C++之函数指针_回调函数_函数模板初探
站在编译器和C的角度剖析c++原理, 用代码说话
函数指针
C语言中通过typedef为函数类型重命名, 语法格式为:typedef type name(parameter list).
那么,什么是函数指针呢? 函数指针用于指向一个函数, 并且函数名是执行函数体的入口地址. 我们先回顾一下如何定义一个数组类型:
typedef int (MyArrayType)[10];这样我就能够使用: MyArrayType myArray; myArray[0] = 1;, 这样就相当于是int myArray[10];.
接下来我们再回顾一下定义一个数组指针类型:
typedef int (*PMyArrayType)[10];, 这里表示的是指向数组的指针. 于是:
int array2[10];
typedef int (*PMyArrayType)[10];
PMyArrayType pmyArray;
pmyArray = &array2;
(*pmyArray)[0] = 11;这里涉及到array, &array, *array的知识点,咱们再回顾一下:
我们先说如何理解int (*Parray)[10]=&arr;这是一个数组指针呢? 首先()优先级比较高, 所以Parray是一个指针,指向一个整形的一维数组,数组的长度为10,比如int arr[10]={0,1,2,3,4,5,6,7,8,9}; 那么是么是指针数组? int Parray[10]就是典型的指针数组, []优先级高,先与Parray结合成为一个数组,再由int说明这是一个整型指针数组,它有10个指针类型的数组元素.
这里再回顾一下我们第一片文章的引用的本质是常指针,常指针可不是常量指针,它是指针常量,也就是类似于int * const a, 是说这个指针不能改变而不是指针指向的内存空间不能改变. 另一个容易混淆的概念是常量指针,也就是类似于int const * a, 这是说指针指向的内存空间不能改变.
好那么我们回顾一下数组:
int a[10]
打印a和打印&a的地址是一样的,但是意义不一样,现在的a表示一个常指针指向了数组的首元素,所以打印地址就是首元素的地址, &a就是指向数组的地址,也可认为是整个数组的地址, a不能进行++是因为,是因为常指针的原因,但是能进行a+1,这样移动4个字节的地址, 但是&a++就是移动40个字节. sizeof(a)这时候就不能再把数组当成是指针了,这个返回的就是40, sizeof(&a)这个就是4, 因为它就是个指针. sizeof(*a)这个返回的是4,因为第一个元素的大小,就是4字节的int.
我们先回顾在这里.
我们有时候会在代码块中定义{}, 比如:
int main(void)
{
{
}
return 0;
}为什么内部这样写,在C中我们定义变量都必须定义在开头,有了这个代码块儿就能再这里面定义了,但其实编译器在还是放在一开始就将所以变量分配了内存了,只是不能用而已.
int (*pM)[10];定义了一个指针变量, 告诉c编译器给我分配4个字节的内存,这个指针变量指向了一个数组, 言外之意是: pM++会后移一个数组单位(4*10).
我们现在深入到函数,先来定义一个函数类型:
typedef int (MyFuncType)(int);,
int test(int a){//test是函数名,函数名代表函数首地址,函数名就是函数指针
printf("a:%d", a);
return 0;
}
int main(void)
{
typedef int (MyFuncType)(int);
MyFuncType *myfunc;//函数指针变量
test(1);
myfunc = test;
myfunc(2);
myfunc = &test;
return 0;
}这里的myfunc = &test;和myfunc = test;效果是一样的,这是C语言的一个历史遗留问题,取多少个地址都是一样的效果.
