百分点认知智能实验室:基于NL2SQL的问答技术和实践
百分点认知智能实验室:基于NL2SQL的问答技术和实践
编者按
NL2SQL是语义解析和智能问答领域的前沿问题,可以将人类的自然语言问句转化为结构化查询语句,是实现人类和数据库无缝交互和提高数据库分析效率的核心技术。
百分点认知智能实验室自成立以来,结合公司实际业务和项目需求,自主研发NL2SQL算法,并在各个公开数据集上取得了良好的效果,同时还在业务项目中积累了宝贵的实际落地经验,本文主要就NL2SQL技术路线的发展历史和实验室在工程实践中的落地经验进行分享。
本文作者:易显维、宁星星、镇诗奇、苏海波
一 NL2SQL问题描述
以往通过SQL查询业务数据或做数据分析时,一般要经历以下几个步骤:
总结要查询数据的需求;
后端工程师编写SQL并部署成服务和数据库连接;
前端工程师编写该SQL查询对应的界面;
运维工程师上线服务;
业务数据分析人员和用户登录页面执行查询语句显示数据。
例如,下图中对一个表格进行查询,针对该需求需要写成一条SQL语句才能在数据库中执行并得到答案。

Spider数据集中自然语言问题和对应的SQL那么,如何能够减少数据分析和查询时的工作量,最好是让用户只通过一个搜索框,输入查询语句,通过自然语言处理技术将输入转化为SQL,直接执行并显示答案,这就是NL2SQL要解决的问题,详见下图。

从上图可以看出,我们将以前研发SQL查询新需求的工作效率极大地提高了,并且很多非IT人士也能通过自然语言交互界面便捷快速地和数据库交互,业务流程速度大为提高。
二 NL2SQL数据集
研究任何一个机器学习算法问题都需要该领域的数据集,在此我们列举了NL2SQL中经常使用到的几个数据集。根据数据集中SQL涉及到的数据库表的个数不同,分为单表和多表;根据所生成的SQL结构中是否含有嵌套查询,将数据集分类为有嵌套和无嵌套。
- 单表无嵌套数据集
ATIS&GeoQuery数据集:
ATIS来源于机票订阅系统,由用户提问生成SQL语句,是一个单一领域且上下文相关的数据集。GeoQuery来源于美国的地理,包括880条的提问与SQL语句,是一个单一领域且上下文无关的数据集。
WikiSQL数据集:
ATIS和GeoQuery这两个数据集存在着数据规模小(SQL不足千句),标注简单等问题。于是,2017年VictorZhong等研究人员基于维基百科,标注了80654的训练数据,涵盖了26521个数据库,取名为WikiSQL。这个大型数据集一经推出,便引起学术界的广泛关注,因为它对模型的设计提出了新的挑战,需要模型更好地建构Text和SQL之间的映射关系,更好地利用表格中的属性,更加关注解码的过程。在后续工作中产生了一系列优秀的模型,如Seq2SQL、SQLNet、TypeSQL等,我们将在主流工作一章进行详细的介绍。项目链接:https://github.com/salesforce/WikiSQL。 - 多表嵌套数据集
Spider数据集:
由于WikiSQL数据集也存在着问题,它的每个问题只涉及一个表格,而且仅支持比较简单的SQL操作,这不是很符合日常生活中的场景。现实生活中存在着医疗、票务、学校、交通等各个领域的数据库,而且每个数据库又有数十甚至上百个表格,表格之间又有着复杂的主外键联系。于是,2018年耶鲁大学的研究人员推出了Spider数据集,这也是目前最复杂的Text-to-SQL数据集。它有以下几个特点:(1)领域比较丰富,拥有来自138个领域的200多个数据库,每个数据库平均对应5.1个表格,并且训练集、测试集中出现的数据库不重合。(2)SQL语句更为复杂,包含orderBy、union、except、groupBy、intersect、limit、having 关键字,以及嵌套查询等。研究人员根据SQL语句的复杂程度(关键字个数、嵌套程度)分为了4种难度,值得注意的是,WikiSQL在这个划分下只有EASY难度。Spider相比WikiSQL,对模型的跨领域、生成复杂SQL的能力提出了新的要求,目前的最佳模型也只有60%左右的准确度。挑战赛链接:https://yale-lily.github.io/spider。
中文CSpider数据集:
西湖大学在EMNLP2019上提出了一个中文Text-to-SQL的数据集CSpider,主要是选择Spider作为源数据集进行了问题的翻译,并利用SyntaxSQLNet作为基线系统进行了测试,同时探索了在中文上产生的一些额外的挑战,包括中文问题对英文数据库的对应问题(Question-to-DBmapping)、中文的分词问题以及一些其他的语言现象。挑战赛链接:https://taolusi.github.io/CSpider-explorer/。 - 竞赛数据集
