利用卷积神经网络对CIFAR-10数据集分类
CIFAR-10
该数据集共有60000张彩色图像,这些图像是32*32,分为10个类,每类6000张图。这里面有50000张用于训练,构成了5个训练批,每一批10000张图;另外10000用于测试,单独构成一批。测试批的数据里,取自10类中的每一类,每一类随机取1000张。抽剩下的就随机排列组成了训练批。注意一个训练批中的各类图像并不一定数量相同,总的来看训练批,每一类都有5000张图。
python 版本数据集下载网址:)
http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
下载之后加压,文件结构如下
data_batch_1到data_batch_5用于模型的训练,test_batch用于模型的验证。
下面我们使用卷积神经网络对CIFAR数据集进行分类
这里我们使用的网络结构如下:
#输入层(32,32,3)–卷积层1(32,32,32)–池化层1(16,16,32)–卷积层2(16,16,64)–池化层2(8,8,64)-全连接层-输出层
首先将数据下载,并加载进来。
代码如下:
import pickle as p
def load_batch(file):
with open(file,'rb') as f:
data_dict=p.load(f,encoding='bytes')
images=data_dict[b'data']
labels=data_dict[b'labels']
images=images.reshape(10000,3,32,32)
images=images.transpose(0,2,3,1)
labels=np.array(labels)
return images,labels
def load_data(data_dir):
images_train=[]
labels_train=[]
for i in range(5):
f=os.path.join(data_dir,'data_batch_%d'%(i+1))
print('loading f')
image_batch,label_batch=load_batch(f)
images_train.append(image_batch)
labels_train.append(label_batch)
Xtrain=np.concatenate(images_train)
Ytrain=np.concatenate(labels_train)
del image_batch,label_batch
Xtest,Ytest=load_batch(os.path.join(data_dir,'test_batch'))
print('finishing loading data')
return Xtrain,Ytrain,Xtest,Ytest
data_dir='data/'
Xtrain,Ytrain,Xtest,Ytest=load_data(data_dir)
print(Xtrain.shape)
print(Ytrain.shape)
print(Xtest.shape)
print(Ytest.shape)
2:数据预处理
Xtrain_norm=Xtrain.astype('float32')/255.
Xtest_norm=Xtest.astype('float32')/255.
Xtrain_norm[0][0][0]
3:将数据的标签格式改为独热编码
#独热编码
import sklearn
from sklearn.preprocessing import OneHotEncoder
encoder=OneHotEncoder(sparse=False)
yy=[[0],[1],[2],[3],[4],[5],[6],[7],[8],[9]]
encoder.fit(yy)
Y_train_reshape=Ytrain.reshape(-1,1)
Y_test_reshape=Ytest.reshape(-1,1)
Ytrain_onehot=encoder.transform(Y_train_reshape)
Ytest_onehot=encoder.transform(Y_test_reshape)
4:定义网络结构,损失函数,优化器
#输入层(32,32,3)-卷积层1(32,32,32)
#-池化层1(16,16,32)-卷积层2(16,16,64)
#-池化层2(8,8,64)-全连接层-输出层
#tf.reset_default_graph()
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
def bias(shape):
return tf.Variable(tf.constant(0.1,shape=shape),name='b')
def weight(shape):
return tf.Variable(tf.truncated_normal(shape,stddev=0.1),name='w')
def conv2d(x,w):
return tf.nn.conv2d(x,w,strides=[1,1,1,1],padding='SAME')
def max_pool(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
with tf.name_scope('input_layer'):
x=tf.placeholder('float',shape=[None,32,32,3],name='x')
