【论文阅读VLDB13】Online, Asynchronous Schema Change in F1
Online, Asynchronous Schema Change in F1
ABSTRACT
在一个globally 分布式数据库,with shared data, stateless servers, and no global membership.进行一个schema演变。证明许多常见的模式更改可能会导致异常和数据库损坏,通过将破坏引起的模式更改替换为一系列模式更改来避免这些问题,这些更改保证避免破坏数据库,只要所有服务器在任何时候都不超过一个模式版本。最后,我们讨论了我们的协议在 F1 中的实际实现,F1 是存储 Google AdWords 数据的数据库管理系统。
1. INTRODUCTION
将 Spanner 视为键值存储。F1影响模式更改的主要特性有:
- Massively distributed:F1的一个实例由数百个独立的F1服务器组成
- Relational schema:每个F1服务器都有一个描述表、列、索引和约束的关系模式副本。对模式的任何修改都需要进行分布式模式更改以更新所有服务器
- Shared data storage:所有数据中心的所有F1服务器都可以访问存储在Spanner中的所有数据。F1服务器之间没有数据分区。
- Stateless servers:F1服务器必须容忍机器故障、抢占和对网络资源的访问丢失。为了解决这个问题,F1服务器在很大程度上是无状态的——客户端可以连接到任何F1服务器,即使是同一事务中的不同语句。
- No global membership:因为F1服务器是无状态的,所以F1不需要实现全局成员协议。这意味着没有可靠的机制来确定当前正在运行的F1服务器,并且不可能实现显式的全局同步。
对模式更改过程施加了几个约束:
- Full data availability:在模式更改期间(例如,锁定一列以构建索引)使数据库的一部分脱机是不可接受的。
- Minimal performance impact:F1的schema会改变的很快来支持日常业务,因为模式更改是频繁的,所以它们必须对用户操作的响应时间产生最小的影响
- Asynchronous schema change:异步更改,不同的F1服务器可能会在不同的时间转换到使用新的模式。
首先,由于所有数据都必须尽可能可用,因此我们不限制对正在进行重组的数据的访问。其次,因为模式更改必须对用户事务的影响最小,所以我们允许事务跨越任意数量的模式更改。最后,在单个F1服务器上异步应用模式更改意味着可以同时使用模式的多个版本。
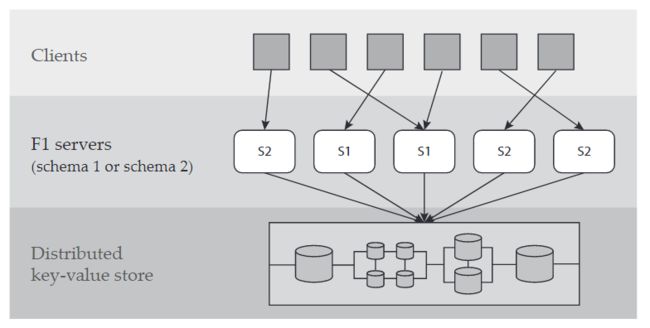
所有服务器共享相同的键值存储,但是有多版本的schema在F1 servers.