在国内,关于NL2SQL的比赛已举办过多次,其中规模较大的两次分别为追一科技的“首届中文NL2SQL挑战赛”和百度的“2020语言与智能技术竞赛:语义解析任务”。其中,追一比赛数据集为单表无嵌套NL2SQL数据集,数据形式较为简单,每一条SQL只有求最大值、最小值、平均值、求和、计数和条件过滤语法现象,无聚合函数,所以排行榜得分较高,算法实现较为容易。

追一比赛官网截图
百度数据集为多表含有嵌套SQL数据集,数据形式较为复杂,更贴近真实用户和工业落地场景。
百度比赛截图
三 主要技术路线
目前关于NL2SQL技术路线的发展主要包含以下几种:
Seq2Seq方法,在深度学习的研究背景下,很多研究人员将Text-to-SQL看作一个类似神经机器翻译的任务,主要采取Seq2Seq的模型框架。基线模型Seq2Seq在加入Attention、Copying等机制后,能够在ATIS、GeoQuery数据集上达到84%的精确匹配,但是在WikiSQL数据集上只能达到23.3%的精确匹配,37.0%的执行正确率;在Spider数据集上则只能达到5~6%的精确匹配。
模板槽位填充方法,将SQL的生成过程分为多个子任务,每一个子任务负责预测一种语法现象中的列,该方法对于单表无嵌套效果好,并且生成的SQL可以保证语法正确,缺点是只能建模固定的SQL语法模板,对于有嵌套的SQL情况,无法对所有嵌套现象进行灵活处理。
中间表达方法,该方法为当前主流方法,以IRNet为代表,将SQL生成分为两步,第一步预测SQL语法骨干结构,第二步对前面的预测结果做列和值的补充。在后续的文章中将围绕此方法展开讲述我们的实践经验。
结合图网络的方法,此方法主要为解决多个表中有同名的列的时候,预测不准确的问题,以Global-GNN、RatSQL为代表,但是由于数据库之间并没有边相连接,所以此方法提升不大且模型消耗算力较大。
强化学习方法,此方法以Seq2SQL为代表,每一步计算当前决策生成的SQL是否正确,本质上强化学习是基于交互产生的训练数据集的有监督学习,此法效果和翻译模型相似。
结合预训练模型、语义匹配的方法,该方法以表格内容作为预训练语料,结合语义匹配任务目标输入数据库Schema,从而选中需要的列,例如:BREIDGE、GRAPPA等。
- X-SQL方法
本节主要介绍X-SQL的方法,此方法为当前模板填充法的代表,将单表的NL2SQL任务转化为多个子任务,每一个子任务负责预测一个语法现象中存在的列和对列的操作,将NL2SQL任务转化为一个在列上的分类任务。模型结构如图所示:

X-SQL网络结构上图中的模型分为编码器、上下文强化层、输出层。
编码器来自改良的BERT–MT-DNN,其数据输入形式为自然语言问题和各列的名称,自然语言问题和列名之间用BERT中的特殊token [SEP]隔开,并且在每一列的开始位置使用不同的token表示不同的数据类型。编码器还把[CLS] token换成了[CTX] token。
上下文增强层是将每个列的输出向量合并到[CTX]位置的输出向量中得到一个列向量。
输出层有六个子任务分别是:W-NUM(条件个数),W-COL(条件对应列,column_index),W-OP(条件运算符,operator_index),W-VAL(条件目标值,condition),S-COL(查询目标列,sel),S-AGG(查询聚合操作,agg)。
由于在工程实践中目标数据库的列较多,SQL选中的列相对数据库存在的列的比例较少,例如一个一百列的数据库可能SQL选中其中一列,因此造成标记数据稀疏的问题,需要先进行列名的相关性排序或者人工在程序中进行重采样来解决。
2. IRNet方法
IRNet设计了一种在自然语言和SQL之间的中间表达SemQL,采用两步完成Text-to-SQL的过程:
第一步SchemaEncoding和Schema Linking:SchemaEncoding顾名思义就是对表结构(表名、列名、列类型、主键、外键等等)进行编码,以便后续模型训练使用。SchemaLinking则是要把Question中表述的内容与具体的表名和列名对齐。
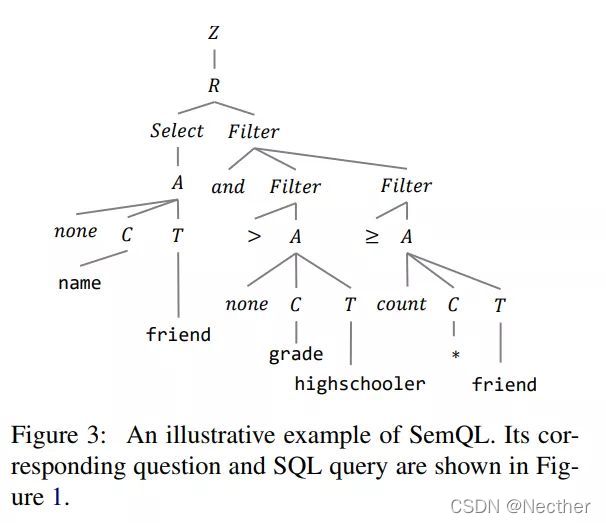
第二步预测SemQL,然后用第一步预测的列来填充SemQL所表示的SQL语法结构。文中设计的中间表达SemQL结构如下:

SemQL结构图SQL根据文中设定的规则可以拆解为如下图的语法树:

IRNet中SemQL的语法树Z是根节点,R表示一个SQL单句,上图的”Select Filter“表示当前的SQL中包含有SELECT和WHERE两个SQL关键词。树中的每一个中间节点表示该SQL含有某一个SQL中的语法现象。其中的C、T分别代表该SQL查询到的列和表。最终通过第一步Schema Encoding和Schema Linking中的结果将该树补全则成为一条完整的SQL语句。
3. BRIDGE方法
考虑到问题和Schema之间的表达是有关联和差距的,BRIDGE方法设计了一种桥接手段,通过问题和Schema中的值模糊匹配,丰富模型的输入。具体地,将命中的值拼接到所属列名的后面,用来表示该列名与问题之间较可能存在关联,相当于从值的层面告诉模型该问题应该重点关注哪几个列。最后,输入经过BERT+Bi-LSTM得到列的语义表示。BRIDGE模型架构如下图所示:
四 算法大赛实践分享
以国家电网调控人工智能创新大赛为例
- 比赛赛题及背景
电网调控系统经多年运行汇集了海量的电网运行数据,存储于数据库或文件系统中,呈现出规模大、种类多、范围广等特点,对于这类数据的获取和分析通常需要通过机器编程语言与数据库(或文件系统)进行交互操作,给数据分析带来了较高的门槛。数据挖掘深度不够、数据增值变现能力弱等问题也逐渐显现。亟需通过人工智能技术手段,实现人机交互方式变革,提高数据分析挖掘效率,激活数据价值,促进数据价值变现。针对电网调控系统数据以结构化、半结构化形式存储特点以及海量数据分析繁琐低效的问题,要求参赛者利用语义解析技术训练AI智能体,理解调控系统常见问题,解析数据库的表、属性、外键等复杂关系,最终生成SQL语句并在数据库中执行获得问题答案,为用户提供自动、高效、精准的信息检索服务。 - 赛题理解和分析
本赛题属于语义解析领域,即将自然语言转换为逻辑形式的任务,它被认为是从自然语言到语义表征的映射,它可以在各种环境中执行,以便通过将自然语言解析成数据库查询,或在会话代理(如Siri和Alexa)中进行查询解析来实现,诸如机器人导航、数据探索分析等任务。语义解析技术发展至今,已经有诸多相关的解决方案和学术研究,例如,基于模板填充的解析技术、基于Seq2Seq的语义解析技术、基于强化学习的语义解析技术等等。本次《电网运行信息智能检索》赛题要求是“给定自然语言表述的电网调控问题及其对应的数据库,要求参评的语义解析系统自动生成SQL查询语句。”分析数据集得知,比赛数据集来自电网调控领域真实语料,包含46张表以及对应的1720条调控场景问题-SQL语句对,涉及公共数据、电力一次设备、自动化设备等多个数据对象;收集调控领域常用查询问题并转写为SQL语句,包含了同一类问题的不同问法等多种情况。 - 技术路线
由于本赛题涉及数据资源属于单一数据库类型,数据并不存在跨领域问题,SQL表达具有较好的一致性,因此适用于基于Seq2Seq的翻译模型来完成任务。根据数据集“单一数据库”、“较多连表查询”、“表列数目较大”等特点,我们设计了基于Transformer的融合表列值信息的Seq2Seq语义解析模型,我们以Transformer作为基础特征提取单元,构建一个融合表、列、值多元信息的Encoder-Decoder架构来完成端到端的NL2SQL任务。
算法流程图如下:

算法流程描述:如图所示,首先由于数据量的限制,我们需要对数据进行合理的增广,通过对原始自然问句进行分词,通过列名替换、停用词替换和句式替换等方法得到新的问句-SQL查询对。同时,采用AEDA的噪音增强技术,参杂一定比例的噪音样本增强模型鲁棒性。由于SQL语句对大小写不敏感,所以我们统一将SQL语句转化为小写字符。比较关键的一步是,如何将Schema信息与自然语言问句进行交互,我们采用基于模糊匹配的方法,根据不同的自然语言问句动态生成相应的Schema信息与原自然语言问句进行拼接。对于扩充后的数据集,我们采用基于Transformer架构的生成式预训练Text2Text模型,进行端到端的Finetune。在测试时,同样地,我们对测试样本动态生成Schema拼接信息,完成端到端推理预测,得到SQL语句。
算法的关键环节如下:
自然语言问句AEDA数据增强;
输入文本与输出文本保持大小写统一;
对每一个自然语言问句使用动态Schema信息生成技术,进行额外的信息拼接;
