Verilog 学习笔记
Verilog HDL的基本语法
模块
• Verilog HDL程序是由模块构成的。每个模块的内容都是嵌在module和endmodule两个语句之间。每个模块实现特定的功能。模块是可以进行层次嵌套的。正因为如此,才可以将大型的数字电路设计分割成不同的小模块来实现特定的功能,最后通过顶层模块调用子模块来实现整体功能。
• 每个模块要进行端口定义,并说明输入输出口,然后对模块的功能进行行为逻辑描述。
• Verilog HDL程序的书写格式自由,一行可以写几个语句,一个语句也可以分写多行。
• 除了endmodule语句外,每个语句和数据定义的最后必须有分号。
• 可以用/*.....*/和//.......对Verilog HDL程序的任何部分作注释。一个好的,有使用价值的源程序都应当加上必要的注释,以增强程序的可读性和可维护性。
每个Verilog程序包括四个主要部分:端口定义、I/O说明、内部信号声明、功能定义
模块内容,模块的内容包括I/O说明、内部信号声明、功能定义。
I/O说明的格式如下:
输入口: input 端口名1,端口名2,………,端口名i; //(共有i个输入口)
输出口: output 端口名1,端口名2,………,端口名j; //(共有j个输出口)I/O说明也可以写在端口声明语句里。其格式如下:
module module_name(input port1,input port2,… output port1,output port2… );内部信号说明:在模块内用到的和与端口有关的wire 和 reg 变量的声明。
如:
reg [width-1 : 0] R变量1,R变量2 。。。。;
wire [width-1 : 0] W变量1,W变量2 。。。。;
………..功能定义: 模块中最重要的部分是逻辑功能定义部分。有三种方法可在模块中产生逻辑。
1).用assign声明语句
assign a = b & c;这种方法的句法很简单,只需写一个assign,后面再加一个方程式即可。例子中的方程式描述了一个有两个输入的与门。
2).用实例元件
and and_inst( q, a, b );采用实例元件的方法象在电路图输入方式下,调入库元件一样。键入元件的名字和相连的引脚即可,表示在设计中用到一个跟与门(and)一样的名为and_inst的与门,其输入端为a, b,输出为q。要求每个实例元件的名字必须是唯一的,以避免与其他调用与门(and)的实例混淆。
3).用“always”块
always @(posedge clk or posedge clr)
begin
if(clr) q <= 0;
else if(en) q <= d;
end采用“assign”语句是描述组合逻辑最常用的方法之一。而“always”块既可用于描述组合逻辑也可描述时序逻辑。上面的例子用“always”块生成了一个带有异步清除端的D触发器。“always”块可用很多种描述手段来表达逻辑,例如上例中就用了if...else语句来表达逻辑关系。如按一定的风格来编写“always”块,可以通过综合工具把源代码自动综合成用门级结构表示的组合或时序逻辑电路。
X and Z
在数字电路中,x代表不定值,z代表高阻值。一个x可以用来定义十六进制数的四位二进制数的状态,八进制数的三位,二进制数的一位。z的表示方式同x类似。z还有一种表达方式是可以写作?。在使用case表达式时建议使用这种写法,以提高程序的可读性。见下例:
4'b10x0 //位宽为4的二进制数从低位数起第二位为不定值
4'b101z //位宽为4的二进制数从低位数起第一位为高阻值
12'dz //位宽为12的十进制数其值为高阻值(第一种表达方式)
12'd? //位宽为12的十进制数其值为高阻值(第二种表达方式)
8'h4x //位宽为8的十六进制数其低四位值为不定值负数
一个数字可以被定义为负数,只需在位宽表达式前加一个减号,减号必须写在数字定义表达式的最前面。注意减号不可以放在位宽和进制之间也不可以放在进制和具体的数之间。见下例:
-8'd5 //这个表达式代表5的补数(用八位二进制数表示)
8'd-5 //非法格式parameter
来定义常量,即用parameter来定义一个标识符代表一个常量,称为符号常量。 参数型常数经常用于定义延迟时间和变量宽度。在模块或实例引用时可通过参数传递改变在被引用模块或实例中已定义的参数。下面将通过两个例子进一步说明在层次调用的电路中改变参数常用的一些用法。
在引用Decode实例时,D1,D2的Width将采用不同的值4和5,且D1的Polarity将为0。可用例子中所用的方法来改变参数,即用 #(4,0)向D1中传递 Width=4,Polarity=0; 用#(5)向D2中传递Width=5,Polarity仍为1。
module Decode(A,F);
parameter Width=1, Polarity=1;
……………
endmodule
module Top;
wire[3:0] A4;
wire[4:0] A5;
wire[15:0] F16;
wire[31:0] F32;
Decode #(4,0) D1(A4,F16);
Decode #(5) D2(A5,F32);
Endmodule量
网络数据类型表示结构实体(例如门)之间的物理连接。网络类型的变量不能储存值,而且它必需受到驱动器(例如门或连续赋值语句,assign)的驱动。如果没有驱动器连接到网络类型的变量上,则该变量就是高阻的,即其值为z。常用的网络数据类型包括wire型和tri型。这两种变量都是用于连接器件单元,它们具有相同的语法格式和功能。之所以提供这两种名字来表达相同的概念是为了与模型中所使用的变量的实际情况相一致。wire型变量通常是用来表示单个门驱动或连续赋值语句驱动的网络型数据,tri型变量则用来表示多驱动器驱动的网络型数据。如果wire型或tri型变量没有定义逻辑强度(logic strength),在多驱动源的情况下,逻辑值会发生冲突从而产生不确定值。下表为wire型和tri型变量的真值表(注意:这里假设两个驱动源的强度是一致的)。
| wire/tri |
0 |
1 |
x |
z |
| 0 |
0 |
x |
x |
0 |
| 1 |
x |
1 |
x |
1 |
| x |
x |
x |
x |
x |
| z |
0 |
1 |
x |
z |
wire
wire型数据常用来表示用于以assign关键字指定的组合逻辑信号。Verilog程序模块中输入输出信号类型缺省时自动定义为wire型。wire型信号可以用作任何方程式的输入,也可以用作“assign”语句或实例元件的输出。
wire型信号的格式同reg型信号的很类似。其格式如下:
wire [n-1:0] 数据名1,数据名2,…数据名i; //共有i条总线,每条总线内有n条线路或
wire [n:1] 数据名1,数据名2,…数据名i;reg
寄存器是数据储存单元的抽象。寄存器数据类型的关键字是reg.通过赋值语句可以改变寄存器储存的值,其作用与改变触发器储存的值相当。Verilog HDL语言提供了功能强大的结构语句使设计者能有效地控制是否执行这些赋值语句。这些控制结构用来描述硬件触发条件,例如时钟的上升沿和多路器的选通信号。在行为模块介绍这一节中我们还要详细地介绍这些控制结构。reg类型数据的缺省初始值为不定值,x。
reg型数据常用来表示用于“always”模块内的指定信号,常代表触发器。通常,在设计中要由“always”块通过使用行为描述语句来表达逻辑关系。在“always”块内被赋值的每一个信号都必须定义成reg型。