因为每个服务器都共享对所有数据的访问,所以使用不同模式版本的服务器可能会破坏数据库。假设两个不同的服务器,M1和M2,执行以下操作序列:
- 服务器M2使用schema S2,向表R中插入行r,因为S2有索引I,所以M2也会在KV存储里面加上一个新的关于r的index entry
- 服务器M1使用schema S1,删除行r,因为S1不包含索引I,M1能够成功删除行r,但是删除对应的索引项失败。
这样第二次删除会使数据库损坏。例如,index-only scan将返回不正确的结果,其中包含已删除行r的列值。
要开发一种协议来解决在分布式数据库下,共享数据访问下异步、模式演变所带来的问题。不仅考虑对逻辑模式的更改,如添加或删除列,还考虑对物理模式的更改,如添加或删除二级索引。通过确保在任何给定时间使用的模式版本不超过两个,并且这些模式版本具有特定的属性,我们的协议支持分布式模式更改,而不需要全局成员关系、节点之间的隐式或显式同步,也不需要在模式更改完成后保留旧的模式版本。
本文主要贡献是:
- 描述 在键值存储之上构建全局规模分布式DBMS时所做的设计选择以及它们对模式更改操作的影响。
- 在共享数据访问的系统中异步执行模式更改的协议,同时避免导致数据损坏的异常。该协议允许在模式更改期间由用户事务并发修改数据库
- 提出的模式更改协议的形式化模型和正确性证明。
- 讨论为了实现协议而对系统所做的更改。
- 在谷歌AdWords使用的生产系统中对协议的实现和有效性进行了评估。
在第2节中解释键值存储的接口以及F1的关系模式和操作的高级设计。第三节,为我们支持的模式更改提供了一个模型,并展示了我们如何设计它们以防止可能破坏数据库的各种异常。在第4节中,我们描述了如何在为谷歌的AdWords服务了一年多的生产F1系统中实现这些模式更改,在第5节中提供了有关系统性能和整体用户体验的一些信息。最后,我们在第6节讨论相关工作,并在第7节结束。
2. BACKGROUND
F1存relation view 作为KV 存到KV store里面,传统关系型db
2.1 Key–value store
kv store支持get put del,使用occ,OCC添加了下面俩限制
- Commit timestamps:提交时间戳。每个键-值对都有一个最后修改的时间戳,由键-值存储自动更新。
- Atomic test-and-set support:多个get和put操作可以原子执行。
2.2 Relational schema
一个F1 schema是一个table definition的集合,一个 table definition通常包含了column list(以及它们的类型)、secondary index list次要索引列表、完整性约束列表(外键或索引唯一性约束)和乐观锁列表。列值可以是primitive type 或者 complex type,主键的值必须是原生类型。
-
Primitive type / complex type
In Hive:complex data types: structs Maps Arrays union
primitive type就是最基本的int bigint等
2.3 Row representation
row 就是一组 kv pairs,每个非主键列就是一对kv,每个列的key逻辑上包括了table name,该行的主键值以及列名。物理上不需要这种重复存key的冗余信息,F1的物理存储格式消除了这种冗余,我们表示r行中C列值的key为 k r ( C ) k_r{(C)} kr(C)。还有一个特殊的列叫exists,

map 关系table → KV table
F1支持secondary index,一个二级索引包括了表上一系列非空列,二级索引本身是由很多kv pairs组成,索引表中的每一行都有一个关联的索引键值对,这个pair的key是连接了table name,index name,该行的列索引值集合以及该行的主键值。我们将索引I中第r行的索引key表示为kr (I),当在特殊的exists列的情况下,value is null。
2.4 Relational operations
- insert(R, vk_R, vc_r)用主键值vk_R和非键列值vc_r插入行R到表R。如果表R中已经存在具有相同主键值的行,则插入失败。
- delete(R, vk R)删除表R中主键值为vk R的行R
- update(R, vk R, vcr)通过将非键列子集的值替换为vcr中的值,用表R中的主键值vk R更新行R。更新不能修改主键的值。这样的更新是通过删除和插入来建模的。
- query ( R ⃗ , C ⃗ , P ) (\vec{R}, \vec{C}, P) (R,C,P) returns a projection C ⃗ \vec{C} C of rows from tables in R ⃗ \vec{R} R that satisfy predicate P P P.
使用write 用以替代insert delete update,read 代替query。
delete(R, vk R)删除模式S中表R上定义的主键vk R的所有列和索引对应的所有键值对。因此,我们将所有操作都下标为与其相关的模式,例如delete_s(R, vk R)。
u p d a t e s 1 ( R , v k r , v c r ) update_s^1(R,vk_r,vc_r) updates1(R,vkr,vcr)是事务T1在schema S上做的更新操作。
2.5 Concurrency control
F1使用T/O OCC,F1的schema在每个表上记录一个乐观锁optimistic lock;一个表有很多锁
F1实现行级锁定。但是,由于用户可以向表中添加新锁并将它们与该表中的任意列关联,因此F1用户可以根据需要选择从行级到列级的锁粒度。因此,我们必须考虑从模式中添加或删除锁的模式更改的正确性
3. SCHEMA CHANGES
需要一个正式的模型来验证其正确性,因为不正确执行的模式更改可能导致灾难性的数据丢失。后面对模式更改的正确性会给出形式化说明。
F1 servers共享kv store,为了解析这些kv pairs,就需要schema,每个F1 server 做一个copy schema到自己内存中,然后用这个schema来处理关系算子转化成KV操作,当客户端发起请求的时候,使用的schema是根据F1 SERVER 当前内存中的schema 来决定的。
这个schema其实相当于要所有servers共识,在所有servers里面schema都一致的。schema 有个 copy?