我们再开定义一个函数指针类型:
typedef int (*PMyFuncType) (int);//相当于定义了个函数指针类型
PMyFuncType pMyfuncType;
pMyfuncType = test;
pMyfuncType(5);我们再来定义一个指针函数的指针变量:
int (*PmyFunc)(int);//告诉编译器,分配四个字节
PmyFunc = test;
PmyFunc(1);函数指针做函数参数
先上一段代码
int add(int a, int b){
int c;
c = a + b;
return c;
}
int MyOP(int (*MyAdd)(int, int)){
MyAdd(1, 2);
return 0;
}
int main(void){
int (*pAdd)(int, int);//定义一个函数指针变量
pAdd = add;//把函数的入口地址赋值给pAdd
MyOP(pAdd);
return 0;
}我们能够看到在MyOP函数参数列表式一个函数指针. 这样有什么用呢?好比说MyOP函数是我的核心框架,很早之前就写好的,一个程序最好的情况就是能够实现扩展,也就是说能调用未来. 那么我新写了一个扩展函数add, 只需要按照int (*pAdd)(int, int);这种函数定义去实现,我就能直接将新写的函数放入到以前的框架中实现新功能的扩展. 于是我们就能够写成这样:
//声明一个类型是个函数指针类型
typedef int (*PMyFuncType)(int, int);
int MyOP2(PMyFuncType pMyFuncType){
pMyFuncType(1, 2);
return 0;
}你只需要按照我定义的函数指针类型去实现你新的方法,然后再把函数名传入我的方法中就实现了函数指针做函数参数的调用了,这就是回调函数, 更加解耦合,表示任何的执行者,只要按照这个函数实现,我就能给你调起来.
函数指针做函数参数的本质不光是把函数的入口地址传送给被调用函数,同时函数类型是做了一个接口的约定. 其实就是个任务类型的约定, 反应到代码上就是函数类型三要素,名称,参数,返回值,通通的做了个约定, 这个是指针做函数参数的核心思想. 所以说这样是不是和c++的多态很像了. 我只要按照typedef int (*PMyFuncType)(int, int);定义出的函数,MyOP(pAdd2);就直接能用了,以前写的代码直接调用后来人的方法.
这里是我自己的一个socket进行加密解密的框架,虽然没有具体的加密解密的实现,但是主要是是为了体现用C的回调函数实现c++多条的功能.
函数模板基础语法
void myswap(int &c, int &d){
int s = c;
c = d;
}
int main(void)
{
int a1 = 1;
int b1 = 2;
myswap(a1, b1);
}这是我们之前写交换函数的方式,一旦传入myswap的函数编程char型,就得重写参数是char型的函数. 学过java的就会想到泛型,那么C++中也是有泛型的,但是业界通常叫做模板函数.
template T>
void myswap(T &a, T &b){
T t = a;
a = b;
b = t;
}; template关键字告诉c++编译器,现在我要进行泛型编程, typename就是告诉编译器我这里是个类型,请不要随便报错. 只不过是T为数据类型参数化而已, T就是int char double..
怎么使用呢:
int main(void)
{
int x = 1;
int y = 1;
myswap(x, y);
char c1 = 'q';
char c2 = 'b';
myswap(c1, c2);
return 0;
}模板函数会进行自动的类型识别. 还有一种调用方法就是现实调用类型:
myswap<int>(x, y);
char c1 = 'q';
char c2 = 'b';
myswap<char>(c1, c2);模板强化
template<typename T>
int printArray(T *a, int num)
{
for (int i=0; icout<return 0;
}
//templatefor (int j=i+1; jif (a[i] < a[j])
{
tmp = a[i];
a[i] = a[j];
a[j] = tmp;
}
}
}
return 0;
}
//templatefor (int j=i+1; jif (a[i] < a[j])
{
tmp = a[i];
a[i] = a[j];
a[j] = tmp;
}
}
}
return 0;
}
int main()
{
char buf[] = "dfdsafdsafdsafdaaaaaaafffff";
int buflen = strlen(buf);
printArray<char>(buf, buflen);
sortArray2<char, int>(buf, buflen);
printArray<char>(buf, buflen);
return 0;
} 首先说上面的templete和templete是一样的. 然后我们在进行调用的时候指定类型是泛型再指定,不是泛型就不需要指定了.