reg型数据的格式如下:
reg [n-1:0] 数据名1,数据名2,… 数据名i;或
reg [n:1] 数据名1,数据名2,… 数据名i;对于reg型数据,其赋值语句的作用就象改变一组触发器的存储单元的值。在Verilog中有许多构造(construct)用来控制何时或是否执行这些赋值语句。这些控制构造可用来描述硬件触发器的各种具体情况,如触发条件用时钟的上升沿等,或用来描述具体判断逻辑的细节,如各种多路选择器。reg型数据的缺省初始值是不定值。reg型数据可以赋正值,也可以赋负值。但当一个reg型数据是一个表达式中的操作数时,它的值被当作是无符号值,即正值。例如:当一个四位的寄存器用作表达式中的操作数时,如果开始寄存器被赋以值-1,则在表达式中进行运算时,其值被认为是+15。
reg型只表示被定义的信号将用在“always”块内,理解这一点很重要。并不是说reg型信号一定是寄存器或触发器的输出。虽然reg型信号常常是寄存器或触发器的输出,但并不一定总是这样。
memory
Verilog HDL通过对reg型变量建立数组来对存储器建模,可以描述RAM型存储器,ROM存储器和reg文件。数组中的每一个单元通过一个数组索引进行寻址。在Verilog语言中没有多维数组存在。 memory型数据是通过扩展reg型数据的地址范围来生成的。其格式如下:
reg [n-1:0] 存储器名[m-1:0];或
reg [n-1:0] 存储器名[m:1];这个例子定义了一个名为mema的存储器,该存储器有256个8位的存储器。该存储器的地址范围是0到255。注意:对存储器进行地址索引的表达式必须是常数表达式。
另外,在同一个数据类型声明语句里,可以同时定义存储器型数据和reg型数据。见下例:
parameter wordsize=16, //定义二个参数。
memsize=256;
reg [wordsize-1:0] mem[memsize-1:0],writereg, readreg;尽管memory型数据和reg型数据的定义格式很相似,但要注意其不同之处。如一个由n个1位寄存器构成的存储.
运算符及表达式
等式运算符
1) == (等于)
2) != (不等于)
3) === (等于)
4) !== (不等于)这四个运算符都是二目运算符,它要求有两个操作数。"=="和"!="又称为逻辑等式运算符。其结果由两个操作数的值决定。由于操作数中某些位可能是不定值x和高阻值z,结果可能为不定值x。而"==="和"!=="运算符则不同,它在对操作数进行比较时对某些位的不定值x和高阻值z也进行比较,两个操作数必需完全一致,其结果才是1,否则为0。"==="和"!=="运算符常用于case表达式的判别,所以又称为"case等式运算符"。
位拼接运算符(Concatation)
在Verilog HDL语言有一个特殊的运算符:位拼接运算符{}。用这个运算符可以把两个或多个信号的某些位拼接起来进行运算操作。其使用方法如下:
{信号1的某几位,信号2的某几位,..,..,信号n的某几位}即把某些信号的某些位详细地列出来,中间用逗号分开,最后用大括号括起来表示一个整体信号。见下例:
{a,b[3:0],w,3’b101}也可以写成为
{a,b[3],b[2],b[1],b[0],w,1’b1,1’b0,1’b1}在位拼接表达式中不允许存在没有指明位数的信号。这是因为在计算拼接信号的位宽的大小时必需知道其中每个信号的位宽。
位拼接还可以用重复法来简化表达式。见下例:
{4{w}} //这等同于{w,w,w,w}位拼接还可以用嵌套的方式来表达。见下例:
{b,{3{a,b}}} //这等同于{b,a,b,a,b,a,b}用于表示重复的表达式如上例中的4和3,必须是常数表达式。
缩减运算符(reduction operator)
缩减运算符是单目运算符,也有与或非运算。其与或非运算规则类似于位运算符的与或非运算规则,但其运算过程不同。位运算是对操作数的相应位进行与或非运算,操作数是几位数则运算结果也是几位数。而缩减运算则不同,缩减运算是对单个操作数进行或与非递推运算,最后的运算结果是一位的二进制数。缩减运算的具体运算过程是这样的:第一步先将操作数的第一位与第二位进行或与非运算,第二步将运算结果与第三位进行或与非运算,依次类推,直至最后一位。
reg [3:0] B;
reg C;
C = &B;相当于:
C =( (B[0]&B[1]) & B[2] ) & B[3];由于缩减运算的与、或、非运算规则类似于位运算符与、或、非运算规则,这里不再详细讲述,请参照位运算符的运算规则介绍。
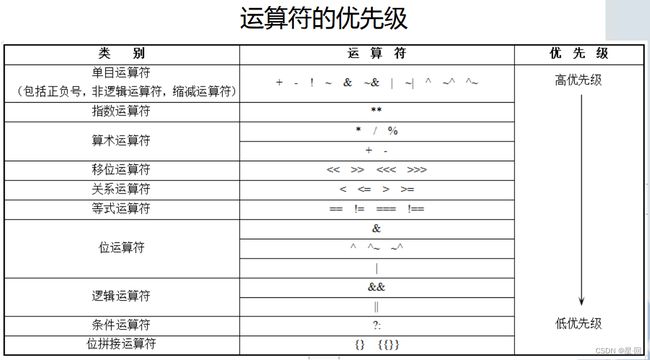
优先级别
关键词
always, and, assign,begin,buf,bufif0,bufif1,case,casex,casez,cmos,deassign,default,defparam,disable,edge,else,end,endcase,endmodule,endfunction,endprimitive, endspecify, endtable, endtask, event, for, force, forever, fork, function,highz0, highz1, if,initial, inout, input,integer,join,large,macromodule,medium,module,nand,negedge,nmos,nor,not,notif0,notifl, or, output, parameter, pmos, posedge, primitive, pull0, pull1, pullup, pulldown, rcmos, reg, releses, repeat, mmos, rpmos, rtran, rtranif0,rtranif1,scalared,small,specify,specparam,strength,strong0, strong1, supply0, supply1, table, task, time, tran, tranif0, tranif1, tri, tri0, tri1, triand, trior, trireg,vectored,wait,wand,weak0,weak1,while, wire,wor, xnor, xor
赋值语句和块语句
信号有两种赋值方式:
(1).非阻塞(Non_Blocking)赋值方式( 如 b <= a; )
1) 块结束后才完成赋值操作。
2) b的值并不是立刻就改变的。
3) 这是一种比较常用的赋值方法。(特别在编写可综合模块时)
(2).阻塞(Blocking)赋值方式( 如 b = a; )
1) 赋值语句执行完后,块才结束。
2) b的值在赋值语句执行完后立刻就改变的。
3) 可能会产生意想不到的结果。
块语句
块语句通常用来将两条或多条语句组合在一起,使其在格式上看更象一条语句。块语句有两种,一种是begin_end语句,通常用来标识顺序执行的语句,用它来标识的块称为顺序块。一种是fork_join语句,通常用来标识并行执行的语句,用它来标识的块称为并行块。下面进行详细的介绍。
一.顺序块
顺序块有以下特点:
1) 块内的语句是按顺序执行的,即只有上面一条语句执行完后下面的语句才能执行。
2) 每条语句的延迟时间是相对于前一条语句的仿真时间而言的。
3) 直到最后一条语句执行完,程序流程控制才跳出该语句块。
顺序块的格式如下:
begin
语句1;
语句2;
......
