《利用Python进行数据分析》笔记记录第六章——数据载入、存储及文件格式的第二部分
文章目录
- 前言
- 一、二进制格式
-
- 1.1 使用HDF5格式
- 1.2 读取Microsoft Excel 文件
- 二、与Web API交互
- 三、与数据库交互
- 总结
前言
接着上回我们将继续对文本输入输出进行学习。
一、二进制格式
使用Python内建的pickle序列化模块进行二进制格式操作是存储数据(也称序列化)最高效、最方便的方式之一。pandas对象拥有一个to_pickle方法可以将数据以pickle格式写入硬盘。
frame = pd.read_csv(r'D:\python project\aa.csv')
print(frame)
---------------------------------------------------------
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
frame.to_pickle(r'D:\python project\frame_pickle')
你可以直接使用内建的pickle读取文件中"pickle化对象",或更方便地使用pandas,read_pickle做上述操作:
frame1 = pd.read_pickle(r'D:\python project\frame_pickle')
print(frame1)
---------------------------------------------------------
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
pickle仅被推荐作为短期的存储格式,问题在于pickle很难确保格式的长期有效性;一个今天被pickle化的对象可能明天会因为库的新版本而无法反序列化。
pandas内建支持其他两个二进制格式:HDF5和MessagePack。在下一节将会展出HDF5的一些示例。
1.1 使用HDF5格式
HDF5是一个备受好评的文件格式,用于存储大量的科学数组数据。它以c库的形式提供,并且具有许多其他语言的接口,包括Java、Julia、MATLAB和Python。HDF5中的“HDF”代表分层数据格式。每个HDF5文件可以存储多个数据集并且支持元数据。与更简单的格式相比,HDF5支持多种压缩模式的即时压缩,使得重复模式的数据可以更高效地存储。HDF5适用于处理不适合在内存中存储的超大型数据,可以使你高效读写大型数组的一块。
pandas提供了一个高阶的接口,可以简化Series和DataFrame的存储。HDFStore类像字典一样工作并处理低级别细节,HDFStore()是用于生成管理HDF5文件IO操作的对象:
store = pd.HDFStore('demo2.h5')
print(store)
------------------------------------------------------------
<class 'pandas.io.pytables.HDFStore'>
File path: demo2.h5
利用键值对将不同的数据存入store对象中:
s = pd.Series(np.random.randn(5),index=['a','b','c','d','e'])
frame = pd.DataFrame({'a': np.random.randn(100)})
store = pd.HDFStore('demo2.h5')
store['obj1'] = s
store['obj1_col'] = frame
for i in store.keys():
print(store[i])
------------------------------------------------------------
a -0.345438
b 1.838261
c -0.427200
d -0.646880
e 0.271832
dtype: float64
a
0 -1.981442
1 0.978182
2 0.381809
3 0.428230
4 1.077274
.. ...