对于绝大部分SQL语句进行Greedy Decoding,部分较长SQL查询采用Top-p Sampling或BeamSearch Decoding。
接下来,我们对本次比赛中有较多贡献的AEDA数据增强技术和动态Schema信息生成技术进行详细阐述。
本次数据集的规模相较于真实用户场景的数据规模而言是非常小的。数据增强技术的使用不可避免。怎样去使用数据增强技术,使用哪一种数据增强技术,对于模型的影响都是举足轻重的。
2019年的EDA(Easy Data Augmentation Techniques forBoosting Performance on Text Classification Tasks)论文发表于ICLR2019,提出了四种简单的数据增强操作,包括:同义词替换(通过同义词表将句子中的词语进行同义词替换)、随机交换(随机交换句子的两个词语,改变语序)、随机插入(在原始句子中随机插入,句子中某一个词的同义词)和随机删除(随机删除句子中的词语)。
本次比赛中应用的AEDA(An Easier Data Augmentation),是一种简单的用于生成噪音文本的数据增强技术。最开始被用于提升文本分类的鲁棒性,主要是在原始文本中随机插入一些标点符号,属于增加噪声的一种,主要与EDA论文对标,突出“简单”二字。
传统EDA方法,无论是同义词替换,还是随机替换、随机插入、随机删除,都改变了原始文本的序列信息,而AEDA方法,只是插入标点符号,对于原始数据的序列信息修改不明显。而在NL2SQL的EDA过程中,我们显然是不希望原始问句语义被篡改,因此,在数据量较小的场景下,AEDA的增强技术能够较好地完成增强NL2SQL语义解析模型的鲁棒性提升任务。
接下来将介绍本次比赛的另一个关键点——动态Schema信息生成技术。
对于NL2SQL任务,如何将输入的自然语言问句与数据库中的存储信息进行连接,十分关键,我们称之为Schema Linking环节。对于百分点科技此次比赛使用的End2End翻译模型而言,传统的Schema Linking技术并不适用。因而我们采用了一种基于字符串匹配的动态Schemainformation生成技术,对模型的输入进行动态增强,从而达到翻译过程中的Schema Linking目的。
首先,为了将自然语言问句与数据库的Schema进行关联,需要将数据库中的表名和列名进行规范化(例如对不合理命名、歧义命名、英文命名等,根据业务进行重新梳理规整)。
然后,对于所有的规范化后的表名和列名,我们通过模糊匹配的方式对其与自然语言问句进行相似度评分,并依据评分从大到小进行表列名的字符串拼接,形式如下:
“{Table name1:Column1| Column2 | …} | {…}…”
这里我们将不同表的信息用“{}”进行聚合,然后通过“|”分隔,同一张表内的不同列之间通过“|”分隔,无论是表间信息的排序还是表内信息的排序,都是依据字符串模糊匹配得分来进行。在对每一个自然语言问句模型输入前,均进行这样的动态Schema 信息生成,然后拼接到原始自然语言问句中,作为模型新的输入。这里由于拼接信息可能会超过512字符(传统BERT模型的限制),于是我们采用基于更长距离建模特征的Transformer-XL来替代原始Transformer模块,来完成长序列的建模。同样的,我们的动态Schema生成技术,亦可用于DB Content的信息拼接,思路大同小异。
总结一下,算法的创新点如下:
End-to-End方式解决NL2SQL任务,执行效率高,无子模型pipeline误差传递;
AEDA数据增强技术,简单直接的文本增强技术,可以生成带噪音的自然语言问句样本;
动态融合Schema信息和DBContent信息,构建简单合理的Schema Linking机制,使得自然语言问句与数据库中的目标表和列联系更加紧密。
5. 比赛成绩
在该比赛中,百分点科技参赛团队名称是“语义解析”队,我们的方案在初赛中的精准匹配率是0.8228,获得了第三名成绩;在决赛中的精准匹配率是0.6554,获得了第五名的成绩。
五工程实践经验
本节以某地方空天院的NL2SQL项目简单介绍我们工程实施中的方案,经过上文中介绍的技术路线,我们对比了两种主流技术路线中的优劣势:
基于模板填充的方法:优势在于计算资源依赖少、SQL生成效率高、可控性强、SQL组件顺序不敏感;劣势在于复杂SQL生成乏力,子模型累积误差;
基于Seq2Seq的方法:优势在于可生成任意形态SQL;劣势在于资源依赖高、SQL生成效率低、可控性一般、SQL组件顺序敏感。