语句n;
end
或
begin:块名块内声明语句
语句1;
语句2;
......
语句n;
end其中:
- 块名即该块的名字,一个标识名。其作用后面再详细介绍。
- 块内声明语句可以是参数声明语句、reg型变量声明语句、integer型变量声明语句、real型变量声明语句。
下面举例说明:
begin
areg = breg;
creg = areg; //creg的值为breg的值。
end[例]:这个例子中用顺序块和延迟控制组合来产生一个时序波形。
parameter d=50; //声明d是一个参数
reg [7:0] r; //声明r是一个8位的寄存器变量
begin //由一系列延迟产生的波形
#d r = 'h35;
#d r = 'hE2;
#d r = 'h00;
#d r = 'hF7;
#d -> end_wave; //触发事件end_wave
end并行块 fork join
并行块有以下四个特点:
1) 块内语句是同时执行的,即程序流程控制一进入到该并行块,块内语句则开始同时并行地执行。
2) 块内每条语句的延迟时间是相对于程序流程控制进入到块内时的仿真时间的。
3) 延迟时间是用来给赋值语句提供执行时序的。
4) 当按时间时序排序在最后的语句执行完后或一个disable语句执行时,程序流程控制跳出该程序块。
并行块的格式如下:
fork
语句1;
语句2;
.......
语句n;
join
或
fork:块名
块内声明语句
语句1;
语句2;
......
语句n;
join其中:
• 块名即标识该块的一个名字,相当于一个标识符。
• 块内说明语句可以是参数说明语句、reg型变量声明语句、integer型变量声明语句、
real型变量声明语句、time型变量声明语句、事件(event)说明语句。
fork
#50 r = 'h35;
#100 r = 'hE2;
#150 r = 'h00;
#200 r = 'hF7;
#250 -> end_wave; //触发事件end_wave.
join在这个例子中用并行块来替代了前面例子中的顺序块来产生波形,用这两种方法生成的波形是一样的。
在fork_join块内,各条语句不必按顺序给出,因此在并行块里,各条语句在前还是在后是无关紧要的。
块名
在VerilgHDL语言中,可以给每个块取一个名字,只需将名字加在关键词begin或fork后面即可。这样做的原因有以下几点。
1) 这样可以在块内定义局部变量,即只在块内使用的变量。
2) 这样可以允许块被其它语句调用,如被disable语句。
3) 在Verilog语言里,所有的变量都是静态的,即所有的变量都只有一个唯一的存储地址,因此进入或跳出块并不影响存储在变量内的值。
基于以上原因,块名就提供了一个在任何仿真时刻确认变量值的方法。
起始时间和结束时间
在并行块和顺序块中都有一个起始时间和结束时间的概念。对于顺序块,起始时间就是第一条语句开始被执行的时间,结束时间就是最后一条语句执行完的时间。而对于并行块来说,起始时间对于块内所有的语句是相同的,即程序流程控制进入该块的时间,其结束时间是按时间排序在最后的语句执行完的时间。
当一个块嵌入另一个块时,块的起始时间和结束时间是很重要的。至于跟在块后面的语句只有在该块的结束时间到了才能开始执行,也就是说,只有该块完全执行完后,后面的语句才可以执行。
在fork_join块内,各条语句不必按顺序给出,因此在并行块里,各条语句在前还是在后是无关紧要的。见下例:
[例]:
fork
#250 -> end_wave;
#200 r = 'hF7;
#150 r = 'h00;
#100 r = 'hE2;
#50 r = 'h35;
join在这个例子中,各条语句并不是按被执行的先后顺序给出的,但同样可以生成前面例子中的波形。
条件语句
if_else语句
if语句是用来判定所给定的条件是否满足,根据判定的结果(真或假)决定执行给出的两种操作之一。Verilog HDL语言提供了三种形式的if语句。
五点说明:
(1).三种形式的if语句中在if后面都有“表达式”,一般为逻辑表达式或关系表达式。系统对表达式的值进行判断,若为0,x,z,按“假”处理,若为1,按“真”处理,执行指定的语句。
(2) .第二、第三种形式的if语句中,在每个else前面有一分号,整个语句结束处有一分号。
(3).在if和else后面可以包含一个内嵌的操作语句(如上例),也可以有多个操作语句,此时用begin和end这两个关键词将几个语句包含起来成为一个复合块语句。
(4).允许一定形式的表达式简写方式。如下面的例子:
if(expression) 等同与 if( expression == 1 )
if(!expression) 等同与 if( expression != 1 )(5).if语句的嵌套
case语句
case语句是一种多分支选择语句,Verilog语言提供的case语句直接处理多分支选择。case语句通常用于微处理器的指令译码,它的一般形式如下:
1) case(表达式)
2) casez(表达式)
3) casex(表达式)
case分支项的一般格式如下:
分支表达式: 语句
缺省项(default项): 语句说明:
a) case括弧内的表达式称为控制表达式,case分支项中的表达式称为分支表达式。控制表达式通常表示为控制信号的某些位,分支表达式则用这些控制信号的具体状态值来表示,因此分支表达式又可以称为常量表达式。
b) 当控制表达式的值与分支表达式的值相等时,就执行分支表达式后面的语句。如果所有的分支表达式的值都没有与控制表达式的值相匹配的,就执行default后面的语句。
c) default项可有可无,一个case语句里只准有一个default项。
下面是一个简单的使用case语句的例子。该例子中对寄存器rega译码以确定result的值。
reg [15:0] rega;
reg [9:0] result;
case(rega)
16 'd0: result = 10 'b0111111111;
16 'd1: result = 10 'b1011111111;
16 'd2: result = 10 'b1101111111;
16 'd3: result = 10 'b1110111111;
16 'd4: result = 10 'b1111011111;
16 'd5: result = 10 'b1111101111;
16 'd6: result = 10 'b1111110111;
16 'd7: result = 10 'b1111111011;
16 'd8: result = 10 'b1111111101;
16 'd9: result = 10 'b1111111110;
default: result = 'bx;
endcased) 每一个case分项的分支表达式的值必须互不相同,否则就会出现矛盾现象(对表达式的同一个值,有多种执行方案)。
e) 执行完case分项后的语句,则跳出该case语句结构,终止case语句的执行。
f) 在用case语句表达式进行比较的过程中,只有当信号的对应位的值能明确进行比较时,比较才能成功。因此要注意详细说明case分项的分支表达式的值。
g) case语句的所有表达式的值的位宽必须相等,只有这样控制表达式和分支表达式才能进行对应位的比较。一个经常犯的错误是用'bx, 'bz 来替代 n'bx, n'bz,这样写是不对的,因为信号x, z的缺省宽度是机器的字节宽度,通常是32位(此处 n 是case控制表达式的位宽)。
下面将给出 case, casez, casex 的真值表:
| case | 0 | 1 | x | z |
|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 |
| 1 | 0 | 1 | 0 | 0 |
| x | 0 | 0 | 1 | 0 |
| z | 0 | 0 | 0 | 1 |
| casex | 0 | 1 | x | z |
|---|---|---|---|---|
| 0 | 1 | 0 | 1 | 1 |
| 1 | 0 | 1 | 1 | 1 |
| x | 1 | 1 | 1 | 1 |
| z | 1 | 1 | 1 | 1 |
| casez | 0 | 1 | x | z |
|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 1 |
| 1 | 0 | 1 | 0 | 1 |
| x | 0 | 0 | 1 | 1 |
| z | 1 | 1 | 1 | 1 |
由于使用条件语句不当在设计中生成了原本没想到有的锁存器
Verilog HDL设计中容易犯的一个通病是由于不正确使用语言,生成了并不想要的锁存器。下面我们给出了一个在“always"块中不正确使用if语句,造成这种错误的例子。
检查一下左边的"always"块,if语句保证了只有当al=1时,q才取d的值。这段程序没有写出 al = 0 时的结果, 那么当al=0时会怎么样呢?