95 2.462956
96 -0.626211
97 -0.895639
98 -0.055814
99 -1.034306
[100 rows x 1 columns]
包含在HDF5文件中的对象可以使用相同的字典型API进行检索:
print(store['obj1'])
------------------------------------------------------------
a -0.345438
b 1.838261
c -0.427200
d -0.646880
e 0.271832
dtype: float64
HDFStore支持两种存储模式。“fixed”和“table”。后者数度慢,但支持一种特殊语法的查询操作:
利用store对象的put()方法是第二种将数据存入store对象的方式。第一个参数是key值,第二参数是value值,第三个则是用于指定写出模式:
store.put('obj2',frame,format='table')
利用store对象的select()方法可以根据标签输出数据:
s = store.select('obj2',where=['index >= 10 and index <= 15'])
print(s)
------------------------------------------------------------
a
10 -0.109698
11 -0.205488
12 0.922490
13 0.983422
14 -0.336955
15 0.897830
而to_hdf也是用于存储格式的快捷方式,而pd.read_hdf如同select()方法:
frame.to_hdf('demo2.h5','obj3',format='table')
s1 = pd.read_hdf('demo2.h5','obj3',where=['index<5'])
print(s1)
------------------------------------------------------------
a
0 -1.981442
1 0.978182
2 0.381809
3 0.428230
4 1.077274
1.2 读取Microsoft Excel 文件
pandas支持通过ExcelFile类或pandas.read_excel函数读取存储在Excel2003(或更高版本)文件中的表格型数据。这些工具内部是使用附加包xlrd和openpyxl来分别读取XLS和XLSX文件的。你可能需要使用pip或conda手动安装这些工具。
使用ExcelFile时,通过将xls或xlsx的路径传入,生成一个实列:
xlsx = pd.ExcelFile('ex.xlsx')
print(xlsx)
------------------------------------------------------------
<pandas.io.excel._base.ExcelFile object at 0x00000154C225E5B0>
然后我们在ex.xlsx中添加这些数据:
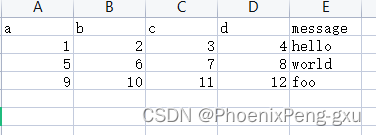
存储在表中的数据可以通过pandas.read_excel读取到DataFrame中:
df = pd.read_excel(xlsx,'Sheet1')
print(df)
-----------------------------------------------------------------
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
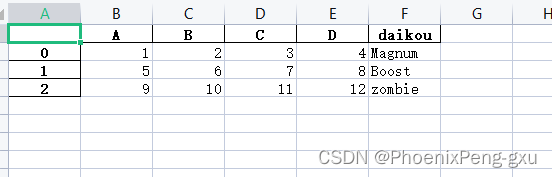
如果你读取的是含有多个表的文件,可以更改为“Sheet2”,就可以读取“Sheet2”中的数据:

df1 = pd.read_excel(xlsx,'Sheet2')
print(df1)
-----------------------------------------------------------------
A B C D daikou
0 1 2 3 4 Magnum
1 5 6 7 8 Boost
2 9 10 11 12 zombie
如需将pandas数据写入到Excel格式中,你必须先生成一个ExcelWriter,然后使用pandas对象的to_excel方法将数据写入,不用完了要用writer.save保存:
writer = pd.ExcelWriter('ex2.xlsx')
df2 = df1.to_excel(writer,'Sheet2')
writer.save()
也可以将文件路径传给to_excel,避免直接调用ExcelWriter:
df2 = df1.to_excel('ex2.xlsx','Sheet2')
二、与Web API交互
很多网站都有公开API,通过JSON或其他格式提供数据服务。有多种方式可以利用Python来访问API;书中推荐的简单易用方式是request包。
要获取GitHub上最新的30条关于pandas的问题,我们可以使用附加库requests发送一个HTTP GET请求:
import requests
url = 'https://api.github.com/repos/pandas-dev/pandas/issues'
resp = requests.get(url)
print(resp)
-----------------------------------------------------------------
<Response [200]>
Response(响应)对象的json方法将返回一个包含解析为本地Python对象的JSON的字典:
data = resp.json()
a = data[0]['title']
print(a)
-----------------------------------------------------------------
API: Series/DataFrame.mask(other) should default to lib.no_default instead of np.nan
data中的每一个元素都是一个包含GitHub问题页面上的所有数据的字典(注释除外)。我们可以将data直接传给DataFrame,并提取感兴兴趣的字段:
issues = pd.DataFrame(data, columns=['number', 'title'])
print(issues)
issues = pd.DataFrame(data, columns=['labels', 'state'])
print(issues)
-----------------------------------------------------------------
number title
0 49111 API: Series/DataFrame.mask(other) should defau...
1 49110 BUG: `quantile` sometimes using interpolation ...
2 49109 PERF: StringArray from np.str_ array
3 49108 BUG(?)/API: pd.NA + bytes raises TypeError
4 49107 REF: _reso->_creso
5 49106 ENH: date_range support reso keyword
6 49105 CLN/TST: Remove pandas_testing_mode
7 49104 BUG: Timestamp.__richcmp__(dt64_unsupported_reso)
8 49102 Backport PR #48770 on branch 1.5.x (added sytl...
