独家 | 2018年Analytics Vidhya上最受欢迎的15篇数据科学和机器学习文章

作者:Pranav Dar
翻译:陈之炎
校对:丁楠雅
本文约4200字,建议阅读10+分钟。
本文为你整理了多个高质量和受欢迎的数据科学培训课程、学习文章及学习指南。
简介
Analytics Vidhya是由Kunal发起的一个数据科学社区,上面有许多精彩的内容。2018年我们把社区的内容建设提升到了一个全新的水平,推出了多个高质量和受欢迎的培训课程,出版了知识丰富的机器学习和深度学习文章和指南,博客访问量每月超过250万次。
当拉上2018年的精彩帷幕之时,我们想和社区的读者来分享这一年中的精彩华文。本文也是该系列文章的一部分,希望你能喜欢。其他几篇回溯性文章见:
A Technical Overview of AI & ML (NLP, Computer Vision, Reinforcement Learning) in 2018 & Trends for 2019:
https://www.analyticsvidhya.com/blog/2018/12/key-breakthroughs-ai-ml-2018-trends-2019/
The 25 Best Data Science Projects on GitHub from 2018 that you Should Not Miss:
https://www.analyticsvidhya.com/blog/2018/12/best-data-science-machine-learning-projects-github/

在这个文集中,我总结了每一篇文章,并根据它们各自的领域进行了分类。每一篇文章还包含对内容的总结。如果你有其他你觉得特别有用的文章,请在下面的评论框中告诉我们。
现在,我们来看看2018年在Analytics Vidhya上的那些最受欢迎程的文章吧!
本文所涵盖的专题
一、机器学习与深度学习-终极二重奏
二、商业智能与数据可视化
三、数据科学方向的职业
四、自然语言处理(NLP)
五、播客
一、机器学习与深度学习-终极二重奏
1. Scratch构建推荐引擎的综合指南(用Python语言)
https://www.analyticsvidhya.com/blog/2018/06/comprehensive-guide-recommendation-engine-python/

推荐技术已经存在了几十年(不是几百年)。机器学习的兴起无疑加速了这些技术的进步,我们已经不再需要依靠直觉,手动地对行为进行监控——只要把数据和正确的技术有机结合起来,瞧!你便有了一个非常高效和划算的组合。
本文是你在这个主题中能找到的最全面的指南之一。它涵盖了各种类型的推荐引擎算法以及在Python中创建它们的基本原理。Pulkit首先解释了什么是推荐引擎,它们是如何工作的。然后用Python(使用流行的MovieLens数据集)进行了一个案例研究,并利用它解释了如何构建特定模型,他关注的两项主要技术是协同过滤和矩阵因式分解。
一旦建立好了推荐引擎,该如何评估它呢?我们怎么知道它是否按照我们的计划运作呢?Pulkit展示了六种不同的评估技术来验证我们的模型,从而解答了这个问题。
2. 24个可以提高你的知识和技能的终极数据科学项目(&可以自由访问,无需付费)
https://www.analyticsvidhya.com/blog/2018/05/24-ultimate-data-science-projects-to-boost-your-knowledge-and-skills/

这是Analytics Vidhya有史以来最受欢迎的文章之一。最初发布于2016年,我们的团队更新了来自不同行业的最新数据集。数据集被划分为三个职业级别-各个级别适合于职业生涯中的不同阶段:
初级:这个级别主要使用易用的数据集,并且不需要复杂的数据科学技术
中级:这个级别主要使用更富挑战性的数据集,它由中、大型数据集组成,要求具备一些高级的模式识别技能
高级:这个级别最适合那些了解高级主题的人,如神经网络、深度学习、推荐系统等。
蛋糕上的糖霜呢?每个项目都有一个与之相关的教程!因此,无论你是想从scratch开始学习,还是被困在某个点上,或者只是想用一个分数来评估你的结果,你都可以将它标记为书签,迅速回到该教程之中。
3. 在Scratch中用Python理解和建立目标检测模型
https://www.analyticsvidhya.com/blog/2018/06/understanding-building-object-detection-model-python/

