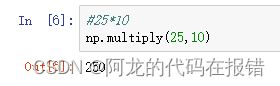
除

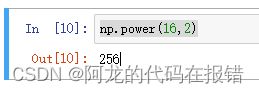
幂运算(可以做开放运算):
np.power(16,2)
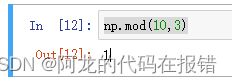
求余运算:
np.mod(10,3)
自然底数的对数:
np.log(),np.log^2 ()
,np.log^10()
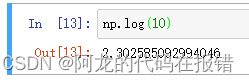
np.log(10)
numpy 查找和排序
查找索引:
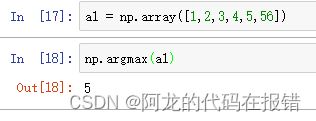
argmax:返回最大的值的索引位置
a1 = np.array([1,2,3,4,5,56])
np.argmax(a1)
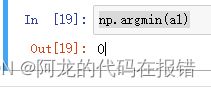
argmin:返回最小的值的索引位置
a1 = np.array([1,2,3,4,5,56])
np.argmin(a1)
条件查询
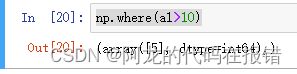
np.where:函数返回输如数组中给定条件的元素索引
参数:
condition:条件表达式
a1 = np.array([1,2,3,4,5,56])
np.where(a1>10)
快速索引
np.start()与ndarray.stort()都可以进行排序但是有区别
np.start()不改变输出方式 ndarray.sort() 本地处理,不占用空间,但是改变输出的方式
data = np.random.randint(1,100,10)
np.sort(data)
data.sort()

索引排序
np.argsort():函数返回的是数组从小到大的索引值
data = np.random.randint(0,10,10)
np.argsort(data)

部分索引
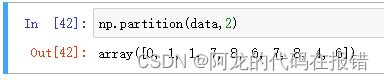
np.partition(a,k):当k为正数的时候得到最小的k个数,当k为负数的时候,得到最大的k个数
他只是给k个数进行排序不是显示k个数
data = np.random.randint(0,10,10)
np.partition(data,2)
写在最后面
个人笔记,如果有错误的地方希望各位大佬帮忙指正纠正。