其中可控性指的是模型产生的SQL语句是否符合SQL语法规范能够正确执行,SQL顺序敏感指的是在SQL的过滤条件中列的前后顺序并不影响SQL的正确性。和前面介绍的百度和国家电网NL2SQL竞赛不同,工业应用对于可控性的要求比较高,同时涉及到的数据形式会更复杂,采用Seq2Seq模型生成的SQL语句无法保证其语法规范性,同时也无法针对具体的领域数据进行定向优化。而简单的“模版填充法”虽然可以实现定向优化,但是无法解决复杂的嵌套表达形式。为了能够更好地扬长避短,结合两种主流方案的优势,我们提出了以下的算法工程方案:
SQL结构预测:将自然语言问句和表结构到最终生成的SQL中出现的语法现象编码(子查询、分组等),通过bert-sequence建模;
列识别模型:预测SQL中Select部分存在的列和列上执行的操作(聚合函数等);
值识别模型:预测SQL中where部分中对应的判断符号(大于、小于、等于)。
整体模型流程如下:

在该项目中由于问题和需要生成SQL的数据库表格长度较短,所以可以直接进行Schema Linking,并且不会由于选中列的标记数据稀疏导致训练失效的问题,所以我们采用了上面的方案取得了不错的效果。
六 总结与展望
当前,自然语言处理技术的发展和预训练模型的大规模应用,使语义解析中的NL2SQL技术在真实场景落地成为可能。但是在工业实践中应用仍旧有不少问题尚待解决,主要表现在自然语言建模更多的是使用联结主义的方法,如深度学习,而要生成的SQL语句为形式化语言,人工智能技术尚且无法完全弥合符号主义和联结主义两种方法之间的鸿沟,这也是NL2SQL技术所面临的最大挑战。不过随着认知智能技术的发展,出现了越来越多的方法,相信终有一日NL2SQL等语义解析问题会被完美解决,实现人机交互的无缝衔接。本文介绍了当前NL2SQL的主流技术路线,以及百分点认知智能实验室在竞赛和项目中积累的实践经验。后续实验室将继续努力深耕NL2SQL问题,为客户带来更好的技术解决方案,创造更大的业务价值。
参考资料
[1] Lin X V , R Socher, Xiong C . Bridging Textual and Tabular Data for Cross-Domain Text-to-SQLSemantic Parsing[C]// Findings of the Association for ComputationalLinguistics: EMNLP 2020. 2020.[2] Yu T , Wu C S , Lin X V , et al. GraPPa: Grammar-AugmentedPre-Training for Table Semantic Parsing[J]. 2020.
[3] Seq2sql: Generating structured queries fromnatural languageusing reinforcement learning (Victor Zhong, Caiming Xiong,Richard Socher.CoRR2017)
[4] SQLNet: Generating Structured Queries FromNatural LanguageWithout Reinforcement Learning (Xiaojun Xu, Chang Liu, DawnSong. ICLR2018).
[5] Global Reasoning over Database Structures forText-to-SQLParsing (Ben Bogin, Matt Gardner, Jonathan Berant. EMNLP2019).
[6] RAT-SQL: Relation-Aware Schema Encoding andLinking forText-to-SQL Parsers (Bailin Wang, Richard Shin, Xiaodong Liu,Oleksandr Polozov,Matthew Richardson. Submitted to ACL2020).
[7] Towards Complex Text-to-SQL in Cross-DomainDatabase withIntermediate Representation (Jiaqi Guo, Zecheng Zhan, Yan Gao,Yan Xiao,Jian-Guang Lou, Ting Liu, and Dongmei Zhang. ACL2019).