目标检测在2018年真正开始了起飞,它可以为自动驾驶汽车安全导航,使之顺利通过交通拥堵,在人群拥挤的地方发现暴力行为,协助运动队分析和建立侦察报告,在制造过程中确保质量控制等等,这些只是目标检测技术所涉及的表面而已,它能做到的事情远不止这些。
在本文中,Faizan Shaikh首先解释了目标检测是什么,然后再深入探讨解决目标检测问题的多种不同的方法。他从非常基本的方法开始,将图像分割成不同的部分,并在每个部分上使用图像分类器。在此基础上,对每个步骤进行了改进,最终展示了如何利用深度学习来构建端到端的对象检测模型。
如果这个话题吸引到了你,并且你正在寻找一个切入点开始你的深度学习之旅,我建议你去看看“利用深度学习的计算机视觉”课程。
4. 集成学习综合指南(附Python代码)
https://www.analyticsvidhya.com/blog/2018/06/comprehensive-guide-for-ensemble-models/
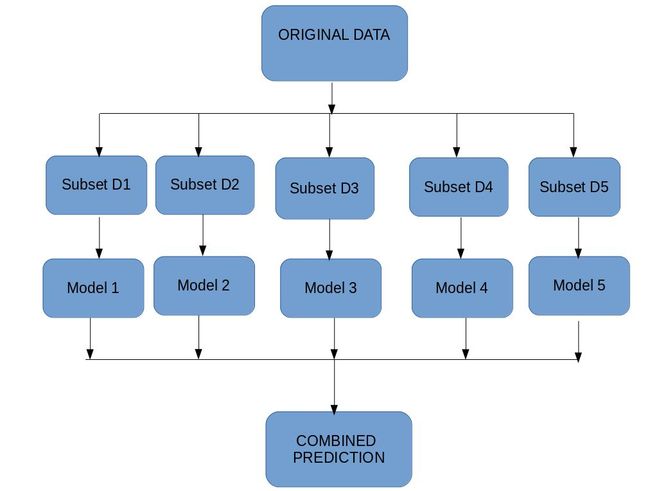
一旦我们掌握了基本的机器学习算法,接下来就是集成学习了。这是一个迷人的概念,并在本文中得到了非常好的解释。有大量的例子可以帮助把复杂的主题分解成容易理解的想法。
由于本指南的综合性,Aishwarya指导我们通过许多技术-bagging,boosting,随机森林,LightGBM,CatBoost等等,所有的信息宝库都集中在一个地方!
在黑客比赛中,你经常会遇到这种方法-它是一种已经被证实的、成为领头羊的方法。
5. 每个数据科学家必须使用的25个深度学习开放数据集
https://www.analyticsvidhya.com/blog/2018/03/comprehensive-collection-deep-learning-datasets/

学习和吸收一个概念的最好方法是什么?学习理论是一个很好的开始,但是只有当我们真正理解这种技术是如何工作之后,我们才能从实践中真正学到东西。对于像深度学习这样广阔的领域来说,尤其如此。
训练技能的数据集并不短缺-但是应该从哪里开始呢?哪一组数据集最适合用来建立你的个人资料?你能得到特定领域的数据集来帮助你熟悉这一领域的工作吗?为了能够帮助到你,我们为你精心挑选了25个开放的深度学习数据集。
这些数据集分为三类:
图像处理
自然语言处理
音频/语音处理
所以,选择你感兴趣的领域,从今天起就开始吧!
6. 12种降维技术的终极指南(附Python代码)
https://www.analyticsvidhya.com/blog/2018/08/dimensionality-reduction-techniques-python/

啊,维度的诅咒。能有更多的数据固然好,它有助于构成一个足够大的训练集。但正如大多数数据科学家所证实的那样,拥有过多的数据最终会让人头疼。当面对一个拥有1000个变量的数据集时,应该做什么?要在粒度级别上分析每个变量是不太可能的。
这就是降维技术会如此重要的原因。在不丢失(太多)信息的情况下减少特征的数量是我们共同努力的目标,降维是一种非常有效的方法,Pulkit在这篇文章中对此做了全面的展示。他讨论了12种降维技术,以及它们在Python中的实现,其中包括主成分分析(PCA)、因子分析和t-SNE。
二、商业智能与数据可视化
1. 数据科学和商业智能专业人员的Tableau中级指南
https://www.analyticsvidhya.com/blog/2018/01/tableau-for-intermediate-data-science/