函数模板和函数重载在一起
template<typename T>
void myswap(T &a, T &b)
{
T c ;
c = a;
a = b;
b = c;
}
void myswap(int &a,char &b)
{
printf("dddd\n");
}
int main()
{
int a = 10;
char b = 'b';
myswap(a, a);//ok
myswap(b, b);//ok
myswap(a, b);//ok由系统提供隐士转换
myswap(b, a);//ok
return 0;
}函数重载遇上函数模板的调用原则:
1. 函数模板可以像普通函数一样被重载
2. C++编译器优先考虑普通函数
3. 如果函数模板可以产生一个更好的匹配,那么选择模板
4. 可以通过空模板实参列表的语法限定编译器只通过模板匹配
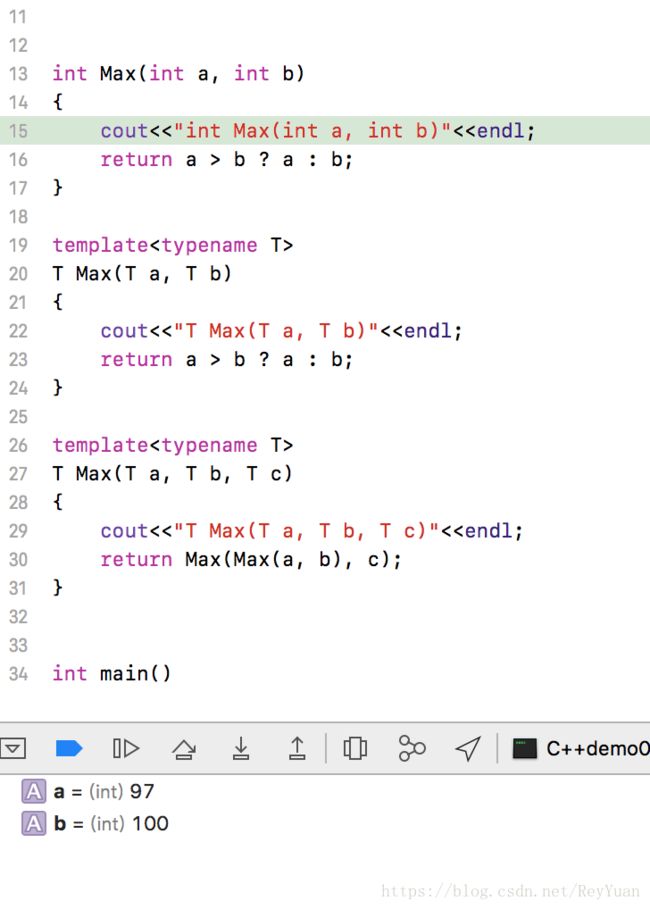
nt Max(int a, int b)
{
cout<<"int Max(int a, int b)"<return a > b ? a : b;
}
template<typename T>
T Max(T a, T b)
{
cout<<"T Max(T a, T b)"<return a > b ? a : b;
}
template<typename T>
T Max(T a, T b, T c)
{
cout<<"T Max(T a, T b, T c)"<return Max(Max(a, b), c);
}
int main()
{
int a = 1;
int b = 2;
cout<//int Max(int a, int b)
cout<(a, b)<//T Max(T a, T b)
cout<3.0, 4.0)<//T Max(T a, T b)
cout<5.0, 6.0, 7.0)<cout<'a', 100)<//int Max(int a, int b)
return 0;
} 对最后一个有些奇异的同学请看调试:
函数模板深入理解
那么函数模板到底是怎么实现的,其实是C++编译器为我们做了一些事,咱们看看g++ -s编译出的汇编是什么样子的:
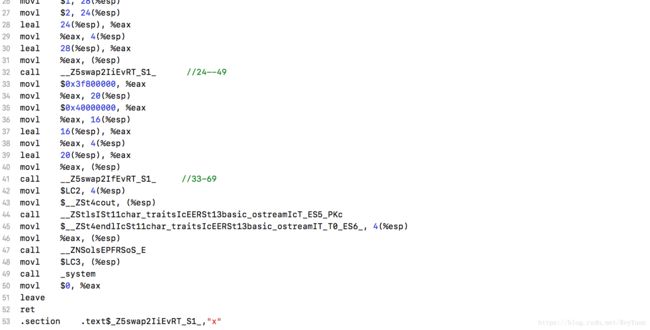
我们能够看出,在编译的时候,C++将模板中指定的不同类型分别写了一个函数,其实就是相当于我们写的重载函数,只不过是编译器帮我们做了而已.
联系方式: [email protected]