在"always"块内,如果在给定的条件下变量没有赋值,这个变量将保持原值,也就是说会生成一个锁存器! 如果设计人员希望当 al = 0 时q的值为0,else项就必不可少了,请注意看右边的"always"块,整个Verilog程序模块综合出来后,"always"块对应的部分不会生成锁存器。
Verilog HDL程序另一种偶然生成锁存器是在使用case语句时缺少default项的情况下发生的。
case语句的功能是:在某个信号(本例中的sel)取不同的值时,给另一个信号(本例中的q)赋不同的值。注意看下图左边的例子,如果sel=0,q取a值,而sel=11,q取b的值。这个例子中不清楚的是:如果sel取00和11以外的值时q将被赋予什么值?在下面左边的这个例子中,程序是用Verilog HDL写的,即默认为q保持原值,这就会自动生成锁存器。
右边的例子很明确,程序中的case语句有default项,指明了如果sel不取00或11时,编译器或仿真器应赋给q的值。程序所示情况下,q赋为0,因此不需要锁存器。
以上就是怎样来避免偶然生成锁存器的错误。如果用到if语句,最好写上else项。如果用case语句,最好写上default项。遵循上面两条原则,就可以避免发生这种错误,使设计者更加明确设计目标,同时也增强了Verilog程序的可读性。
循环语句
在Verilog HDL中存在着四种类型的循环语句,用来控制执行语句的执行次数。
1) forever 连续的执行语句。
2) repeat 连续执行一条语句 n 次。
3) while 执行一条语句直到某个条件不满足。如果一开始条件即不满足(为假), 则语句一次也不能被执行。
4) for通过以下三个步骤来决定语句的循环执行。
a) 先给控制循环次数的变量赋初值。
b) 判定控制循环的表达式的值,如为假则跳出循环语句,如为真则执行指定的语句后,转到第三步。
c) 执行一条赋值语句来修正控制循环变量次数的变量的值,然后返回第二步。
forever语句
forever 语句; 或
forever begin 多条语句 end
forever循环语句常用于产生周期性的波形,用来作为仿真测试信号。它与always语句不同处在于不能独立写在程序中,而必须写在initial块中。其具体使用方法将在"事件控制"这一小节里详细地加以说明。
repeat语句
repeat语句的格式如下:
repeat(表达式) 语句; 或
repeat(表达式) begin 多条语句 end
在repeat语句中,其表达式通常为常量表达式。
while语句
while语句的格式如下:
while(表达式) 语句
或用如下格式:
while(表达式) begin 多条语句 end
for语句
for语句的一般形式为:
for(表达式1;表达式2;表达式3) 语句
它的执行过程如下:
1) 先求解表达式1;
2) 求解表达式2,若其值为真(非0),则执行for语句中指定的内嵌语句,然后执行下面的第3步。若为假(0),则结束循环,转到第5步。
3) 若表达式为真,在执行指定的语句后,求解表达式3。
4) 转回上面的第2步骤继续执行。
5) 执行for语句下面的语句。
结构说明语句
Verilog语言中的任何过程模块都从属于以下四种结构的说明语句。
1) initial说明语句
2) always说明语句
3) task说明语句
4) function说明语句
initial和always说明语句在仿真的一开始即开始执行。initial语句只执行一次。相反,always语句则是不断地重复执行,直到仿真过程结束。在一个模块中,使用initial和always语句的次数是不受限制的。task和function语句可以在程序模块中的一处或多处调用。
一个模块中可以有多个initial块,它们都是并行运行的。initial块常用于测试文件和虚拟模块的编写,用来产生仿真测试信号和设置信号记录等仿真环境。
always语句由于其不断重复执行的特性,只有和一定的时序控制结合在一起才有用。如果一个always语句没有时序控制,则这个always语句将会发成一个仿真死锁。
沿触发的always块常常描述时序逻辑,如果符合可综合风格要求可用综合工具自动转换为表示时序逻辑的寄存器组和门级逻辑,而电平触发的always块常常用来描述组合逻辑和带锁存器的组合逻辑,如果符合可综合风格要求可转换为表示组合逻辑的门级逻辑或带锁存器的组合逻辑。一个模块中可以有多个always块,它们都是并行运行的。
task和function说明语句分别用来定义任务和函数。利用任务和函数可以把一个很大的程序模块分解成许多较小的任务和函数便于理解和调试。输入、输出和总线信号的值可以传入、传出任务和函数。任务和函数往往还是大的程序模块中在不同地点多次用到的相同的程序段。学会使用task和function语句可以简化程序的结构,使程序明白易懂,是编写较大型模块的基本功。
一. task和function说明语句的不同点
任务和函数有些不同,主要的不同有以下四点:
1) 函数只能与主模块共用同一个仿真时间单位,而任务可以定义自己的仿真时间单位。
2) 函数不能启动任务,而任务能启动其它任务和函数。
3) 函数至少要有一个输入变量,而任务可以没有或有多个任何类型的变量。
4) 函数返回一个值,而任务则不返回值。
函数的目的是通过返回一个值来响应输入信号的值。任务却能支持多种目的,能计算多个结果值,这些结果值只能通过被调用的任务的输出或总线端口送出。Verilog HDL模块使用函数时是把它当作表达式中的操作符,这个操作的结果值就是这个函数的返回值。
task说明语句
如果传给任务的变量值和任务完成后接收结果的变量已定义,就可以用一条语句启动任务。任务完成以后控制就传回启动过程。如任务内部有定时控制,则启动的时间可以与控制返回的时间不同。任务可以启动其它的任务,其它任务又可以启动别的任务,可以启动的任务数是没有限制的。不管有多少任务启动,只有当所有的启动任务完成以后,控制才能返回。
1) 任务的定义
定义任务的语法如下:
任务:
task <任务名>;
<端口及数据类型声明语句>
<语句1>
<语句2>
.....