with tf.name_scope('conv_1'):
w1=weight([3,3,3,32])
b1=bias([32])
conv_1=conv2d(x,w1)+b1
conv_1=tf.nn.relu(conv_1)
with tf.name_scope('pool_1'):
pool_1=max_pool(conv_1)
with tf.name_scope('conv_2'):
w2=weight([3,3,32,64])
b2=bias([64])
conv_2=conv2d(pool_1,w2)+b2
conv_2=tf.nn.relu(conv_2)
with tf.name_scope('pool_2'):
pool_2=max_pool(conv_2)
with tf.name_scope('fc'):
w3=weight([4096,256])
b3=bias([256])
flat=tf.reshape(pool_2,[-1,4096])
h=tf.nn.relu(tf.matmul(flat,w3)+b3)
h_dropout=tf.nn.dropout(h,keep_prob=0.7)
with tf.name_scope('output'):
w4=weight([256,10])
b4=bias([10])
pred=tf.nn.softmax(tf.matmul(h_dropout,w4)+b4)
with tf.name_scope('optimizer'):
learning_rate=0.001
y=tf.placeholder('float',shape=[None,10],name='label')
loss_function=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=pred,labels=y))
optimizer=tf.train.AdamOptimizer(learning_rate).minimize(loss_function)
with tf.name_scope('evaluation'):
correct_prediction=tf.equal(tf.argmax(pred,1),tf.argmax(y,1))
acc=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
5:启动Session,训练模型
import os
from time import time
sess=tf.Session()
init=tf.global_variables_initializer()
sess.run(init)
train_epochs=50
batch_size=100
total_batch=int(len(Xtrain)/batch_size)
epoch_list=[]
acc_list=[]
loss_list=[]
epoch=tf.Variable(0,name='epoch',trainable=False)
#定义batch读取函数
def get_train_batch(number,batch_size):
return Xtrain_norm[number*batch_size:(number+1)*batch_size],Ytrain_onehot[number*batch_size:(number+1)*batch_size]
for ep in range(train_epochs):
for i in range(total_batch):
batch_x,batch_y=get_train_batch(i,batch_size)
sess.run(optimizer,feed_dict={x:batch_x,y:batch_y})
if i %100==0:
print('step',i,'finished')
loss,acc1=sess.run([loss_function,acc],feed_dict={x:batch_x,y:batch_y})
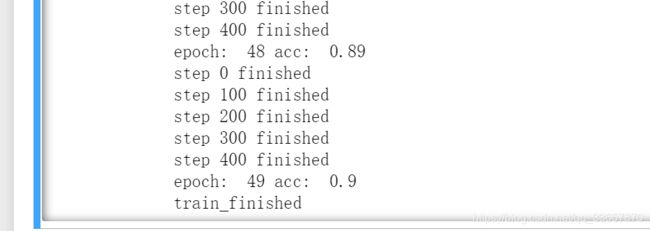
print('epoch: ',ep,'acc: ',acc1)
epoch_list.append(ep+1)
loss_list.append(loss)
acc_list.append(acc1)
print('train_finished')
训练50次,训练分类精度达到0.9;
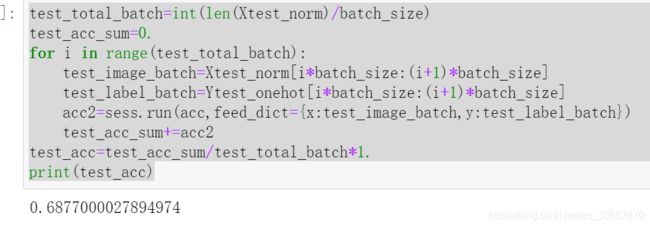
使用测试数据集进行测试,测试精度仅为0.68
test_total_batch=int(len(Xtest_norm)/batch_size)
test_acc_sum=0.
for i in range(test_total_batch):
test_image_batch=Xtest_norm[i*batch_size:(i+1)*batch_size]
test_label_batch=Ytest_onehot[i*batch_size:(i+1)*batch_size]
acc2=sess.run(acc,feed_dict={x:test_image_batch,y:test_label_batch})
test_acc_sum+=acc2
test_acc=test_acc_sum/test_total_batch*1.
print(test_acc)
训练精度和测试精度相差较大,可调整参数,比如网络结构,学习率,batch大小,训练次数等来尝试提高精度。