数据库原理
绪论
- 数据:描述事物的符号记录称为数据,数据的含义称为语义
- 数据库(DB):数据库是长期存储在计算机内,有组织的,可共享的大量数据的集合
- 数据库管理系统(DBMS):软件
- 数据库系统(DBS):数据库系统是由数据库,数据库管理系统,应用程序和数据库管理员组成的存储、管理、处理和维护数据的系统。
数据库管理的三个阶段
人工管理、文件系统、数据库系统
概念模型
- 实体:客观存在可相互区别的事物
- 属性:实体所具有的某一特性
- 码:唯一标识实体的属性集称为码
- 实体型:用实体名及其属性名集合来抽象和刻画同类实体。学生(学号,姓名……)
- 实体集:同一类型实体的集合。全体学生
- 联系:一对一,一对多,多对多
数据模型
- 数据结构
- 数据操作:对数据库中的对象允许执行的操作的集合
- 数据的完整性约束条件:数据及期联系所具有的制约和依存关系
三级模式结构
- 模式:也称逻辑模式,是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图,一个数据库只有一个模式
- 外模式:也称子模式或用户模式,是数据库用户能够看见和使用的局部数据的逻辑结构和特征的描述,数据库用户的数据视图,是与某一应用有关的数据的逻辑表示。保证数据库安全性,用户只能看到对应的外模式。
- 内模式:也称存储模式,一个数据库只有一个内模式,它是数据物理结构和存储方式的描述,是数据在数据库内部的组织方式
- 外模式/模式映象:和外模式个数有关;当模式改变时,只需修改映象,不必修改外模式,保证逻辑独立性
- 逻辑模式/内模式映象:当存储结构改变时,只需修改映象,保证物理独立性
第二章
域:一组具有相同数据类型的值的集合
元组:域的笛卡尔积叫做元组
候选码:某一属性组的值能唯一标识一个元组,而其子集不能
主码:从候选码中选择一个作为主码
外码:关系R中的一个属性,它不是R的候选码,但它与另一个关系S的主码相对应,则称R中的这个属性为外码
关系:基本表、查询表、视图
关系模式:
R(U,D,DOM,F)R为关系名,U为组成该关系的属性名集合,D为U中属性所来自的域,DOM为属性向域的映像集合,F为属性间数据依赖关系集合
结构化查询语言:SQL
关系完整性
- 实体完整性:主属性不能取空值
- 参照完整性:属性与另一个表的主码相对应(外码)
- 用户定义完整性:语义要求(唯一值、取值范围等)
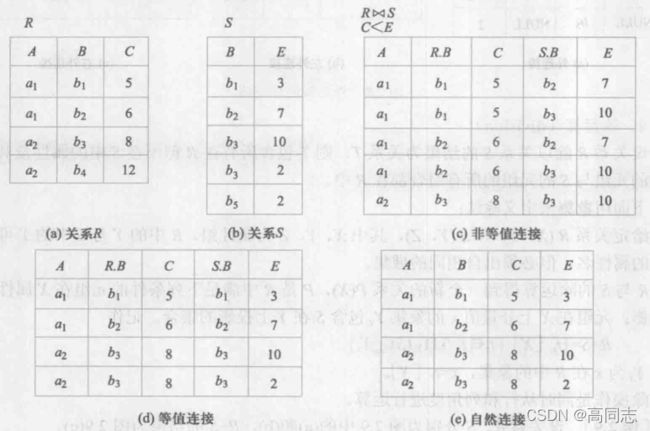
关系代数
| ∪ | - | ∩ | × | ÷ | σ | ∏ | ▷◁ | ρ |
|---|---|---|---|---|---|---|---|---|
| 并 | 差 | 交 | 笛卡尔积 | 除 | 选择 | 投影 | 连接 | 更名 |
代数操作
交
θ连接
自然连接
等值连接
θ为“=”的连接运算称为等值连接,选取属性值相等的元组
自然连接是特殊的等值连接,要求比较的分量必须是同名的属性组
除
结果中属性部分包含属性相减之后的,元组部分满足结果与除数的连接的结果在被除数中

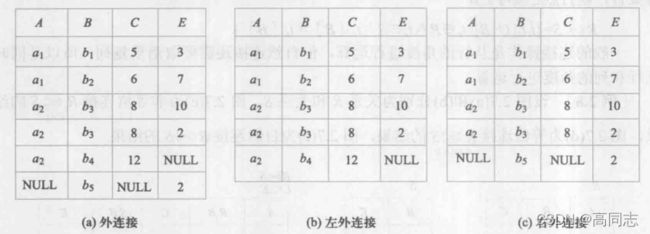
外连接
连接时,由于没有公共属性上值相等的元组,造成某些元组被舍弃了,这些被舍弃的元组称为悬浮元组。如果想把悬浮元组也保存在结果中,则其无对应的属性值为NULL,
- 左外连接:只保留连接式左边的元组
- 右外连接:只保留连接式右边的元组
- 全外连接:左右两边都保存
关系元组演算
第三章
| SQL功能 | 动词 |
|---|---|
| 数据查询 | SELECT |
| 数据定义 | CREATE,DROP,ALTER |
| 数据操纵 | INSERT,UPDATE,DELETE |
| 数据控制 | GRANT,REVOKE |
定义语句
| 创建 | 删除 | 修改 | |
|---|---|---|---|
| 模式 | CREATE SCHEMA | DROP SCHEMA | |
| 表 | CREATE TABLE | DROP TABLE | ALTER TABLE |
| 视图 | CREATE VIEW | DROP VIEW | |
| 索引 | CREATE INDEX | DROP INDEX | ALTER INDEX |
没有修改模式和视图的操作,先删除再重建