修改完copy之后开始schema change→意味着要把这个schema传递给所有server。因为F1是一个高度分布式的系统,有数百台服务器,无法在它们之间进行同步(无论是显式的还是隐式的),所以不同的服务器可能会在不同的时间转换到新的模式(参见图2),并且可能同时使用多个模式版本。

因此,只有当实例中的所有F1服务器都加载了新模式时,我们才说模式更改完成了。
由于一个实例中的所有F1服务器共享一个键值存储,因此不正确地执行异步模式更改可能会损坏数据库。例如,如果模式更改向数据库添加了索引,则仍然在旧模式上运行的服务器将无法维护新索引。如果发生这种情况,任何执行索引读取的查询都将返回不正确的结果。
这种破坏的根本原因是对模式所做的更改在某种意义上太突然了。旧模式上的服务器不知道索引,而新模式上的服务器在所有操作中使用索引,就好像它得到了完全维护一样。此外,尽管我们以添加索引为例,但这个问题在系统中的所有基本模式更改操作中都会发生。
为了解决这个问题,我们设计了一个协议来安全执行依赖于使用中间状态intermediate states的模式更改。
使用我们的协议,可以将模式元素(如表、列、索引等)置于中间状态,限制某些操作的发生,使得能够将单个危险的schema change分解为一系列安全的模式更改,以显示执行正确的行为。
为了简化对实现正确性的推断,我们限制F1实例中的服务器不能使用两个以上不同的模式版本。我们的协议期望所有服务器要么使用最新的模式版本,要么使用最多一个旧版本的模式.允许同时使用两个以上的模式版本也是可能的,但由于这将大大增加关于正确性推理的复杂性,并且实用性有限,因此我们选择在协议中不支持它。
为了描述用于安全执行分布式异步模式更改的协议,并推断其正确性,先描述一下F1 schema的状态和元素。
3.1 Schema elements and states
F1模式有表、列、索引、约束和乐观锁。统称为模式元素,模式中的每个元素都有一个与之相关联的状态。我们认为有两种状态是非中间状态:缺席状态absent 和公共状态public。如果一个元素没有出现在模式中,那么它就是缺席的。如果一个元素存在于模式中,并且它可以被所有操作影响或应用于所有操作,那么它就是公共的。因此,这是用户在向模式添加元素或从模式中删除元素时请求的两种状态。
F1也有两种内部中间状态的概念:delete-only and write-only
- 定义1:delete-only : 一个处于 delete-only table, column, or index状态的对应的kv pairs不能被用户数读,并且
- 如果E是表或列,则只能通过delete操作进行修改;
- 如果E是索引,则只能通过delete和updateoperations进行修改;update可能删除更新索引键对应的键值对,但不能创建新的索引键。
因此当一个元素delete only,F1服务器将根据需要删除其关联的键值对(例如,从索引中删除条目)但它们不允许为该元素插入任何新的键值对。
- 定义2:A write-only column or index可以通过插入、删除和更新操作修改它们的键值对,但是它们的任何对都不能被用户事务读取。这种状态允许写入数据,但不允许读取数据(在索引的情况下,F1服务器不会使用只写索引来加速查找)。
- 定义3:A write-only constraint只写约束1应用于所有新的插入、删除和更新操作,但不能保证保留所有现有数据。F1服务器将对数据库上的新操作实施约束,但是对数据库的读取可能会看到违反约束的数据。
尽管拥有可以将数据插入到数据库中但不读取或以似乎违反预期的方式读取的状态似乎很奇怪,在以下几节中说明,小心使用这些状态对于确保跨所有F1服务器的数据库中的键值对的一致视图非常重要。
3.2 Database consistency
kv存储所有数据需要对应于schema的某个列或索引条目,否则,键值存储将包含一些不属于数据库的“垃圾”数据.此外,数据库必须满足模式中存在的所有约束。介绍一下形式化定义来定义一致性,以此来评估数据库是否被破坏。
- 定义4:数据库表示d与模式S相一致 当且仅当
- 如果不包含行和表,则不存在列值。对于每个列值
- 所有行都具有所有公共必需的列值。 F o r e v e r y r e q u i r e d p u b l i c c o l u m n C i n t a b l e R ∈ S , i f t h e r e e x i s t s ⟨ k r ( e x i s t s ) , n u l l ⟩ ∈ d , t h e r e e x i s t s ⟨ k r ( C ) , v r ( C ) ⟩ ∈ d For every required public column C in table R \in S, if there exists \left\langle k_r\right. (exists ), null \rangle \in d, there exists \left\langle k_r(C), v_r(C)\right\rangle \in d ForeveryrequiredpubliccolumnCintableR∈S,ifthereexists⟨kr(exists),null⟩∈d,thereexists⟨kr(C),vr(C)⟩∈d
- 模式中没有相应的索引就不存在索引项
- 所有公共索引都是完整的。
- 所有索引条目指向有效行
- All public constraints are honored.