<语句n>
endtask这些声明语句的语法与模块定义中的对应声明语句的语法是一致的。
2) 任务的调用及变量的传递
启动任务并传递输入输出变量的声明语句的语法如下:
任务的调用:
<任务名>(端口1,端口2,...,端口n);
下面的例子说明怎样定义任务和调用任务:
task my_task;
input a, b;
inout c;
output d, e;
…<语句> //执行任务工作相应的语句
…
c = foo1; //赋初始值
d = foo2; //对任务的输出变量赋值t
e = foo3;
endtask任务调用:
my_task(v,w,x,y,z);任务调用变量(v,w,x,y,z)和任务定义的I/O变量(a,b,c,d,e)之间是一一对应的。当任务启动时,由v,w,和x.传入的变量赋给了a,b,和c,而当任务完成后的输出又通过c,d和e赋给了x,y和z。
function说明语句
函数的目的是返回一个用于表达式的值。
定义函数的语法:
function <返回值的类型或范围> (函数名);
<端口说明语句>
<变量类型说明语句>
begin
<语句>
........
end
endfunction请注意<返回值的类型或范围>这一项是可选项,如缺省则返回值为一位寄存器类型数据。下面用例子说明:
function [7:0] getbyte;
input [15:0] address;
begin
<说明语句> //从地址字中提取低字节的程序
getbyte = result_expression; //把结果赋予函数的返回字节
end
endfunction从函数返回的值
函数的定义蕴含声明了与函数同名的、函数内部的寄存器。如在函数的声明语句中<返回值的类型或范围>为缺省,则这个寄存器是一位的,否则是与函数定义中<返回值的类型或范围>一致的寄存器。函数的定义把函数返回值所赋值寄存器的名称初始化为与函数同名的内部变量。下面的例子说明了这个概念:getbyte被赋予的值就是函数的返回值。
函数的调用
函数的调用是通过将函数作为表达式中的操作数来实现的。
其调用格式如下:
<函数名> (<表达式><,<表达式>>*)其中函数名作为确认符。下面的例子中通过对两次调用函数getbyte的结果值进行位拼接运算来生成一个字。
word = control? {getbyte(msbyte),getbyte(lsbyte)} : 0;函数的使用规则
与任务相比较函数的使用有较多的约束,下面给出的是函数的使用规则:
1) 函数的定义不能包含有任何的时间控制语句,即任何用#、@、或wait来标识的语句。
2) 函数不能启动任务。
3) 定义函数时至少要有一个输入参量。
4) 在函数的定义中必须有一条赋值语句给函数中的一个内部变量赋以函数的结果值,该内部变量具有和函数名相同的名字。
系统函数和任务
Verilog HDL语言中共有以下一些系统函数和任务:
$bitstoreal, $rtoi, $display, $setup, $finish, $skew, $hold, $setuphold, $itor, $strobe, $period, $time, $printtimescale, $timefoemat, $realtime, $width, $real tobits, $write, $recovery,
$display和$write任务
格式:
$display(p1,p2,....pn);这两个函数和系统任务的作用是用来输出信息,即将参数p2到pn按参数p1给定的格式输出。参数p1通常称为格式控制,参数p2至pn通常称为输出表列。这两个任务的作用基本相同。$display自动地在输出后进行换行,$write则不是这样。如果想在一行里输出多个信息,可以使用$write。在$display和$write中,其输出格式控制是用双引号括起来的字符串,它包括两种信息:
格式说明,由"%"和格式字符组成。它的作用是将输出的数据转换成指定的格式输出。格式说明总是由%字符开始的。对于不同类型的数据用不同的格式输出。表一中给出了常用的几种输出格式。
普通字符,即需要原样输出的字符。其中一些特殊的字符可以通过表二中的转换序列来输出。下面表中的字符形式用于格式字符串参数中,用来显示特殊的字符。
如果输出列表中表达式的值包含有不确定的值或高阻值,其结果输出遵循以下规则:
(1).在输出格式为十进制的情况下:
• 如果表达式值的所有位均为不定值,则输出结果为小写的x。
• 如果表达式值的所有位均为高阻值,则输出结果为小写的z。
• 如果表达式值的部分位为不定值,则输出结果为大写的X。
• 如果表达式值的部分位为高阻值,则输出结果为大写的Z。
(2).在输出格式为十六进制和八进制的情况下:
• 每4位二进制数为一组代表一位十六进制数,每3位二进制数为一组代表一位八进制数。
• 如果表达式值相对应的某进制数的所有位均为不定值,则该位进制数的输出的结果为小写的x。
• 如果表达式值相对应的某进制数的所有位均为高阻值,则该位进制数的输出结果为小写的z。
• 如果表达式值相对应的某进制数的部分位为不定值,则该位进制数输出结果为大写的X。
• 如果表达式值相对应的某进制数的部分位为高阻值,则该位进制数输出结果为大写的Z。
对于二进制输出格式,表达式值的每一位的输出结果为0、1、x、z。下面举例说明:
语句输出结果:
$display("%d", 1'bx); 输出结果为:x
$display("%h", 14'bx0_1010); 输出结果为:xxXa
$display("%h %o",12'b001x_xx10_1x01,12'b001_xxx_101_x01); 输出结果为:XXX 1x5X注意:因为$write在输出时不换行,要注意它的使用。可以在$write中加入换行符\n,以确保明确的输出显示格式。
系统任务$monitor
格式:
$monitor(p1,p2,.....,pn);
$monitor;
$monitoron;
$monitoroff;任务$monitor提供了监控和输出参数列表中的表达式或变量值的功能。其参数列表中输出控制格式字符串和输出表列的规则和$display中的一样。当启动一个带有一个或多个参数的$monitor任务时,仿真器则建立一个处理机制,使得每当参数列表中变量或表达式的值发生变化时,整个参数列表中变量或表达式的值都将输出显示。如果同一时刻,两个或多个参数的值发生变化,则在该时刻只输出显示一次。但在$monitor中,参数可以是$time系统函数。这样参数列表中变量或表达式的值同时发生变化的时刻可以通过标明同一时刻的多行输出来显示。如:
$monitor($time,,"rxd=%b txd=%b",rxd,txd);在$display中也可以这样使用。注意在上面的语句中,“,,"代表一个空参数。空参数在输出时显示为空格。
$monitoron和$monitoroff任务的作用是通过打开和关闭监控标志来控制监控任务$monitor的启动和停止,这样使得程序员可以很容易的控制$monitor何时发生。