视图是从基本表中或其他视图中导出的表,它本身并不存储在数据库中,虚表
模式
表示一个数据库的命名空间
--为用户WANG定义一个模式 S-T
CREATE SCHEMA "S-T" AUTHORIZATION WANG
--为用户ZHANG创建一个模式TEST,并且在其中定义一个表TAB1
CREATE SCHEMA TEST AUTHORIZATION ZHANG
CREATE TABLE TAB1(COL1 INT,
COL2 CHAR(20)
);
--删除模式
DROP SCHEMA <模式名> <CASCADE|RESTRICT>
--CASCADE和RESTRICT必选其一,CASCADE级联,表示在删除模式的同时把该模式下的数据库对象全部删除;RESCRICT限制,表示如果该模式中已经定义了数据库对象,则拒绝该语句的执行
表
定义
create table Course
(Cno char(4) primary key,
Cname char(40) not null,
Cpno char(4),
Ccredit smallint,
foreign key (Cno) references Course(Cno) --外码约束
);
create table SC
(Sno char(9),
Cno char(4),
Grade smallint,
primary key(Sno,Cno),--主键包括两个属性
foreign key (Sno) references Student(Sno),
foreign key (Cno) references Course(Cno)
);
修改
--Student表中增加列S_entrance
alter table Student add S_entrance Date;
--修改表Student的列的数据类型
alter table Student modify Sage int;
--增加Course表中的Cname列的约束条件
alter table Course add unique(Cname);
--删除列的约束条件
alter table Student drop unique(Sno);
删除
--表一旦删除,表中的数据和建立的索引都将自动删除,视图也无法使用
drop table Student;
--CASCADE会删除与该表有关的一切事物
索引
加快表的查询速度,按某种方式排序之后的结果,可以建立在一列或多列上,在DBMS中一般是自动建立的(主键)
- unique:表示索引的每一个索引值只对应唯一的数据记录,有重复值的列不能建立索引
- cluster:聚簇索引,磁盘上存储的物理顺序和索引项的顺序一致,一个表只能建立一个聚簇索引
建立(默认ASC升序)
--在表Student的Sname列建立一个聚簇索引,Student表中的记录按照Sname升序存放
create cluster index ind_Sname on Student(Sname);
--唯一索引
create unique index int_Cno on Course(Cno);
create unique index ind_SC on SC(Sno ASC,Cno DESC)
删除
drop index ind_Sname
查询
between and,not between and
in,not in
like,not like,%,_
is null,is not null
and,or
集函数
count()
sum()
avg()
max()
min()
去重
distinct,all
select Sno,count(*)
from Student
where Sdept='CS'
group by Ssex having count(*)>4
order by Sno ASC
外连接,主表和从表,空值补充
--左外连接,右边从表补充空值
select Student.Sno,Sname,Cno,Grade
from Student,SC
where Student.Sno=SC.Sno(*)
嵌套查询
--子查询一定要写在比较运算符之后
select Sname
from Student
where Sno in
(select Sno
from SC
where Cno='2')
--查询其他系中比IS系所有学生年龄都小的学生名单
select Sname,Sage