- No unknown values.
- 如果不包含行和表,则不存在列值。对于每个列值
我们将数据库表示 d 与模式 S 一致的事实表示为 d |= S。
数据库表示 d 相对于模式 S 的一致性可以通过两种方式违反:
- 有不符合schema的kv pair,叫做orphan data anomaly孤儿数据异常,数据库表示 d 违反了定义 4 的子句 1、3、5 或 7,则其相对于 S 有孤儿数据。
- 数据库表示d缺少一个根据模式S应该包含的键-值对,或者它包含一个违反模式S中的公共约束的键-值对。这种是 :integrity anomaly完整性约束违反,具体来说,如果数据库表示d违反定义4的第2、4或6条,则它具有完整性异常
OPs是delete、update、insert、query,在schema下的操作,每个正确的操作实现都可以保证该schema下的数据库一致性,但是在schema change下,不能保证,为了避免这种情况,我们定义了consistencypreserving schema change一致性保持模式更改的概念。
- 定义5: 从模式S1到模式S2的模式更改是保持一致性的,当且仅当,对于任何与S1和S2相一致的数据库表示d有以下成立:
- 任何操作opS1都保留d相对于模式S2的一致性。
- 任何操作opS2都保持d相对于模式S1的一致性
没有必要要求所有操作保持数据库表示相对于旧模式S1的一致性。毕竟,一旦模式更改完成,所有F1服务器都将使用新的模式S2。因此,只要所有操作保持与S2的一致性,一旦模式更改完成,数据库表示就会保持一致。
但是,使用旧模式 S1 的 F1 服务器对与 S1 不一致的表示进行操作可能会发出产生与新模式 S2 不一致的数据库表示的操作,即如果应用于数据库表示 d ≠ S1,操作 opS1 具有未定义的行为。假设从S1→S2,添加了一个列C和仅与模式S2一致的数据库表示d。 i n s e r t S 2 ( R , v k r , v r ( C ) ) insert_{S_2}(R,vk_r,v_r(C)) insertS2(R,vkr,vr(C)) 按照S2,向表R中,根据主键值vkr,插入列值vrc,r代表某一行。得到的数据库表示d '仍然与模式S2一致(但不是S1!)。现在,假设稍后对数据库表示d '执行 d e l e t e S 1 ( R , v k r ) delete_{S1}(R, vk_r) deleteS1(R,vkr)操作,按照schema S1删除该表中的行r,它无法从数据库表示d '中删除键值对< kr ©, vr © >,因为列C不存在于模式S1中,使得键值对< kr ©, vr © >对于模式S2来说是孤立的。因此,得到的数据库表示d ''与模式S2不一致,而且,在模式更改完成后,损坏将持续存在。
因此,我们必须在定义5中要求,在保持一致性的模式更改期间,所有操作在模式更改期间始终保持与旧模式s1和新模式S2的一致性。这个属性也意味着定义5是对称的:
CLAIM 1. 从模式S1到模式S2的模式更改是保持一致性的,如果从模式S2到模式S1的模式更改是保持一致性的。
保持一致性的模式更改确保数据库不会损坏;然而,许多常见的模式更改并不能保持一致性。
3.3 Adding and removing schema elements
F1用户请求的最常见的模式更改是在模式中添加和删除元素,如表、列和约束。将表、列(包括乐观锁)和索引作为structural schema elements (or simply structural elements).由于同时使用多个模式版本,在不使用任何中间状态的情况下添加或删除任何结构元素都有可能破坏数据库。
CLAIM 2. 从模式S1到模式S2的任何模式更改,无论是添加还是删除公共结构元素E,都不能保持一致性。
PROOF:考虑从模式S1到模式S2的模式更改,其中添加了结构元素E和一个(可能为空的)数据库表示d |= S1, S2。E可能是下面几种:
- E is a Table,假设 i n s e r t S 2 ( E , v k r , v c r ) insert_{S_2}(E,vk_r,vc_r) insertS2(E,vkr,vcr)得到d’ , d’ ≠ S1,因为inserts2添加的是相对S1的孤儿数据,违反了定义4的第一条(没有表和行,就没有列值)