9 49101 pylint: disable access-member-before-definitio...
10 49096 DEPS: Bump PyArrow to 5.0
11 49095 CLN/TST: Convert `tests/tseries/offset` to pyt...
12 49091 ENH: Add use nullable dtypes to read_excel
13 49089 DEP: Enforce deprecation of mangle_dup cols an...
14 49087 DEP: Enforce deprecation of names and dtype in...
15 49086 DEP: Enforce deprecation of date converters fo...
16 49084 DEP: Enforce set_values and set_codes inplace ...
17 49083 DEP: Enforce numpy keyword deprecation in read...
18 49082 DEP: Enforce deprecation of squeeze argument i...
19 49081 DEP: Enforce deprecation of pad/backfill for g...
20 49078 BUG: pickling subset of Arrow-backed data woul...
21 49076 API: Timestamp and Timedelta .value changing i...
22 49075 BUG: `USFederalHolidayCalendar.holidays` incon...
23 49073 ENH: `DatetimeProperties` results seem to be i...
24 49071 DOC: Typo on Dataframe.drop_duplicates() docst...
25 49069 ENH: add as_index to value_counts and pivot_table
26 49068 [PERF] Improve pickle support with BZ2 & LZMA
27 49066 PERF: sparse to_csv
28 49064 STYLE: fix pylint no-method-argument warning
29 49060 API: resolution for date_range, to_datetime, t...
labels state
0 [{'id': 2822342, 'node_id': 'MDU6TGFiZWwyODIyM... open
1 [{'id': 76811, 'node_id': 'MDU6TGFiZWw3NjgxMQ=... open
2 [{'id': 8935311, 'node_id': 'MDU6TGFiZWw4OTM1M... open
3 [{'id': 2822342, 'node_id': 'MDU6TGFiZWwyODIyM... open
4 [] open
5 [] open
6 [{'id': 127685, 'node_id': 'MDU6TGFiZWwxMjc2OD... open
7 [] open
8 [{'id': 1508144531, 'node_id': 'MDU6TGFiZWwxNT... open
9 [{'id': 106935113, 'node_id': 'MDU6TGFiZWwxMDY... open
10 [{'id': 527603109, 'node_id': 'MDU6TGFiZWw1Mjc... open
11 [{'id': 127685, 'node_id': 'MDU6TGFiZWwxMjc2OD... open
12 [{'id': 76812, 'node_id': 'MDU6TGFiZWw3NjgxMg=... open
13 [{'id': 49254273, 'node_id': 'MDU6TGFiZWw0OTI1... open
14 [{'id': 87485152, 'node_id': 'MDU6TGFiZWw4NzQ4... open
15 [{'id': 47229171, 'node_id': 'MDU6TGFiZWw0NzIy... open
16 [{'id': 71268330, 'node_id': 'MDU6TGFiZWw3MTI2... open
17 [{'id': 49379259, 'node_id': 'MDU6TGFiZWw0OTM3... open
18 [{'id': 233160, 'node_id': 'MDU6TGFiZWwyMzMxNj... open
19 [{'id': 233160, 'node_id': 'MDU6TGFiZWwyMzMxNj... open
20 [{'id': 1625435109, 'node_id': 'MDU6TGFiZWwxNj... open
21 [{'id': 49597148, 'node_id': 'MDU6TGFiZWw0OTU5... open
22 [{'id': 76811, 'node_id': 'MDU6TGFiZWw3NjgxMQ=... open
23 [{'id': 76812, 'node_id': 'MDU6TGFiZWw3NjgxMg=... open
24 [{'id': 134699, 'node_id': 'MDU6TGFiZWwxMzQ2OT... open
25 [{'id': 76812, 'node_id': 'MDU6TGFiZWw3NjgxMg=... open
26 [{'id': 8935311, 'node_id': 'MDU6TGFiZWw4OTM1M... open