from Student
where Sage < all
(select Sage
from Student
where Sdept='IS')
and Sdept != 'IS'
order by Sage DESC
select Sname,Sage
from Student
where Sage <
(select min(age)
from Student
where Sdept='IS')
and Sdept != 'IS'
order by Sage DESC
UNION并集(属性相同)
select *
from Student
where Sdept="CS"
union
select *
from Student
where Sage<=19
插入
insert into SC(Sno,Cno)
values('95020','1');
insert into Deptage(Sdept,Averge)
select Sdept,avg(Sage)
from Student
Group by Sdept
修改
update Student
set Sage=22
where Sno="95001"
视图
视图是不实际存储数据的虚表,可以对数据提供安全保护
--创建信息系的学生信息
create view IS_Student
as
select Sno,Sname,Sage
from Student
where Sdept='IS'
with check option
select语句一般情况下不允许有order by和distinct- 如果定义视图的语句省略了组成视图的属性名,则默认和
select语句的属性名一致 with check option表示对视图的操作update,insert,delete同时要满足where语句中的谓词条件- 定义的视图只是把视图的定义存入数据字典,而并不执行
select语句,在对视图进行查询操作时才在基础表中进行数据查询,也就是说视图并不是在创建时就固定不变,而是随着基本表的变化而动态变化 - 视图可以建立在另一个视图上
--创建每个学生的平均值
create view S_G(Sno,Gavg)
as
select Sno,avg(Grade)
from SC
group by Sno
定义视图时最好有明确的属性列名
--创建女生学生视图
create view view1(Snum,Sname,sex,age,dept)
as
select *
from Student
where Ssex = "女"
select *,如果以后修改了Student表的结构(比如新增加一列),则视图view1与Student的映像关系就会出现问题,所以还是明确指出基本表的属性名与视图属性映射。或者修改基本表的结构之后,删除视图并重新建立
--删除视图
drop view view1
若视图的基本表被删除了,视图不会自动删除,只是会失效
视图的查询:用户对视图的查询+视图定义时的子查询
更新:由于视图是不实际存储数据的虚表,因此对视图的更新最终要转化为对基本表的更新
为防止视图在更新时操作不属于视图操作范围的基本表数据,在创建视图时加上with check option,这样在视图更新时就会检查在视图定义时的条件
并不是所有的视图都允许更新,因为有些不能转化为对应的基本表操作
update IS_Student
set Sname="zhangsan"
where Sno='95002'
--转换成对应基本表的操作,添加上视图创建时的where谓词条件
update Student
set Sname="zhangsan"
where Sno='95002' and Sdept='IS'
insert into IS_Student
values('95025','lisi',20)
--转化
insert into Student(Sno,Sname,Sage,Sdept)
values('95025','lisi',20,'IS')
delete from IS_Student
where Sno='95025'
--转化
delete from IS_Student
where Sno='95025' and Sdept='IS'
授权
| 对象 | 类型 | 操作权限 |
|---|---|---|