- E是table R column, i n s e r t S 2 ( R , v k r , v r ( E ) ) insert_{S_2}(R,vk_r,v_r(E)) insertS2(R,vkr,vr(E)),向新加的列E中插入对应的列值,和上面一样,S1没有该行,肯定和S1不保持一致性。
- E是table R的index, i n s e r t S 2 ( R , v k r , v c r ) insert_{S_2}(R,vk_r,vc_r) insertS2(R,vkr,vcr),新加入的行r的所有列被index E cover,得到d’’’,d’’’≠S1 也≠ S2,违反了定义4.3(对S1来说没有索引) 4.4(对S2来说只有新插入的有索引)
然而,通过明智地使用我们在3.1节中描述的中间状态,可以防止这些异常。当以适当的顺序应用这些中间状态时,可以确保数据库表示中不会出现孤立数据或完整性异常,从而允许我们执行保持一致性的模式更改。
CLAIM 3. 从模式S1到模式S2的模式更改是保持一致性的,前提是它避免了相对于S1和S2的孤立数据和完整性异常。
PROOF: 粗浅理解为满足定义4的所有要求也就没有孤立数据和完整性异常。
依次讨论支持添加和删除可选结构元素、必需结构元素和约束所需的确切中间状态。
-
3.3.1 Optional structural elements
这里元素指的是schema的元素,表、列索引等。添加和删除公共可选元素可能会导致孤立数据异常,因为一些服务器知道其他服务器不知道的元素,并且这些元素可以由用户事务自由修改。通过确保元素在被设置为public(在添加的情况下)或被删除(在删除的情况下)之前经过一个中间模式来消除这些异常。能够以一种不损害数据库表示一致性的方式向模式添加一个新的、只能删除的元素。
CLAIM 4. S1→S2,添加一个delete-only 结构元素E,d |= S1,则添加之后 d |= S2。且d中E的任何操作opS1或opS2都不会导致相对于S1或S2的孤儿数据或完整性异常。
Proof:因为d |= S1,而E在S1中不存在,所以d中没有对应E的键值对。元素E在S2中不是公共的,因此不需要这样的键值对来建立d |= S2。(粗浅理解就是改了 但是没生效不要求填入数据的状态)
假设E是一个index,使用S2的操作不会相对于使用S1的操作增加任何新的键值对;由于两种模式都不允许插入任何对应于E的键值对,因此使用s1和S2的任何操作对都可以轻松地避免孤立数据异常。并且禁止插入符合S2的操作,所以相比于S1 没有增加任何符合S2不符合S1的数据。
不会发生完整性异常,因为S1和S2都不会对数据库中的键值对施加任何新的需求或约束,因为E是可选的。
一旦可选结构元素在模式中处于仅删除状态,就可以将其提升为公共,而不会导致进一步的异常。
CLAIM 5. S1→S2,将可选的结构元素e从delete-only提升为public,d |= S1 ,则 d |= S2。在d中的E上没有操作opS1或opS2可以导致关于S1或S2的孤儿数据或完整性异常。
Proof:因为d |= S1,E是S1下delete only,d中可有 也可以没有 E对应的pair,因为E是可选的,在S2中,E的pair是允许但是不是必须的,所以d | = S2。
如果存在,使用模式 S1 删除操作将删除与结构元素 E 对应的键值对,因为元素在 S1 中处于仅删除状态。类似地,如果存在,使用模式 S2 的操作将删除与结构元素 E 对应的键值对,因为E is public。因此,所有操作都将通过删除与结构元素 E 对应的键值对来避免孤儿数据异常。完整性异常不会发生,因为元素 E 是可选的。
因此,如果一个结构元素是可选的,它可以安全地从模式中添加或者删除,只有一个中间schema和以下状态转换(删除的顺序颠倒):absent → delete-only → public。
然而,删除还有一个额外步骤,必须删除 和被删除的结构元素有关的的键值对。
展示了如何仅使用delete-only中间状态添加和删除可选元素;然而,为了支持添加和删除所需的结构元素和约束,需要一个额外的状态。