通常在通过调用$monitoron启动$monitor时,不管$monitor参数列表中的值是否发生变化,总是立刻输出显示当前时刻参数列表中的值,这用于在监控的初始时刻设定初始比较值。在缺省情况下,控制标志在仿真的起始时刻就已经打开了。在多模块调试的情况下,许多模块中都调用了$monitor,因为任何时刻只能有一个$monitor起作用,因此需配合$monitoron与$monitoroff使用,把需要监视的模块用$monitoron打开,在监视完毕后及时用$monitoroff关闭,以便把$monitor 让给其他模块使用。$monitor与$display的不同处还在于$monitor往往在initial块中调用,只要不调用$monitoroff,$monitor便不间断地对所设定的信号进行监视。
时间度量系统函数$time
在Verilog HDL中有两种类型的时间系统函数:$time和$realtime。用这两个时间系统函数可以得到当前的仿真时刻。
$time可以返回一个64比特的整数来表示的当前仿真时刻值。该时刻是以模块的仿真时间尺度为基准的。下面举例说明。
[例]:
`timescale 10ns/1ns
module test;
reg set;
parameter p=1.6;
initial
begin
$monitor($time,,"set=",set);
#p set=0;
#p set=1;
end
endmodule
输出结果为:
0 set=x
2 set=0
3 set=1在这个例子中,模块test想在时刻为16ns时设置寄存器set为0,在时刻为32ns时设置寄存器set为1。但是由$time记录的set变化时刻却和预想的不一样。这是由下面两个原因引起的:
1) $time显示时刻受时间尺度比例的影响。在上面的例子中,时间尺度是10ns,因为$time输出的时刻总是时间尺度的倍数,这样将16ns和32ns输出为1.6和3.2。
2) 因为$time总是输出整数,所以在将经过尺度比例变换的数字输出时,要先进行取整。在上面的例子中,1.6和3.2经取整后为2和3输出。注意:时间的精确度并不影响数字的取整。
$realtime系统函数
$realtime和$time的作用是一样的,只是$realtime返回的时间数字是一个实型数,该数字也是以时间尺度为基准的。下面举例说明:
[例]:
`timescale10ns/1ns
module test;
reg set;
parameter p=1.55;
initial
begin
$monitor($realtime,,"set=",set);
#p set=0;
#p set=1;
end
endmodule输出结果为:
0 set=x
1.6 set=0
3.2 set=1系统任务$finish
格式:
$finish;
$finish(n);系统任务$finish的作用是退出仿真器,返回主操作系统,也就是结束仿真过程。任务$finish可以带参数,根据参数的值输出不同的特征信息。如果不带参数,默认$finish的参数值为1。下面给出了对于不同的参数值,系统输出的特征信息:
0 不输出任何信息
1 输出当前仿真时刻和位置
2 输出当前仿真时刻,位置和在仿真过程中 所用memory及CPU时间的统计
系统任务$stop
格式:
$stop;
$stop(n);$stop任务的作用是把EDA工具(例如仿真器)置成暂停模式,在仿真环境下给出一个交互式的命令提示符,将控制权交给用户。这个任务可以带有参数表达式。根据参数值(0,1或2)的不同,输出不同的信息。参数值越大,输出的信息越多。
系统任务$readmemb和$readmemh
在Verilog HDL程序中有两个系统任务$readmemb和$readmemh用来从文件中读取数据到存贮器中。这两个系统任务可以在仿真的任何时刻被执行使用,其使用格式共有以下六种:
1) $readmemb("<数据文件名>",<存贮器名>);
2) $readmemb("<数据文件名>",<存贮器名>,<起始地址>);
3) $readmemb("<数据文件名>",<存贮器名>,<起始地址>,<结束地址>);
4) $readmemh("<数据文件名>",<存贮器名>);
5) $readmemh("<数据文件名>",<存贮器名>,<起始地址>);
6) $readmemh("<数据文件名>",<存贮器名>,<起始地址>,<结束地址>);在这两个系统任务中,被读取的数据文件的内容只能包含:空白位置(空格,换行,制表格(tab)和form-feeds),
注释行(//形式的和/*...*/形式的都允许),二进制或十六进制的数字。数字中不能包含位宽说明和格式说明,
对于$readmemb系统任务,每个数字必须是二进制数字,对于$readmemh系统任务,每个数字必须是十六进制数字。
数字中不定值x或X,高阻值z或Z,和下划线(_)的使用方法及代表的意义与一般Verilog HDL程序中的用法及意义是一样的。另外数字必须用空白位置或注释行来分隔开。
在下面的讨论中,地址一词指对存贮器(memory)建模的数组的寻址指针。当数据文件被读取时,每一个被读取数字都被存放到地址连续的存贮器单元中去。存贮器单元的存放地址范围由系统任务声明语句中的起始地址和结束地址来说明,每个数据的存放地址在数据文件中进行说明。当地址出现在数据文件中,其格式为字
符“@”后跟上十六进制数。 如:
@hh...h对于这个十六进制的地址数中,允许大写和小写的数字。在字符“@”和数字之间不允许存在空白位置。可以在数据文件里出现多个地址。当系统任务遇到一个地址说明时,系统任务将该地址后的数据存放到存贮器中相应的地址单元中去。
对于上面六种系统任务格式,需补充说明以下五点:
1) 如果系统任务声明语句中和数据文件里都没有进行地址说明,则缺省的存放起始地址为该存贮器定义语句中的起始地址。数据文件里的数据被连续存放到该存贮器中,直到该存贮器单元存满为止或数据文件里的数据存完。
2) 如果系统任务中说明了存放的起始地址,没有说明存放的结束地址,则数据从起始地址开始存放,存放到该存贮器定义语句中的结束地址为止。
3) 如果在系统任务声明语句中,起始地址和结束地址都进行了说明,则数据文件里的数据按该起始地址开始存放到存贮器单元中,直到该结束地址,而不考虑该存贮器的定义语句中的起始地址和结束地址。
4) 如果地址信息在系统任务和数据文件里都进行了说明,那么数据文件里的地址必须在系统任务中地址参数声明的范围之内。否则将提示错误信息,并且装载数据到存贮器中的操作被中断。
5) 如果数据文件里的数据个数和系统任务中起始地址及结束地址暗示的数据个数不同的话,也要提示错误信息。
先定义一个有256个地址的字节存贮器 mem:
reg[7:0] mem[1:256];下面给出的系统任务以各自不同的方式装载数据到存贮器mem中。
initial $readmemh("mem.data",mem);
initial $readmemh("mem.data",mem,16);