| 属性列,视图 | Table | Select,Insert,Update,Delete,All Privileges(四种8权限的总和) |
| 基本表 | Table | Select,Insert,Update,Delete,Alter,Index,All Privileges |
| 数据库 | Database | CREATETAB |
--把修改Student表的权限授给用户U1,并允许U1将此权限授给其他用户
Grant Update On Table Student To U1 With Grant Option
--把Student和Course表的所有权限授给用户U3和U2
Grant All Privileges On Table Student,Course To U3,U2
--把Student的插入权限授给所有用户
Grant Insert On Table Student To Public
--DBA将在数据库S_C中创建表的权限授给U4
Grant CREATETAB On DATABASE To U4
第四章
关系模式:
R(U,D,DOM,F)R为关系名,U为组成该关系的属性名集合,D为U中属性所来自的域,DOM为属性向域的映像集合,F为属性间数据依赖关系集合
逻辑蕴涵
设F是关系模式R(U)中的一个函数依赖集合,X,Y是R的属性子集,如果从F中的函数依赖能够推导出X->Y,则称F逻辑蕴涵X->Y,或称X->Y是F的逻辑蕴涵。
闭包
被F逻辑蕴涵的所有函数依赖集合称为F的闭包,记作F+
(若F+=F,则说F是一个全函数依赖族)
Armstrong ‘ s Axioms 阿姆斯特朗公理
- 自反律:若Y属于X属于U,则X->Y被F逻辑蕴涵。
- 增广律:若X->Y∈F,且Z属于U,则XZ->YZ
- 传递率:若X->Y∈F,且Y->Z,则X->Z被F逻辑蕴涵
- 合并律:若X->Y且X->Z,则X->YZ
- 伪传递律:若X->Y且WY->Z,则XW->Z
- 分解律:若X->Y且Z属于Y,则X->Z
属性闭包
X+ = { A | 用阿姆斯特朗定理从F导出的X->A }

覆盖
对R(U)上的两个函数依赖集合F,G,如果F+ = G+ ,则称F和G是等价的,也称F覆盖G或者G覆盖F。
函数依赖
函数依赖:X函数确定Y。F={Sno->Sdept,Sdept->Mname,(Sno,Cname)->Grade}
糟糕的关系模式会存在:数据冗余太大,更新异常,插入异常,删除异常
平凡函数依赖与非平凡函数依赖
-
非平凡函数依赖:R(U)中,对于U的子集X和Y,如果X->Y,但Y不是X的子集,则称X->Y是非平凡函数依赖
-
平凡函数依赖:如果X->Y,Y是X的子集,则称X->Y是平凡函数依赖
完全函数依赖与部分函数依赖
-
完全函数依赖:R(U),如果X->Y,并且对于X的任何一个真子集X’,都不能X’->Y,则称Y完全函数依赖于X,记作
X-f->Y(Sno,Cno)-f->Grade -
部分函数依赖:若X->Y,但Y不完全函数依赖于X,则称Y部分函数依赖于Y,记作
X-p->Y(Sno,Cno)-p->Cname
传递函数依赖
X->Y,Y->Z,且Y不是X的子集,Z不是Y的子集,Y不能退出X,则称Z传递函数依赖X
码
- 候选码:R
K-f->U,则K称为R的一个候选码 - 主码:选定一个候选码为主码
- 主属性:如一个属性是构成某一个候选关键字的属性集中的一个属性,称为主属性
第一范式1NF
所有属性都是不可分的基本数据项,R属于1NF
SLC(Sno,Sdept,Sloc,Cno,Grade),[【码(Sno,Cno)】
(Sno,Cno)-f->Grade,完全函数依赖;(Sno,Cno)-p->Sdept,部分函数依赖
插入异常,删除异常,数据冗余大,修改复杂。【原因:Sdept,Sloc对码的部分函数依赖】
第二范式2NF
若R属于1NF,并且每一个非主属性都完全依赖于R的码,则R属于2NF
SC(Sno,Cno,Grade)【码(Sno,Cno)】;SL(Sno,Sdept,Sloc)【码:Sno,Cno】【消除了Sdept,Sloc对码的部分函数依赖】
依然存在插入异常,删除异常,数据冗余性大,修改复杂。【原因:SL中Sloc传递函数依赖与Sno】
第三范式3NF
第三范式每一个非主属性既不部分函数依赖于候选码,也不传递函数依赖于候选码
把SL分解为
SD(Sno,Sdept)【码:Sno】;DL(Sdept,Sloc)【码:Sdept】