-
3.3.2 Required structural elements
除了影响可选元素的孤立数据异常之外,在公共状态下添加和删除这些元素也会导致完整性异常。在删除的情况下,状态顺序颠倒,并且database reorganization发生在转换到absent之前):
演示如何将write-only状态与delete-only状态结合使用,通过以下状态转换以保持一致性的方式执行这些模式更改
absent → delete only → write only →(db rcorg) public
CLAIM 6. 模式S1→S2,index或者column E从delete-only → write-only,并使用d |= S1这样的任何数据库表示,则d |= S2,对d中E的操作ops1, ops2都不会引起孤儿数据或者相对于S1或者S2的完整性约束。
PROOF:模式S1和S2包含除了元素E以外的相同元素。S1,S2在internal state里面都包含E,这两个模式都允许对应于d中的E的键值对,但是并不强制要求存在,因此d|s1,d|s2。不会造成孤儿数据:考虑E是索引,假设某行r,存在孤键值对< kr (E), null >。该孤值对只能通过删除或更新来形成。但是,deleteS1和updateS1不能形成孤儿,因为E在模式S1中是只删除的。类似地,deleteS2和updates2不能形成孤儿,因为E在模式S2中是只写的。由于S1和S2都不要求存在对应于E的键值对,因此完整性异常不会发生。如果E是必填项列,同样的推理也适用。
即在write-only state可以添加索引或者列,不会导致孤儿数据或者完整性问题。一旦元素处于仅写状态,所有F1服务器将确保为新数据正确维护它;但是,在模式更改之前存在的数据可能不一致。因此,在将索引或所需列提升为public之前,必须执行一个数据库重组过程database reorganization process,该过程将填充与新元素对应的缺失键值对对应的所有缺失键值对。完成此操作后,元素就可以转换为public而不会导致异常。
CLAIM 7. S1→S2,E从write-only 到 public,d|=s1,s2,那么在E in d上的操作opS1或opS2都不会导致相对于s1或S2的孤儿数据或完整性异常。
定理1:考虑从模式S1到模式S2的模式更改,该更改添加或删除结构元素e,并使用任何数据库表示d1,使d1 |= S1。然后是一系列保持一致性的模式更改,最多一次数据库重组,将所有服务器转换到模式S2,并将d1修改为数据库表示d2,以便d2 |= S2。
-
3.3.3 Constraints
F1支持外键和索引唯一性完整性约束。添加和删除这些约束可能会导致完整性异常;例如,如果在不使用中间状态的情况下向列添加唯一性约束,则使用旧模式的服务器将允许插入重复值,从而从新模式上的服务器的角度来看,导致违反约束。这些异常可以通过首先在只写状态下添加以下状态转换的约束来防止:
absent → write only → public
3.4 Changing lock coverage
F1在schema中标识乐观锁为named objects,用户可以修改乐观锁覆盖哪些列来修改每个表的锁粒度。锁覆盖模式更改会修改哪个锁处理给定列的并发控制。drop lock隐式地导致相应的锁覆盖变化,又因为所有列都必须被某个锁覆盖。对锁覆盖的更改如果实现不当,可能会允许非序列化的调度。
CLAIM 8. 从模式S1到S2的模式更改(将列C的覆盖范围从锁L1更改为锁L2)允许非序列化调度。
PROOF:事务Ti Tj如下:

如果事务Ti提交,这个调度是不可序列化的,因为在事务Ti和事务Tj之间存在读写冲突。但是,由于事务使用不同的模式,对C具有不同的锁覆盖率,因此该调度将(错误地)被允许。事务i,使用模式S1的lock L1,读取和更新锁的时间戳,事务j,用的是S2的lock L2来读取和更新时间戳,所以Tj不会管Ti的时间戳,验证成功错误提交。
解决:允许列临时被多个lock覆盖。模式更改的时候,插入一个中间状态,列同时被旧锁和新锁覆盖,叫做dualcoverage,必须读取、验证和更新与该列关联的所有锁。