initial $readmemh("mem.data",mem,128,1);第一条语句在仿真时刻为0时,将装载数据到以地址是1的存贮器单元为起始存放单元的存贮器中去。第二条语句将装载数据到以单元地址是16的存贮器单元为起始存放单元的存贮器中去,一直到地址是256的单元为止。第三条语句将从地址是128的单元开始装载数据,一直到地址为1的单元。在第三种情况中,当装载完毕,系统要检查在数据文件里是否有128个数据,如果没有,系统将提示错误信息。
系统任务 $random
这个系统函数提供了一个产生随机数的手段。当函数被调用时返回一个32bit的随机数。它是一个带符号的整形数。
$random一般的用法是:$ramdom % b ,其中 b>0.它给出了一个范围在(-b+1):(b-1)中的随机数。
reg[23:0] rand;
rand = $random % 60;上面的例子给出了一个范围在-59到59之间的随机数,
下面的例子通过位并接操作产生一个值在0到59之间的数。
reg[23:0] rand;
rand = {$random} % 60;利用这个系统函数可以产生随机脉冲序列或宽度随机的脉冲序列,以用于电路的测试。下面例子中的Verilog HDL模块可以产生宽度随机的随机脉冲序列的测试信号源,在电路模块的设计仿真时非常有用。同学们可以根据测试的需要,模仿下例,灵活使用$random系统函数编制出与实际情况类似的随机脉冲序列。
[例]
`timescale 1ns/1ns
module random_pulse( dout );
output [9:0] dout;
reg dout;
integer delay1,delay2,k;
initial
begin
#10 dout=0;
for (k=0; k< 100; k=k+1)
begin
delay1 = 20 * ( {$random} % 6);
// delay1 在0到100ns间变化
delay2 = 20 * ( 1 + {$random} % 3);
// delay2 在20到60ns间变化
#delay1 dout = 1 << ({$random} %10);
//dout的0--9位中随机出现1,并出现的时间在0-100ns间变化
#delay2 dout = 0;
//脉冲的宽度在在20到60ns间变化
end
end
endmodule编译预处理
在Verilog HDL语言中,为了和一般的语句相区别,这些预处理命令以符号“ `”开头(注意这个符号是不同于单引号“ '”的)。这些预处理命令的有效作用范围为定义命令之后到本文件结束或到其它命令定义替代该命令之处。Verilog HDL提供了以下预编译命令:
`accelerate,`autoexpand_vectornets,`celldefine,`default_nettype,`define,`else,`endcelldefine,`endif,`endprotect,`endprotected,`expand_vectornets,`ifdef,`include,`noaccelerate,`noexpand_vectornets,`noremove_gatenames,`noremove_netnames,`nounconnected_drive,`protect,`protecte,`remove_gatenames,`remove_netnames,`reset,`timescale,`unconnected_drive。
宏定义 `define
用一个指定的标识符(即名字)来代表一个字符串,它的一般形式为:
`define 标识符(宏名) 字符串(宏内容)
`define signal string它的作用是指定用标识符signal来代替string这个字符串,在编译预处理时,把程序中在该命令以后所有的signal都替换成string。这种方法使用户能以一个简单的名字代替一个长的字符串,也可以用一个有含义的名字来代替没有含义的数字和符号,因此把这个标识符(名字)称为“宏名”,在编译预处理时将宏名替换成字符串的过程称为“宏展开”。
- 在引用已定义的宏名时,必须在宏名的前面加上符号“`”,表示该名字是一个经过宏定义的名字。
- 宏定义不是Verilog HDL语句,不必在行末加分号。如果加了分号会连分号一起进行置换
- 宏名和宏内容必须在同一行中进行声明。如果在宏内容中包含有注释行,注释行不会作为被置换的内容。
文件包含”处理 `include
所谓“文件包含”处理是一个源文件可以将另外一个源文件的全部内容包含进来,即将另外的文件包含到本文件之中。Verilog HDL语言提供了`include命令用来实现“文件包含”的操作。其一般形式为:
`include “文件名”关于“文件包含”处理的四点说明:
1) 一个`include命令只能指定一个被包含的文件,如果要包含n个文件,要用n个`include命令。注意下面的写法是非法的`include"aaa.v""bbb.v"
2) `include命令可以出现在Verilog HDL源程序的任何地方,被包含文件名可以是相对路径名,也可以是绝对路径名。例如:'include"parts/count.v"
3) 可以将多个`include命令写在一行,在`include命令行,只可以出空格和注释行。例如下面的写法是合法的。
'include "fileB" 'include "fileC" //including fileB and fileC4) 如果文件1包含文件2,而文件2要用到文件3的内容,则可以在文件1用两个`include命令分别包含文件2和文件3,而且文件3应出现在文件2之前。
5) 在一个被包含文件中又可以包含另一个被包含文件,即文件包含是可以嵌套的。例如上面的问题也可以这样处理。
时间尺度 `timescale
`timescale命令用来说明跟在该命令后的模块的时间单位和时间精度。使用`timescale命令可以在同一个设计里包含采用了不同的时间单位的模块。例如,一个设计中包含了两个模块,其中一个模块的时间延迟单位为ns,另一个模块的时间延迟单位为ps。EDA工具仍然可以对这个设计进行仿真测试。 `timescale 命令的格式如下:
`timescale<时间单位>/<时间精度>在这条命令中,时间单位参量是用来定义模块中仿真时间和延迟时间的基准单位的。时间精度参量是用来声明该模块的仿真时间的精确程度的,该参量被用来对延迟时间值进行取整操作(仿真前),因此该参量又可以被称为取整精度。如果在同一个程序设计里,存在多个`timescale命令,则用最小的时间精度值来决定仿真的时间单位。另外时间精度至少要和时间单位一样精确,时间精度值不能大于时间单位值。
在`timescale命令中,用于说明时间单位和时间精度参量值的数字必须是整数,其有效数字为1、10、100,单位为秒(s)、毫秒(ms)、微秒(us)、纳秒(ns)、皮秒(ps)、毫皮秒(fs)
下面举例说明`timescale命令的用法。
`timescale 1ns/1ps在这个命令之后,模块中所有的时间值都表示是1ns的整数倍。这是因为在`timescale命令中,定义了时间单位是1ns。模块中的延迟时间可表达为带三位小数的实型数,因为 `timescale命令定义时间精度为1ps.