Tableau是分析手头数据的一个非常好的工具,它的功能不仅仅局限于生成漂亮的可视化图表——利用 Excel同样也可以实现类似的任务。
Tableau的扩展功能确实可以将智能放入到BI之中。
本文针对的是已经熟悉Tableau的基本功能,但是希望拓展对该工具的认识的用户。作者介绍了连接、数据混合、执行计算、分析和理解参数等主题。文中的华美描述,将使你更加想要立即启动Tableau!
如果需要快速复习一下Tableau,也可以先阅读Tableau初学者指南。
2. 数据科学和商业智能专业人员的Tableau高级进阶指南
https://www.analyticsvidhya.com/blog/2018/03/tableau-for-advanced-users-easy-expertise-in-data-visualisation/

在完成Tableau中级指南之后,接下来顺理成章地可以学习本指南。在这里,我们超越了Tableau的“ShowMe”(秀我)特性,探索出更为高级的图表。Pavleen雄辩地如是说-“这些高级图表的壮美令人兴奋和陶醉”。
这篇文章中涵盖多种不同类型的图表- Motion,Bump,Donut,Waterfall 和Pareto。此外,还介绍了Tableau中R编程的概念。当你希望将数据科学与BI结合起来时,这的确非常有用!
三、数据科学方向的职业
1. 最全面的数据科学与机器学习面试指南
https://www.analyticsvidhya.com/blog/2018/06/comprehensive-data-science-machine-learning-interview-guide/

把这些个指南放在一起真的很有趣。面试往往是数据科学家们面临的绊脚石,要想通过面试,需要一定的技能组合,如果你来自非技术背景(比如我),那么破解这些面试就变得更具挑战性了。
数据科学方向的面试通常会问什么样的问题?面试官要寻找的是什么?技术和软技能的正确结合是什么?如果没有做好充分的准备,这些都会让人望而生畏,这就是撰写这篇冗长而详细的指南背后的想法。
这个全面的帖子涵盖了多个主题与丰富的资源,包括数据科学和机器学习问题,特定工具的小测验,各种案例研究,谜题,猜测,甚至是几个引导你奔向终点线的真实的励志小故事!
2. 业余数据科学家所犯的13个常见错误及如何避免这些错误
https://www.analyticsvidhya.com/blog/2018/07/13-common-mistakes-aspiring-fresher-data-scientists-make-how-to-avoid-them/

有抱负的数据科学家在匆忙闯入这个领域时往往会犯很多错误,我同样在这个领域也出过很多错,在这篇文章中,记录了13个我见过的业余数据科学家所犯的常见错误。相信我,成为一名数据科学家是一条艰难的道路,而你并不是唯一犯这些错误的人。
从别人的错误中吸取教训也可能是一种职业生涯的经历,为此,我还提供了一份资源清单,目的是帮助你克服这些障碍,助力你迈向数据科学希望之地的旅程。
3. 想成为一名数据工程师吗?这是一份助你启程的全面的资源列表。
https://www.analyticsvidhya.com/blog/2018/11/data-engineer-comprehensive-list-resources-get-started/

到目前为止,我们主要讨论的是数据科学家。但是数据科学领域还有很多其他的角色,目前最热门的是数据工程师。在所有的数据科学家的大肆宣传中,他们往往被忽视了,但在任何DS项目中,数据工程师都是非常关键的一环。
要成为数据工程师,目前没有单一的结构化路径可以遵循,我希望这篇文章能提供一个不同的选项。这里有大量免费资源,包括电子书、视频课程、基于文本的文章等。
了解了什么是数据工程师,以及这个角色与数据科学家的不同之处之后,我们便直接深入到你需要了解的各个方面的知识和技能,以便使你顺利成为自己希望成为的那个角色。文中,我还提到了一些在数据科学界得到了认可的数据工程证书。
四、自然语言处理
1. 数据科学家和工程师们处理文本数据的终极指南(附Python语言)
https://www.analyticsvidhya.com/blog/2018/02/the-different-methods-deal-text-data-predictive-python/