BUT,这种模式更改的组合仍然允许非序列化的调度。假设schemaS1中的锁L1覆盖的列C,模式S2中的锁L1和L2,以及schemaS3中的锁L2,锁L1和锁L2具有相同的时间戳t1,

在第一个操作中,Ti接收到锁L1的时间戳t1。在第二个操作中,Tj将S1 lockL1 的时间戳更新为时间戳t2 (t2 > t1)。当Ti使用S3提交其写操作时,时间戳t1由服务器根据S3中列出的当前锁(L2)进行验证。L2的时间戳没有因为上面的调度而改变,s1通过了验证,允许一个非序列化的调度。
通过使用数据库重组来防止并发异常,所有servers转换到dualcoverage状态,执行一个重组过程,如下公式重组L2的时间戳。
timestamp(L2) = max(timestamp(L1), timestamp(L2))
通过这种修改,可以在模式更改的时候实现锁覆盖的没有任何不可串行化的调度。
CLAIM 9. 任何修改了列C 的lock 从L1→L2的S1→S2,都可以替换为重组和一系列模式更改,以避免不可序列化的调度。
Proof:S’是一个模式,列C被锁L1和L2同时被锁L1和L2覆盖,我们用以下方式替换从模式S1到S2的模式更改:从S1→S’,如果需要,将L1实例的时间戳传播到L2实例的重组过程,以及从S '到S2的模式更改。在模式从S1更改到S '期间,所有操作都有效地针对L1进行验证。虽然L2存在并由使用S2的操作维护,但它还没有用于并发控制。因此,唯一允许的调度是被L1 cover的列C,它们对应于可串行化的调度。
在第一次模式变更之后,但在开始从S '到S2的模式变更之前,重组过程确保每一行的时间戳(L2)≥时间戳(L1),因此,当不执行锁覆盖更改且仅使用锁L1的时候(即不可序列化的调度),被拒绝的调度在使用双覆盖(锁L1和L2)或仅使用L2时不能被接受。因此,在从S '到S2的模式更改期间,只能允许可序列化的计划。
下图总结了每个模式更改所需的中间状态以及它们之间的转换。

4. IMPLEMENTATION
4.1 Spanner
与F1模式更改相关的两个Spanner特性:垃圾收集和写防护与F1模式更改相关的两个Spanner特性:垃圾收集和写防护garbage collection and write fencing:
-
Garbage collection
spanner里面的模式描述了允许的KV集合,不被允许的都不能被访问最后被回收,从spanner模式里面主动删除结构元素,可以不需要重组数据库,等同于删除所有关联的键值对。
-
Write fencing
如果一个写操作要花费很长时间提交,这个过程中会涉及多个模式更改然后才生效,违反了操作必须基于不超过一个模式更改的要求,Spanner允许我们为每个写操作设置一个截止日期,以便在截止日期之后提交写操作,就不会涉及多个模式更改?
4.2 Schema change process
F1不去实现DDL操作来进行模式更改,使用DDL语句单独应用更改不如果将多个模式更改批处理在一起,后者可以平摊大部分开销(例如,重组)。
F1把数据库的模式作为protocol buffer-encoded file,该文件的版本是从存储在版本控制系统中的source生成的;当用户需要修改模式时,他们更新版本控制系统中的source,来包含上所想要的change,这允许我们将对模式的多个更新批处理为一个模式更改操作。
admin每周两次从版本控制系统中获取模式,并将其应用于正在运行的F1实例。在应用新模式之前,分析过程确定需要哪些中间状态和重组才能安全地执行模式更改。一旦确定了中间模式和重组,执行过程将按顺序应用它们,同时确保在任何时候使用的模式版本不超过两个。单个中间模式可以将状态转换应用于模式中的许多不同元素(同一行中发生的状态转换被合并为单个模式更改)。
4.3 Schema leases
我们的模式更改协议要求F1服务器最多同时使用两个不同的模式。由于F1不维护全局服务器成员关系,因此我们无法直接联系服务器以检查它们正在运行的模式版本或使用新模式更新它们。此外,即使全局成员数据可用,F1也需要一种方法来处理无响应的服务器。