27 [{'id': 8935311, 'node_id': 'MDU6TGFiZWw4OTM1M... open
28 [{'id': 106935113, 'node_id': 'MDU6TGFiZWwxMDY... open
29 [{'id': 35818298, 'node_id': 'MDU6TGFiZWwzNTgx... open
三、与数据库交互
在业务场景中,大部分数据并不是储存在文本或Excel文件中。基于SQL的关系型数据库(例如SQL Server、PostgreSQL 和MySQL)使用广泛,很多小众数据库也变得越来越发流行。数据库的选择通常取决于性能、数据完整性以及应用的可伸缩性需求。
从SQL中将数据读取为DataFrame是相当简单直接的,pandas有多个函数可以简化这个过程。作为例子,我将使用Python内建的sqlite3驱动来生成一个SQLite数据库:
import sqlite3
query = """
CREATE TABLE test2
(a VARCHAR(20), b VARCHAR(20),
c REAL , d INTEGER);"""
con = sqlite3.connect('mydata.sqlite')
a = con.execute(query)
print(a)
con.commit()
-----------------------------------------------------------------
<sqlite3.Cursor object at 0x00000234C0CDBC00>
在上面的例子中,connect()方法是用于连接数据库,返回一个数据库连接对象。而指针对象的execute(query[,parameters])方法执行数据库查询。连接对象的db.commit()方法表示事务提交。
再插入几行数据:
data = [('Geats','Magnum',22,6),('Tycoon','Ninja',21,9),('Buffa','Zombie',20,1)]
stmt = 'INSERT INTO test2 VALUES(?,?,?,?)'
a1 = con.executemany(stmt ,data)
print(a1)
con.commit()
-----------------------------------------------------------------
<sqlite3.Cursor object at 0x00000234C0CDB9D0>
对象的executemany()方法,在一次数据库的IO操作中,可以插入多条记录。
当从数据库中的表中选择数据时,大部分Python的SQL驱动(PyODBC、psycopg2、MySQLdb、pymssql等)返回的是元组的列表:
cursor = con.execute('select * from test2')
rows = cursor.fetchall()
print(rows)
-----------------------------------------------------------------
[('Geats', 'Magnum', 22.0, 6),
('Tycoon', 'Ninja', 21.0, 9),
('Buffa', 'Zombie', 20.0, 1)]
指针对象的cursor.fetchall()可取出指针结果集中的所有行,返回多个元组,即返回多条记录(rows),
你可以将元组的列表传给DataFrame构造函数,但你还需要包含在游标的description属性中的列名:
cursor.description
-----------------------------------------------------------------
(('a', None, None, None, None, None, None),
('b', None, None, None, None, None, None),
('c', None, None, None, None, None, None),
('d', None, None, None, None, None, None))
a2 = pd.DataFrame(rows,columns=[x[0] for x in cursor.description])
print(a2)
-----------------------------------------------------------------
a b c d
0 Geats Magnum 22.0 6
1 Tycoon Ninja 21.0 9
2 Buffa Zombie 20.0 1
SQLAlchemy项目是一个流行的Python SQL工具包,抽象去除了SQL数据库之间的许多常见差异。pandas有一个read_sql函数允许你从通用的SQLAlchemy连接中轻松地读取数据。这里,我将使用SQLAlchemy连接到相同的SQLite数据库,并从之前创建的表中读取数据:
import sqlalchemy as sqla
db = sqla.create_engine("sqlite:///mydata.sqlite")
a1 = pd.read_sql('select * from test2',db)
print(a1)
-----------------------------------------------------------------
a b c d
0 Geats Magnum 22.0 6
1 Tycoon Ninja 21.0 9
2 Buffa Zombie 20.0 1
总结
访问数据通常是数据分析过程的第一步。我们在本章已经学习了一些有用的工具,可以帮助入门。在后续章节中,我们将深入数据处理、数据可视化、时间序列分析和其他主题。