这是一本你的必读指南。这本NLP初学者基础指南,从一些基本概念开始,逐步构建起更先进的概念,如包词和单词嵌入。解决文本数据问题有多种方法,在这里将介绍这些不同的方法。
特征提取、预处理和高级技术-所有这些都是文本数据包含的内容。每种技术都使用Python代码和一个开放的数据集来展示,这样可以做到一边学习一边编写代码。
你还可以加入 ‘使用Python的自然语言处理’综合课程,开启自己的NLP职业生涯。
2. 用Python构建FAQ聊天机器人-信息搜索的未来
https://www.analyticsvidhya.com/blog/2018/01/faq-chatbots-the-future-of-information-searching/

2018年是聊天机器人达到顶峰的一年,这是自然语言处理(NLP)在市场上最常见的应用。不难理解的是,越来越多的人想要学习如何构建一个聊天机器人。那么,你来对地方了!
本文探讨如何提取与印度最近引入的商品和服务税(GST)相关信息,在Python中构建聊天机器人。一个GST-FAQ机器人!作者利用Rasa-NLU库构建了该BOT。
3. 在Python中使用ULMFiT和Quickai库进行文本分类(NLP)教程
https://www.analyticsvidhya.com/blog/2018/11/tutorial-text-classification-ulmfit-fastai-library/
这是一个非常重要的话题-无论对于初学者还是高级NLP用户来说都是如此。ULMFiT框架是由Sebastian Ruder和JeremyHoward开发的,它为其他迁移学习库铺平了道路。这篇文章更适合那些熟悉基本NLP技术并希望拓展知识面的人。
Prateek Joshi采用通俗易懂方法,向我们介绍了迁移学习的世界:ULMFiT框架,以及如何在Python中实现这些概念。正如Sebastian Ruder所说,“NLP的ImageNet时刻已经到来”,是时候跳上这架马车了。
五、播客(一种可订阅下载音频文件的互联网服务,多为个人自发制作)
注:播客是一种可订阅下载音频文件的互联网服务,多为个人自发制作。
1. 必听的10个数据科学、机器学习和人工智能的播客
https://www.analyticsvidhya.com/blog/2018/01/10-data-science-machine-learning-ai-podcasts-must-listen/
播客是一个很好的消费信息的媒介。不是所有的人都有时间阅读文章,播客正是填补了这一空白,使得我们更为便捷地了解机器学习的最新发展。这个前10名播客集在出版时就走红了,之后便一直位居榜首。
我们今年还推出了自己的播客系列:DataHack Radio。DHR的特点是数据科学和机器学习行业的顶级先驱者和实践者,并迎合数据科学界各层级的需要。它可以在SoundCloud,iTunes上访问到,当然也可以在我们自己的网站上访问到!
尾注
再一次对Analytics Vidhya社区的成员大声表示:感谢你们一如既往的支持和对数据科学的热爱。让我们共同努力,使2019年成为更加美好和更为壮大的一年,并承诺保持我们对学习的无限渴望!明年见。
原文标题:
The 15 Most Popular Data Science and Machine Learning Articles on Analytics Vidhya in 2018
原文链接:
https://www.analyticsvidhya.com/blog/2018/12/most-popular-articles-analytics-vidhya-2018/
译者简介

陈之炎,北京交通大学通信与控制工程专业毕业,获得工学硕士学位,历任长城计算机软件与系统公司工程师,大唐微电子公司工程师,现任北京吾译超群科技有限公司技术支持。目前从事智能化翻译教学系统的运营和维护,在人工智能深度学习和自然语言处理(NLP)方面积累有一定的经验。业余时间喜爱翻译创作,翻译作品主要有:IEC-ISO 7816、伊拉克石油工程项目、新财税主义宣言等等,其中中译英作品“新财税主义宣言”在GLOBAL TIMES正式发表。能够利用业余时间加入到THU 数据派平台的翻译志愿者小组,希望能和大家一起交流分享,共同进步
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。


点击“阅读原文”拥抱组织