通过为每个F1服务器授予模式租期schema leases来解决这个问题,租期的典型值为几分钟,F1服务器通过在每个租期period从键值存储中的已知位置重新读取模式来更新租期。如果服务器无法更新其租期,它将终止—由于F1服务器在托管集群执行环境中运行,因此它们将在健康节点上自动重新启动。
将单个写操作限制为仅使用具有活动租约的模式,如果单个写操作的执行时间超过两个租期,则可能违反我们的要求,即在任何时候只能使用两个最新的模式版本。我们使用写防护来确保,如果它所基于的模式具有过期的租约,则不会提交任何写操作。
需要维护以下常量:
Invariant 1. 如果在时间t0写入模式S,并且在时间t0和t1之间没有写入其他模式(t1 > t0 +lease_period),那么在时间t1,每个F1服务器要么使用要么无法提交事务。
因此,我们通过每个租期最多写入一个模式来确保F1服务器在任何时候最多使用两个模式。
4.4 Data reorganization
一些模式更改(如添加索引)需要对数据库表示进行相应的更新。我们使用backgroud reorganizer执行这些更新,要考虑到
- 假设整个重组可以自动完成是不切实际的。因此,重组器的操作必须是可恢复的和幂等的。
- 在重组程序执行时,所有数据必须可用。因此,重组器必须允许对被修改数据的并发访问。
- 重组器应该避免重新执行已经由用户事务执行的数据更改(例如,重新添加已经存在的索引键值对)。
我们使用MapReduce框架构建了我们的重组器,MapReduce控制器对数据库进行分区,并为map任务分配分区。map任务在对应于模式更改开始的快照时间戳扫描其分配的分区中的所有行,并在必要时更新每一行以符合新模式。每个map task读取分配给它的每一行的表示,并确定自重组开始以来是否已被用户事务更新。如果重组了,则根据Thomas 写规则不能修改改行,否则,它会根据需要添加或删除键值对。
4.5 Schema repository
由于在我们的生产F1实例中经常发生模式更改,因此在从一个模式转移到另一个模式时,每个F1服务器不会延迟或失败大量用户操作,这一点很重要。为了管理这种转换,每个服务器在其易失性内存中存储一个模式存储库。模式存储库存储多个模式版本以及与它们相关联的租用时间,模式存储库维护以下几个不变量:
- 新的写操作使用存储库中可用的最新模式版本
- 存储库加载新模式版本后,允许挂起的写操作使用先前分配的模式版本完成。
- 当相关模式版本的租约到期时,所有提交的写操作都将通过write fencing终止
由于租约到期而终止的写操作由服务器重新提交,但这会导致浪费工作。我们可以通过提前更新模式租约来降低写操作失败的可能性;然而,更频繁的租约更新增加了F1和Spanner的负载。根据我们的经验,我们发现在租赁期限还剩一半时续签租约是一个合理的设置。
5. IMPACT ON USER TRANSACTIONS
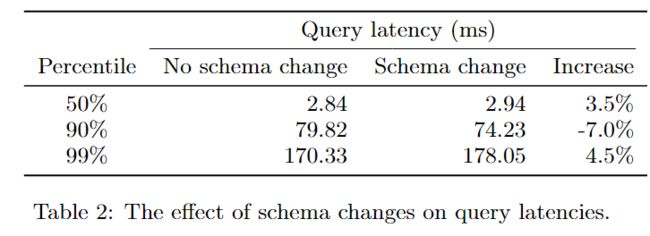
F1中的模式更改通常涉及数据重组,这将执行全局数据库更新。在F1中实现模式更改的设计目标之一是尽量减少这种重组对用户操作响应时间的影响。生产系统由大约1500台F1服务器组成,均匀分布在五个数据中心。日志包含19个模式更改的记录,这些更改的时间跨度大约为10周。
在此期间,在没有进行模式更改的情况下,发生了超过10亿次用户操作,在模式更改期间发生了超过5000万次操作。这些操作包括大约75%的查询和25%的写(插入、删除和更新)。模式更改之外和期间的查询和写延迟分别如下:

6. RELATED WORK
事务最多可以同时使用两个模式版本。但是,对数据库快照的只读查询使用快照的模式版本。
我们的协议是针对每个操作而不是每个事务的,并且我们将索引的中间状态一般化为只写状态。
分布式系统中的模式演变主要集中在数据仓库和联邦系统上,我们的工作解决了当一个模式的多个版本被用来解释和修改一组公共数据时出现的问题最后,Spanner还支持模式更改[5]。然而,它们的实现依赖于通过同步时钟和全局成员信息执行同步更改的能力。
7. CONCLUSION
我们研究了F1中的模式演变,F1是一个建立在分布式键值存储之上的分布式关系数据库。我们的方法允许用户在不丢失可用性、全局同步和数据损坏风险的情况下更改模式。我们在生产服务器中实现了我们的协议,并且我们已经在持续使用的关键系统中成功地执行了数百个模式更改。