BCNF
所有属性都不部分依赖于码也不传递依赖于码。每个决定属性集都包含候选码,BCNF
STJ(S,T,J)学生,教师,课程。一个教师教一门课,每门课由若干教师教函数依赖:
(S,J)->T;(S,T)->J;T->J。满足3NF,但仍存在问题。T是决定属性集,T只是主属性,既不是候选码也不包含候选码
分解:
ST(S,T);TJ(T,J)分解后没有任何属性对码的部分函数依赖和传递函数依赖
多值依赖
Teach(C,T,B)课程C,教师T,参考书BC—>—>T,T多值依赖于C。一个C的值可以决定多个T的值
第四范式4NF
限制关系模式的属性之间不允许有非平凡且非函数依赖的多值依赖
CT(C,T);CB(C,B)

关系模式的分解
如果分解后的关系可以通过自然连接恢复成原来的关系,那么这种分解就没有丢失信息,具有无损连接性
- 分解具有无损连接性能保证不丢失信息;分解保持函数依赖可以减轻或解决各种异常情况
- 具有无损连接性的分解不一定能保持函数依赖;同样保持函数依赖的分解也不一定具有无损连接性
如果分解具有无损连接性,那么模式分解一定能够达到4NF
若要求分解保持函数依赖,那么模式分解一定能够达到3NF,但不一定能够达到BCNF
若要求分解达到无损连接和函数依赖,那么模式分解一定能够达到3NF,但不一定能够达到BCNF
第五章
数据库保护
用户标识和鉴定、存取控制、定义视图、审计(日志)、数据加密
并发控制
事务
事务是数据库的逻辑工作单位,它是用户定义的一组操作序列
--开始
Begin Transaction
--提交事务的所有操作,将事务中所有对数据库的更新写回到磁盘上的物理数据库,事务正常结束
Commit
--回滚,发生故障,将事务中对数据库的所有已完成的更新操作全部撤销,回滚到开始时的状态
RollBack
ACID属性
- 原子性(atomicity):不可分割,一个事务中的操作要么都做,要么都不做
- 一致性(consistency):从一个一致性状态到另一个一致性状态
- 隔离性(isolation):一个事物的执行不能被另一个事务干扰
- 持续性(durability):一个事物一旦提交,它对数据库的数据改变就应该是永久性的
丢失修改

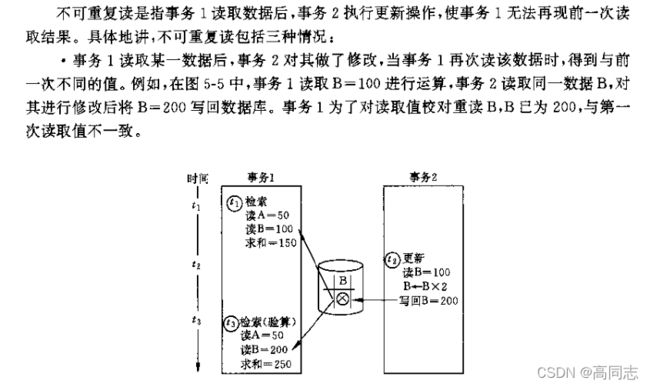
不可重复读
脏读

触发器
定义在关系表上的一类由事件驱动的特殊过程
create trigger SC_T--触发器名
After update of Grade on SC--触发事件
并发操作的调度
事务不同的执行顺序,串行执行结果相同,这种并行的调度策略称为可串行化
封锁
- 排它锁(X锁,写锁):事务T给数据对象A加上X锁,只允许T读取和修改A,其他任何事务都不能对A做任何操作,直到T释放A上的锁
- 共享锁(S锁,读锁):事务T对数据对象A加上S锁,只允许读A,其他事务只能对A加S锁,不能加X锁,直到T释放A的S锁。
封锁粒度:封锁的粒度越大,系统中能够被封锁的对象就越少,并发度也就越小,但同时系统开销也就越小。相反,封锁粒度越小,并发度越高,系统开销越大
死锁和活锁
活锁:某个事务由于某种原因一直处于无限期的等待
死锁:多个事务处于一种互相争夺资源数据的状态,互相等待,不能结束
恢复
事务故障、系统故障、介质故障
日志文件:先写日志文件,再写数据库
数据库复制
对等复制:各个场地的数据库地位平等,可以互相复制数据
主/从复制:只能从主数据库复制到从数据库中,更新数据也只能在主数据库中
级联复制:从主数据库复制过来的数据又从该场地复制到其他数据库中
第六章
数据库设计步骤

数据字典
数据项、数据结构、数据流、数据存储、处理过程
第八章
数据库系统的发展
- 第一代:层次和网状
- 第二代:关系数据
- 第三代:面向对象
分布式数据库的特点
- 数据的物理分布,分布在不同场地的计算机上;
- 数据的逻辑整体性,逻辑上是相互联系的整体;
- 数据的分布独立性,用户不必关心数据的分布和分片;
- 场地自治的协调,每个结点具有独立性,能处理局部的请求和处理全局的应用请求;
- 数据的冗余及透明性,存在适当冗余以适合分布式处理的特点
数据仓库
为了构建新的分析处理环境而出现的一种数据存储和组织技术
面向主题的、集成的、不可更新(数据仓库主要供分析决策之用,一般不进行修改操作)、数据仓库随时间变化(增加新的数据,删除旧的数据)