`timescale 10us/100ns在这个例子中,`timescale命令定义后,模块中时间值均为10us的整数倍。因为`timesacle 命令定义的时间单位是10us。延迟时间的最小分辨度为十分之一微秒(100ns),即延迟时间可表达为带一位小数的实型数。
`timescale 10ns/1ns
module test;
reg set;
parameter d=1.55;
initial
begin
#d set=0;
#d set=1;
end
endmodule在这个例子中,`timescale命令定义了模块test的时间单位为10ns、时间精度为1ns。因此在模块test中,所有的时间值应为10ns的整数倍,且以1ns为时间精度。这样经过取整操作,存在参数d中的延迟时间实际是16ns(即1.6×10ns),这意味着在仿真时刻为16ns时寄存器set被赋值0,在仿真时刻为32ns时寄存器set被赋值1。仿真时刻值是按照以下的步骤来计算的。
1) 根据时间精度,参数d值被从1.55取整为1.6。
2) 因为时间单位是10ns,时间精度是1ns,所以延迟时间#d作为时间单位的整数倍为16ns。
3) EDA工具预定在仿真时刻为16ns的时候给寄存器set赋值0 (即语句 #d set=0;执行时刻),在仿真时刻为32ns的时候给 寄存器set赋值1(即语句 #d set=1;执行时刻),
注意:如果在同一个设计里,多个模块中用到的时间单位不同,需要用到以下的时间结构。
1) 用`timescale命令来声明本模块中所用到的时间单位和时间精度。
2) 用系统任务$printtimescale来输出显示一个模块的时间单位和时间精度。
3) 用系统函数$time和$realtime及%t格式声明来输出显示EDA工具记录的时间信息。
条件编译命令`ifdef、`else、`endif
一般情况下,Verilog HDL源程序中所有的行都将参加编译。但是有时希望对其中的一部分内容只有在满足条件才进行编译,也就是对一部分内容指定编译的条件,这就是“条件编译”。有时,希望当满足条件时对一组语句进行编译,而当条件不满足是则编译另一部分。
条件编译命令有以下几种形式:
`ifdef 宏名 (标识符)
程序段1
`else
程序段2
`endif它的作用是当宏名已经被定义过(用`define命令定义),则对程序段1进行编译,程序段2将被忽略;否则编译程序段2,程序段1被忽略。其中`else部分可以没有,即:
`ifdef 宏名 (标识符)
程序段1
`endif这里的 “宏名” 是一个Verilog HDL的标识符,“程序段”可以是Verilog HDL语句组,也可以是命令行。这些命令可以出现在源程序的任何地方。注意:被忽略掉不进行编译的程序段部分也要符合Verilog HDL程序的语法规则。
通常在Verilog HDL程序中用到`ifdef、`else、`endif编译命令的情况有以下几种:
• 选择一个模块的不同代表部分。
• 选择不同的时序或结构信息。
• 对不同的EDA工具,选择不同的激励。
不同抽象级别的Verilog HDL模型
抽象的级别和它们对应的模型类型共有以下五种:
1) 系统级(system)
2) 算法级(algorithmic)
3) RTL级(RegisterTransferLevel):
4) 门级(gate-level):
5) 开关级(switch-level)
门级结构描述
与非门、或门和反向器等及其说明语法
Verilog HDL中有关门类型的关键字共有26个之多,在本教材中我们只介绍最基本的八个。下面列出了八个基本的门类型(GATETYPE)关键字和它们所表示的门的类型:
and 与门
nand 与非门
nor 或非门
or 或门
xor 异或门
xnor 异或非门
buf 缓冲器
not 非门
门与开关的说明语法可以用标准的声明语句格式和一个简单的实例引用加以说明。门声明语句的格式如下:
<门的类型>[<驱动能力><延时>]<门实例1>[,<门实例2>,…<门实例n>];
nand #10 nd1(a,data,clock,clear);这说明在模块中引用了一个名为nd1的与非门(nand),输入为data、clock和clear,输出为a,输出与输入的延时为10个单位时间。
用户定义的原语(UDP)
用户定义的原语是从英语User Defined Primitives直接翻译过来的,在Verilog HDL 中我们常用它的缩写UDP来表示。利用UDP用户可以定义自己设计的基本逻辑元件的功能,也就是说,可以利用UDP来定义有自己特色的用于仿真的基本逻辑元件模块并建立相应的原语库。这样,我们就可以与调用Verilog HDL基本逻辑元件同样的方法来调用原语库中相应的元件模块来进行仿真。由于UDP是用查表的方法来确定其输出的,用仿真器进行仿真时,对它的处理速度较对一般用户编写的模块快得多。与一般的用户模块比较,UDP更为基本,它只能描述简单的能用真值表表示的组合或时序逻辑。UDP模块的结构与一般模块类似,只是不用module而改用primitive关键词开始,不用endmodule而改用endprimitive关键词结束。在Verilog的语法中还规定了UDP的形式定义和必须遵守的几个要点,与一般模块有不同之处,我们在下面加以介绍。
定义UDP的语法:
primitive 元件名(输出端口名,输入端口名1,输入端口名2,…)
output 输出端口名;
input 输入端口名1, 输入端口名2,…;
reg 输出端口名;
initial begin
输出端口寄存器或时序逻辑内部寄存器赋初值(0,1,或 X);
end
table
//输入1 输入2 输入3 … : 输出
逻辑值 逻辑值 逻辑值 … : 逻辑值 ;
逻辑值 逻辑值 逻辑值 … : 逻辑值 ;
逻辑值 逻辑值 逻辑值 … : 逻辑值 ;
… … … … : … ;
endtable
endprimitive注意点:
1) UDP只能有一个输出端,而且必定是端口说明列表的第一项。
2) UDP可以有多个输入端,最多允许有10个输入端。
3) UDP所有端口变量必须是标量,也就是必须是1位的。
4) 在UDP的真值表项中,只允许出现0、1、X三种逻辑值,高阻值状态Z是不允许出现的。
5) 只有输出端才可以被定义为寄存器类型变量。
6) initial语句用于为时序电路内部寄存器赋初值,只允许赋0、1、X三种逻辑值,缺省值为X。
对于数字系统的设计人员来说,只要了解UDP的作用就可以了,而对微电子行业的基本逻辑元器件设计工程师,必须深入了解UDP的描述,才能把所设计的基本逻辑元件,通过EDA工具呈现给系统设计工程师。
Verilog HDL的行为描述建模
event: 它用来定义一个事件,以便在后面的操作中触发这一事件。它的触发方式是:
# time (触发的时刻〕->(事件名)DFF:表示带复位端的D触发器。是Verilog语言中保留的关键字。
大家知道RISC CPU是一个复杂的数字逻辑电路,但是它基本部件的逻辑并不复杂,我们可把它分割成九个基本部件:累加器(ACCUMULATOR)、RISC算术运算单元(RISC_ALU)、数据控制器(DATACTRL)、动态存储器(RAM)、指令寄存器(INSTRUCTION REGISTER)、状态控制器(STATE CONTROLLER)、程序计数器(PROGRAMM COUNTER)、地址多路器(ADDRMUX)和时钟发生器(CLKGEN)。用Verilog HDL把各基本部件的功能描述清楚,并把每个部件的输入输出之间的逻辑关系通过仿真加以验证,并不是很困难的一件事,然后用结构建模的方法把它们组成一个顶层模块,也就是RISC_CPU的Verilog HDL整体模型,经仿真验证各部件之间的逻辑关系后,再逐块用可综合风格的Verilog HDL语法检查并改写为可综合的Verilog HDL,或用电路图描述把它们设计出来。经综合、优化、布局、布线后再做后仿真。如果仿真结果正确,电路就设计完毕。